目录
前言
一、难点分析
二、实现流程
1.DNF窗口位置获取
2.获取训练数据
3.数据标注
4.数据格式转换
5.数据训练
5.刷图逻辑编写
前言
这是一篇不务正业的研究,首先说明,这不是外挂!这不是外挂!这不是外挂!这只是用ai做图像识别、目标检测然后通过模拟键鼠实现的一个外部自动化脚本。求生欲极强!哈哈哈哈
一、难点分析
在不读取内存又想拿到信息的情况下,只有走图像识别一条路了。一个完整的刷图应该包括打怪,拾取物品,找门过图。那么YOLOV7的轻量级框架能支持140fps的图像实时解析,必定非常符合我们的要求。
剩下的难点就是怎么让人物移动的固定坐标点,怎么设计打怪逻辑,怎么读取技能cd时间让人物合理释放技能。
二、实现流程
1.DNF窗口位置获取
这里当然是使用过pywin32是快捷的,下载一个spy++,拿到dnf窗口句柄,然后用过win32gui来获取窗口坐标。
def get_window_rect(hwnd):
try:
f = ctypes.windll.dwmapi.DwmGetWindowAttribute
except WindowsError:
f = None
if f:
rect = ctypes.wintypes.RECT()
DWMWA_EXTENDED_FRAME_BOUNDS = 9
f(ctypes.wintypes.HWND(hwnd),
ctypes.wintypes.DWORD(DWMWA_EXTENDED_FRAME_BOUNDS),
ctypes.byref(rect),
ctypes.sizeof(rect)
)
return rect.left, rect.top, rect.right, rect.bottom
hid = win32gui.FindWindow("地下城与勇士", "地下城与勇士:创新世纪")
left, top, right, bottom = get_window_rect(hid)2.获取训练数据
拿到DNF窗口位置后,我们需要截屏具体位置来获取训练的图像,截屏我们使用pyautogui这个库来完成,因为这个库非常强大,能实现0.004秒一张图截屏速度,只需要手动刷一遍图,就能截取大量素材。
im = pyautogui.screenshot(region=[left, top, abs(right - left), abs(top - bottom)])然后我们拿到了大量的图片
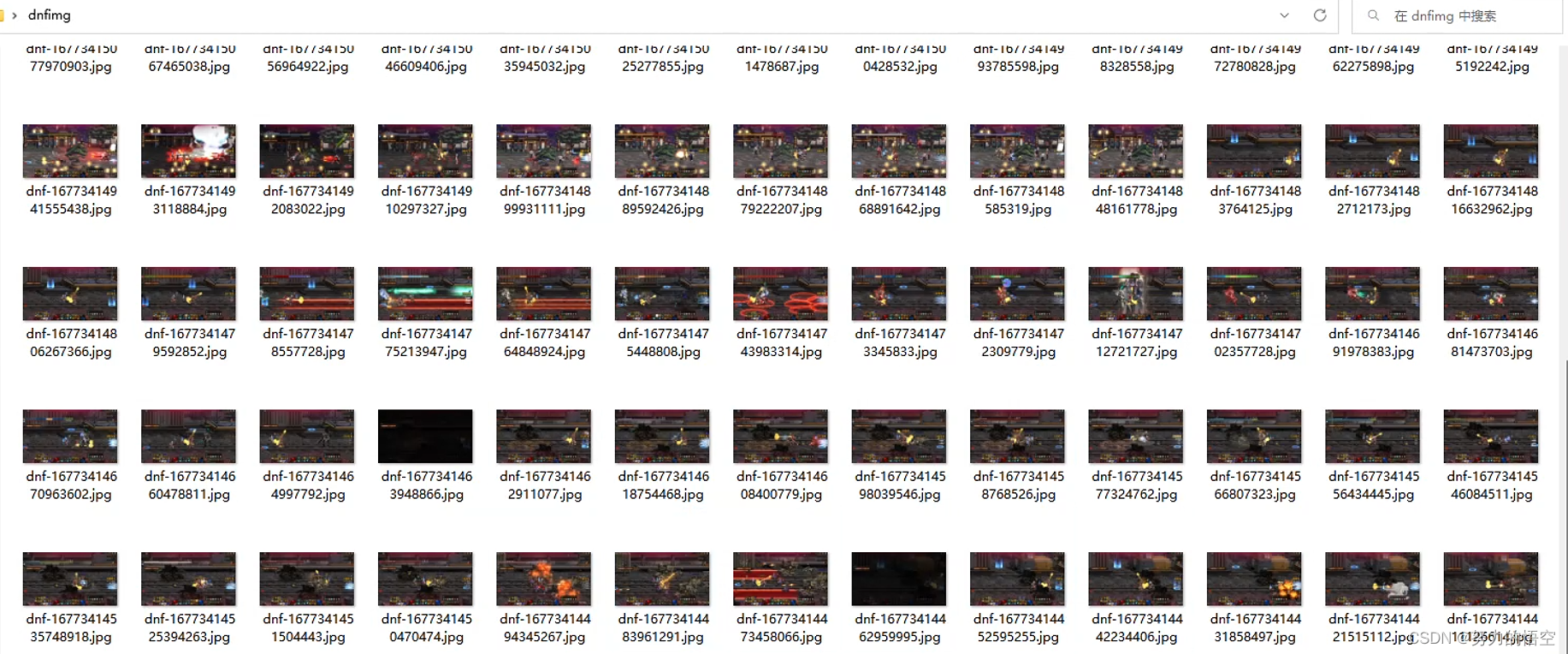
3.数据标注
这就到了整个环节最痛苦的流程了,使用labme工具标注数据,标注门、物品、角色、怪物

4.数据格式转换
labme标注完成后,会导出一个json文件,为了将json文件转换成标准训练集数据格式,我们用fme写了一个模板来完成数据转换。

转换前数据:
{
"version": "4.5.6",
"flags": {},
"shapes": [
{
"label": "i",
"points": [
[
541.21768707483,
298.85034013605446
],
[
642.578231292517,
428.78231292517006
]
],
"group_id": null,
"shape_type": "rectangle",
"flags": {}
},
{
"label": "guai",
"points": [
[
267.7482993197279,
228.10204081632654
],
[
380.6734693877551,
379.12244897959187
]
],
"group_id": null,
"shape_type": "rectangle",
"flags": {}
}
],
"imagePath": "dnf-16773414691978383.jpg",
"imageData": "",
"imageHeight": 600,
"imageWidth": 1067
}转换后数据:(将数据用路径+标注类别+坐标表示)
942,619,996,635,2 786,609,961,630,2 824,563,879,589,2 880,531,1004,555,2 1017,544,1091,572,2
C:\Users\Administrator\Desktop\dnfimg\dnf-73bc62b1-f305-4a76-809e-72f7564a9633.jpg 639,413,771,677,0 746,625,817,653,2 977,598,1174,632,2 942,619,996,635,2 786,609,961,630,2 824,563,879,589,2 880,531,1004,555,2 1017,544,1091,572,2
C:\Users\Administrator\Desktop\dnfimg\dnf-73bc62b1-f305-4a76-809e-72f7564a9633.jpg 639,413,771,677,0 746,625,817,653,2 977,598,1174,632,2 942,619,996,635,2 786,609,961,630,2 824,563,879,589,2 880,531,1004,555,2 1017,544,1091,572,2
C:\Users\Administrator\Desktop\dnfimg\dnf-73bc62b1-f305-4a76-809e-72f7564a9633.jpg 639,413,771,677,0 746,625,817,653,2 977,598,1174,632,2 942,619,996,635,2 786,609,961,630,2 824,563,879,589,2 880,531,1004,555,2 1017,544,1091,572,2
C:\Users\Administrator\Desktop\dnfimg\dnf-73bc62b1-f305-4a76-809e-72f7564a9633.jpg 639,413,771,677,0 746,625,817,653,2 977,598,1174,632,2 942,619,996,635,2 786,609,961,630,2 824,563,879,589,2 880,531,1004,555,2 1017,544,1091,572,2
C:\Users\Administrator\Desktop\dnfimg\dnf-73bc62b1-f305-4a76-809e-72f7564a9633.jpg 639,413,771,677,0 746,625,817,653,2 977,598,1174,632,2 942,619,996,635,2 786,609,961,630,2 824,563,879,589,2 880,531,1004,555,2 1017,544,1091,572,2
C:\Users\Administrator\Desktop\dnfimg\dnf-73bc62b1-f305-4a76-809e-72f7564a9633.jpg 639,413,771,677,0 746,625,817,653,2 977,598,1174,632,2 942,619,996,635,2 786,609,961,630,2 824,563,879,589,2 880,531,1004,555,2 1017,544,1091,572,2
C:\Users\Administrator\Desktop\dnfimg\dnf-73bc62b1-f305-4a76-809e-72f7564a9633.jpg 639,413,771,677,0 746,625,817,653,2 977,598,1174,632,2 942,619,996,635,2 786,609,961,630,2 824,563,879,589,2 880,531,1004,555,2 1017,544,1091,572,2
C:\Users\Administrator\Desktop\dnfimg\dnf-73bc62b1-f305-4a76-809e-72f7564a9633.jpg 639,413,771,677,0 746,625,817,653,2 977,598,1174,632,2 942,619,996,635,2 786,609,961,630,2 824,563,879,589,2 880,531,1004,555,2 1017,544,1091,572,2
C:\Users\Administrator\Desktop\dnfimg\dnf-e2bbbe68-605b-4021-960b-e75c9f01dcd1.jpg 1207,452,1312,690,0 1080,446,1174,658,1 299,628,363,663,2 879,397,1071,474,1
C:\Users\Administrator\Desktop\dnfimg\dnf-e2bbbe68-605b-4021-960b-e75c9f01dcd1.jpg 1207,452,1312,690,0 1080,446,1174,658,1 299,628,363,663,2 879,397,1071,474,1
C:\Users\Administrator\Desktop\dnfimg\dnf-e2bbbe68-605b-4021-960b-e75c9f01dcd1.jpg 1207,452,1312,690,0 1080,446,1174,658,1 299,628,363,663,2 879,397,1071,474,1
C:\Users\Administrator\Desktop\dnfimg\dnf-e2bbbe68-605b-4021-960b-e75c9f01dcd1.jpg 1207,452,1312,690,0 1080,446,1174,658,1 299,628,363,663,2 5.数据训练
将yolov7代码封装到fme的pythoncaller中。
import fme
import fmeobjects
import datetime
import os
from functools import partial
import tensorflow as tf
import tensorflow.keras.backend as K
from tensorflow.keras.callbacks import (EarlyStopping, LearningRateScheduler,
TensorBoard)
from tensorflow.keras.optimizers import SGD, Adam
from nets.yolo import get_train_model, yolo_body
from nets.yolo_training import get_lr_scheduler
from utils.callbacks import LossHistory, ModelCheckpoint, EvalCallback
from utils.dataloader import YoloDatasets
from utils.utils import get_anchors, get_classes, show_config
from utils.utils_fit import fit_one_epoch
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
eager = False
#---------------------------------------------------------------------#
# train_gpu 训练用到的GPU
# 默认为第一张卡、双卡为[0, 1]、三卡为[0, 1, 2]
# 在使用多GPU时,每个卡上的batch为总batch除以卡的数量。
#---------------------------------------------------------------------#
train_gpu = [0,]
#---------------------------------------------------------------------#
# classes_path 指向model_data下的txt,与自己训练的数据集相关
# 训练前一定要修改classes_path,使其对应自己的数据集
#---------------------------------------------------------------------#
classes_path = 'model_data/voc_classes.txt'
#---------------------------------------------------------------------#
# anchors_path 代表先验框对应的txt文件,一般不修改。
# anchors_mask 用于帮助代码找到对应的先验框,一般不修改。
#---------------------------------------------------------------------#
anchors_path = 'model_data/yolo_anchors.txt'
anchors_mask = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
#----------------------------------------------------------------------------------------------------------------------------#
# 权值文件的下载请看README,可以通过网盘下载。模型的 预训练权重 对不同数据集是通用的,因为特征是通用的。
# 模型的 预训练权重 比较重要的部分是 主干特征提取网络的权值部分,用于进行特征提取。
# 预训练权重对于99%的情况都必须要用,不用的话主干部分的权值太过随机,特征提取效果不明显,网络训练的结果也不会好
#
# 如果训练过程中存在中断训练的操作,可以将model_path设置成logs文件夹下的权值文件,将已经训练了一部分的权值再次载入。
# 同时修改下方的 冻结阶段 或者 解冻阶段 的参数,来保证模型epoch的连续性。
#
# 当model_path = ''的时候不加载整个模型的权值。
#
# 此处使用的是整个模型的权重,因此是在train.py进行加载的。
# 如果想要让模型从0开始训练,则设置model_path = '',下面的Freeze_Train = Fasle,此时从0开始训练,且没有冻结主干的过程。
#
# 一般来讲,网络从0开始的训练效果会很差,因为权值太过随机,特征提取效果不明显,因此非常、非常、非常不建议大家从0开始训练!
# 从0开始训练有两个方案:
# 1、得益于Mosaic数据增强方法强大的数据增强能力,将UnFreeze_Epoch设置的较大(300及以上)、batch较大(16及以上)、数据较多(万以上)的情况下,
# 可以设置mosaic=True,直接随机初始化参数开始训练,但得到的效果仍然不如有预训练的情况。(像COCO这样的大数据集可以这样做)
# 2、了解imagenet数据集,首先训练分类模型,获得网络的主干部分权值,分类模型的 主干部分 和该模型通用,基于此进行训练。
#----------------------------------------------------------------------------------------------------------------------------#
model_path = 'model_data/best_epoch_weights.h5'
#------------------------------------------------------#
# input_shape 输入的shape大小,一定要是32的倍数
#------------------------------------------------------#
input_shape = [640, 640]
#------------------------------------------------------#
# phi 所使用的YoloV7的版本。l、x
#------------------------------------------------------#
phi = 'l'
#------------------------------------------------------------------#
# mosaic 马赛克数据增强。
# mosaic_prob 每个step有多少概率使用mosaic数据增强,默认50%。
#
# mixup 是否使用mixup数据增强,仅在mosaic=True时有效。
# 只会对mosaic增强后的图片进行mixup的处理。
# mixup_prob 有多少概率在mosaic后使用mixup数据增强,默认50%。
# 总的mixup概率为mosaic_prob * mixup_prob。
#
# special_aug_ratio 参考YoloX,由于Mosaic生成的训练图片,远远脱离自然图片的真实分布。
# 当mosaic=True时,本代码会在special_aug_ratio范围内开启mosaic。
# 默认为前70%个epoch,100个世代会开启70个世代。
#------------------------------------------------------------------#
mosaic = True
mosaic_prob = 0.5
mixup = True
mixup_prob = 0.5
special_aug_ratio = 0.7
#------------------------------------------------------------------#
# label_smoothing 标签平滑。一般0.01以下。如0.01、0.005。
#------------------------------------------------------------------#
label_smoothing = 0
#----------------------------------------------------------------------------------------------------------------------------#
# 训练分为两个阶段,分别是冻结阶段和解冻阶段。设置冻结阶段是为了满足机器性能不足的同学的训练需求。
# 冻结训练需要的显存较小,显卡非常差的情况下,可设置Freeze_Epoch等于UnFreeze_Epoch,Freeze_Train = True,此时仅仅进行冻结训练。
#
# 在此提供若干参数设置建议,各位训练者根据自己的需求进行灵活调整:
# (一)从整个模型的预训练权重开始训练:
# Adam:
# Init_Epoch = 0,Freeze_Epoch = 50,UnFreeze_Epoch = 100,Freeze_Train = True,optimizer_type = 'adam',Init_lr = 1e-3,weight_decay = 0。(冻结)
# Init_Epoch = 0,UnFreeze_Epoch = 100,Freeze_Train = False,optimizer_type = 'adam',Init_lr = 1e-3,weight_decay = 0。(不冻结)
# SGD:
# Init_Epoch = 0,Freeze_Epoch = 50,UnFreeze_Epoch = 300,Freeze_Train = True,optimizer_type = 'sgd',Init_lr = 1e-2,weight_decay = 5e-4。(冻结)
# Init_Epoch = 0,UnFreeze_Epoch = 300,Freeze_Train = False,optimizer_type = 'sgd',Init_lr = 1e-2,weight_decay = 5e-4。(不冻结)
# 其中:UnFreeze_Epoch可以在100-300之间调整。
# (二)从0开始训练:
# Init_Epoch = 0,UnFreeze_Epoch >= 300,Unfreeze_batch_size >= 16,Freeze_Train = False(不冻结训练)
# 其中:UnFreeze_Epoch尽量不小于300。optimizer_type = 'sgd',Init_lr = 1e-2,mosaic = True。
# (三)batch_size的设置:
# 在显卡能够接受的范围内,以大为好。显存不足与数据集大小无关,提示显存不足(OOM或者CUDA out of memory)请调小batch_size。
# 受到BatchNorm层影响,batch_size最小为2,不能为1。
# 正常情况下Freeze_batch_size建议为Unfreeze_batch_size的1-2倍。不建议设置的差距过大,因为关系到学习率的自动调整。
#----------------------------------------------------------------------------------------------------------------------------#
#------------------------------------------------------------------#
# 冻结阶段训练参数
# 此时模型的主干被冻结了,特征提取网络不发生改变
# 占用的显存较小,仅对网络进行微调
# Init_Epoch 模型当前开始的训练世代,其值可以大于Freeze_Epoch,如设置:
# Init_Epoch = 60、Freeze_Epoch = 50、UnFreeze_Epoch = 100
# 会跳过冻结阶段,直接从60代开始,并调整对应的学习率。
# (断点续练时使用)
# Freeze_Epoch 模型冻结训练的Freeze_Epoch
# (当Freeze_Train=False时失效)
# Freeze_batch_size 模型冻结训练的batch_size
# (当Freeze_Train=False时失效)
#------------------------------------------------------------------#
Init_Epoch = 0
Freeze_Epoch = 50
Freeze_batch_size = 14
#------------------------------------------------------------------#
# 解冻阶段训练参数
# 此时模型的主干不被冻结了,特征提取网络会发生改变
# 占用的显存较大,网络所有的参数都会发生改变
# UnFreeze_Epoch 模型总共训练的epoch
# SGD需要更长的时间收敛,因此设置较大的UnFreeze_Epoch
# Adam可以使用相对较小的UnFreeze_Epoch
# Unfreeze_batch_size 模型在解冻后的batch_size
#------------------------------------------------------------------#
UnFreeze_Epoch = 50
Unfreeze_batch_size = 4
#------------------------------------------------------------------#
# Freeze_Train 是否进行冻结训练
# 默认先冻结主干训练后解冻训练。
#------------------------------------------------------------------#
Freeze_Train = True
#------------------------------------------------------------------#
# 其它训练参数:学习率、优化器、学习率下降有关
#------------------------------------------------------------------#
#------------------------------------------------------------------#
# Init_lr 模型的最大学习率
# 当使用Adam优化器时建议设置 Init_lr=1e-3
# 当使用SGD优化器时建议设置 Init_lr=1e-2
# Min_lr 模型的最小学习率,默认为最大学习率的0.01
#------------------------------------------------------------------#
Init_lr = 1e-2
Min_lr = Init_lr * 0.01
#------------------------------------------------------------------#
# optimizer_type 使用到的优化器种类,可选的有adam、sgd
# 当使用Adam优化器时建议设置 Init_lr=1e-3
# 当使用SGD优化器时建议设置 Init_lr=1e-2
# momentum 优化器内部使用到的momentum参数
# weight_decay 权值衰减,可防止过拟合
# adam会导致weight_decay错误,使用adam时建议设置为0。
#------------------------------------------------------------------#
optimizer_type = "sgd"
momentum = 0.937
weight_decay = 5e-4
#------------------------------------------------------------------#
# lr_decay_type 使用到的学习率下降方式,可选的有'step'、'cos'
#------------------------------------------------------------------#
lr_decay_type = 'cos'
#------------------------------------------------------------------#
# save_period 多少个epoch保存一次权值
#------------------------------------------------------------------#
save_period = 10
#------------------------------------------------------------------#
# save_dir 权值与日志文件保存的文件夹
#------------------------------------------------------------------#
save_dir = 'logs'
#------------------------------------------------------------------#
# eval_flag 是否在训练时进行评估,评估对象为验证集
# 安装pycocotools库后,评估体验更佳。
# eval_period 代表多少个epoch评估一次,不建议频繁的评估
# 评估需要消耗较多的时间,频繁评估会导致训练非常慢
# 此处获得的mAP会与get_map.py获得的会有所不同,原因有二:
# (一)此处获得的mAP为验证集的mAP。
# (二)此处设置评估参数较为保守,目的是加快评估速度。
#------------------------------------------------------------------#
eval_flag = True
eval_period = 10
#------------------------------------------------------------------#
# num_workers 用于设置是否使用多线程读取数据,1代表关闭多线程
# 开启后会加快数据读取速度,但是会占用更多内存
# keras里开启多线程有些时候速度反而慢了许多
# 在IO为瓶颈的时候再开启多线程,即GPU运算速度远大于读取图片的速度。
#------------------------------------------------------------------#
num_workers = 1
#------------------------------------------------------#
# train_annotation_path 训练图片路径和标签
# val_annotation_path 验证图片路径和标签
#------------------------------------------------------#
train_annotation_path = '2007_train.txt'
val_annotation_path = '2007_val.txt'
#------------------------------------------------------#
# 设置用到的显卡
#------------------------------------------------------#
os.environ["CUDA_VISIBLE_DEVICES"] = ','.join(str(x) for x in train_gpu)
ngpus_per_node = len(train_gpu)
gpus = tf.config.experimental.list_physical_devices(device_type='GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
#------------------------------------------------------#
# 判断当前使用的GPU数量与机器上实际的GPU数量
#------------------------------------------------------#
if ngpus_per_node > 1 and ngpus_per_node > len(gpus):
raise ValueError("The number of GPUs specified for training is more than the GPUs on the machine")
if ngpus_per_node > 1:
strategy = tf.distribute.MirroredStrategy()
else:
strategy = None
print('Number of devices: {}'.format(ngpus_per_node))
class FeatureProcessor(object):
"""Template Class Interface:
When using this class, make sure its name is set as the value of the 'Class
to Process Features' transformer parameter.
"""
def __init__(self):
"""Base constructor for class members."""
pass
def input(self, feature):
class_names, num_classes = get_classes(classes_path)
print("类名{},类数量{}".format(class_names, num_classes))
anchors, num_anchors = get_anchors(anchors_path)
#----------------------------------------------------#
# 判断是否多GPU载入模型和预训练权重
#----------------------------------------------------#
if True:
#------------------------------------------------------#
# 创建yolo模型
#------------------------------------------------------#
model_body = yolo_body((None, None, 3), anchors_mask, num_classes, phi, weight_decay)
if model_path != '':
pass
#------------------------------------------------------#
# 载入预训练权重
#------------------------------------------------------#
# print('Load weights {}.'.format(model_path))
# model_body.load_weights(model_path, by_name=True, skip_mismatch=True)
if not eager:
model = get_train_model(model_body, input_shape, num_classes, anchors, anchors_mask, label_smoothing)
model.summary()
#---------------------------#
# 读取数据集对应的txt
#---------------------------#
with open(train_annotation_path, encoding='utf-8') as f:
train_lines = f.readlines()
with open(val_annotation_path, encoding='utf-8') as f:
val_lines = f.readlines()
num_train = len(train_lines)
num_val = len(val_lines)
show_config(
classes_path = classes_path, anchors_path = anchors_path, anchors_mask = anchors_mask, model_path = model_path, input_shape = input_shape, \
Init_Epoch = Init_Epoch, Freeze_Epoch = Freeze_Epoch, UnFreeze_Epoch = UnFreeze_Epoch, Freeze_batch_size = Freeze_batch_size, Unfreeze_batch_size = Unfreeze_batch_size, Freeze_Train = Freeze_Train, \
Init_lr = Init_lr, Min_lr = Min_lr, optimizer_type = optimizer_type, momentum = momentum, lr_decay_type = lr_decay_type, \
save_period = save_period, save_dir = save_dir, num_workers = num_workers, num_train = num_train, num_val = num_val
)
#---------------------------------------------------------#
# 总训练世代指的是遍历全部数据的总次数
# 总训练步长指的是梯度下降的总次数
# 每个训练世代包含若干训练步长,每个训练步长进行一次梯度下降。
# 此处仅建议最低训练世代,上不封顶,计算时只考虑了解冻部分
#----------------------------------------------------------#
wanted_step = 5e4 if optimizer_type == "sgd" else 1.5e4
total_step = num_train // Unfreeze_batch_size * UnFreeze_Epoch
if total_step <= wanted_step:
if num_train // Unfreeze_batch_size == 0:
raise ValueError('数据集过小,无法进行训练,请扩充数据集。')
wanted_epoch = wanted_step // (num_train // Unfreeze_batch_size) + 1
print("\n\033[1;33;44m[Warning] 使用%s优化器时,建议将训练总步长设置到%d以上。\033[0m"%(optimizer_type, wanted_step))
print("\033[1;33;44m[Warning] 本次运行的总训练数据量为%d,Unfreeze_batch_size为%d,共训练%d个Epoch,计算出总训练步长为%d。\033[0m"%(num_train, Unfreeze_batch_size, UnFreeze_Epoch, total_step))
print("\033[1;33;44m[Warning] 由于总训练步长为%d,小于建议总步长%d,建议设置总世代为%d。\033[0m"%(total_step, wanted_step, wanted_epoch))
#------------------------------------------------------#
# 主干特征提取网络特征通用,冻结训练可以加快训练速度
# 也可以在训练初期防止权值被破坏。
# Init_Epoch为起始世代
# Freeze_Epoch为冻结训练的世代
# UnFreeze_Epoch总训练世代
# 提示OOM或者显存不足请调小Batch_size
#------------------------------------------------------#
if True:
if Freeze_Train:
freeze_layers = {'n':118, 's': 118, 'm': 167, 'l': 216, 'x': 265}[phi]
#print(freeze_layers)
for i in range(50): model_body.layers[i].trainable = False
# print('Freeze the first {} layers of total {} layers.'.format(freeze_layers, len(model_body.layers)))
#-------------------------------------------------------------------#
# 如果不冻结训练的话,直接设置batch_size为Unfreeze_batch_size
#-------------------------------------------------------------------#
batch_size = Freeze_batch_size if Freeze_Train else Unfreeze_batch_size
#-------------------------------------------------------------------#
# 判断当前batch_size,自适应调整学习率
#-------------------------------------------------------------------#
nbs = 64
lr_limit_max = 1e-3 if optimizer_type == 'adam' else 5e-2
lr_limit_min = 3e-4 if optimizer_type == 'adam' else 5e-4
Init_lr_fit = min(max(batch_size / nbs * Init_lr, lr_limit_min), lr_limit_max)
Min_lr_fit = min(max(batch_size / nbs * Min_lr, lr_limit_min * 1e-2), lr_limit_max * 1e-2)
#---------------------------------------#
# 获得学习率下降的公式
#---------------------------------------#
lr_scheduler_func = get_lr_scheduler(lr_decay_type, Init_lr_fit, Min_lr_fit, UnFreeze_Epoch)
epoch_step = num_train // batch_size
epoch_step_val = num_val // batch_size
if epoch_step == 0 or epoch_step_val == 0:
raise ValueError('数据集过小,无法进行训练,请扩充数据集。')
train_dataloader = YoloDatasets(train_lines, input_shape, anchors, batch_size, num_classes, anchors_mask, Init_Epoch, UnFreeze_Epoch, \
mosaic=mosaic, mixup=mixup, mosaic_prob=mosaic_prob, mixup_prob=mixup_prob, train=True, special_aug_ratio=special_aug_ratio)
val_dataloader = YoloDatasets(val_lines, input_shape, anchors, batch_size, num_classes, anchors_mask, Init_Epoch, UnFreeze_Epoch, \
mosaic=False, mixup=False, mosaic_prob=0, mixup_prob=0, train=False, special_aug_ratio=0)
optimizer = {
'adam' : Adam(lr = Init_lr, beta_1 = momentum),
'sgd' : SGD(lr = Init_lr, momentum = momentum, nesterov=True)
}[optimizer_type]
if eager:
start_epoch = Init_Epoch
end_epoch = UnFreeze_Epoch
UnFreeze_flag = False
gen = tf.data.Dataset.from_generator(partial(train_dataloader.generate), (tf.float32, tf.float32, tf.float32, tf.float32, tf.float32))
gen_val = tf.data.Dataset.from_generator(partial(val_dataloader.generate), (tf.float32, tf.float32, tf.float32, tf.float32, tf.float32))
gen = gen.shuffle(buffer_size = batch_size).prefetch(buffer_size = batch_size)
gen_val = gen_val.shuffle(buffer_size = batch_size).prefetch(buffer_size = batch_size)
if ngpus_per_node > 1:
gen = strategy.experimental_distribute_dataset(gen)
gen_val = strategy.experimental_distribute_dataset(gen_val)
time_str = datetime.datetime.strftime(datetime.datetime.now(),'%Y_%m_%d_%H_%M_%S')
log_dir = os.path.join(save_dir, "loss_" + str(time_str))
loss_history = LossHistory(log_dir)
eval_callback = EvalCallback(model_body, input_shape, anchors, anchors_mask, class_names, num_classes, val_lines, log_dir, \
eval_flag=eval_flag, period=eval_period)
#---------------------------------------#
# 开始模型训练
#---------------------------------------#
for epoch in range(start_epoch, end_epoch):
#---------------------------------------#
# 如果模型有冻结学习部分
# 则解冻,并设置参数
#---------------------------------------#
if epoch >= Freeze_Epoch and not UnFreeze_flag and Freeze_Train:
batch_size = Unfreeze_batch_size
#-------------------------------------------------------------------#
# 判断当前batch_size,自适应调整学习率
#-------------------------------------------------------------------#
nbs = 64
lr_limit_max = 1e-3 if optimizer_type == 'adam' else 5e-2
lr_limit_min = 3e-4 if optimizer_type == 'adam' else 5e-4
Init_lr_fit = min(max(batch_size / nbs * Init_lr, lr_limit_min), lr_limit_max)
Min_lr_fit = min(max(batch_size / nbs * Min_lr, lr_limit_min * 1e-2), lr_limit_max * 1e-2)
#---------------------------------------#
# 获得学习率下降的公式
#---------------------------------------#
lr_scheduler_func = get_lr_scheduler(lr_decay_type, Init_lr_fit, Min_lr_fit, UnFreeze_Epoch)
for i in range(len(model_body.layers)):
model_body.layers[i].trainable = True
epoch_step = num_train // batch_size
epoch_step_val = num_val // batch_size
if epoch_step == 0 or epoch_step_val == 0:
raise ValueError("数据集过小,无法继续进行训练,请扩充数据集。")
train_dataloader.batch_size = batch_size
val_dataloader.batch_size = batch_size
gen = tf.data.Dataset.from_generator(partial(train_dataloader.generate), (tf.float32, tf.float32, tf.float32, tf.float32, tf.float32))
gen_val = tf.data.Dataset.from_generator(partial(val_dataloader.generate), (tf.float32, tf.float32, tf.float32, tf.float32, tf.float32))
gen = gen.shuffle(buffer_size = batch_size).prefetch(buffer_size = batch_size)
gen_val = gen_val.shuffle(buffer_size = batch_size).prefetch(buffer_size = batch_size)
if ngpus_per_node > 1:
gen = strategy.experimental_distribute_dataset(gen)
gen_val = strategy.experimental_distribute_dataset(gen_val)
UnFreeze_flag = True
lr = lr_scheduler_func(epoch)
K.set_value(optimizer.lr, lr)
fit_one_epoch(model_body, loss_history, eval_callback, optimizer, epoch, epoch_step, epoch_step_val, gen, gen_val,
end_epoch, input_shape, anchors, anchors_mask, num_classes, label_smoothing, save_period, save_dir, strategy)
train_dataloader.on_epoch_end()
val_dataloader.on_epoch_end()
else:
start_epoch = Init_Epoch
end_epoch = Freeze_Epoch if Freeze_Train else UnFreeze_Epoch
if ngpus_per_node > 1:
with strategy.scope():
model.compile(optimizer = optimizer, loss={'yolo_loss': lambda y_true, y_pred: y_pred})
else:
model.compile(optimizer = optimizer, loss={'yolo_loss': lambda y_true, y_pred: y_pred})
#-------------------------------------------------------------------------------#
# 训练参数的设置
# logging 用于设置tensorboard的保存地址
# checkpoint 用于设置权值保存的细节,period用于修改多少epoch保存一次
# lr_scheduler 用于设置学习率下降的方式
# early_stopping 用于设定早停,val_loss多次不下降自动结束训练,表示模型基本收敛
#-------------------------------------------------------------------------------#
model.load_weights(model_path)
time_str = datetime.datetime.strftime(datetime.datetime.now(),'%Y_%m_%d_%H_%M_%S')
log_dir = os.path.join(save_dir, "loss_" + str(time_str))
logging = TensorBoard(log_dir)
loss_history = LossHistory(log_dir)
checkpoint = ModelCheckpoint(os.path.join(save_dir, "ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5"),
monitor = 'val_loss', save_weights_only = True, save_best_only = False, period = save_period)
checkpoint_last = ModelCheckpoint(os.path.join(save_dir, "last_epoch_weights.h5"),
monitor = 'val_loss', save_weights_only = True, save_best_only = False, period = 1)
checkpoint_best = ModelCheckpoint(os.path.join(save_dir, "best_epoch_weights.h5"),
monitor = 'val_loss', save_weights_only = True, save_best_only = True, period = 1)
early_stopping = EarlyStopping(monitor='val_loss', min_delta = 0, patience = 10, verbose = 1)
lr_scheduler = LearningRateScheduler(lr_scheduler_func, verbose = 1)
eval_callback = EvalCallback(model_body, input_shape, anchors, anchors_mask, class_names, num_classes, val_lines, log_dir, \
eval_flag=eval_flag, period=eval_period)
callbacks = [logging, loss_history, checkpoint, checkpoint_last, checkpoint_best, lr_scheduler, eval_callback]
if start_epoch < end_epoch:
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
model.fit(
x = train_dataloader,
steps_per_epoch = epoch_step,
validation_data = val_dataloader,
validation_steps = epoch_step_val,
epochs = end_epoch,
initial_epoch = start_epoch,
use_multiprocessing = True if num_workers > 1 else False,
workers = num_workers,
callbacks = callbacks
)
self.pyoutput(feature)
def close(self):
"""This method is called once all the FME Features have been processed
from input().
"""
pass
def process_group(self):
"""When 'Group By' attribute(s) are specified, this method is called
once all the FME Features in a current group have been sent to input().
FME Features sent to input() should generally be cached for group-by
processing in this method when knowledge of all Features is required.
The resulting Feature(s) from the group-by processing should be emitted
through self.pyoutput().
FME will continue calling input() a number of times followed
by process_group() for each 'Group By' attribute, so this
implementation should reset any class members for the next group.
"""
pass
开始训练

训练需要注意几个事项,首先是需要加载主干网络预训练权重,然后是训练50个epoch后,冻结模型部分层继续训练,使得模型能更加匹配数据。
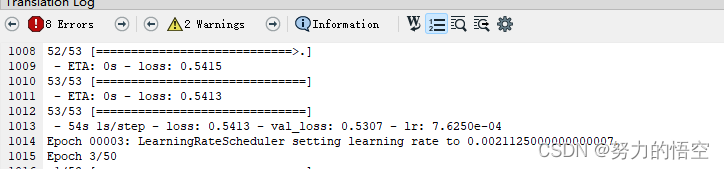
5.刷图逻辑编写
这里我们需要自己做两个类,一个键鼠控制类,一个是人物行为类。以下是部分类代码
def get_thing(yolo_list):
door_list = []
guai_list = []
wuping_list = []
person_xy = []
if len(yolo_list) != 0:
# 解析当前状态
for i in yolo_list:
if i["label"] == str("i"):
# 获取人物所在屏幕真实坐标点
person_x = (i["right"] + i["left"]) / 2
person_y = i["bottom"]
person_xy.append(person_x)
person_xy.append(person_y)
if "door" in str(i["label"]):
# 获取门所在真实坐标点
door_x = (i["right"] + i["left"]) / 2
door_y = i["bottom"] - 10
door_list.append([door_x, door_y])
if "guai" in str(i["label"]):
# 获取门所在真实坐标点
guai_x = (i["right"] + i["left"]) / 2
guai_y = i["bottom"] - 30
guai_list.append([guai_x, guai_y])
if "wuping" in str(i["label"]):
# 获取物品所在真实坐标点
wuping_x = (i["right"] + i["left"]) / 2
wuping_y = i["bottom"] + 33
wuping_list.append([wuping_x, wuping_y])
return person_xy,door_list,guai_list,wuping_list
def recognize(img):
ocr = ddddocr.DdddOcr()
res = ocr.classification(img)
return res
class Action(object):
"""
-------------------------------------------------------------------------
该类为dnf人物角色动作类,目前适配大部分职业
-------------------------------------------------------------------------
"""
def __init__(self, dnf_win_box,speed):
self.dnf_win_box = dnf_win_box
self.speed = speed
self.skill_button = ["q", "w", "e", "r", "t", "y", "a", "s", "d", "f", "h", "ctrl","alt"]
pass
def buff(self):
"""添加角色buff,默认右右空格,上上空格,上下空格,左右空格都按一遍"""
pydirectinput.press(['right','right','space'])
pydirectinput.press(['up', 'up', 'space'])
#pydirectinput.press(['right', 'right', 'space'])
pydirectinput.press(['down', 'down', 'space'])
pydirectinput.press(['left', 'right', 'z'])
pass
def move_to_wuping(self,target_xy,person_xy):
"""输入目标坐标,人物会移动到该坐标"""
speed=self.speed
target_x=target_xy[0]
target_y = target_xy[1]
person_x = person_xy[0]
person_y = person_xy[1]
if target_x - person_x > 30:
x_button_name = "right"
time1 = abs(target_x - person_x) / (400*speed)
pydirectinput.keyDown(x_button_name)
time.sleep(time1)
pydirectinput.keyUp(x_button_name)
elif target_x - person_x < -30:
x_button_name = "le然后就是角色cd判定机制,为了能匹配所有职业,我选择再做一个轻量级的ai神经网络来干这个事情。
截取各种角色的技能图标作为训练集
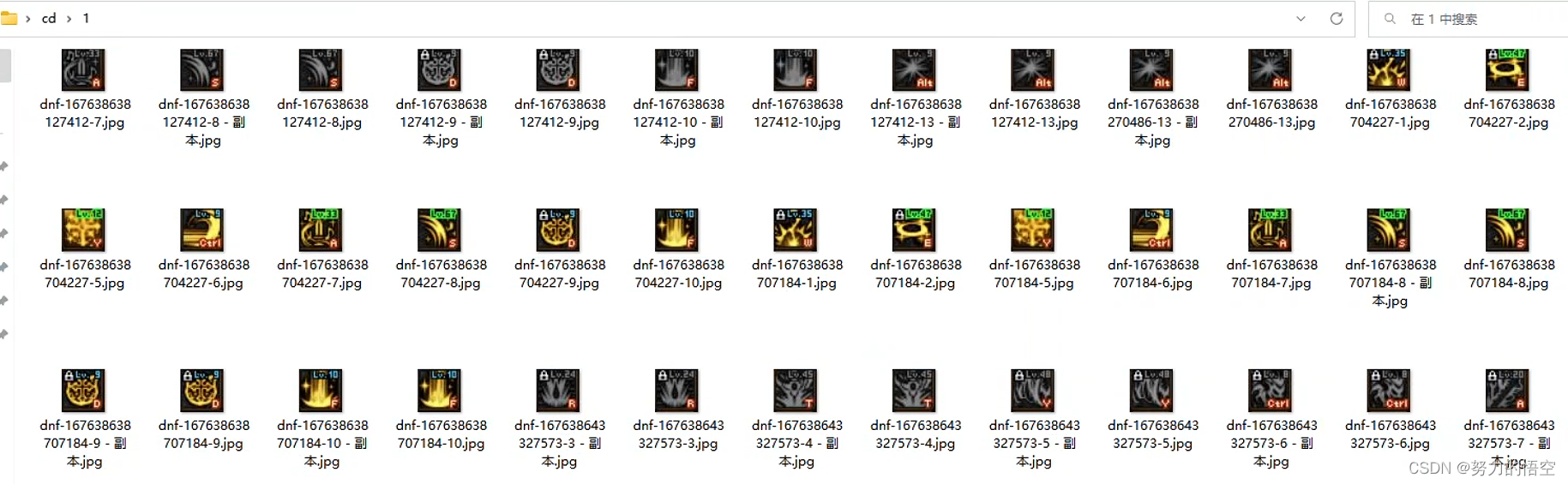
搭建轻量级网络进行模型训练

然后写一个技能判断的类,完成技能自动识别
def getcdpic(img,model):
h=47
next_img = img.crop((649, 796, 977, 895))
buttonlist1=["q","w","e","r","t","y","ctrl"]
buttonlist2=["a","s","d","f","g","h","alt"]
new_buttonlist=[]
for i in range(14):
if i <=6:
aa=next_img.crop((0+(i*h),0,h+(i*h),h))
b= havecd(aa,model)
if b == 1:
new_buttonlist.append(buttonlist1[i])
else:
i=i-7
aa=next_img.crop((0+(i*h),h,h+(i*h),h*2))
b= havecd(aa,model)
if b == 1:
new_buttonlist.append(buttonlist2[i])
return new_buttonlist最后就是整体的刷图逻辑,包括过图,角色切换等



通过FME多层循环,来保证整体的流程控制,最终实现只需要输入,刷图的角色数量,即可完成搬砖自动化
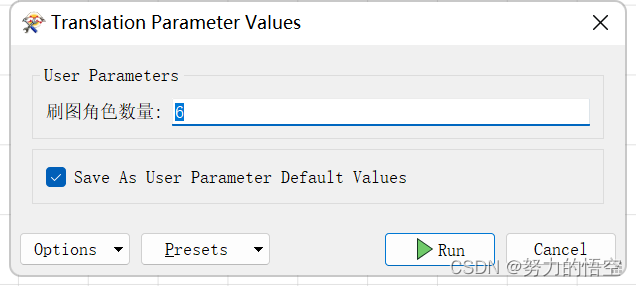
总结
该研究仅为个人学习研究使用,主要为展示FME在深度学习领域的作用。代码只展示部分,不接受任何形式的购买行为。前前后后用空闲时间折腾了几个月,算是完成了一个有趣的课题研究。yolo真的是一个非常牛逼的算法,最近才推出了yolov8,性能和精度都获得了较大提升。

![【开发规范】go项目开发中的[流程,git,代码,目录,微服务仓库管理,静态检查]](https://img-blog.csdnimg.cn/e3ed8135e2e14fa58027c416b942ffce.png#pic_center)