一个多小时前刚发的论文,Composer: Creative and Controllable Image Synthesis with Composable Conditions。 我读完了快速帮大家概要一下啊。论文地址见文章最后。
阿里巴巴团队开发的这个重磅图像生成模型 Compose,支持多重引导条件的图像生成(合成)(扩散模型)。跟 Stable Diffuison 属于同等级别的基础模型,但路线有差异。
核心特点是支持多重引导条件的图像合成。论文里 公布的引导条件包括 (caption) 文本 prompt、(sketch) 草稿、(palette )调色板、(depthmap) 深度图、(Instances) 形状图、(masking)蒙版图、(Intensity)灰度图,以及风格参考图。可以用多张输入图片作为多重条件同时引导,生成/重组为结果图片。你可以理解为是一种高级的图像 remix。
模型规模:5B 参数。虽然参数也不是决定因素。5B 参数 (虽然参数规模不一定能跟效果挂钩)。同类基础模型的比较,DALLE-2: 3.5B, Google Imagen: 4.6 B, Stable Diffusion 的第一个版本,不到1B 参数。
使用Composer可以创建与输入图像类似的变体,通过设置引导条件的组合,灵活控制图像如何变化。Compose 将图像分解为具有代表性的因素 (representative factors),以所有这些因素为条件,训练扩散模型,对输入图像进行重组。在推理阶段,这些丰富的 intermediate representations 作为重组的要素发挥作用。
从 论文里的Demo看,效果不错。
下面两张demo图,每一行6张是生成的结果图片,侧面小图是用珍珠耳环少女图转化而成的 input condition, 底部小图/文本是调色板、深度图、草稿这些引导条件。


用文本prompt引导的风格迁移

Remix,风格插值(Style Interpolations)


input image (最左边娃娃图)+ 不同 sketch 引导图的重组合成 (Reformulation)。最右边一张 跟 神奈川冲浪图sketch 的合成让我影响深刻,integration 很 makesense,不生硬。
4重引导条件 (shape + sketch + palette + pic)的合成结果

论文里提到了3种图像控制手段:1 插值 Interpolations(通过在两个图像的全局表示的嵌入空间中遍历,混合这两个图像以进行变异。Composer 能够精确控制在两个图像之间插值的要素以及需要保持不变的要素,产生多种插值方向),2 重构 Reconfigurations;3 ,指定可编辑区域 (蒙版),提供了强大的图像编辑\设计功能。
1. 图像插值 Interpolations 的demo。
第二行起,左边的小图是调色板、轮廓图等 引导条件,图中可见 加入引导条件后,对 第一行最左和最右两张图像remix 结果的影响。引导条件决定了remix 过程中的哪些图像要素得如何变化,哪些要素得到保留。

2. 图像重构 Reconfigurations 的 demo
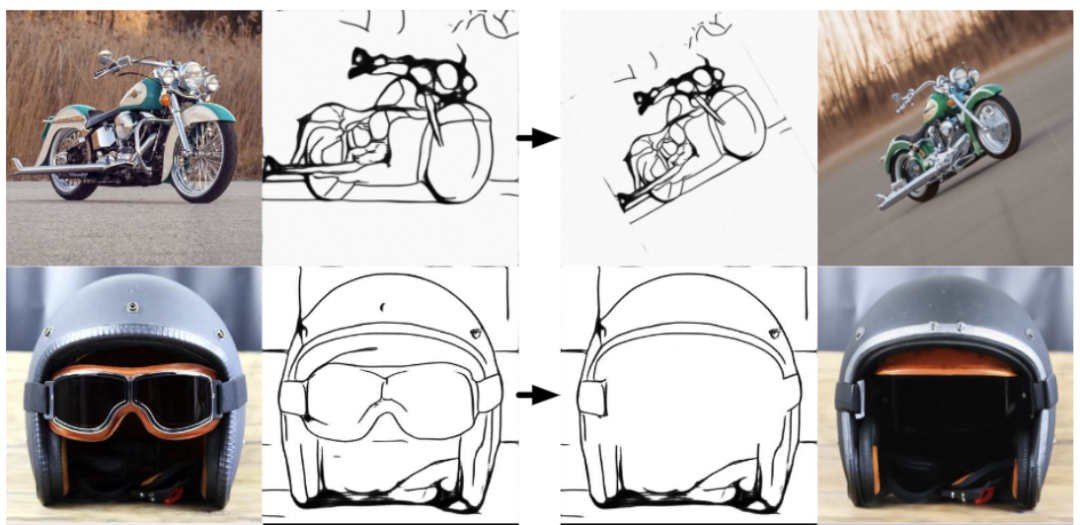
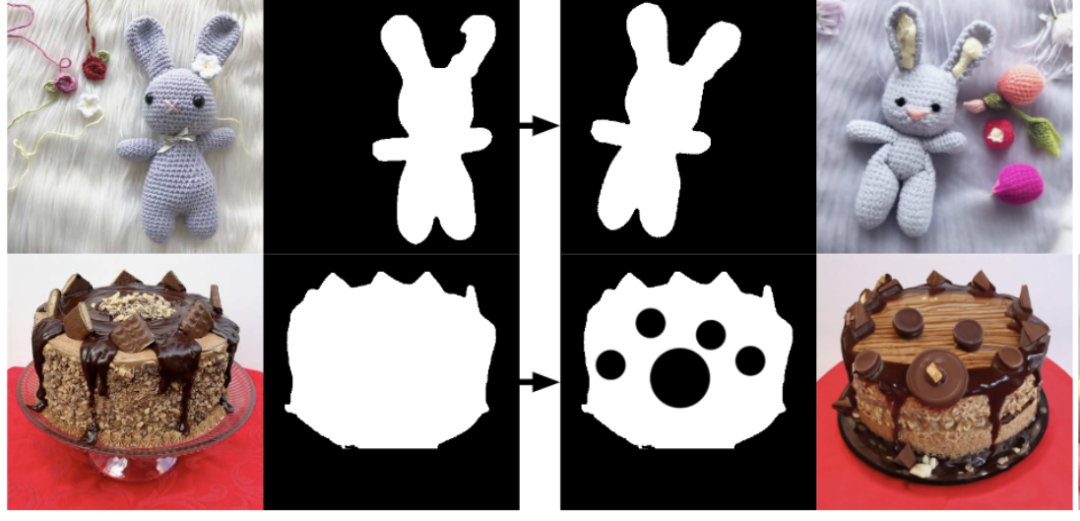
3. 可编辑区域 (蒙版)的 demo
上面一排是 用 text prompt 编辑 蒙版区域,下面一排是用 调色板 编辑 蒙版区域

差不多就这些了。项目的Github 上承诺会逐步放出 代码和预训模型、带GUI的 Gradio 应用,兼容 SD2.1 的轻型模型。
从设计feature和 Demo的效果看,我个人感觉 Composer 会在消费级应用上更有竞争力,对普通人使用门槛更低,应用场景更广泛。
祝这个行业越来越卷 

 !
!
Github: https://github.com/damo-vilab/composer
Paper: arxiv.org/abs/2302.09778
Project page: damo-vilab.github.io/composer-page/
我刚刚发布了 AIGC 艺术家样式库 lib.KALOS.art 。4人小团队前后忙了4周。
- 目前全球规模最大,1300+艺术家共3万余张 4v1 样式图片,
- 覆盖三个主流图像生成模型
- 为每个艺术家都生成了8~11种常见主题,如 人像、风景、科幻、街景、动物、花卉等主题




艺术家和多种主题的结合,会带来很多意想不到的结果
后现代舞台设计师去画废土科幻场景?or 立体主义雕塑家去画一张猫咪?
按人类惯有思维,用肖像画家去生成肖像,用风景画家去生成风景,其实限制了AI模型的创作力和可能性。希望 lib.kalos.art能帮你发掘AIGC的潜力,得到更多创作灵感


点击阅读原文,访问最新最全的 AIGC 艺术样式数据库









![[计算机网络(第八版)]第一章 概述(章节测试/章节作业)](https://img-blog.csdnimg.cn/0ec19d23a64d488db1a2313c1c712f54.png)