作者:几冬雪来
时间:2023年2月25日
内容:数据结构顺序表内容讲解
目录
前言:
顺序表:
1.线性表:
2.什么是顺序表:
3.顺序表的概念和构成:
4.顺序表的书写:
1.创建文件:
2.顺序表的静态储存:
3.动态顺序表的书写:
4.数据结构的管理:
5.顺序表添加内容:
6.尾插:
7.扩容和尾部增加:
8.尾部删除:
9.代码:
结尾:
前言:
不知不觉中,我们将数据结构算法效率的空间复杂度和时间复杂度都进行了讲解,并且通过了举例来巩固我们的知识,那么在对我们的算法效率那部分内容进行了初步的讲解之后。接下来我们就要进入到我们数据结构中的一个知识——顺序表的的讲解了。

顺序表:
在我们的日常生活中,我们的顺序表是什么不可或缺的东西,平时我们所使用的QQ和微信查找或者添加好友都与我们的顺序表有关,而为了我们以后的一些知识,现在在这里我们将先对顺序表进行一个认识。
1.线性表:
在讲解我们的顺序表之前,我们先来了解我们的线性表。那么线性表在我们的数据结构中是以什么样的形式存在的?这里我们就要知道,线性表是我们在实际中广泛使用的一种数据结构,我们常见的线性表有:顺序表,链表,栈,队列,字符串等等。
那么我们线性表的特征是什么?逻辑上来说,就是我们有n个数据,我们这n个顺序挨个挨个依次存储呈现出一条线性结构,这就是我们线性表的特征。

2.什么是顺序表:
在了解了我们线性表是什么之后,接下来我们就开始正式的讲解我们的顺序表了,那么还是我们熟悉的开头——什么是顺序表。
顺序表其实就是我们写一个结构,然后管理这个结构,而后这个结构对我们的数组进行管理。所以这里我们可以将我们的顺序表看为一个数组。
3.顺序表的概念和构成:
既然我们可以将我们的算术表当成一个数组,那么我们的顺序表的构成是怎么样的?

那么我们的顺序表的概念和构成讲解完了后,接下来我们就要开始动手书写我们的顺序表的代码了。
4.顺序表的书写:
这里我们顺序表的书写和结构和我当初写三子棋博客的结构比较相似。
1.创建文件:
首先就是我们需要创建我们的文件,也就是我们的.h文件和.c文件。相信大家如果是写过三子棋,或者是看过三子棋的博客,那么应该对我们这一步操作不会陌生。
在我们创建完了文件后,我们就要向我们的文件中书写内容。
2.顺序表的静态储存:
在我们的顺序表中我们对其进行了分类,分为了静态顺序表和动态顺序表。那么在学习我们动态顺序表怎么书写之前,我们用来试着定义一个静态顺序表。

这就是我们静态顺序表的大概书写,但是我们的这种静态顺序表在我们的实际中并不好用且不常用,为什么?因为在这里,我们的顺序表的个数是被写死的,没有办法进行扩容或者是缩小。因此在写顺序表的时候,我们经常将我们的顺序表写为动态顺序表。对比起我们的静态顺序表,我们的动态顺序表的优势就是可以按需申请。
3.动态顺序表的书写:
既然我们这里知道了对比起我们静态顺序表我们的动态顺序表有什么优势,那么接下来的操作就很简单了,那就是将我们的静态顺序表的形式改为动态顺序表。

这里我们将我们的数组换成一个指针,指针指向了我们某一块空间,而我们的这块空间又是在我们的堆区进行开辟的,为我们后来对其进行动态调整做铺垫。
这里有人就看见,对比我们的静态顺序表,我们的动态顺序表在这里再开辟了一个临时变量capacity,这是为什么呢?这是因为,在我们向后执行很多次代码之后,某个时刻我们的有效数据等于我们现阶段的空间的容量,满足这个条件这时我们就要对我们的空间进行扩容,因此我们的capacity就是指我们现阶段空间的容量,也是我们要进行扩容所要达成的条件。
4.数据结构的管理:
那么在对我们的动态顺序表进行了初步定义之后,接下来我们就要对我们这里的数据进行管理。那么我们是怎么进行管理的,这里还是以我们的QQ为例,我们数据结构管理的需求就是增删查改。
这里我们就在我们的.h文件中,创立增加和删除的函数。
接下来我们就要再在我们的SeqLish.c文件中将我们结构体中的数据进行初始化,那么怎么个初始化的方法? 这里我们有两种方式,我们先讲第一种方式。

第一种方法就是将我们,将我们所有的空间什么的都初始化为0。并且在我们的test.c中也开始书写我们增加空间的代码。
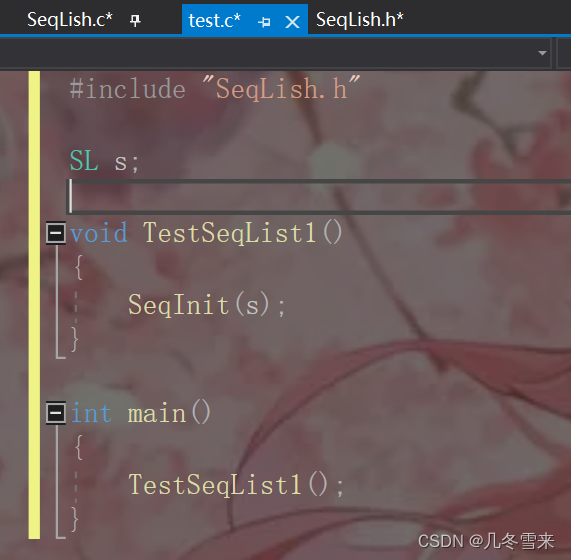
那么如果我们不想将空间都初始化为0,想一开始就给开辟一小块的空间来使用,那我们就可以改用另一种初始化的方式。那么我们这种方式是怎么书写的?


在这里我们就用到我们C语言进阶的动态内存开辟的知识了,利用我们的知识来对我们的顺序表进行一个初始化,给我们的顺序表开辟一块空间。但是如果你觉得这样写没有问题的话,那就放了一个低级错误,这里我们通过调试可以调试出来。

这里为什么我们下面进行了一系列的修改但是没有影响到上面的内容? 这里就是我们的最基本的知识,在我们的SeqInit函数中,我们进行的是传值调用。而众所周知,在进行传值调用的时候,我们的形参是实参的一份临时拷贝,形参的改变不影响实参。因此我们这里要对我们的代码进行修改。
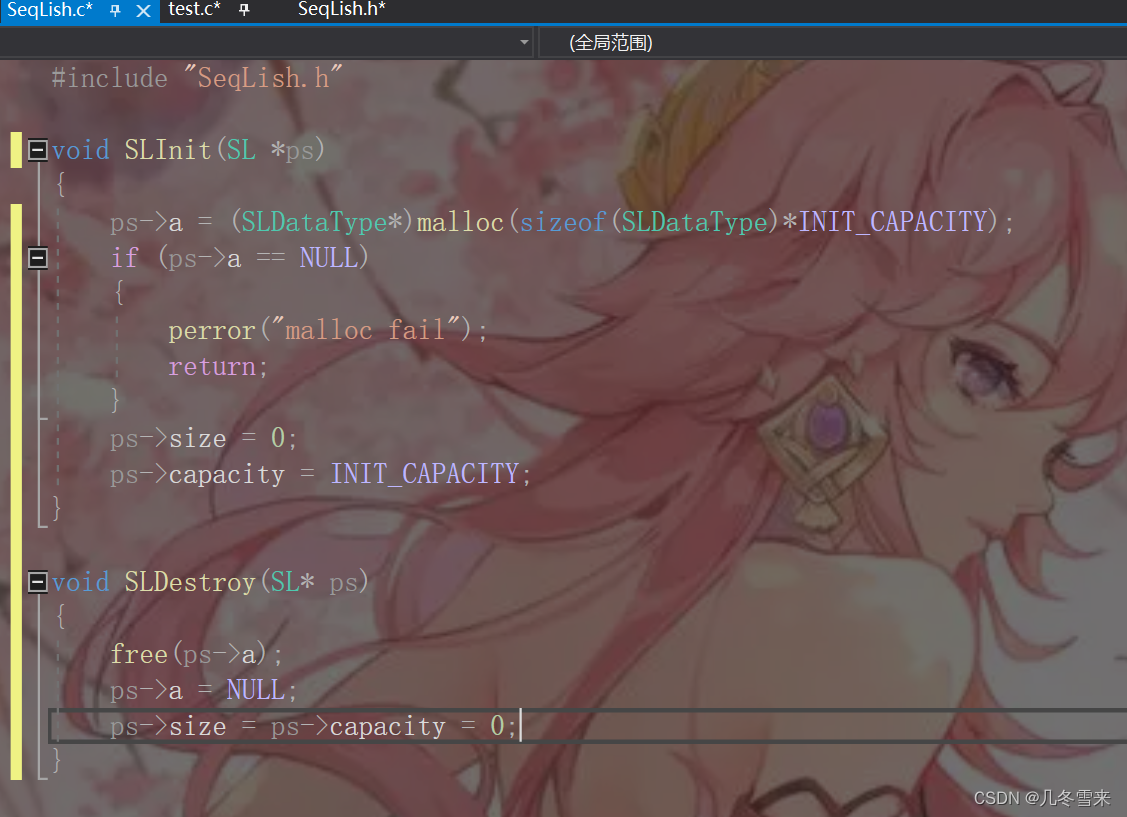

并且在开辟空间使用之后,我们要将开辟的那块空间进行一个释放的操作,因此在代码的结尾我们要进行free,然后再将我们的所有的空间进行归还。
5.顺序表添加内容:
在我们对顺序表进行了一个基础开辟空间操作的代码的编写,接下来依旧以我们的QQ或者微信为例。假如我们建立了一个有关C语言的群,在某一天我们刚刚好遇到了一个有共同爱好的人,这个时候我们就可以把他拉到我们的群里面,而我们这个新加入群的人我们在列表的最后就能找到他。但是这里有人可能反馈每次都要拉到最后面才能找到这个人太过麻烦,我们想将这个人放在前面也是允许的。

这里的数据的插入方式就类似我们顺序表中的两种插入数据的方法,一种是从头部插入被我们简称为头插,而另一种正好相反,这种方法是从尾部插入的,也被我们简称为尾插。既然知道了这两种插入方法,那么接下来我们就应该先在代码中创建这两种插入方法的函数。那么有插入,也就有删除,插入的方法有两种,我们删除的方法也有两种,就是我们所谓的头删和尾删。

在这里我们先将函数写出来后,再对其里面的内容进行进一步的编写。首先我们就先对我们尾插数据的方式写出来。
6.尾插:
相对于顺序表头插,尾插的方式就相对比较简单一点,所以在这里我们就先将我们顺序表如何尾插写出来。

在个编程中,假设我们size的大小为5,我们capacity的大小为9。这个时候我们进行尾插程序,当我们的size作为下标的时候,size并不是我们最后一个数据的下标,所以这里我们的size是我们最后一个数据的下一个位置。

那么在这里我们应该如何尾插我们所需要的值?很简单,这里我会将我们的代码写出来并对其进行分析。
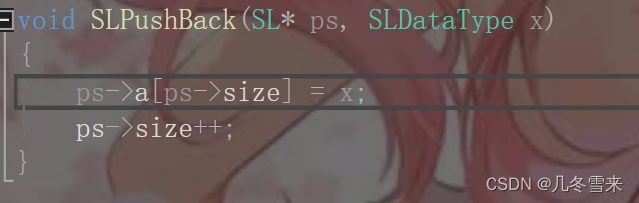
这里我们知道我们的变量a是指针所指向的一块空间,相对于我们今天顺序表中的数组,我们的size又是一个常量,因此这段代码的意思相对于是,我们将x的值赋给我们下标为size(5)的位置,在赋值结束之后对size进行后置++,使其指向我们下一个地址。

到这里我们的尾插的运行原理就基本结束了。但是在往往插入的过程中就有一些事情会发生,假如到这里程序并没有结束,我们想继续向后面插入我们的值会怎么样?
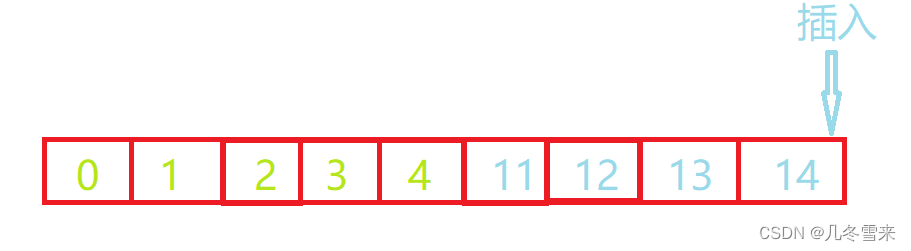
当我们插入到我们size的值和capacity的值相等的时候,这里就不能继续往后插入了,如果我们不听劝阻执意要进行插入操作,那么后面插入的值就会发生越界。 在这个时候我们就要对这块空间进行一个扩容的操作来使得我们后面的值可以继续插入。
7.扩容和尾部增加:
那什么时候要进行扩容的操作,就是当size的值和capacity的值相等的时候,我们就要对其空间扩容,因此在插入值之前我们需要对代码进行检查。
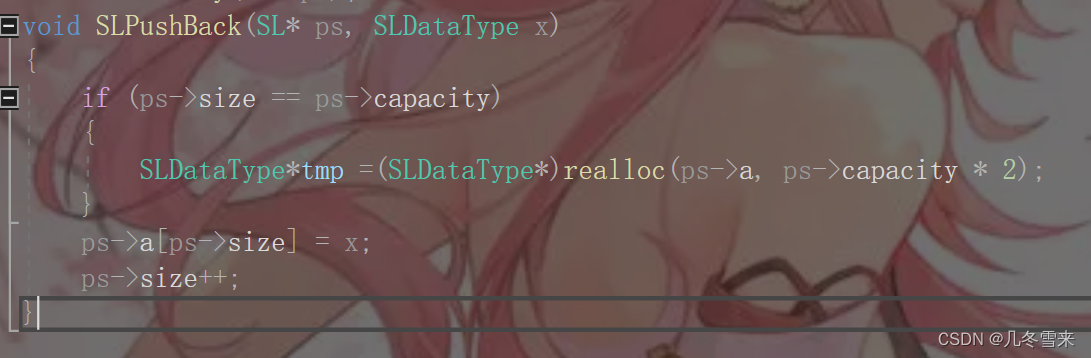
但是在对空间进行扩容的过程中,我们也可能出现扩容失败的情况。而在动态内存开辟那里可以得知,如果空间扩容失败的话就会返回一个空指针,因此我们也要对开辟失败的情况进行判断。接下来就是对代码的修改。

这里如果开辟失败程序就会报错,但是如果开辟成功了的话,我们要再在后面将我们capacity的值乘等于2,这样size的值才会和capacity的值不相等才能继续进行插入数据。
但是在这里我们的代码还是有些坑的存在。我们在这里将我们的顺序表进行打印一下。



这里我们将的代码执行一下,看看结果是什么?

可以看出来,这里输出的结果和我们预期输出的结果是一致的,那怎么说这里的代码有问题呢?是哪里出了问题?我们再在这个代码的后面再插入一个数据。

这里奇怪的事情就发生了,本应该存放3值的空间,现在却是放的一个随机值。这里通过调试我们可以查找出是在free的时候出来了问题。 而一般我们的free出现问题分为两种情况:
第一种情况就是我们free的指针是野指针,或者是我们free只是释放我们空间的一部分,并没有从起始位置释放。
接下来是第二种情况,这种情况不多。这里可能是数组指向的空间可能存在越界行为。
既然可能是越界访问,那么首先查找的就是我们的下标有没有越界,这是大家都懂的知识。可是很遗憾的是,我们这一个代码并没有下标越界的行为,而且我们本身开辟的空间也没有问题,那这里就剩下realloc对我们空间扩容的时候可能出现问题,我们这里空间开辟少了。

在上面看出来,我们一共要输入5个整形,一共需要20个字节的空间,但是这里我们的capacity的大小为4个字节的大小。但是这里realloc扩容的大小却不是20个字节,这里的realloc只是将空间从4个字节扩容到8个字节。 因此我们后面的值都属于越界访问。

这便是我们修改后的代码,这里空间的大小就为32个字节的大小,存放20个字节的数据绰绰有余。 代码修好之后再运行一次来看看结果是什么?

这个时候我们的3的位置并没有变成一个随机值,这就证明我们代码修改正确,程序可以正常运行起来。
8.尾部删除:
在上面我们学习了向我们这块空间插入一个数据的方式是如何运行的,也就是顺序表管理中的增删查改中的增。那么既然有增,那也就是有删,在顺序表中应该如何去删除数据?
这里介绍的方法是我们的尾删。我们要删除我们的数据很简单,我们将代码写出来。

在这里我们将我们下标为size-1的空间赋值为0,然后size再进行--的操作,这样就可以将我们最后的数据进行删除。

这里就可以把我们数据中后面两个值进行删除,但是这里有人就要说了:如果在进行数据删除的时候,下标是size-1的地址的值要是一开始存放的值就是0的话,这里的代码是不是就多此一举了?这一点我们不可否置,那来试试删掉了我们的代码会怎么样?


通过尝试,我们发现这段代码其实有和没有并无太大区别,即使没有这段代码都可以运行且运行之后不会报错或者有哪里出错的地方, 所以我们可以将它删去也没有关系。因为我们这里是按照size去遍历的,我们这里size就是我们的有效数据,我们从开始连续存储size个数据。
但是我们这里要注意一个点,这里删除的这块空间并不能单独使用free函数释放掉,我们在堆上申请数组,我们要释放就应该一起释放,不能一块一块的释放,这样做的话代码会报错。

写到这里我们顺序表的删除部分也就全部写完了吗?并不是的,在这个代码删除过程中,size不断的进行--的操作,不断的将空间的数据进行删除直到删空为止。
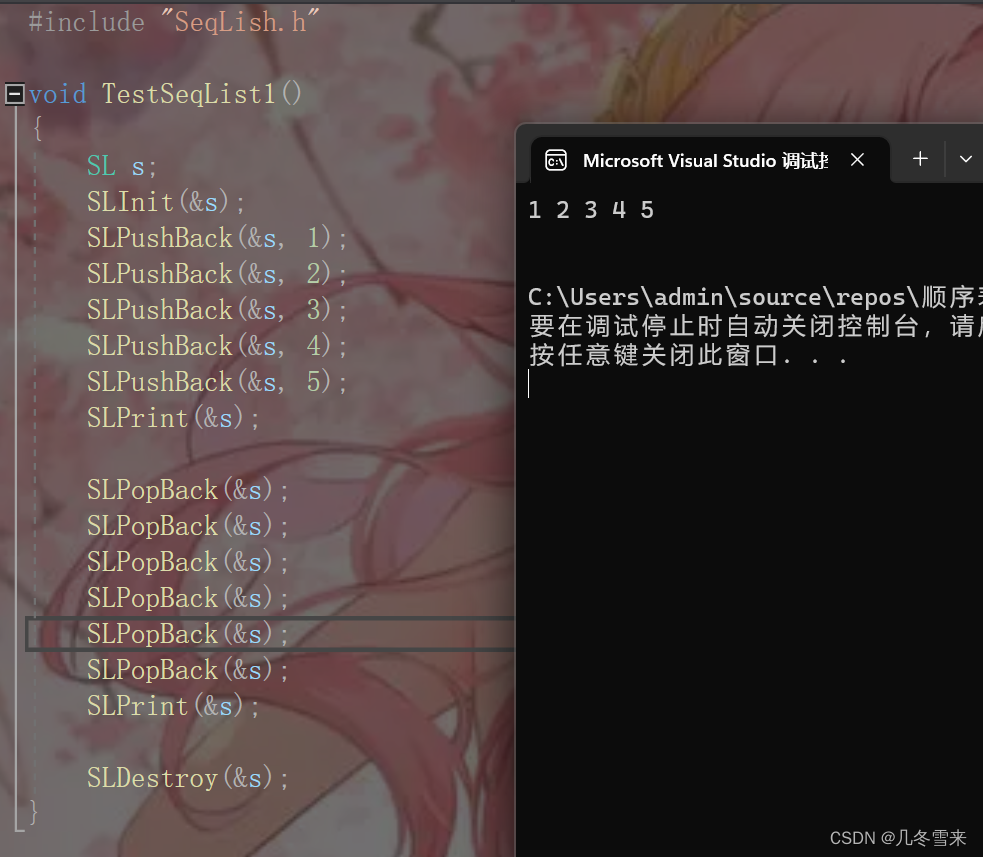
从图片来看,这里空间的所有数据均已被删除,且我们的编译器将我们的结果打印了出来?目前为止一切正常,但是如果在进行完数据的删除之后,我们又想再次插入数据,这里这么做会发生什么事情?

这里不难看出代码报错了,那么为什么会报错?这就需要我们调试一下了。

这里就能看出一个问题,我们size的值本不应该小于0的,当size等于0的时候我们这里的空间已经为空,不能再进行--的操作。 因此,在我们删除数据的函数中还要加入一个判断语句来判断我们的条件或者对size进行断言。

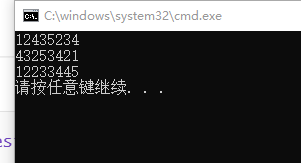
对代码进行修改之后,我们重新执行我们的代码看看这次输出的结果有什么不同的地方。

从图中可以看出,需要新插入的两个值成功的插入了这块空间中,并没有像第一次插入的时候报错。 如果这里将我们的判断代码换为断言代码的话,虽然无法正常的输出,但是会标识出来哪里错误。

出错的地方在我们的SeqLish.c文件中的第34行,正好也是我们断言的行数。 在这里的最后再对我们realloc函数那里进行细微的修改。
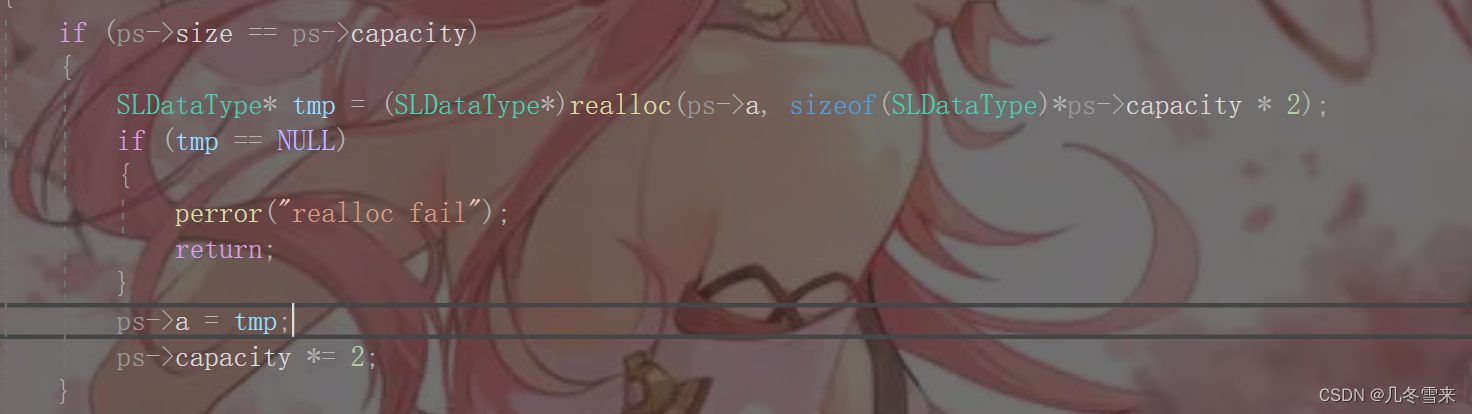
将我们这里的tmp交给我们的a指针维护,这个知识点在动态内存开辟的讲解中也有提到过,有兴趣的可以去了解一下为什么。
到这里我们一个顺序表的头插,创建,尾插,初始化都实现了。下面是我们的代码:
9.代码:
SeqLish.c文件
#include "SeqLish.h"
void SLInit(SL *ps)
{
ps->a = (SLDataType*)malloc(sizeof(SLDataType)*INIT_CAPACITY);
if (ps->a == NULL)
{
perror("malloc fail");
return;
}
ps->size = 0;
ps->capacity = INIT_CAPACITY;
}
void SLDestroy(SL* ps)
{
free(ps->a);
ps->a = NULL;
ps->size = ps->capacity = 0;
}
void SLPrint(SL* ps)
{
for (int i = 0; i < ps->size; ++i)
{
printf("%d ", ps->a[i]);
}
printf("\n");
}
void SLPopBack(SL* ps)
{
//断言
/*assert(ps->size > 0);*/
//判断
if (ps->size == 0)
{
return;
}
/*ps->a[ps->size - 1] = 0;*/
ps->size--;
}
void SLPushBack(SL* ps, SLDataType x)
{
if (ps->size == ps->capacity)
{
SLDataType* tmp = (SLDataType*)realloc(ps->a, sizeof(SLDataType)*ps->capacity * 2);
if (tmp == NULL)
{
perror("realloc fail");
return;
}
ps->a = tmp;
ps->capacity *= 2;
}
ps->a[ps->size] = x;
ps->size++;
}SeqLish.h文件
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
typedef int SLDataType;
#define N 10
#define INIT_CAPACITY 4
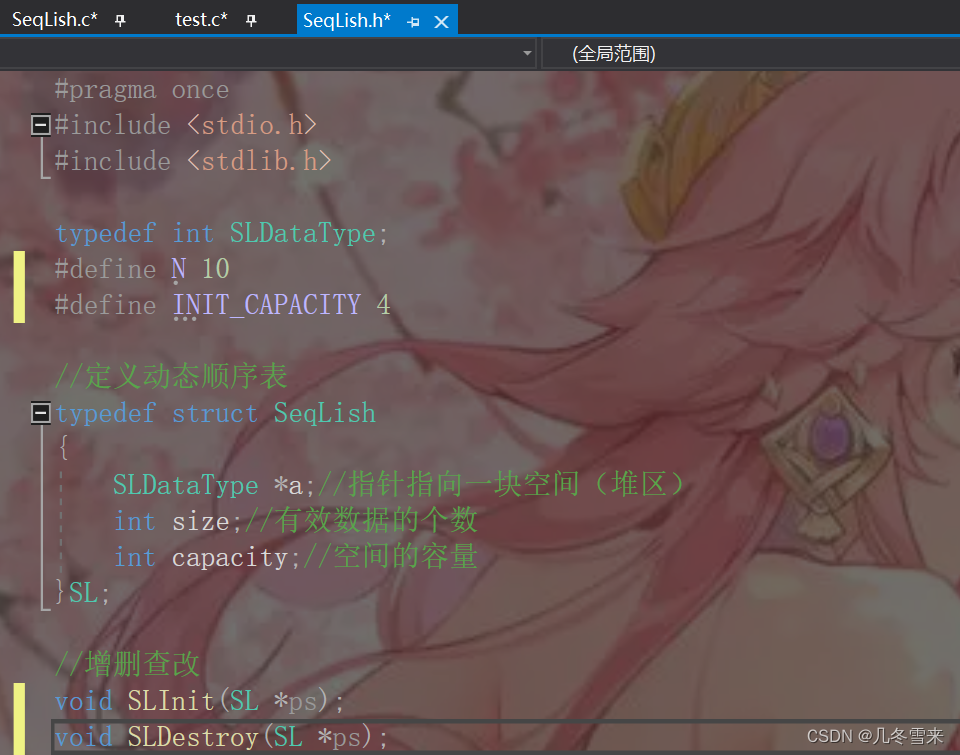
//定义动态顺序表
typedef struct SeqLish
{
SLDataType *a;//指针指向一块空间(堆区)
int size;//有效数据的个数
int capacity;//空间的容量
}SL;
//增删查改
void SLInit(SL *ps);
void SLDestroy(SL *ps);
void SLPrint(SL* ps);
void SLPushBack(SL* ps, SLDataType x);
void SLPopBack(SL* ps);
void SLPushFront(SL* ps, SLDataType x);
void SLPopFront(SL* ps);test.c文件
#include "SeqLish.h"
void TestSeqList1()
{
SL s;
SLInit(&s);
SLPushBack(&s, 1);
SLPushBack(&s, 2);
SLPushBack(&s, 3);
SLPushBack(&s, 4);
SLPushBack(&s, 5);
SLPrint(&s);
SLPopBack(&s);
SLPopBack(&s);
SLPopBack(&s);
SLPopBack(&s);
SLPopBack(&s);
SLPopBack(&s);
SLPrint(&s);
SLPushBack(&s, 10);
SLPushBack(&s, 20);
SLPrint(&s);
SLDestroy(&s);
}
int main()
{
TestSeqList1();
return 0;
}这就是我们现阶段,还不成熟的顺序表的所有代码了。
结尾:
这篇博客我们实现了对我们顺序表的一部分内容的书写,比如初始化,尾插尾删等等,也讲解了一些可能出现的坑,但是正如我们所说,顺序表的内存管理是有增删查改在几种功能的,而且在本篇博客中也引入了我们另一种插入和删除方法——头插头删。这些残缺的内容,我们都将放在下一篇博客中实现,同时希望这篇顺序表的博客能为大家提供帮助。