一 说明
当我们的训练数据非常多,并且还在不断增加时,每次都用全量训练,数据过多,时间过长,此时就可以使用增量训练:用新增的数据微调校正模型。
二 全量与增量的差异
在使用增量训练时,最关心的问题是:全量和增量的差别,从而确定增量训练的使用场景。
假设有200条数据
第一次训练150条,第二次训练50条,
直接用200条训练
差异在于:在第二次训练50条时,前150条数据已经不存在了,模型更拟合于后面的数据。如果我们定期增量训练,那么离当前时间越近的数据对模型影响越大,这也是我们想要的结果。但如果最后一批数据质量非常差,就可能覆盖之前的正确实例的训练结果,把模型带偏。
同理,如果我们按时间把数据分成几部分,然后按从早到晚的顺序多次训练模型,每个模型在上一个模型基础上训练,也间接地参加了后期实例的权重。
XGBoost提供两种增量训练的方式,
一种是在当前迭代树的基础上增加新树,原树不变;
一种是当前迭代树结构不变,重新计算叶节点权重,同时也可增加新树。
对于已存在的决策树,早期训练的实例决定了模型的结构(选择哪些特征及分裂点),后期的实例决定最终的结果(叶节点的权重和新加入的树)。
综上,两个重点:第一,模型训练了一半,突然换了一批完全不同的数据继续训练,早期数据不再能再校正模型;第二,树一旦形成,结构就不再变化,后续的训练只能增加新树和重新计算前树的节点权重。
尽量用全量数据训练,如果数据太多,必须增量时,尽量保证增量数据的质量和数量(均匀分布),以免带偏模型。
三. 例子
import xgboost as xgb
from sklearn.datasets import load_digits # 训练数据
from sklearn.model_selection import train_test_split
X, y = load_digits(n_class=2, return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, shuffle=True, stratify=y,
random_state=100)
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
print("-+-" * 25)
params1 = {'tree_method': 'hist'}
model1 = xgb.train(params1, dtrain, num_boost_round=3) # 训练2棵树的模型
print(len(model1.get_dump()))
for leaf in model1.get_dump():
print(leaf)
print("-+-" * 25)
params2 = {'tree_method': 'hist'}
model2 = xgb.train(params2, dtest, num_boost_round=5, xgb_model=model1) # 在原模型基础上继续训练
print(len(model2.get_dump()))
for leaf in model2.get_dump():
print(leaf)
print("-+-" * 25)
##当前迭代树的结构不变,重新计算叶节点权重,
params3 = {'tree_method': 'hist'}
params3["updater"] = "refresh"
params3["process_type"] = "update"
params3["refresh_leaf"] = True
# 则3棵树结构不变,叶节点权重改变,最终结果一共3棵树
# 特别注意这里的num_boost_round <=原始模型的boost_nums 否则汇报错
model3 = xgb.train(params3, dtest, num_boost_round=3, xgb_model=model1) # 在原模型基础上继续训练
print(len(model3.get_dump()))
for leaf in model3.get_dump():
print(leaf)
import xgboost as xgb
from sklearn.datasets import load_digits # 训练数据
from sklearn.model_selection import train_test_split
X, y = load_digits(n_class=2, return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, shuffle=True, stratify=y,
random_state=100)
# dtrain = xgb.DMatrix(X_train, label=y_train)
# dtest = xgb.DMatrix(X_test, label=y_test)
print("-+-" * 25)
params1 = {'tree_method': 'hist', "n_estimators": 3}
model1 = xgb.XGBClassifier(**params1)
model1.fit(X_train, y_train)
print(len(model1.get_booster().get_dump()))
for leaf in model1.get_booster().get_dump():
print(leaf)
print("-+-" * 25)
params2 = {'tree_method': 'hist', "n_estimators": 3}
model2 = xgb.XGBClassifier(**params2)
model2.fit(X_test, y_test, xgb_model=model1.get_booster())
print(len(model2.get_booster().get_dump()))
for leaf in model2.get_booster().get_dump():
print(leaf)
print("-+-" * 25)
params3 = {'tree_method': 'hist', "n_estimators": 3}
params3["updater"] = "refresh"
params3["process_type"] = "update"
params3["refresh_leaf"] = True
# 则3棵树结构不变,叶节点权重改变,最终结果一共3棵树
# 特别注意这里的num_boost_round <=原始模型的boost_nums 否则汇报错
model3 = xgb.XGBClassifier(**params3)
model3.fit(X_test, y_test, xgb_model=model1.get_booster())
print(len(model3.get_booster().get_dump()))
for leaf in model3.get_booster().get_dump():
print(leaf)
四. 分析
训练函数train()中有个参数xgb_model,可填写旧模型路径,或者模型指针,指定该参数后,新模型在旧模型的基础上训练。
从代码上看,增量训练的逻辑主要在python层面,和普通的训练模型比,只是在c++底层实现了用旧模型填充learner,而非初始化learner。
回想一下前篇讨论过的训练过程:代入实例预测->对比预测结果和实际结果差异(误差函数)及误差方向(误差函数导数)->添加新决策树改进模型。继续训练也是如此。
从上面代码的输出结果可以看到
第一次dump的决策树是3棵,
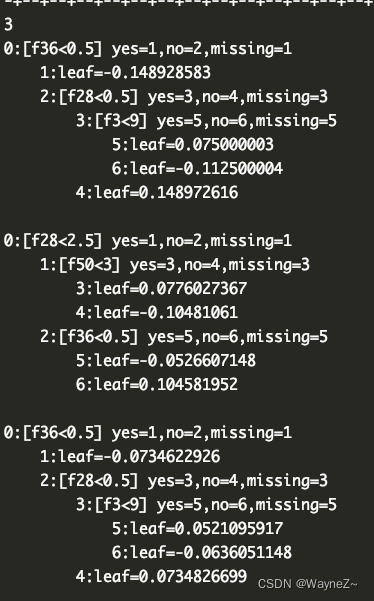
第二次dump出8棵(第一次3棵加第二次5棵)其中的前3棵与之前完全一样。就是说增量训练后,原来模型中的所有树都没变,只是在后面追加了更多的树。
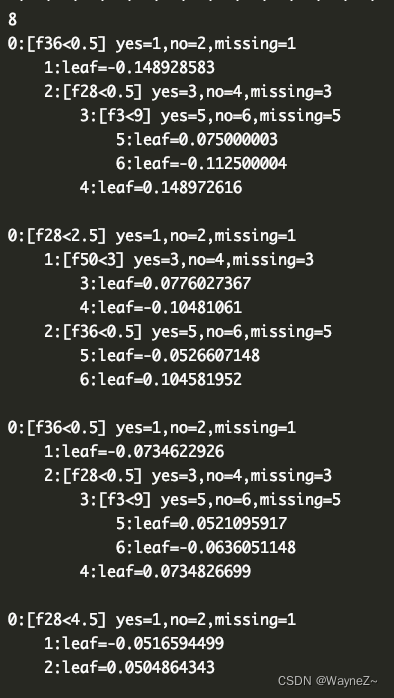
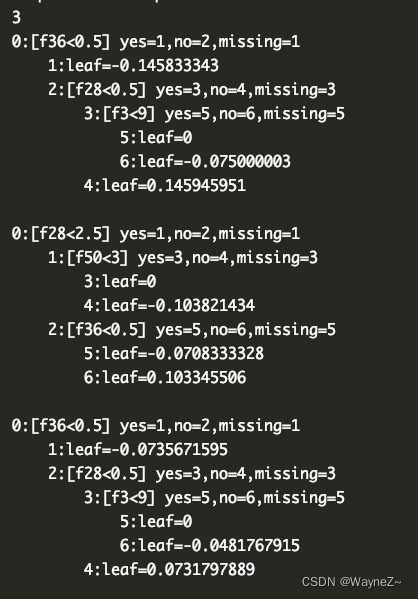
第三次dump出3棵,3棵树结构不变,叶节点权重改变
五 多任务训练
老板说要这个模型对A这个目标有区分度但是你对B的区分度也得有(一个模型要A标签上效果不错,同时也要在B标签上有不错效果)
总体来说通过两阶段任务的学习获得了两个任务的适应性
2. 第2阶段的模型可能损失另外主任务的区分度(相当于预测A目标效果会下降,可接受范围內,但是预测B目标效果会提高)
对于不同的样本空间的学习任务也提供了一种方式来进行训练,对于相近或相似任务可能存在提升(待验证)
https://zhuanlan.zhihu.com/p/320010888