JDK 17
Dubbo 3.1.6
JDK SPI
JDK SPI在sql驱动类加载、以及slf4j日志实现加载方面有具体实现。
示例
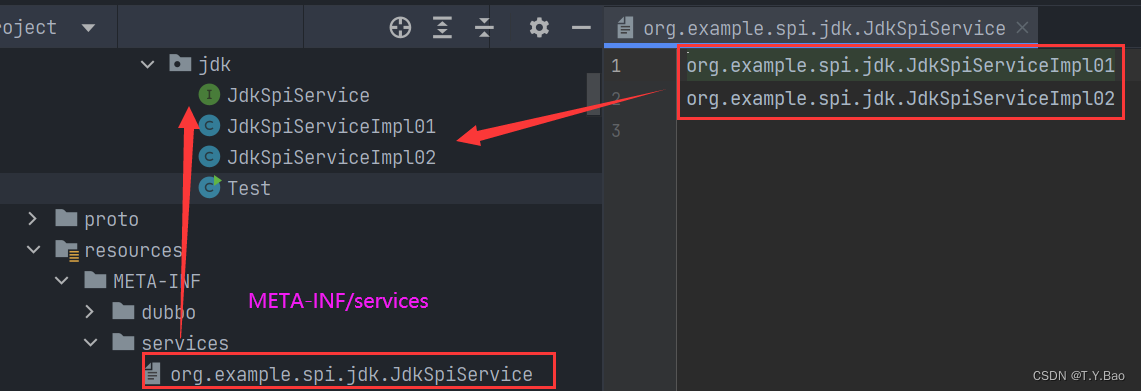
public class Test {
private static final Logger logger = LoggerFactory.getLogger(Test.class);
public static void main(String[] args) {
ServiceLoader<JdkSpiService> services = ServiceLoader.load(JdkSpiService.class);
Set<JdkSpiService> jdkSpiServices = services.stream().map(ServiceLoader.Provider::get).collect(Collectors.toSet());
// for (JdkSpiService service : services) {
// logger.info(service.test());
// }
}
}
ServiceLoader
由ServiceLoader提供,该类实现了Iterable接口,懒加载SPI实现类,所以加载逻辑都封装在内部迭代器类LazyClassPathLookupIterator implements Iterator里,当迭代器迭代时,会调用#hasNext,此时会调用#hasNextService 该方法又会调用#nextProviderClass加载SPI类:
public final class ServiceLoader<S>
implements Iterable<S>
{
private final class LazyClassPathLookupIterator<T>
implements Iterator<Provider<T>>
{
static final String PREFIX = "META-INF/services/";
// 将相对路径变为绝对路径存储,存储多个SPI接口文件
Enumeration<URL> configs;
// 每个SPI文件中的实现类全类名
Iterator<String> pending;
/**
* Loads and returns the next provider class.
*/
private Class<?> nextProviderClass() {
// 首次获取spi实现类,会先从META-INF/services/接口全类名中读取所有的记录到configs中
if (configs == null) {
try {
// 相对路径名 Reference Path
String fullName = PREFIX + service.getName();
// ********************************************************
// 需要通过类加载器加载资源,下面根据类加载器类型加载fullName资源
// ********************************************************
if (loader == null) {
configs = ClassLoader.getSystemResources(fullName);
} else if (loader == ClassLoaders.platformClassLoader()) {
...
} else {
// 一般走这里
// 一般为线程上下文类加载器
configs = loader.getResources(fullName);
}
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
// 第一次为null进入,或者已经执行完毕没有了再进入
// 迭代同一个接口文件中的内容时,该while不会进入
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return null;
}
// 解析一个接口文件中所有的实现类全类名
// URLConnection uc = URL#openConnection;
// InputStream in = uc.getInputStream();
// BufferedReader r = new BufferedReader(new InputStreamReader(in, UTF_8.INSTANCE))
pending = parse(configs.nextElement());
}
// 下一个实现类名
String cn = pending.next();
try {
// 反射实现类加载
return Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service, "Provider " + cn + " not found");
return null;
}
}
}
}
关于sql的SPI中使用了
AccessController#doPrivileged,可以参考AccessController usage。简单来说,就是在SecurityManger中指定了某个jar包的security policy,当该jar包中的方法a调用如System.getProperty()方法时,如果没有包裹doPrivileged,会检查方法a调用栈中所有方法是否都被授予权限。而包裹了doPrivileged,只会检查当前方法a的权限。
不过该AccessController和SecurityManager在 Java 17后即将被移除,且无替代。参见 Class AccessController,关于为什么移除,参见 JEP 411: Deprecate the Security Manager for Removal,简单来说就是SecurityManager解决的两个问题已经不是问题,但是维护它却很费力且性能低。
Dubbo SPI
示例
Dubbo SPI 导入格式:
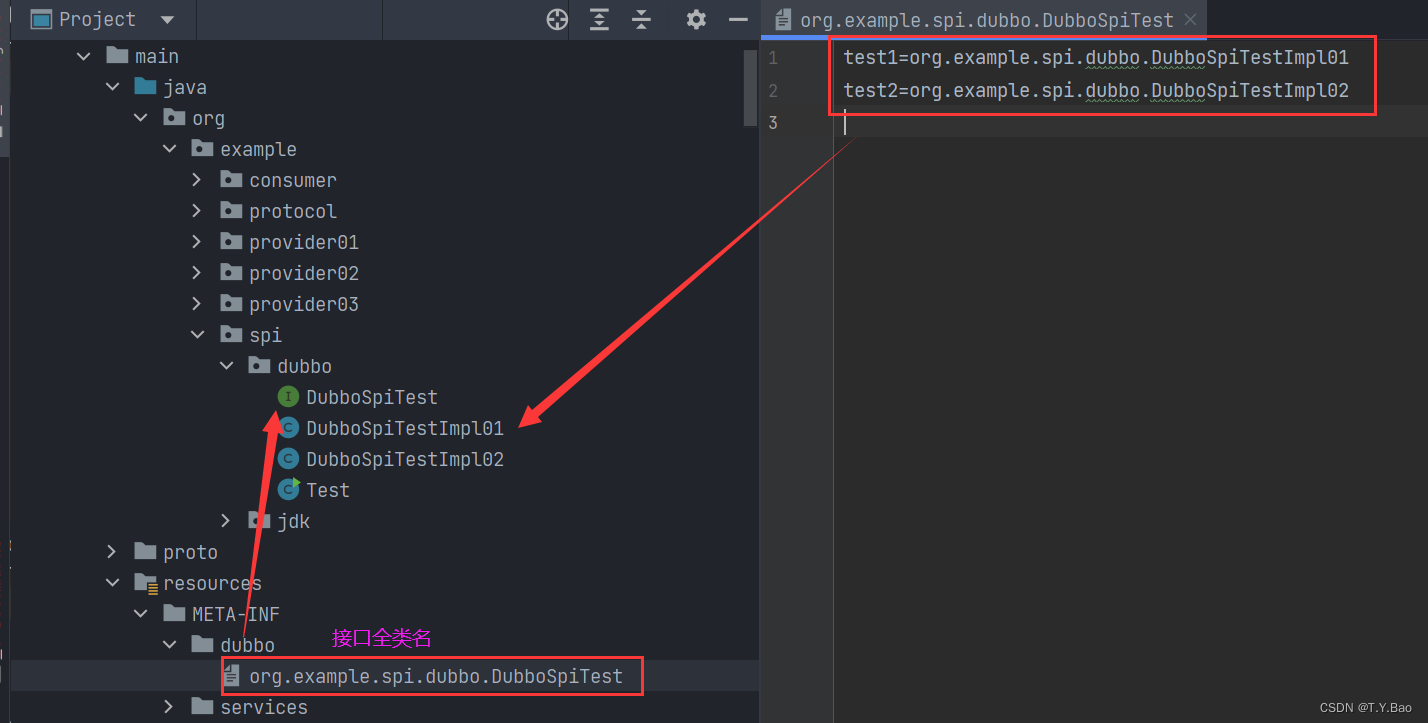
public class Test {
public static void main(String[] args) {
// 这里的几个方法都会检查传入的是否是接口以及是否标注@SPI
ExtensionLoader<DubboSpiTest> extensionLoader =
ApplicationModel.defaultModel()
.getExtensionDirector()
.getExtensionLoader(DubboSpiTest.class);
DubboSpiTest test1 = extensionLoader.getExtension("test1");
DubboSpiTest test2 = extensionLoader.getExtension("test2");
}
}
JDK SPI对应了一个ServiceLoader类,同样Dubbo SPI对应了一个ExtensionLoader。
LoadingStategy
先看该接口。Dubbo SPI 从META-INF下哪个文件夹加载,加载优先级如何,key同名是否支持覆盖等策略信息均由LoadingStrategy接口提供。
LoadingStrategy代表spi加载策略,该接口提供基本的加载信息,默认3个实现类:
DubboInternalLoadingStrategy: 内部加载策略,key同名不可覆盖DubboLoadingStrategy:key同名可覆盖ServicesLoadingStrategy:key同名可覆盖
3个实现类的初始化方式是通过JDK SPI机制引入,参考ExtensionLoader类:
public class ExtensionLoader<T> {
...
private static volatile LoadingStrategy[] strategies = loadLoadingStrategies();
...
// Spliterator接口
private static LoadingStrategy[] loadLoadingStrategies() {
return stream(load(LoadingStrategy.class).spliterator(), false)
.sorted()
.toArray(LoadingStrategy[]::new);
}
...
// 获取LoadingStrategy
public static List<LoadingStrategy> getLoadingStrategies() {
return asList(strategies);
}
}
ExtensionLoader
新版本中,ExtensionLoader#getExtensionLoader同ExtensionFactory接口都已被废弃,改进如下:
ExtensionLoader#getExtensionLoader→ \rightarrow →ExtensionDirector#getExtensionLoaderExtensionFactory→ \rightarrow →ExtensionInjector,其实现类由AdaptiveExtensionFactory→ \rightarrow →AdaptiveExtensionInjector,Adaptive是一个门面,具体干活的由SpiExtensionFactory→ \rightarrow →SpiExtensionInjector,但是所有干活的逻辑弯弯绕绕后又回到ExtensionLoader中,很奇怪。
最终由 ExtensionLoader#loadExtensionClasses执行代码:
public class ExtensionLoader<T> {
...
private static volatile LoadingStrategy[] strategies = loadLoadingStrategies();
...
private Map<String, Class<?>> loadExtensionClasses() throws InterruptedException {
checkDestroyed();
cacheDefaultExtensionName();
Map<String, Class<?>> extensionClasses = new HashMap<>();
for (LoadingStrategy strategy : strategies) {
loadDirectory(extensionClasses, strategy, type.getName());
// compatible with old ExtensionFactory
if (this.type == ExtensionInjector.class) {
loadDirectory(extensionClasses, strategy, ExtensionFactory.class.getName());
}
}
return extensionClasses;
}
private void loadDirectory(Map<String, Class<?>> extensionClasses, LoadingStrategy strategy, String type) throws InterruptedException {
loadDirectoryInternal(extensionClasses, strategy, type);
...
}
private void loadDirectoryInternal(Map<String, Class<?>> extensionClasses, LoadingStrategy loadingStrategy, String type) throws InterruptedException {
String fileName = loadingStrategy.directory() + type;
// 可用的classLoader集合
List<ClassLoader> classLoadersToLoad = new LinkedList<>();
// 先加入ExtensionLoader的类加载器
if (loadingStrategy.preferExtensionClassLoader()) {
ClassLoader extensionLoaderClassLoader = ExtensionLoader.class.getClassLoader();
// 不能是系统类加载器
if (ClassLoader.getSystemClassLoader() != extensionLoaderClassLoader) {
classLoadersToLoad.add(extensionLoaderClassLoader);
}
}
// 获取classloader
Set<ClassLoader> classLoaders = scopeModel.getClassLoaders();
// 如果classloader为空,则用系统类加载器加载SPI文件
if (CollectionUtils.isEmpty(classLoaders)) {
Enumeration<java.net.URL> resources = ClassLoader.getSystemResources(fileName);
}
// 否则加入classLoader集合
else {
classLoadersToLoad.addAll(classLoaders);
}
// 工具类 多个classLoadersToLoad并行搜寻各个classLoader来加载资源
// 但是基本只有一个classLoader,不知道为啥这么设计
Map<ClassLoader, Set<java.net.URL>> resources = ClassLoaderResourceLoader.loadResources(fileName, classLoadersToLoad);
// 遍历所有,反射生成SPI实现类并加入到extensionClasses集合中
resources.forEach(((classLoader, urls) -> {
loadFromClass(extensionClasses,...);
}));
}
}
Spring SPI
注意,该SPI机制属于 org.springframework.core包下,通常用在自定义spring-boot-starter中。
示例
public class TestSpringSpiApplication {
public static void main(String[] args) {
List<TestSpringSpi> spiList = SpringFactoriesLoader.loadFactories(TestSpringSpi.class, Thread.currentThread().getContextClassLoader());
for (TestSpringSpi spi : spiList) {
spi.test();
}
}
}
SpringFactoriesLoader
public final class SpringFactoriesLoader {
public static final String FACTORIES_RESOURCE_LOCATION = "META-INF/spring.factories";
// 缓存
static final Map<ClassLoader, Map<String, List<String>>> cache = new ConcurrentReferenceHashMap<>();
...
public static <T> List<T> loadFactories(Class<T> factoryType, @Nullable ClassLoader classLoader) {
Assert.notNull(factoryType, "'factoryType' must not be null");
ClassLoader classLoaderToUse = classLoader;
//classloader未指定就用该类的classloader
if (classLoaderToUse == null) {
classLoaderToUse = SpringFactoriesLoader.class.getClassLoader();
}
// 加载spi实现类的全类名
List<String> factoryImplementationNames = loadFactoryNames(factoryType, classLoaderToUse);
List<T> result = new ArrayList<>(factoryImplementationNames.size());
for (String factoryImplementationName : factoryImplementationNames) {
result.add(
// 反射类加载
instantiateFactory(factoryImplementationName, factoryType, classLoaderToUse)
);
}
AnnotationAwareOrderComparator.sort(result);
return result;
}
// 加载名称,这里主要做前置检查和结果处理
public static List<String> loadFactoryNames(Class<?> factoryType, @Nullable ClassLoader classLoader) {
... // 进一步检查
// 加载所有的spring.factories中内容,并获取,没有就返回空列表
return loadSpringFactories(classLoaderToUse)
.getOrDefault(factoryTypeName, Collections.emptyList());
}
private static Map<String, List<String>> loadSpringFactories(ClassLoader classLoader) {
// 先从缓存中获取所有加载的springfactories中内容
Map<String, List<String>> result = cache.get(classLoader);
if (result != null) {
return result;
}
// 初始化加载
result = new HashMap<>();
try {
// 获取到MEAT-INF/spring.factories文件的URL,通常就一个
Enumeration<URL> urls = classLoader.getResources(FACTORIES_RESOURCE_LOCATION);
while (urls.hasMoreElements()) {
URL url = urls.nextElement();
UrlResource resource = new UrlResource(url);
// 加载所有的key=value
Properties properties = PropertiesLoaderUtils.loadProperties(resource);
for (Map.Entry<?, ?> entry : properties.entrySet()) {
...
}
}
// Replace all lists with unmodifiable lists containing unique elements
result.replaceAll((factoryType, implementations) -> implementations.stream().distinct()
.collect(Collectors.collectingAndThen(Collectors.toList(), Collections::unmodifiableList)));
// 加入缓存
cache.put(classLoader, result);
}
catch (IOException ex) {
...
}
return result;
}
}
总结
不管是哪一类,基本结构步骤就是
- 获取类加载器
- 利用类加载器在固定路径加载SPI文件,
ClassLoader#getResources生成Enumeration<java.net.URL>对象(通常只有一个URL) - 对URL对象实施解析,获取实现类全类名
- 反射实施类加载
Class#forName→ \rightarrow →Constructor#newInstance