过程步:一个典型的SAS完整程序:

代码说明:
1)reg:回归分析;
2)model:因变量和自变量。
proc开头部分叫过程步。
常用过程:
SORT过程:
PRINT过程与FORTMAT过程:
MEANS过程:
TABULATE过程:
PLOT过程与GPLOT过程:
CHART与GCHART过程:
数据排序:SORT过程:在page 111页。
1)proc sort <选择项>:
DATA=数据集
OUT=数据集,若没有此项,缺省为覆盖原数据集;
BY语句用于指出排序变量名,及是否降序排序。

代码分析:
1)学生学号、和三科成绩;
2)CLAS变量是从num中截取第3位,截取2位长度。
3)TOT=sum(of s1-s3);这个语句还是很有特点的。

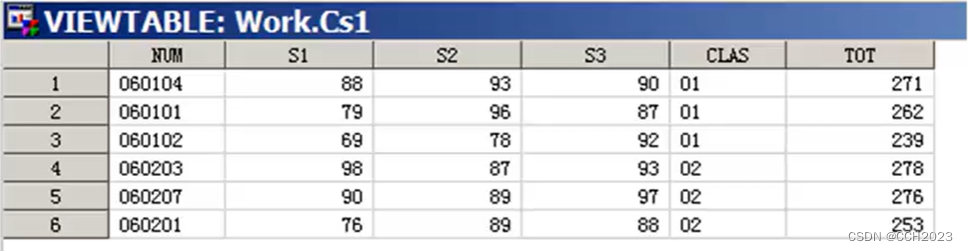
代码分析:
1)先根据CLAS进行升序排列;
2)然后在每个CLAS中再按TOT降序进行排列。例如:01班是从271到239进行降序排列。
3)Proc print语句:没有指定我们要打印输出的数据集,那就只打印我们当前操作的数据集CS1。
PRINT过程:
PROC PRINT <选项>:
VAR 变量表;
ID 变量表;
BY 变量表;
SUM 变量表;

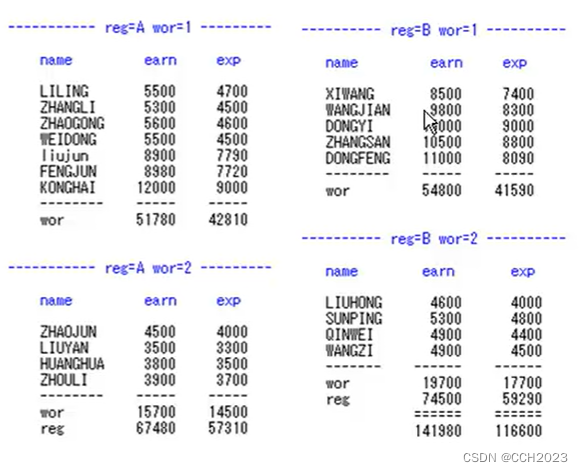
代码说明:
1)proc sort;by reg wor; 这两条语句是进行排序,先reg后wor。
2)然后是proc print语句:
3)然后我们看到了求和;先各自求和,然后分区域求和,然后再汇总求和。
4)ID name:以前的输出结果都是obs,表示第几个观测值;我们用name来代替obs,来代表每行的标识。
5)PRINT语句中,BY语句要先对变量进行排序,所以先要进行SORT才行。要先排序,才能使用BY。
6)sum就是求和。分类求和、大类求和,最后再汇总。
过程步常用的语句:
1)VAR:定义分析的变量,缺省为全部变量;
2)ID:定义取代Obs用于识别观测的变量;
3)BY:表示分组的方法;
4)SUM:指出求和的变量。

代码说明:
1)format:自定义格式。
2)worddate万能时间。
3)视频学习的例子中,老师在PROC FORMAT语句中还包含了library=library,表示格式要保存在指定的逻辑库中;格式码要保存在逻辑库中; 当Library=被指定后,Format过程产生的所有格式都是永久的,这些格式存于逻辑由库名指出的永久目录文件中。
4)
WEIGHT语句:
在过程中规定了数据变量,并以它的值作为观测的相关权重。
各个变量在总结果中
FREQ语句:
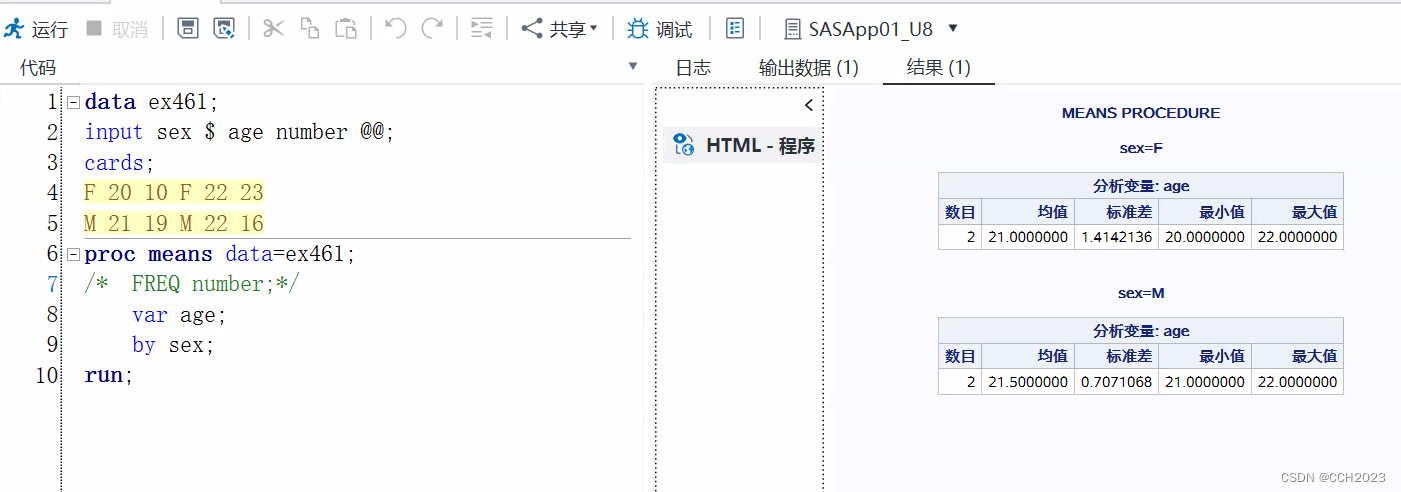
代码说明:
1)var age: 指定分析的变量;对sex变量求平均。
2)by sex; 分组处理某数据集;
3)但是计算时没有考虑各个年龄组的人数。应该是在Means过程中加入表示各组频数的FREQ语句。
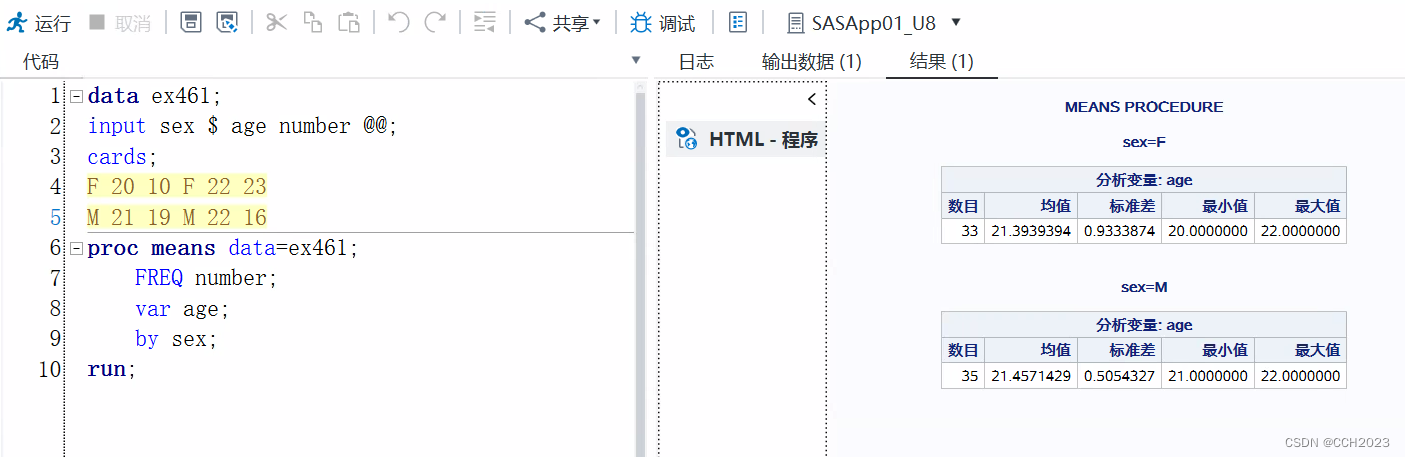
ID语句:
ID 变量表。
用来规定一个变量或几个变量,以便在输出或由该过程产生的SAS数据集中,不再使用obs,而是用这些变量值来识别观测。