一、数据挖掘概况
数据挖掘是指从大量的数据中,通过统计学、人工智能、机器学习等方法,挖掘出未知的、具有价值的信息和知识的过程。
典型案例:
- 啤酒与尿布
- 杜蕾斯与口香糖
- 杜蕾斯与红酒
数据挖掘是一门交叉学科,覆盖了统计学、数据可视化、算法、数据库、机器学习、市场营销以及其他多门学科的知识。

人们普遍认为数据挖掘是一项高大上的工作,必须具备高深的分析技能,需要精通算法,熟悉程序开发,但其实最好的数据挖掘工程师往往是那些熟悉和理解业务的人。

数据挖掘和数据分析区别
数据分析和数据挖掘的本质是一致的。

二、数据挖掘需要解决的常见问题

数据挖掘要解决的问题最终都可以转化为四类问题:分类、聚类、关联性、预测
分类
- 得到分类型目标变量(Y)——属于有监督学习
- 需要使用已知目标分类的历史样本来训练
- 需要对未知分类的样本预测所属的分类
常见的分类方法:决策树、贝叶斯、KNN、支持向量机、神经网络、逻辑回归等。
分类可以应用于“用户流失预测”,“促销活动响应”、“用户信用评估”等商业问题分析上。
聚类
- 无分类型目标变量(Y)——属于无监督学习,
- 不是事先给定分类,是根据数据特征制定的
- 物以类聚思想
常见的聚类算法:划分聚类、层次聚类、密度聚类、网格聚类、基于模型聚类等。
聚类可以应用于“目标市场细分”、“现有客户细分”等商业问题分析上。
关联(购物篮分析)
- 无目标变量(Y)——属于无监督学习
- 基于数据项关联,识别频繁发生的模式
常见的关联算法:Aprior算法、Carma算法、序列算法。
关联分析可以应用于“哪些商品同时购买几率高?”“如何提高商品销售和交叉销售?”等商业问题分析上。
预测
- 数值型目标变量(Y)——属于有监督学习
- 需有已知目标值的历史样本来训练模型
- 对未知样本预测其目标值
常见的预测方法有:简单线性回归分析、多重线性回归分析、时间序列分析等。
预测分析可以用于在“未来气温预测”、“GDP增长预测”、“收入、用户数预测”等商业问题上。
数据挖掘流程
业内经典的数据挖掘流程:CRISP-DM数据挖掘方法论。分为六个步骤,这六个步骤并不会直线进行,经常回到前面的步骤,因此该过程是一个循环的探索过程。
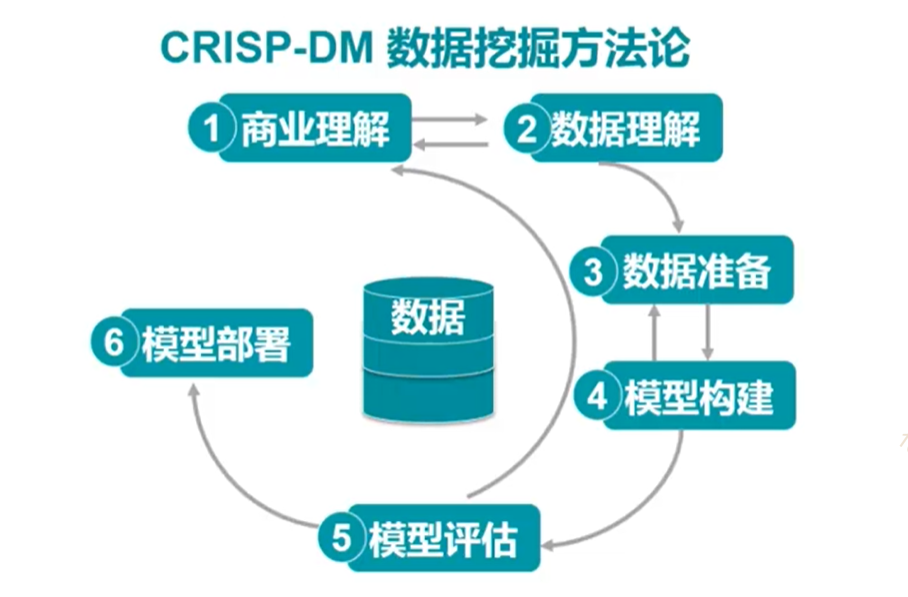
1.商业理解
- 确定商业目标:了解商业背景、商业目标和成功标准等。
- 确定挖掘目标:数据挖掘目标、数据口径、建模时间窗口和模型成功标准。
- 制定项目方案:项目计划、建模工具、算法等
2. 数据理解
- 数据收集
- 数据描述
- 数据探索:绘制图表
- 质量描述:摸清数据来源及真实性
3. 数据准备
完成在进行数据挖掘之前的准备工作,将数据处理成一张大宽表,也就是一维表。
- 数据导入
- 数据抽取:抽取符合条件的变量
- 数据清洗:缺失值、异常值、重复值处理等
- 数据合并:记录合并、字段合并、字段匹配等处理
- 变量计算:字段计算,生成新的变量,如均值和占比等
4. 模型构建
尝试不同模型,将模型调至最佳参数。由于不同模型对数据要求不同,在选好模型后可能会跳回数据准备阶段重新处理宽表。
- 准备模型的训练集和验证集
- 选择使用建模技术
- 建立模型
- 模型对比
5. 模型评估
- 技术层面评估:设置对造组进行比较;设置评估指标:命中率、覆盖率、提升度等。
- 业务经验:业务专家评估
6. 模型部署
根据模型挖掘的结果协助业务开展,定期优化模型。
- 营销过程跟踪记录
- 观察模型衰退变化,以定期优化模型
- 引入新的特征优化模型
- 模型写成程序固化到平台