CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
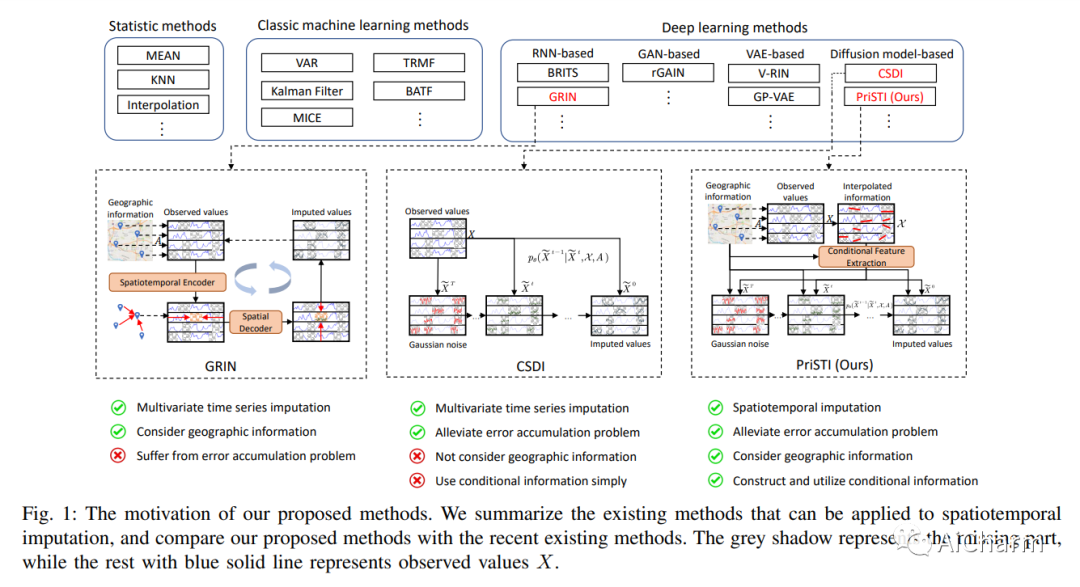
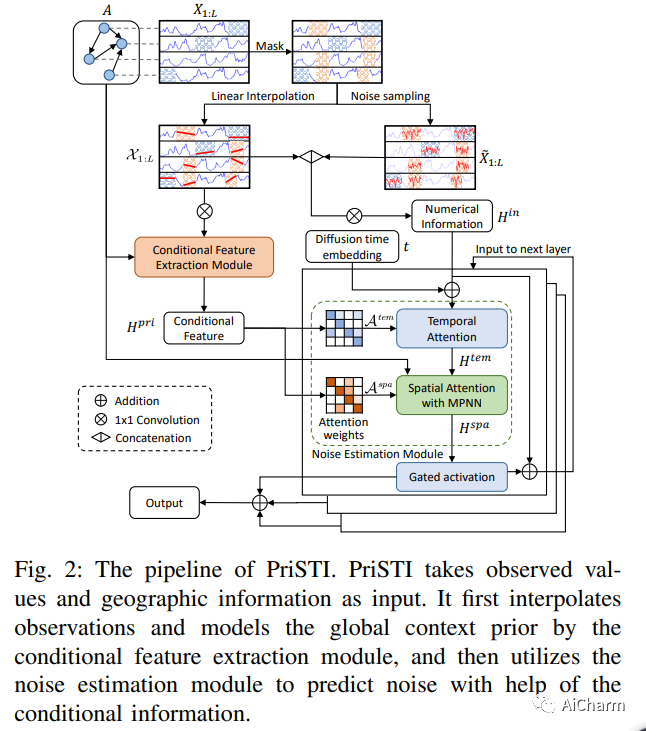
1.PriSTI: A Conditional Diffusion Framework for Spatiotemporal Imputation

标题:PriSTI:时空插补的条件扩散框架
作者:Mingzhe Liu, Han Huang, Hao Feng, Leilei Sun, Bowen Du, Yanjie Fu
文章链接:https://arxiv.org/abs/2302.09746v1
项目代码:https://github.com/lmzzml/pristi
摘要:
时空数据挖掘在空气质量监测、人群流动建模和气候预测中发挥着重要作用。然而,由于传感器故障或传输丢失,现实场景中最初收集的时空数据通常是不完整的。时空插补旨在根据观测值及其潜在的时空依赖性来填充缺失值。以前的主导模型以自回归方式估算缺失值,并存在误差累积的问题。作为新兴的强大生成模型,扩散概率模型可用于插补以观察为条件的缺失值,避免从不准确的历史插补中推断出缺失值。然而,将扩散模型应用于时空插补时,条件信息的构建和利用是不可避免的挑战。为了解决上述问题,我们提出了一个用于时空插补的条件扩散框架,该框架具有增强的先验建模,名为 PriSTI。我们提出的框架首先提供了一个条件特征提取模块,用于从条件信息中提取粗略但有效的时空依赖性作为全局上下文先验。然后,噪声估计模块将随机噪声转换为实际值,并根据条件特征计算时空注意力权重,并考虑地理关系。PriSTI 在不同真实世界时空数据的各种缺失模式中优于现有插补方法,并有效处理高缺失率和传感器故障等场景。
2.Cross-domain Compositing with Pretrained Diffusion Models

标题:使用预训练扩散模型进行跨域合成
作者:Roy Hachnochi, Mingrui Zhao, Nadav Orzech, Rinon Gal, Ali Mahdavi-Amiri, Daniel Cohen-Or, Amit Haim Bermano
文章链接:https://arxiv.org/abs/2302.01791v1
项目代码:https://github.com/cross-domain-compositing/cross-domain-compositing

摘要:
扩散模型启用了高质量的条件图像编辑功能。我们建议扩展他们的武器库,并证明现成的扩散模型可用于广泛的跨域合成任务。其中包括图像混合、对象沉浸、纹理替换甚至 CG2Real 翻译或风格化。我们采用局部迭代细化方案,为注入的对象注入来自背景场景的上下文信息,并能够控制对象可能经历的变化程度和类型。我们对之前的工作进行了一系列定性和定量比较,并表明我们的方法无需任何注释或培训即可产生更高质量和逼真的结果。最后,我们演示了我们的方法如何用于下游任务的数据增强。
3.Composer: Creative and Controllable Image Synthesis with Composable Conditions

标题:Composer:具有可组合条件的创造性和可控图像合成
作者:Lianghua Huang, Di Chen, Yu Liu, Yujun Shen, Deli Zhao, Jingren Zhou
文章链接:https://arxiv.org/abs/2302.01660v2
项目代码:https://github.com/modelscope/modelscope



摘要:
最近在大数据上学习的大规模生成模型能够合成令人难以置信的图像,但可控性有限。这项工作提供了一种新一代范例,可以灵活控制输出图像,例如空间布局和调色板,同时保持合成质量和模型创造力。以组合性为核心思想,我们首先将图像分解为具有代表性的因素,然后以所有这些因素为条件训练扩散模型对输入进行重组。在推理阶段,丰富的中间表示作为可组合元素工作,为可定制的内容创建带来巨大的设计空间(即,与分解因子的数量成指数比例)。值得注意的是,我们称之为 Composer 的方法支持各种级别的条件,例如作为全局信息的文本描述、作为局部指导的深度图和草图、用于低级细节的颜色直方图等。除了提高可控性外,我们确认 Composer 是一个通用框架,无需重新训练即可促进各种经典生成任务。代码和模型将可用。
更多Ai资讯:公主号AiCharm