内容来自尚硅谷
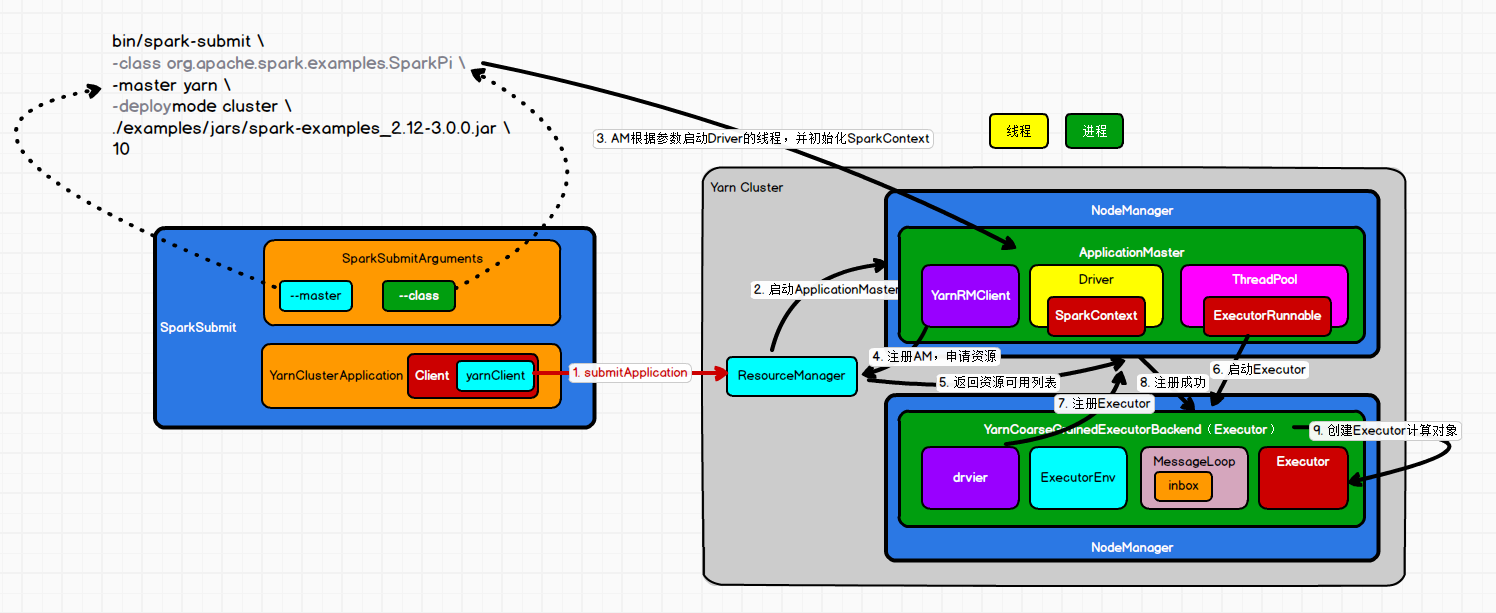
1.submitApplication
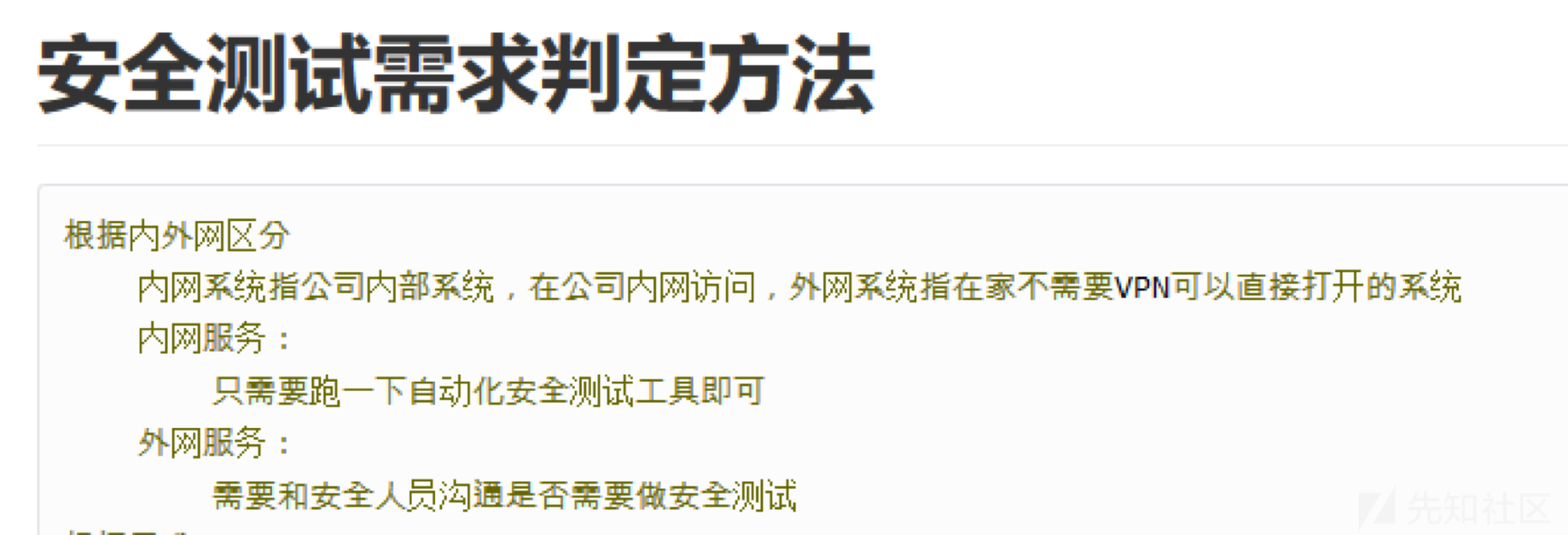
当spark执行任务时会启动java虚拟机,启动一个进程,该进程的名称为SparkSubmit,会执行SparkSubmit中的main方法,该方法中调用了super.doSubmit方法。

org.apache.spark.deploy.SparkSubmit
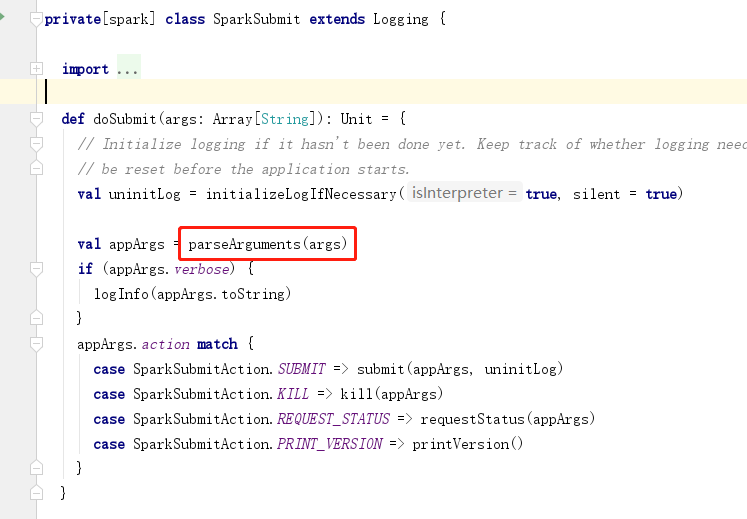
doSubmit方法中首先会解析参数调用parseArguments(args)方法,创建参数构建对象new SparkSubmitArguments(args),根据参数中action类型进行执行,如果是submit就是提交任务
2.启动ApplicationMaster
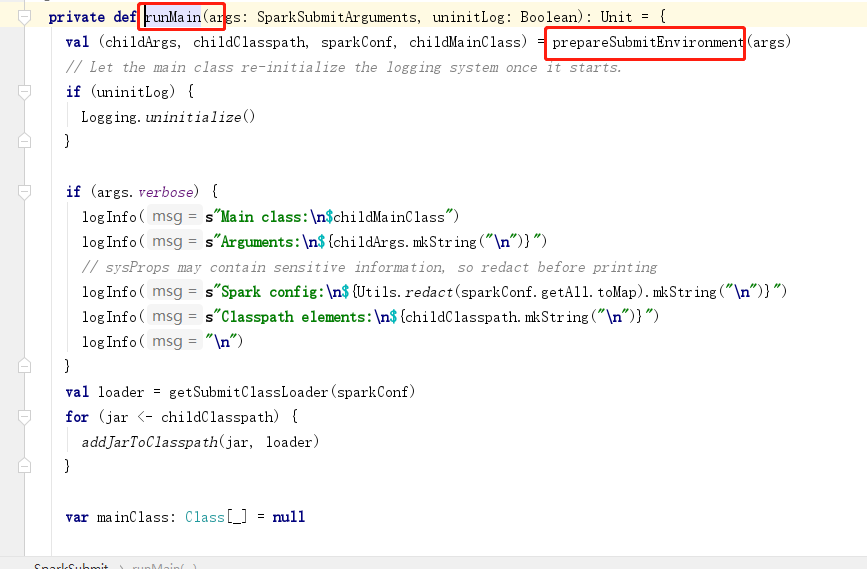
submit方法底层会执行runMain(args, uninitLog),该方法中会调用prepareSubmitEnvironment(args)方法(准备任务提交的环境)
如果是yarn模型,childMainClass=org.apache.spark.deploy.yarn.YarnClusterApplication
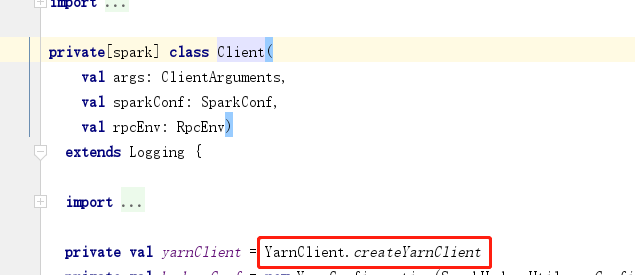
YarnClusterApplication执行start方法会new一个client对象

client对象中包含yarnClient对象,底层会生成resouceManager对象
client.run 会调用submitApplication方法,该方法会封装一些执行的指令

该方法中会创建application对象,指定container


当是集群模式是会创建master对象(进程),随后执行run方法,启动Driver
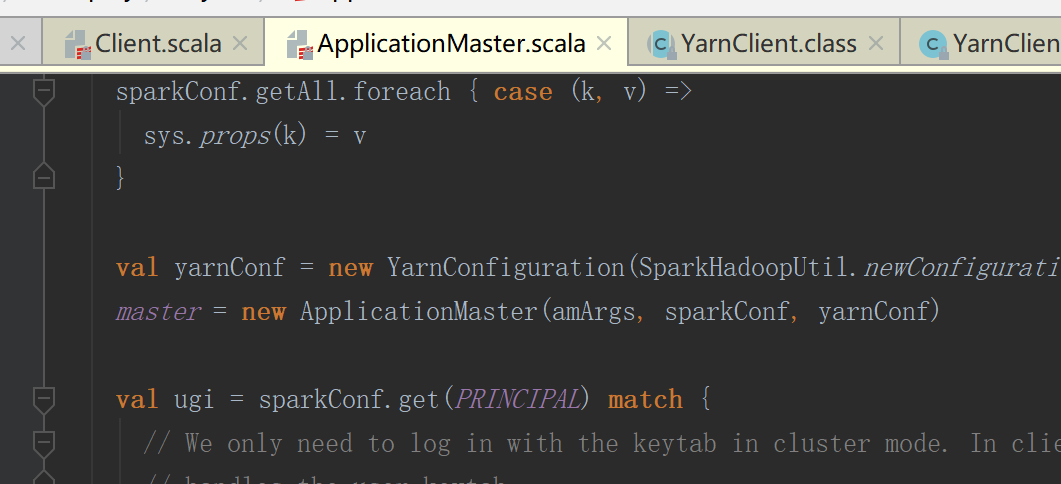

3.启动Driver ,初始化sparkContext
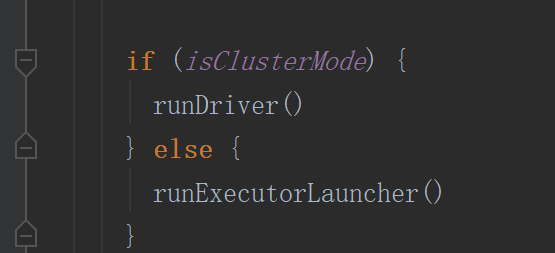
runDriver中会启动一个线程名字为Driver,并执行提交代码的main方法,执行代码中的new sparkContext(conf)代码

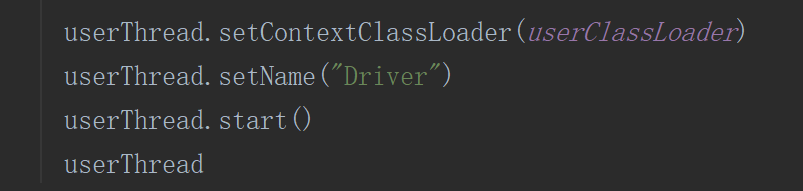
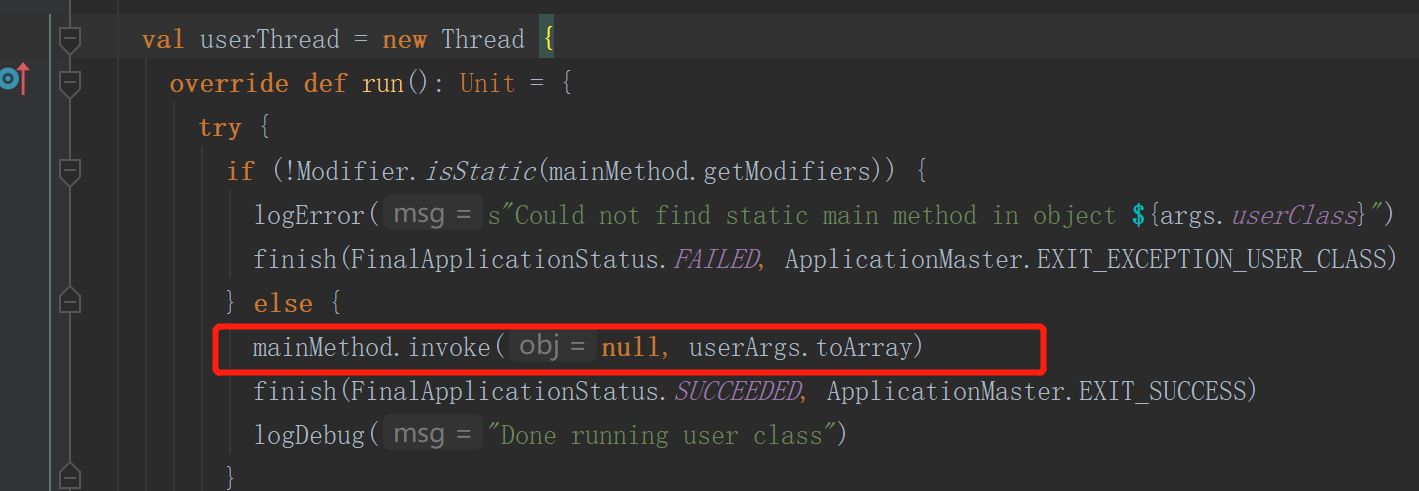
4.注册AM,与resouceManage连接申请资源
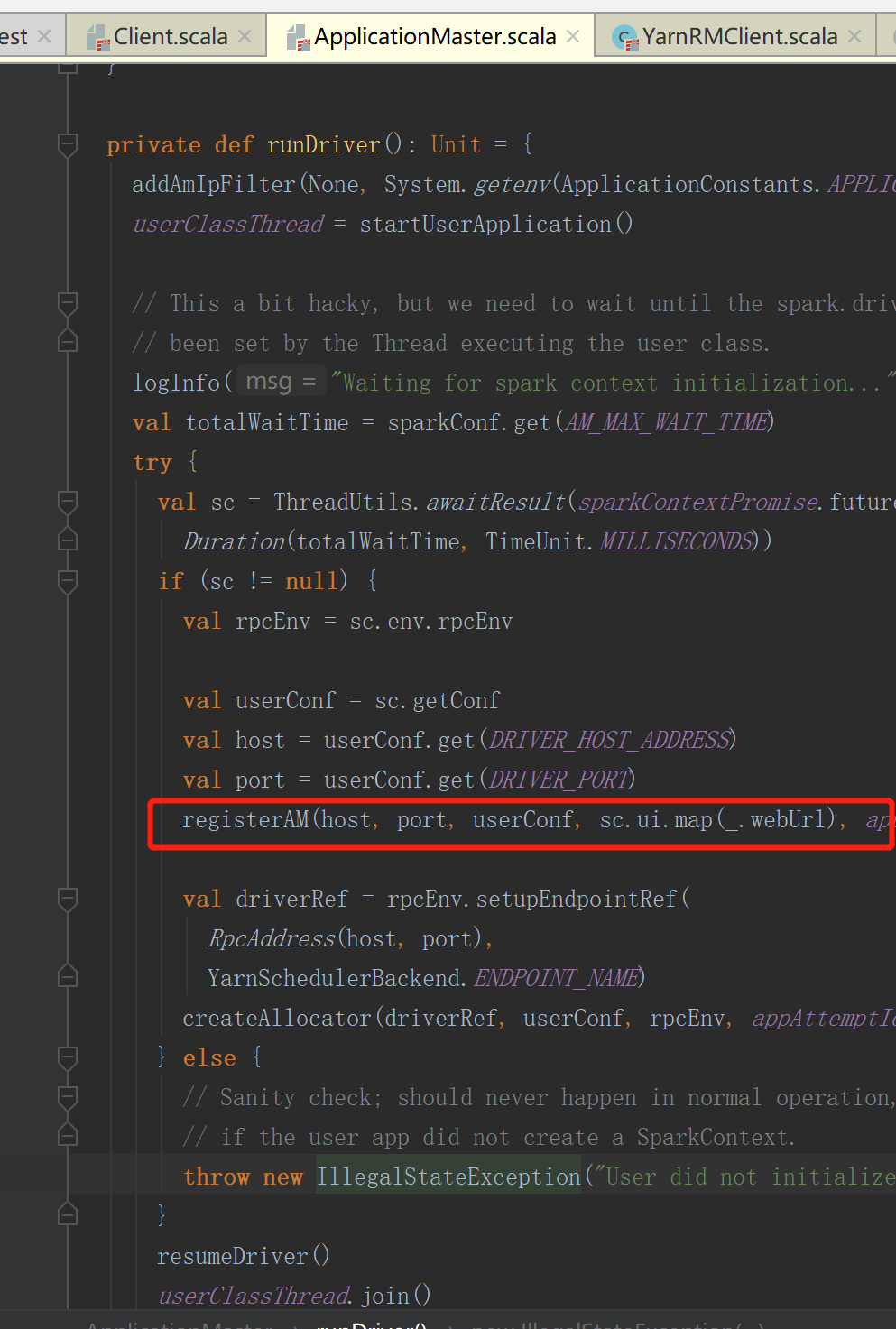
5.注册AM时会获取资源可用服务器链表
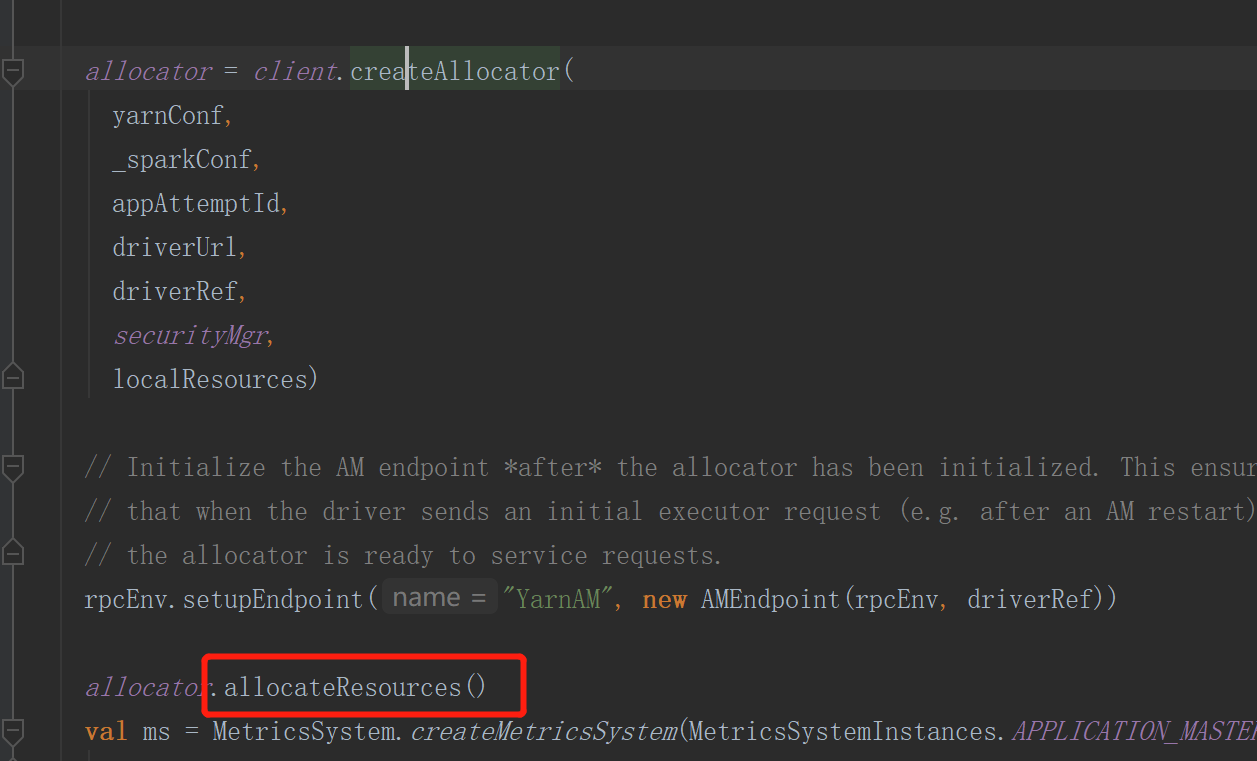
处理可使用的服务器
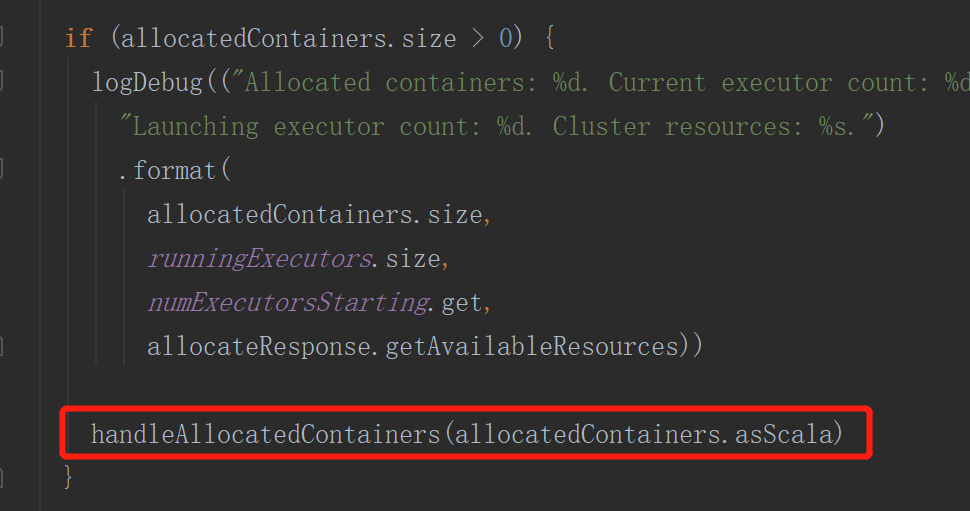
运行已分配服务器

6.启动exceutor通信进程
启动executor线程

执行启动container方法
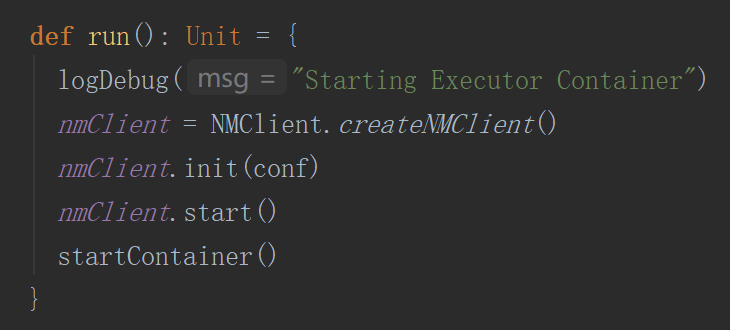
startContainer首先会封装命令,该命令会启动一个进程(org.apache.spark.executor.YarnCoarseGrainedExecutorBackend executor的通信进程)
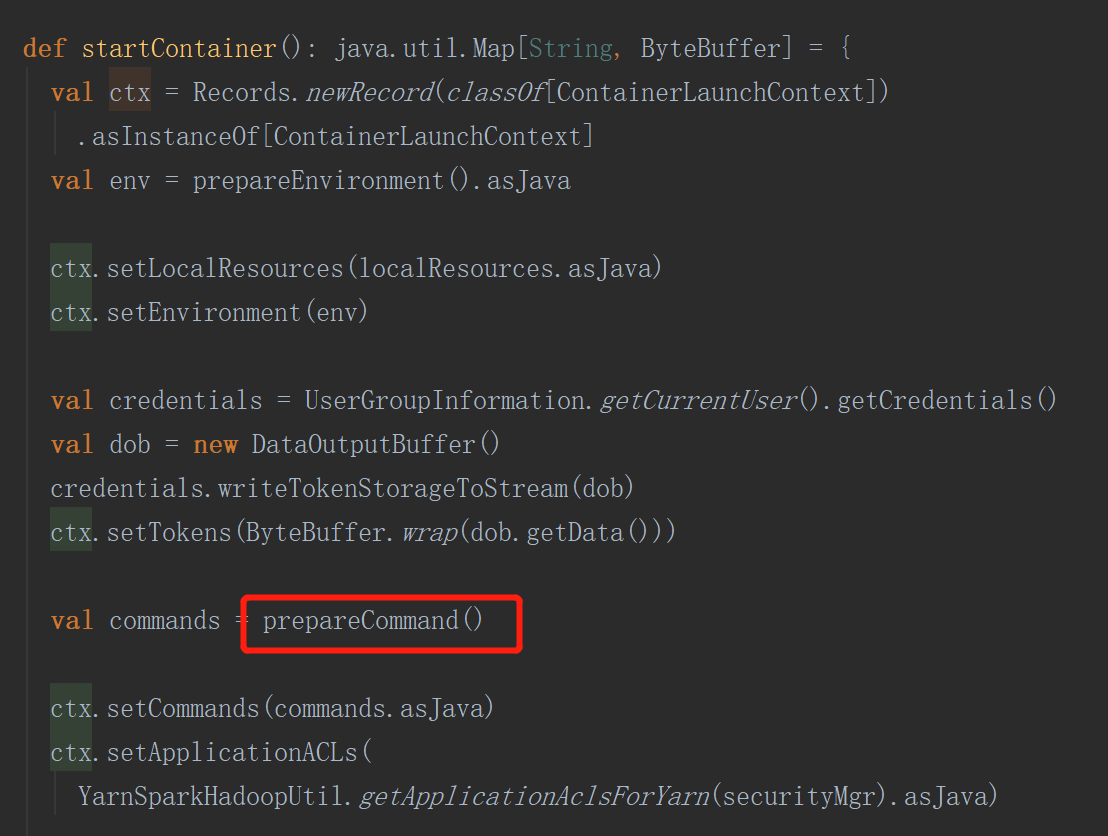
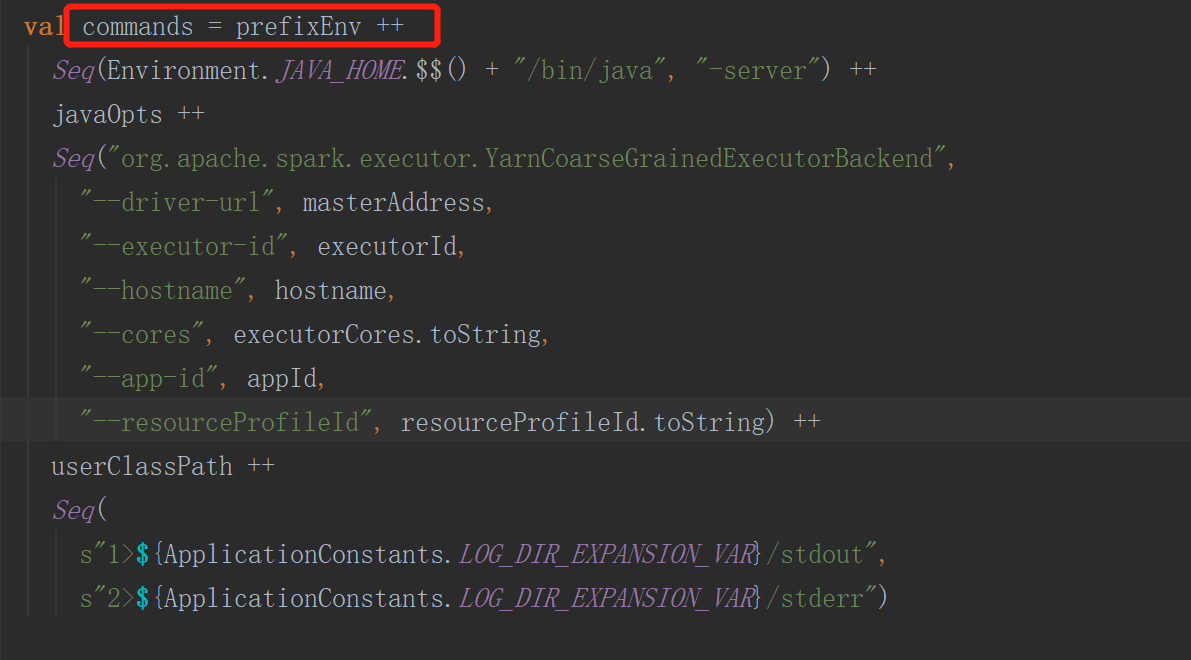
向指定的服务器启动container

创建executorBackend会执行其中的run方法
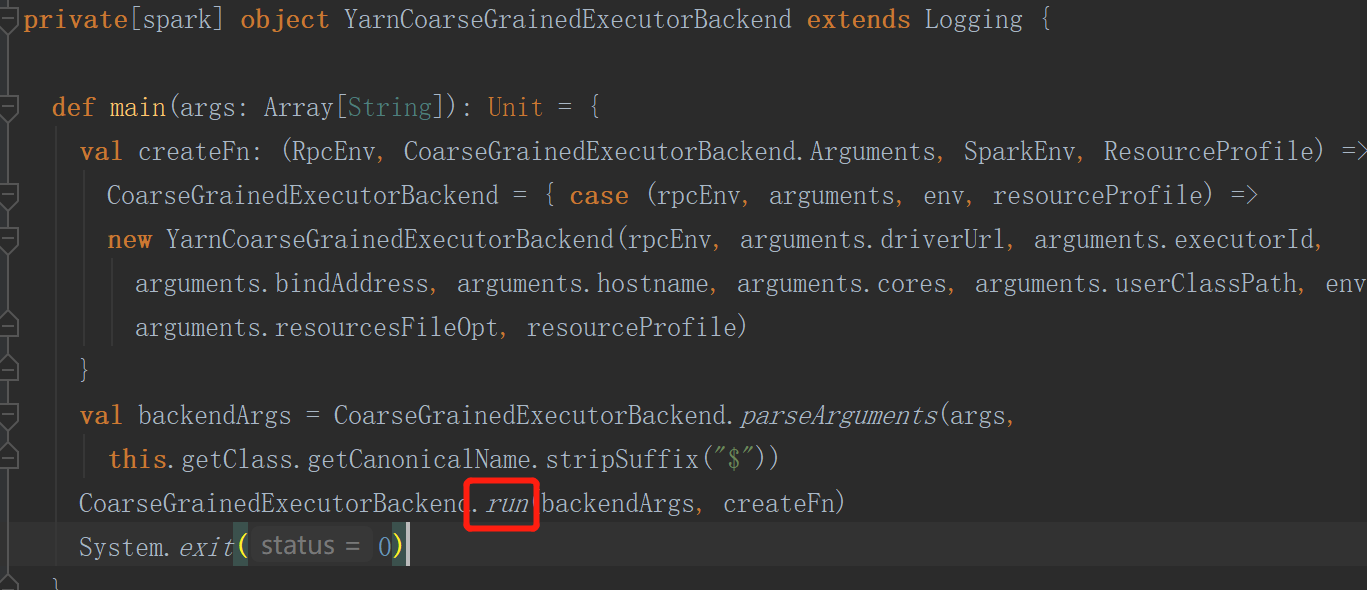
创建SparkEnv环境


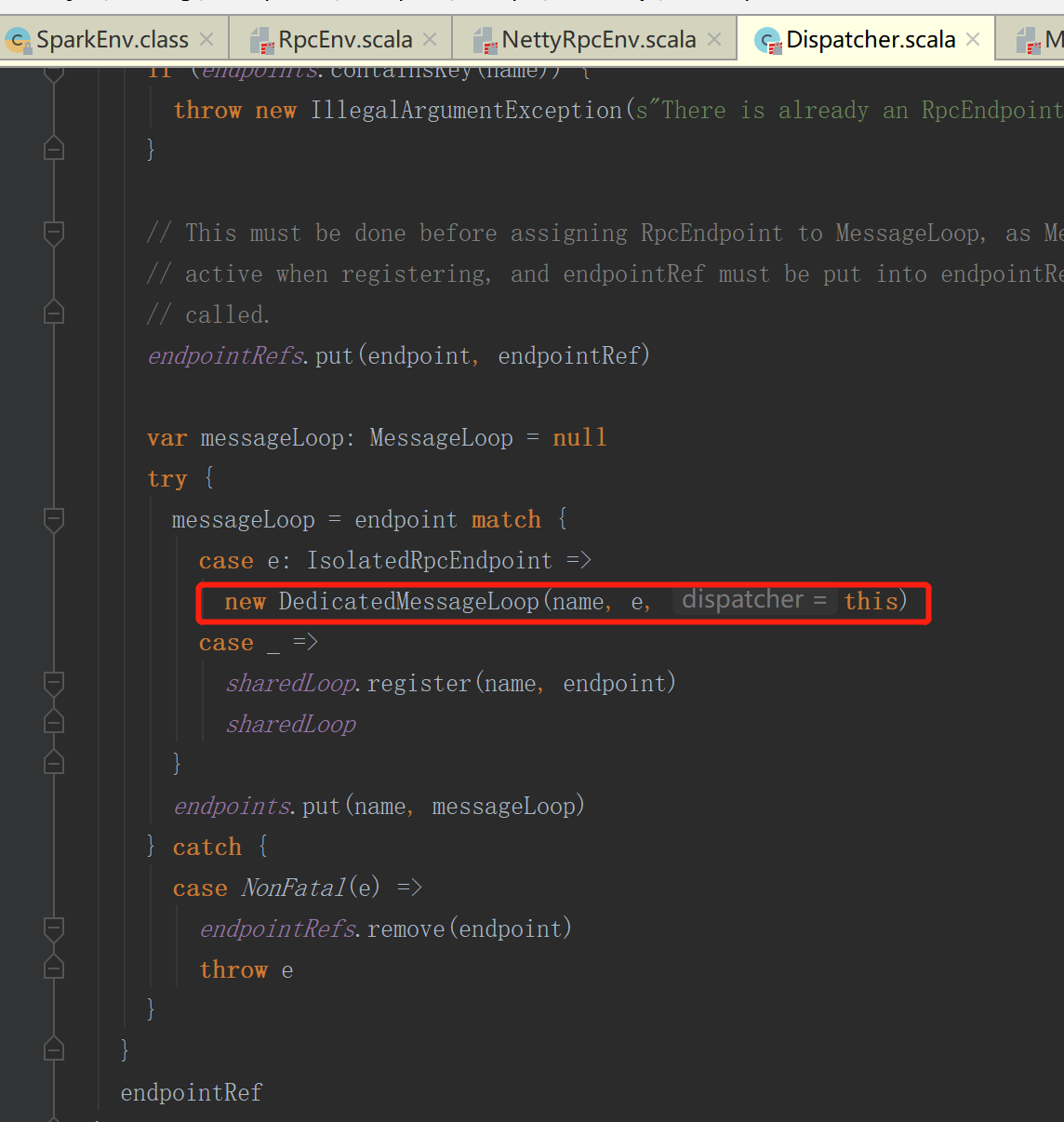
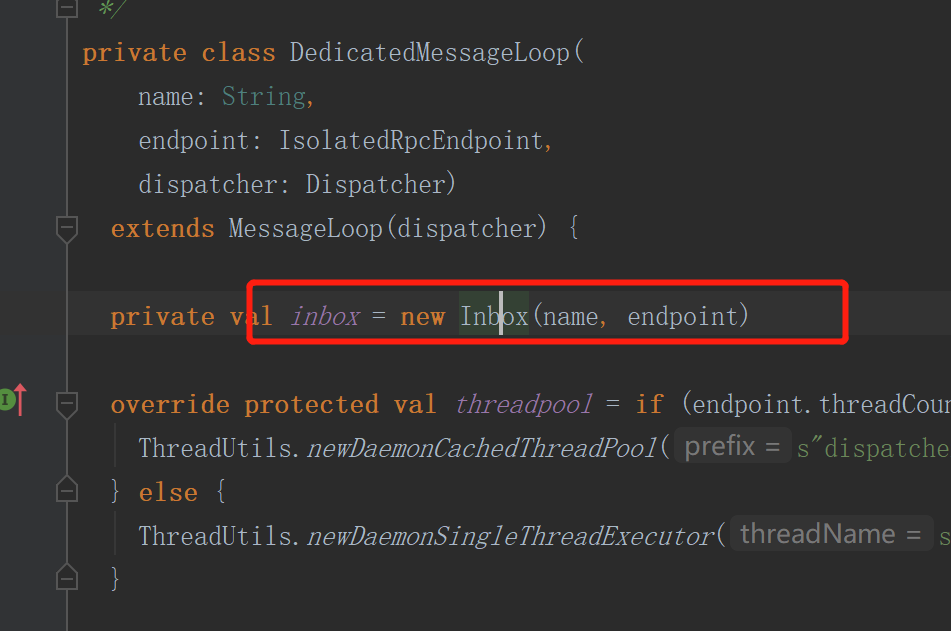

7.executor向driver进行注册
onStart方法执行的是CoarseGrainedExecutorBackend中的onStart方法

当向driver进行注册时,其实是向SparkContext环境进行注册,SparkContext中会有一个对象
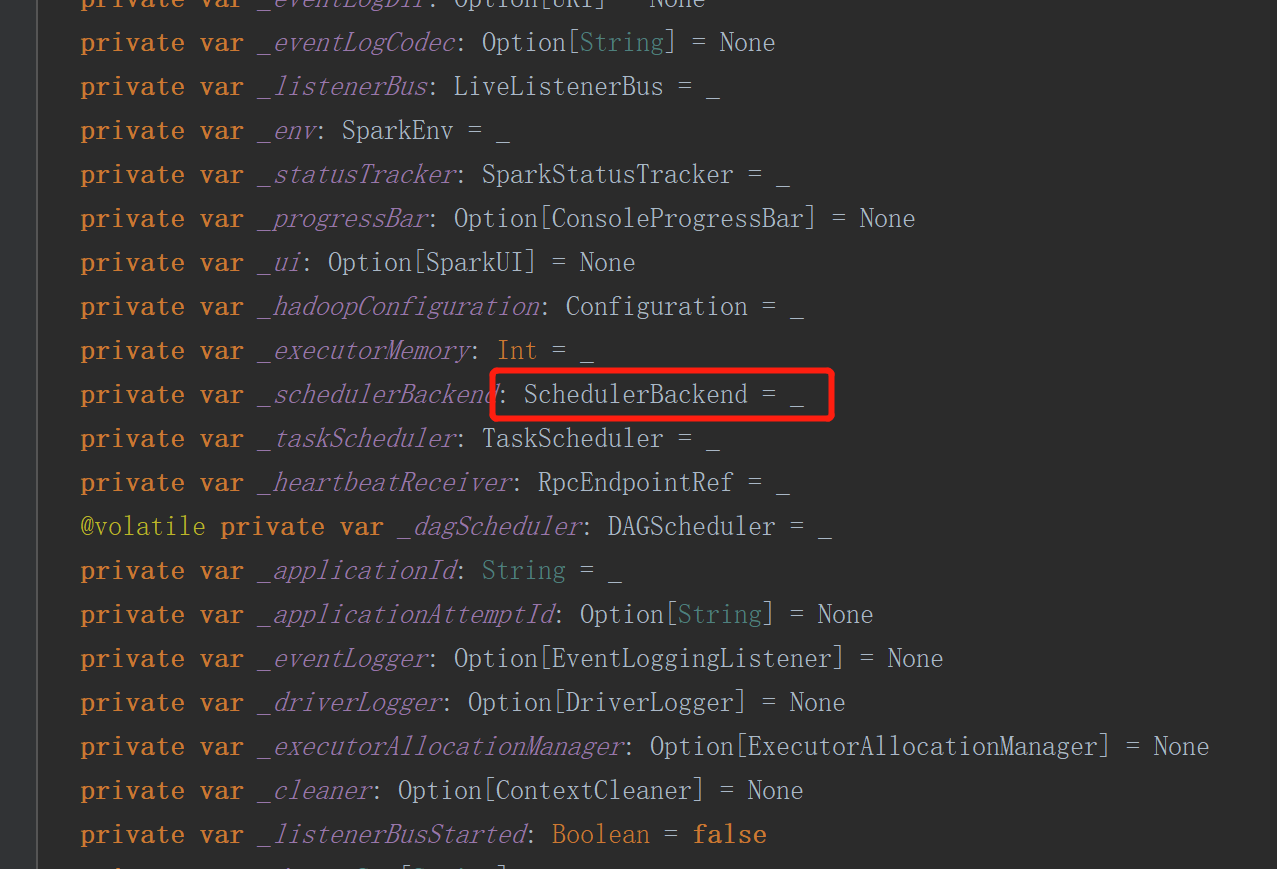
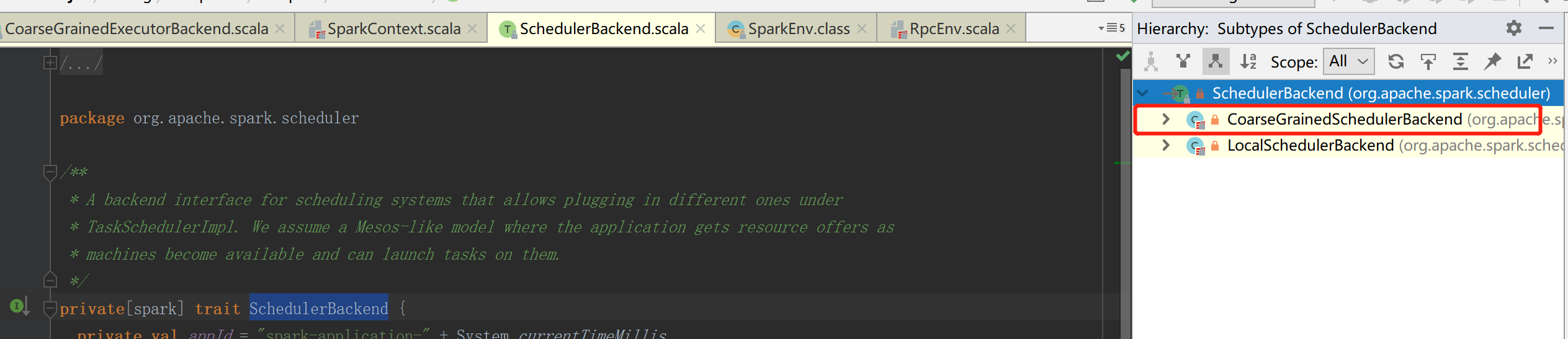
服务器端进行接收和回复
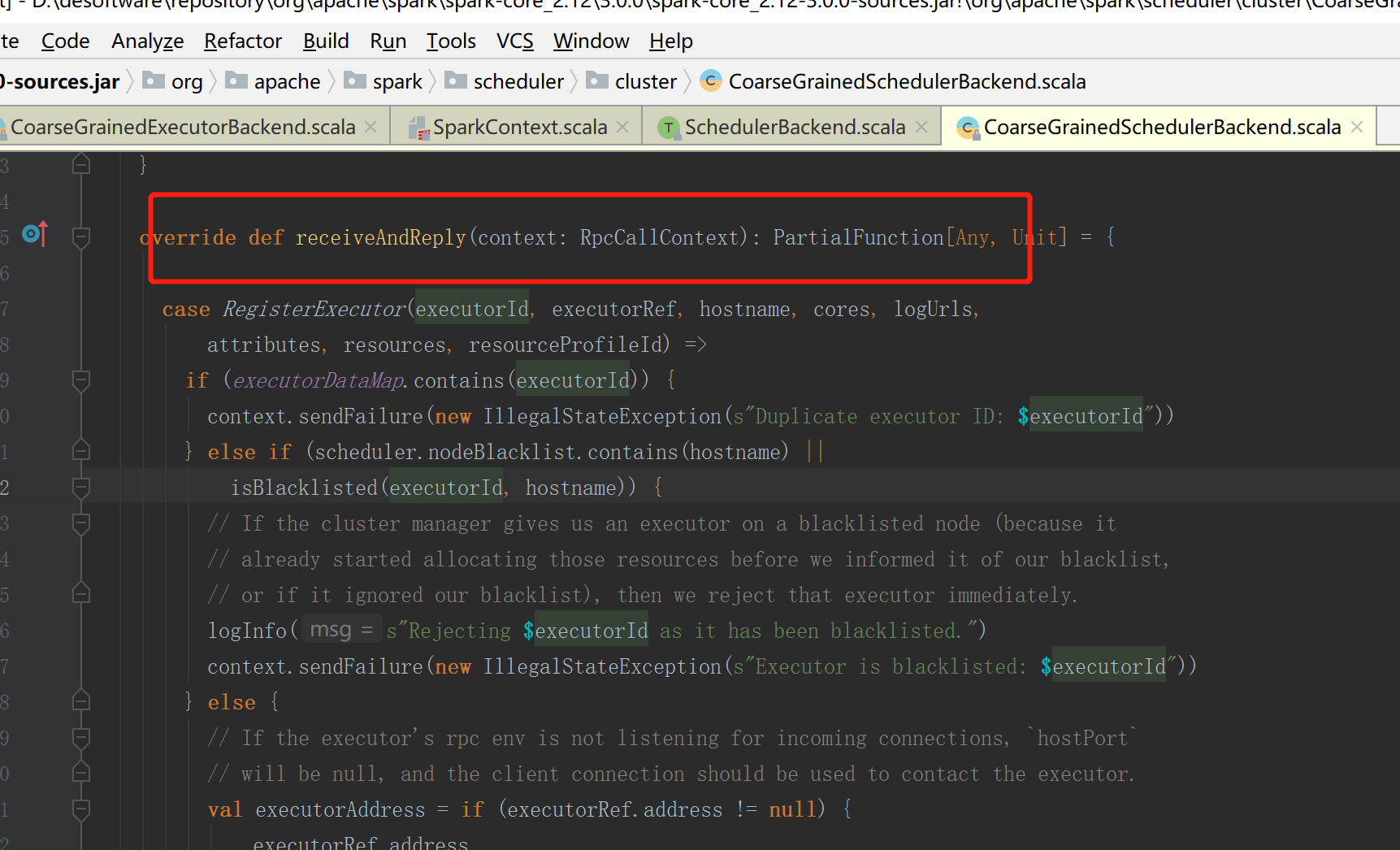
8.executor注册成功
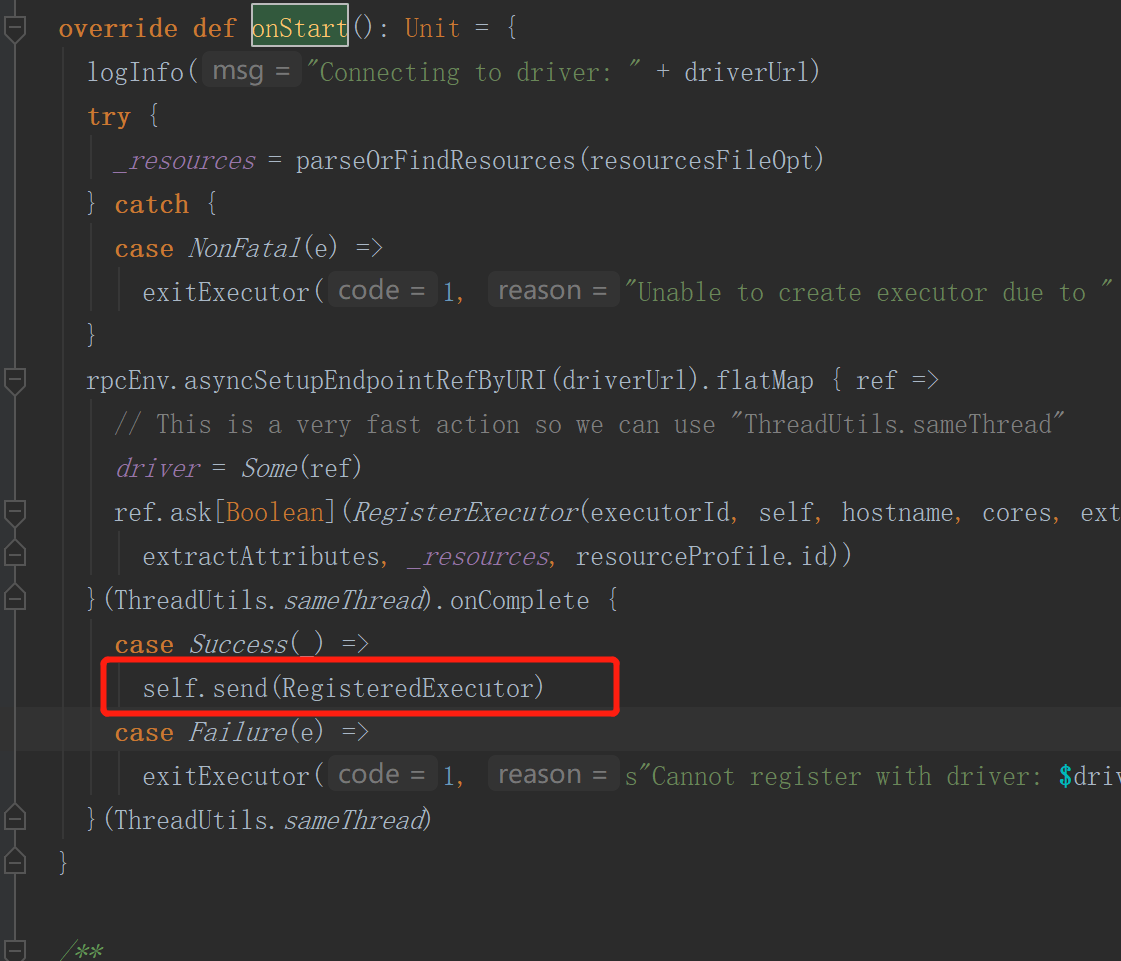
当服务器接收并回复之后,executor会给自己发送消息注册成功
CoarseGrainedExecutorBackend中的onStart方法
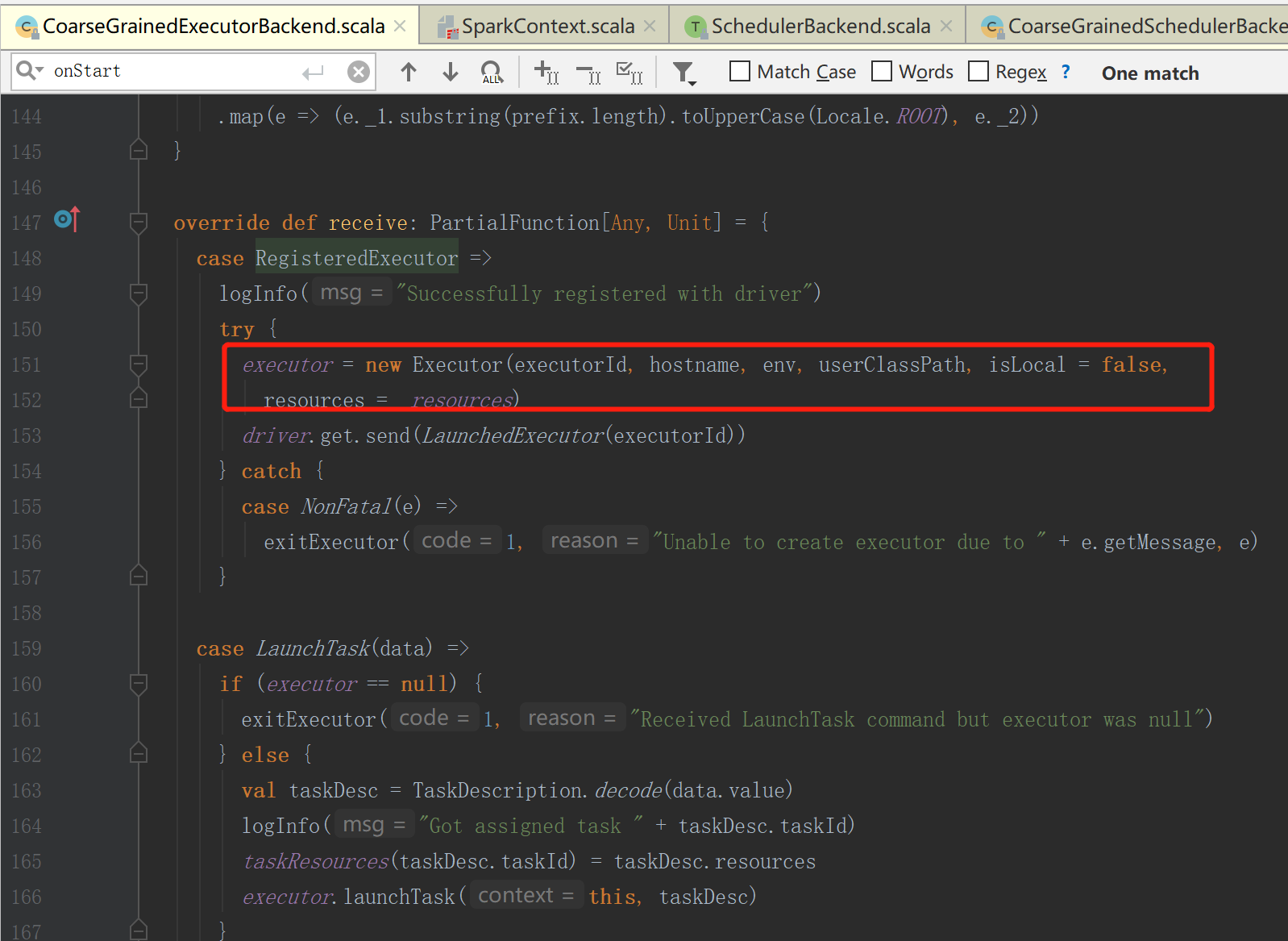
9.创建executor计算对象
executor当接收到消息后创建executor
10.执行代码

总体
1)执行脚本提交任务,实际是启动一个 SparkSubmit 的 JVM 进程;
2) SparkSubmit 类中的 main 方法反射调用 YarnClusterApplication 的 main 方法 YarnClusterApplication 创建 Yarn 客户端,然后向 Yarn 服务器发送执行指令: bin/java
ApplicationMaster; Yarn 框架收到指令后会在指定的 NM 中启动 ApplicationMaster;
3) ApplicationMaster 启动 Driver 线程,执行用户的作业;
4) AM 向 RM 注册,申请资源;
5)获取服务器可用列表
6) 获取资源后 AM 向 NM 发送指令: bin/java YarnCoarseGrainedExecutorBackend;
7) CoarseGrainedExecutorBackend 进程会接收消息,跟 Driver 通信
8)注册已经启动的Executor;
8) 然后启动计算对象 Executor 等待接收任务
10) Driver 线程继续执行完成作业的调度和任务的执行。
11) Driver 分配任务并监控任务的执行。