前言
普通的二叉树是不适合用数组来存储的,因为可能会存在大量的空间浪费。而完全二叉树更适合使用顺序结 构存储。现实中我们通常把堆(一种二叉树)使用顺序结构的数组来存储,需要注意的是这里的堆和操作系统 虚拟进程地址空间中的堆是两回事,一个是数据结构,一个是操作系统中管理内存的一块区域分段。
堆的概念及结构
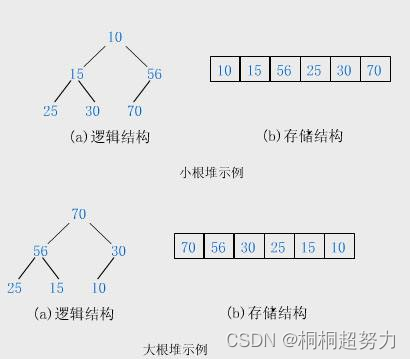
**堆(数据结构)**在逻辑上是一个完全二叉树而在物理上是一个数组。
堆是一种顺序存储结构(采用数组方式存储),仅仅是利用完全二叉树的顺序结构的特点进行分析。
已知二叉树根结点的下标是root,那么它左孩子的下标left=2*root+1,右孩子的下标right=2*root+2。
已知孩子结点的下标(不区分左右)为child,那么双亲的下标为(child-1)/2。
将满足根的值小于等于所有子树结点的值,称为小堆;根的值大于等于所有子树结点的值称为大堆。
堆的实现
我们实现堆还是要用三个文件,来让堆的代码看起来更加的简单易懂,
test.c,用来让测试堆的代码
Heap.c,我们些堆的函数
Heap.h,包括堆函数的头文件
(1)创建一个堆
这就是用一个结构体将这些内容,包括起来。
还是很简单的就不多介绍了
typedef int HPDatatype;
typedef struct Heap
{
HPDatatype* a;
int sz;
int capacity;
}HP;
(2).堆的初始化
//堆的初始化
void HeapInit(HP* php)
{
assert(php);
php->a = NULL;
php->sz = 0;
php->capacity = 0;
}
(2)堆的销毁
我们用
malloc申请了空间,我们就要销毁。
//堆的销毁
void HeapDestory(HP* php)
{
assert(php);
free(php->a);
php->a = NULL;
php->sz = 0;
php->capacity = 0;
}
(3).打印堆
//打印堆
void HeapPrint(HP* php)
{
assert(php);
for (int i = 0; i < php->sz; i++)
{
printf("%d ", php->a[i]);
}
printf("\n");
}
(4)堆的添加元素
我们堆添加元素的思路,就是在数组的最后一位添加元素,然后看他的父节点是不是比他大或者小(创建大堆和创建小堆),如果是大堆,父节点比他小,就交换,然后知道最后交换到头结点。
这时我们就用到一种算法,叫做向上调整算法。
向上调整算法
//向上调整函数
void AdjustUp(HPDatatype* a,int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
交换函数
j进行数据的交换,因为后面用的会很多,就做成一个函数
//交换函数
void Swap(HPDatatype* p1,HPDatatype* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
添加堆元素的代码
//堆的添加元素
void HeapPush(HP* php, HPDatatype x)
{
assert(php);
//扩容
if (php->sz == php->capacity)
{
int newcapacity = php->capacity == 0 ? 4 : php->capacity * 2;
HPDatatype* tmp = (HPDatatype*)realloc(php->a, sizeof(HPDatatype) * newcapacity);
if (tmp == NULL)
{
perror("realloc");
exit(-1);
}
php->a = tmp;
php->capacity = newcapacity;
}
php->a[php->sz] = x;
php->sz++;
//向上调整函数
AdjustUp(php->a,php->sz-1);
}
(5)删除堆顶的元素
我们堆删除元素,都是删除堆顶的元素,那么怎么删除元素了,
我们数组,最好删除的元素就是尾删,所以我们将第一个 元素和最后一个元素交换,然后我们sz--.
然后我们要保持他是一个堆,用到一个向下调整算法。
这个算法就是将最上面的元素,和他的最大的子节点进行交换,然后在进行到最后。
向下调整算法
void AdjustDown(HPDatatype* a, int n, int parent)
{
//选大的子节点进行交换
int child = parent * 2 + 1;
while (child < n)
{
//确认child指向大的孩子
if (child + 1 < n && a[child + 1] < a[child])
{
child++;
}
//孩子大于父亲,就进行交换,继续向下调整
//孩子小于父亲,则调整结束
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
删除元素的框架
//删除堆顶的数据,并保持他还是一个堆、
void HeapPop(HP* php)
{
assert(php);
assert(php->sz);
//第一个和最后一个交换然后尾删
Swap(&php->a[0], &php->a[php->sz - 1]);
php->sz--;
AdjustDown(php->a, php->sz, 0);
}
(6)找堆顶的元素
//找堆顶的元素
HPDatatype* HeapTop(HP* php)
{
assert(php);
assert(php->sz > 0);
return php->a[0];
}
(7)查看堆的大小
//查看堆的大小
int HeapSize(HP* php)
{
assert(php);
return php->sz;
}
(8)判断堆是否为空
//判断堆是否为空
bool HeapEmpty(HP* php)
{
assert(php);
return php->sz==0;
}
堆的构建
我们堆的构建用的算法是我们在删除元素的时候向下调整算法。
在排序之前,我们需要做一个准备工作,将数组放进去。看下面代码。
//堆的构建
void HeapCreate(HP* php, HPDatatype* a, int n)
{
assert(php);
//创建空间,将数组的的内容拷贝到我们的堆中,然后zai
php->a = (HPDatatype*)malloc( sizeof(HPDatatype) * n);
if (php->a == NULL)
{
perror("realloc");
exit(-1);
}
memcpy(php->a, a, sizeof(HPDatatype)*n);
php->sz = php->capacity = n;
}
经过上面的操作,我们将一个无序的数组放进去了,但是现在数组的内容并不是一个堆,现在我们用两种算法将这个数组变成堆。
向下调整的建堆算法
思路就是:我们想将最后一个叶子结点和他的父节点,先构成一个堆,然后我们再将父节点的上一个结点的子节点,将这个构建一个堆,知道最后到根结点。看下面我画的解释图。
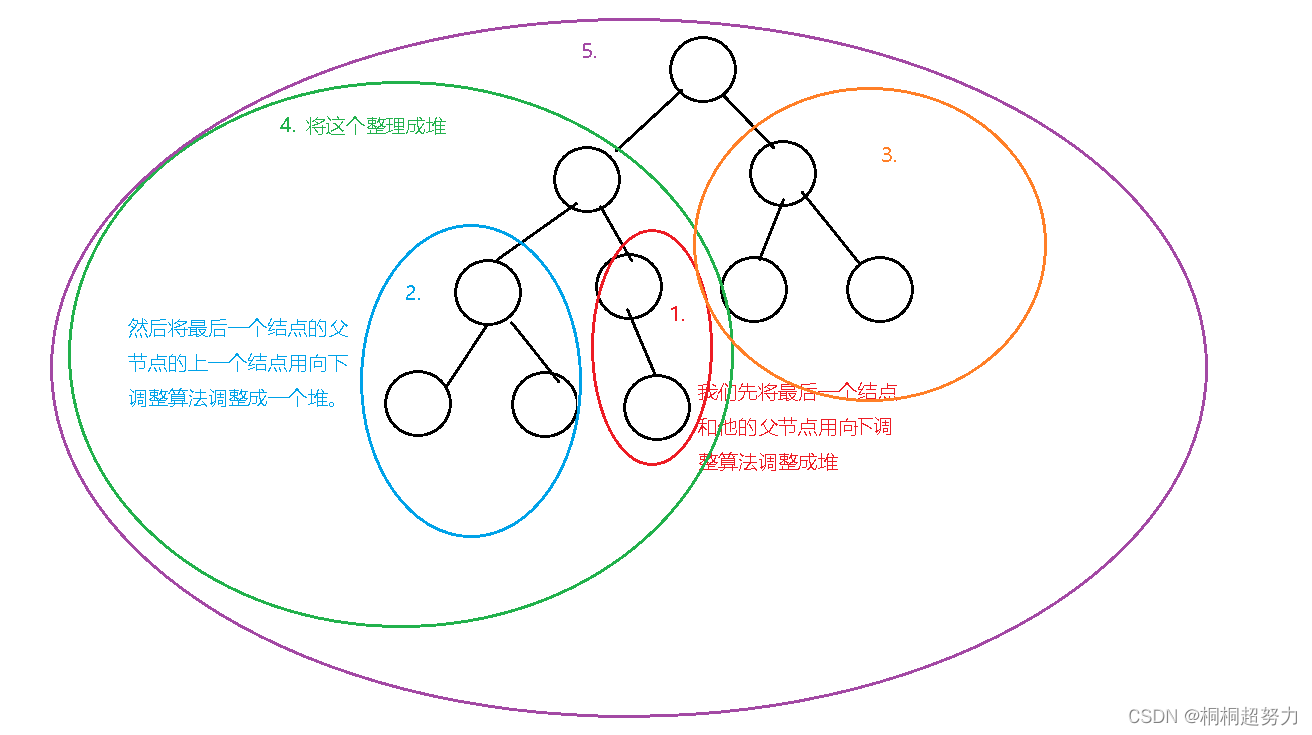
向下调整的建堆算法构建一个堆的代码
n表示这个数组有几个元素,而i表示我们的最后一个结点的父节点,然后就可以依次向下排序了,
//建堆算法
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(php->a, n, i);
}
堆排序
我们想要堆排序,首先我们就要建堆,有了堆我们才可以排序,所以我们怎么将一个数组变成一个堆呢?
首先有两种方法,
1.第一种就是用插入的思想,将每一个数一个一个插进去,这时就要用我们的向上调整算法。
2.第二种方法就是用我们的上面用向下调整算法的思想建堆
向上调整算法建堆
其实这个思想就是将我们的每一个数插入堆的方法,肯定大家又点不理解,下来画个图,大家就理解了
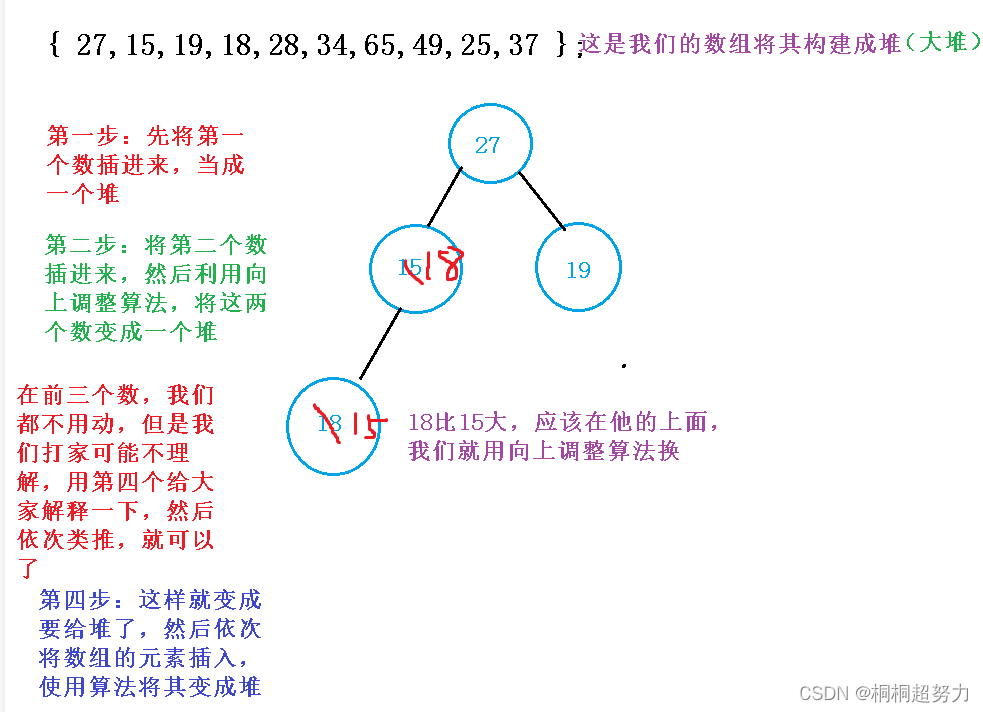
<1>向上调整算法建堆代码
就是如此的简单,将每个数遍历遍,依次使用建堆算法就ok了。
//向上调整建堆
for (int i = 1; i < n; i++)
{
AdjustUp(a, i);
}
<2>向上调整建堆的时间复杂度
我们向上调整算法将每个数遍历一遍,然后将每个数的都要进行向上调整算法,我们就可以通过计算算,高度为h,
第一层不需要调整,
第二层开始调整,第二层有 2 1 2^1 21个元素,每个再向上调整中进行了一次调整。
第三层有 2 2 2^2 22,每个数最多调整2次
依次类推,在第n层,有 2 h − 1 2^{h-1} 2h−1个元素,每个元素换h-1次。
所以可以算出
f ( h ) = 2 1 ∗ 1 + 2 2 ∗ 2 + 2 3 ∗ 3 … … 2 h − 1 ∗ ( h − 1 ) f(h)=2^1*1+2^2*2+2^3*3……2^{h-1}*(h-1) f(h)=21∗1+22∗2+23∗3……2h−1∗(h−1)
然后我们又知道N和h的关系, N = 2 h − 1 N=2^h-1 N=2h−1
算所有的太复杂,所以我们直接算最后一个,因为最后一层的结点最多,而且调整次数最多,可以代表整个的时间复杂度将h换成N。
F ( N ) ≈ ( ( N + 1 ) ( l o g 2 ( N + 1 ) − 1 ) ) / 2 F(N)≈((N+1)(log_2(N+1)-1))/2 F(N)≈((N+1)(log2(N+1)−1))/2
所以我们可以算出他的时间复杂对是 O ( N ∗ l o g 2 ( N ) ) O(N*log_2(N)) O(N∗log2(N))
向下调整算法建堆
我们在堆的构建用的就是向下调整算法,思路和代码都讲了,但是我们为什们用向下调整算法,等我们算完下面的时间复杂度就知道。
<1>向下调整算法的时间复杂度
有的同学,看都不看,看到了两个循环,直接就说他的时间复杂度是O( N 2 N^2 N2),这样都是打错特错了
首先分析一下,因为我们是从我们的最后一个数的父节点才开始算,我们的最后的叶子结点就不进行计算,而且我们想一下,我们的最多的结点不算,这种算法,一看这个时间复杂度就可以。
所以我们的最后一层没有进行堆排,
在我们的倒数第二层就进行一次调整
在倒数第三层进行2次调整
所以依次类推,第一层就进行h-1次调整
所以就可以计算
F ( h ) = 2 h − 2 ∗ 1 + 2 h − 3 ∗ 2 … … 2 2 ∗ ( h − 2 ) + 2 1 ∗ ( h − 1 ) F(h)=2^{h-2}*1 + 2^{h-3}*2……2^2*(h-2)+2^1*(h-1) F(h)=2h−2∗1+2h−3∗2……22∗(h−2)+21∗(h−1)
所以我们可以看出这是一个等差数列*等比数列,用一个错位相减法我们就可以算出 F ( h ) = 2 h − 1 − h F(h)=2^h-1-h F(h)=2h−1−h
我们又知道 N = 2 h − 1 N=2^h-1 N=2h−1,将h换成N就可以得到。
所以可以得出 F ( h ) = N − l o g 2 ( N + 1 ) F(h)=N-log_2(N+1) F(h)=N−log2(N+1)
所以他的时间复杂度就是O(N).
比较两种算法
我们比较算法就是通过时间复杂度和空间复杂度进行比较,我们很容易就比较出来了,明显是向下调整算法好。他的时间复杂度底。
其实这个我们也可以通过画思路图就可以看明白了,
在向上调整算法中,我们的最后的结点最多,并且向上进行最多次,
而在向下调整算法中,我们最后一层的结点都不进行排序,并且在倒数第二层最多的结点才进行一次,而到了最高层最少的结点进行最多次。
如果我们要升序,建大堆还是建小堆
首先先说答案:建大堆。
思路:为什们建大堆,我们大堆的头就是最大的数,这是无容置疑的,然后我们将最大的数和堆最后一个数进行交换,我们的再用向下调整算法调整堆不包括最后一个最大的数,(利用我们堆的删除的思路)知道我们的堆就剩下一个。
for (int i = 0; i < n; i++)
{
Swap(&a[0], &a[n - 1 - i]);
AdjustDown(a, n - 1 -i, 0);
}
这就是我们的堆排序
堆排序的时间复杂度
先说答案 O ( N ∗ l o g 2 ( N ) ) O(N*log_2(N)) O(N∗log2(N))
可以类比一下,我们的向上调整算法,我们的最后一层是最多的一层,同时进行向下调整的次数也是最多的,所以我们直接算最后一层的就可以了,
而最后一层的个数是 N = 2 h − 1 N=2^{h-1} N=2h−1,向下调整算法的时间复杂度为 O ( N ) O(N) O(N),
最后看 F ( h ) = 2 h − 1 ∗ ( h − 1 ) F(h)=2^{h-1}*(h-1) F(h)=2h−1∗(h−1)次然后进行换算一下,
O ( N ∗ l o g 2 ( N ) ) O(N*log_2(N)) O(N∗log2(N))
Top-K问题
-
什们是Top-K问题?
- 即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。 解决方法
-
- 用数据集合中前K个元素来建堆
前k个最大的元素,则建小堆,
前k个最小的元素,则建大堆
- 用数据集合中前K个元素来建堆
-
- 用剩余的N-K个元素依次与堆顶元素来比较,
不满足则替换堆顶元素将剩余N-K个元素依次与堆顶元素比完之后,
堆中剩余的K个元素就是所求的前K个最小或者最大的元素
- 用剩余的N-K个元素依次与堆顶元素来比较,
时间复杂度:
K
+
(
N
−
K
)
∗
l
o
g
k
K+(N-K)*logk
K+(N−K)∗logk=>
O
(
N
∗
l
o
g
k
)
O(N*logk)
O(N∗logk)
空间复杂度:O(K)