文章目录
- 一、背景介绍
- 二、方法介绍
- 三、实验论证
- 四、结论
- 五、感想
- 参考文献
一、背景介绍
1.问题介绍: 许多在自然图像上训练的深度神经网络都表现出一个奇怪的共同现象:在第一层,它们学习类似于Gabor过滤器和color blobs的特征。这样的第一层特征似乎并不特定于特定的数据集或任务,而是通用的(论文中简称general),因为它们适用于许多数据集和任务。而最后一层提取到的特征很大程度上取决于选定的数据集和任务(论文中简称specific)。
从上述现象我们便可以假设有这个结论:一定有一个类似于阈值的层数,当少于这个层数便不受任务和数据影响,大于这个层数便受任务和数据影响。
为了研究这个结论,必须要解决以下三个问题:
- 如何度量某一个网络层的general和specific程度。
- 这个阈值时对应的单个层还是多个层。
- 这个阈值发生在大概什么位置:靠近第一层,中间,还是靠近最后一层。
可以看出,第一个问题是关键,合理的量化后剩下两个问题的答案就呼之欲出了。
2.迁移学习: 在迁移学习中,通常在基础数据集和任务上训练基础网络,然后将学习到的特征重新用于或将它们转移到第二个目标网络,以便在目标数据集和任务上进行训练。如果特征是通用的,即适用于基础任务和目标任务,而不是特定于基础任务,则此过程往往会起作用。
通常的迁移学习方法是训练一个基础网络,然后将其前n层复制到目标网络的前n层。然后将目标网络的其余随机初始化并针对目标任务进行训练。在训练目标任务过程中,前n层可以被冻结即不参与训练,或者被微调。
关于选择微调还是冻结往往取决于目标任务的网络参数量和数据集相对大小。如果目标数据集相对基础数据集较小且目标网络参数相对较大,这时往往采用冻结避免欠拟合等。如果目标数据集很大或者目标网络参数量很少,为了避免过拟合,可以使用微调。
3.微调: 简单的说微调就是通常情况下神经网络在训练过程中使用的是随机初始化,但不少模型的结构和一些已经被训练好的模型部分结构相似,这时我们便可以拿训练好的模型的相似结构的模型参数作为待训练模型的初始化。
微调的好处有:
- 能够比随机初始化更快速的收敛
- 能够提高模型性能
4.Gabor过滤器: 表达式比较复杂,可以理解为一种滤波器,可以用来进行图片特征提取。Gabor常被用来作为边缘提取的滤波器。
二、方法介绍
量化general和specific
将在任务A上学习到的一组特征的普遍性定义为这些特征可用于另一个任务B的程度。就是使用迁移学习(冻结)把模型A前几层迁移到模型B上,使用数据集B来训练B,看看此时模型B得到的性能相较于baseline下降多少。
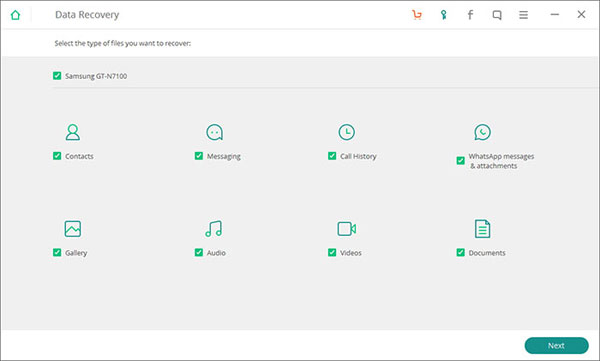
1.模型介绍
模型比较简单,就是几个卷积层加一个全连接层用来进行分类。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QzV6bxum-1677076879845)(C:\Users\21713\AppData\Roaming\Typora\typora-user-images\image-20230222205214738.png)]](https://img-blog.csdnimg.cn/3c00821524d34bc0913685931263daa6.png)
上图中A3A、B3B表示使用的是冻结进行迁移,A3A+、B3B+表示使用的是微调。这里比较有意思的设定是B3B和B3B+,这两个模型的基础任务和目标任务都是自己,数据集也一样,我一开始看的时候蒙蒙的,这个模型有啥用?别着急,后面的实验会给出答案。
这里作者在没有进行实验前就给出了一个结论就是当基础任务和目标任务相差太大,迁移性能便会下降。这也就需要分开讨论。同时,由于这是14年的论文(网络还是不是太深),14年之前有人得出结论,随机初始化的模型便具有不错的性能,故这东西也要拿出来进行对比。
三、实验论证
数据集介绍:a.相似数据集取的是ImageNet中100个类各随机选取一半;b.不相似数据集取的是ImageNet中A和B各自取人造实体和自然实体。
1.数据集相似
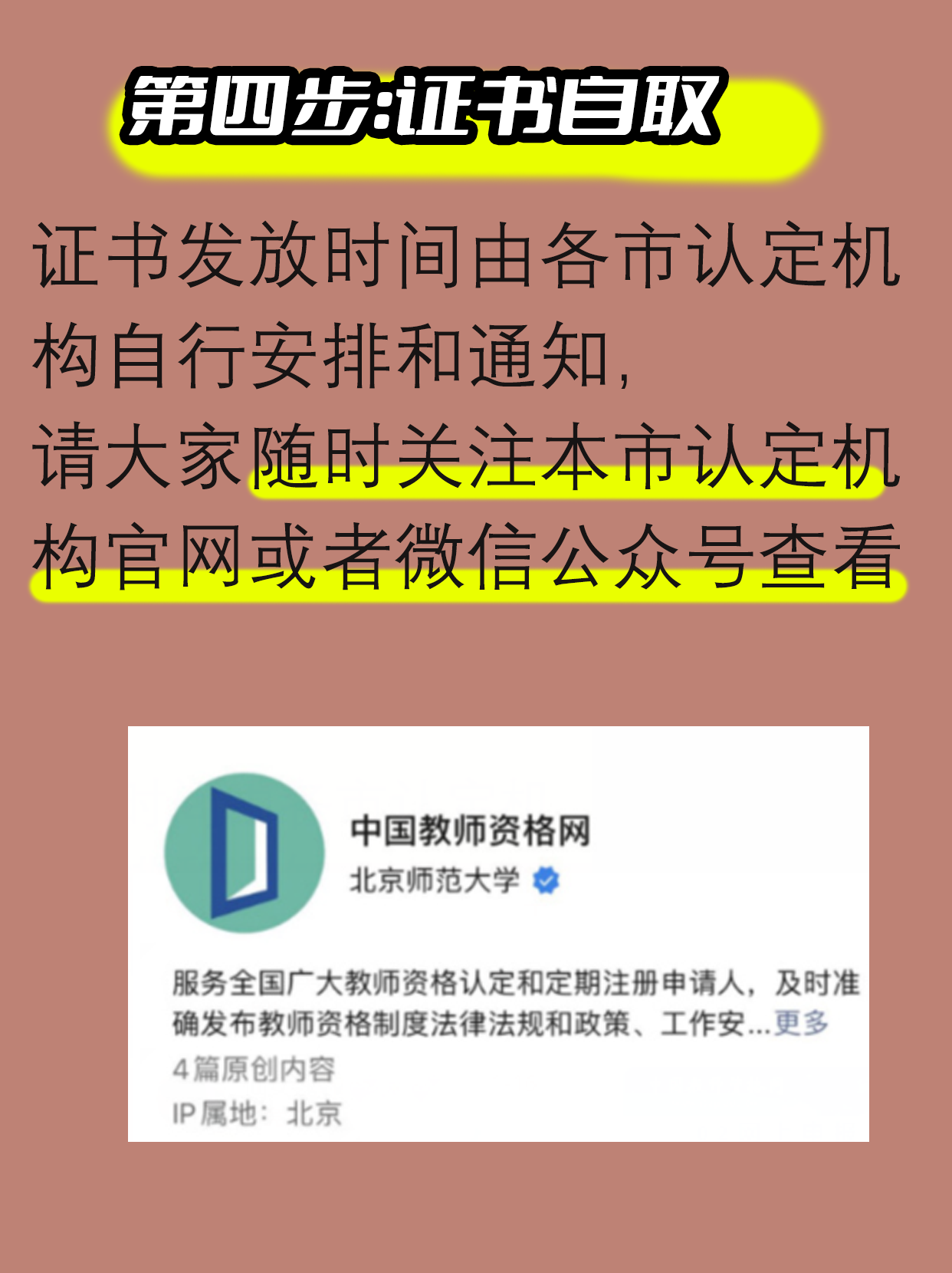
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存失败,源站可能有防盗链机制,建议将图片保存下来直接上传下上传(iPwfdIHETRsS-1677076879846)(C:\Users\21713\AppData\Roaming\Typora\typora-user-images\image-20230222213922583.png)(C:\Users\21713\AppData\Roaming\Typora\typora-user-images\image-20230222205214738.png)]](https://img-blog.csdnimg.cn/4617c32a03e24b25bf4efdabe2da4a9a.png)
这个图片上半幅数据没有看懂咋算出来这么多点的,下半幅就比较容易搞懂了。
a.首先看一下深蓝色的BnB结果。按照其网络结构,初始设想必然是认为最终结果必然是深蓝色结果和baseline B(白点)一样,因为毕竟是相同数据集和相同网络。但是结果却不是这样的。作者认为这种性能下降证明原始网络在连续层上包含脆弱的共同适应性特征(co-adapted features),即以复杂或脆弱的方式相互作用的特征,使得这种共同适应不能单独由上层重新学习。梯度下降能够在第一时间内找到一个很好地解决方案,但这是唯一可能的,因为这些层是联合训练(有层被冻结了无法参与训练)的。这就导致优化困难,在中间层尤其严重。随着层数的增加,这种情况就逐渐消失了,毕竟都快接近初始网络B了。
b.再看一下淡蓝色采用微调的BnB+,这个因为都是一起参与训练,便不会有上述脆弱的共同适应性特征,不好优化这个问题了。
c.深红色的AnB是本文采用的量化方法,可以看到当仅冻结前两层模型B的性能比baseline B好一点,可以得出前两层的特征是general。当冻结超过两层后,性能就直线下降。作者解释这个原因是因为(1)和BnB一样,有co-adapted features的原因存在(这时BnB设置的目的就体现出来了)。(2)另一个原因就是因为后面几层是specific的。
然后呢,作者还比较严谨的解释道,虽然有些迁移学习文章介绍冻结能够带来模型性能提升,这个AnB部分实验结果就有点违背了。产生这样的原因是(1)转移成功的程度已经逐层仔细量化,并且(2)这两种独立的影响已经分离,表明每种影响在制度的一部分中占主导地位。
d.浅红色的AnB+的结果有点令人出乎意料,他没有像深红色一样层数高于3层就性能大幅度下降,反而有些提升。在以前,人们可能想要迁移学习到的特征的原因是为了在不过度拟合小目标数据集的情况下进行训练,但这一新实验结果表明,即使目标数据集很大,迁移特征也会提高泛化性能。注意这种性能上的提升并不是因为迭代次数变多(微调增加了迭代次数)了,对比BnB+就可以知道了(这里就体现了为啥要设置BnB+)。
此外,我们可以发现当使用微调时,不能微调的是都少层,模型性能均有较大的提升。这也就说明了微调的可以用来提高模型性能。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yM51OY9e-1677076879846)(C:\Users\21713\AppData\Roaming\Typora\typora-user-images\image-20230222222657426.png)]](https://img-blog.csdnimg.cn/c9567cf7503b4b32b18855edc26c56d2.png)
2.不相似数据集
这里实验就做的少了,作者仅说了由于数据集不相似导致迁移性能下降。
3.随机初始化权重
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b9oTCNAJ-1677076879847)(C:\Users\21713\AppData\Roaming\Typora\typora-user-images\image-20230222223112064.png)]](https://img-blog.csdnimg.cn/bcb46a91635746809d653b60ac9fc4ab.png)
这里作者主要像通过实验表明,虽然任务不同导致迁移性能下降,但是随机初始化还是没有迁移学习牛。此外,作者还说明为啥之前有人说随机初始化就可以获取得到不错的性能,是因为他们的baseline过拟合了,即对比实验对象性能没有发挥好(哈哈哈)。
One possible reason this latter result may differ from Jarrett et al. (2009) is because their fully-trained (non-random) networks were overfitting more on the smaller Caltech-101 dataset than ours on the larger ImageNet dataset, making their random filters perform better by comparison.
四、结论
1.如何度量训练好特征层的普适性。
2.微调确实可以提高模型性能。
3.我们在进行迁移学习时(我觉得应该是冻结方式吧)要注意co-adapted features带来的问题。
五、感想
1.感觉这篇论文得到的结论有点和何凯明大神的论文唱反调(并没有)。
2.实验做的太少了,根据一个实验就得出了结论。不知道可不可信,毕竟得到的结论是通用性结论。
3.实验分析的贼到位,有理有据。
4.实验切入点找的好。
参考文献
- 什么是微调