Redis的缓存穿透、缓存雪崩和缓存击穿
- 一. 缓存穿透
- 1.1 概念
- 1.2 造成的问题
- 1.3 解决方案
- 1.4 案例:查询商铺信息(缓存穿透的实现)
- 二. 缓存雪崩
- 2.1 概念
- 2.2 解决方案
- 三. 缓存击穿(热点key)
- 3.1 概念
- 3.2 解决方案
- 3.3 案例:查询商铺信息(互斥锁和逻辑过期的实现)
- (1)互斥锁
- 补充:SETNX(setIfAbsent)
- (2)逻辑过期
一. 缓存穿透
1.1 概念
缓存模型;
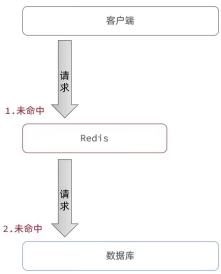
定义:指客户请求的数据在缓存中和数据库中都不存在!这样缓存永远不会命中,请求都会发到数据库;
(穿透即穿透了缓存和数据库);
1.2 造成的问题
假设不断发送这样的请求,则会让数据库崩溃;
1.3 解决方案
(1)主动
- 增加请求参数的复杂度且有一定规范,对请求参数提前做校验;
- 加强用户权限校验,如用拦截器校验登录状态;
- 热点参数的限流
(2)被动
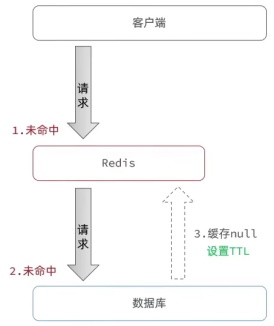
- 缓存空对象:
为了不再让请求造成缓存穿透,则产生一个null空值(value=””)到redis中,当下次再请求时就可以从Redis返回而不用去查数据库;
优点:简单
缺点:
①造成Redis中的内存消耗;----- 对这样的null值数据设置TTL有效时间;
②短期不一致:Redis中存了null值,但是数据库此时真的增加了这条数据,而缓存中数据和数据库不一样,当有用户来查询时会查到null数据;------ 缩短TTL时间 或者手动覆盖数据到Redis中;
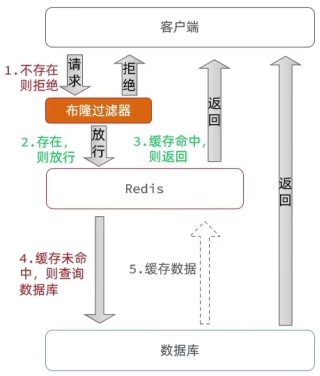
- 布隆过滤
【在请求访问Redis之前】添加一个布隆过滤器;
布隆过滤器中存储的是byte字节数据,存储的是二进制位;
数据库中的数据会经过Hash算法,将计算后的值存到布隆过滤器,当请求发过来时,会判断请求的Hash值是否存在于过滤器中,若过滤器判断不存在则一定不存在;
若过滤器判断存在,则只是可能存在,不是100%准确,所以依然有一定缓存穿透风险的;
优点:内存占用少,只需要存Hash值,没有多余key
缺点:实现相对复杂;可能误判(哈希冲突);
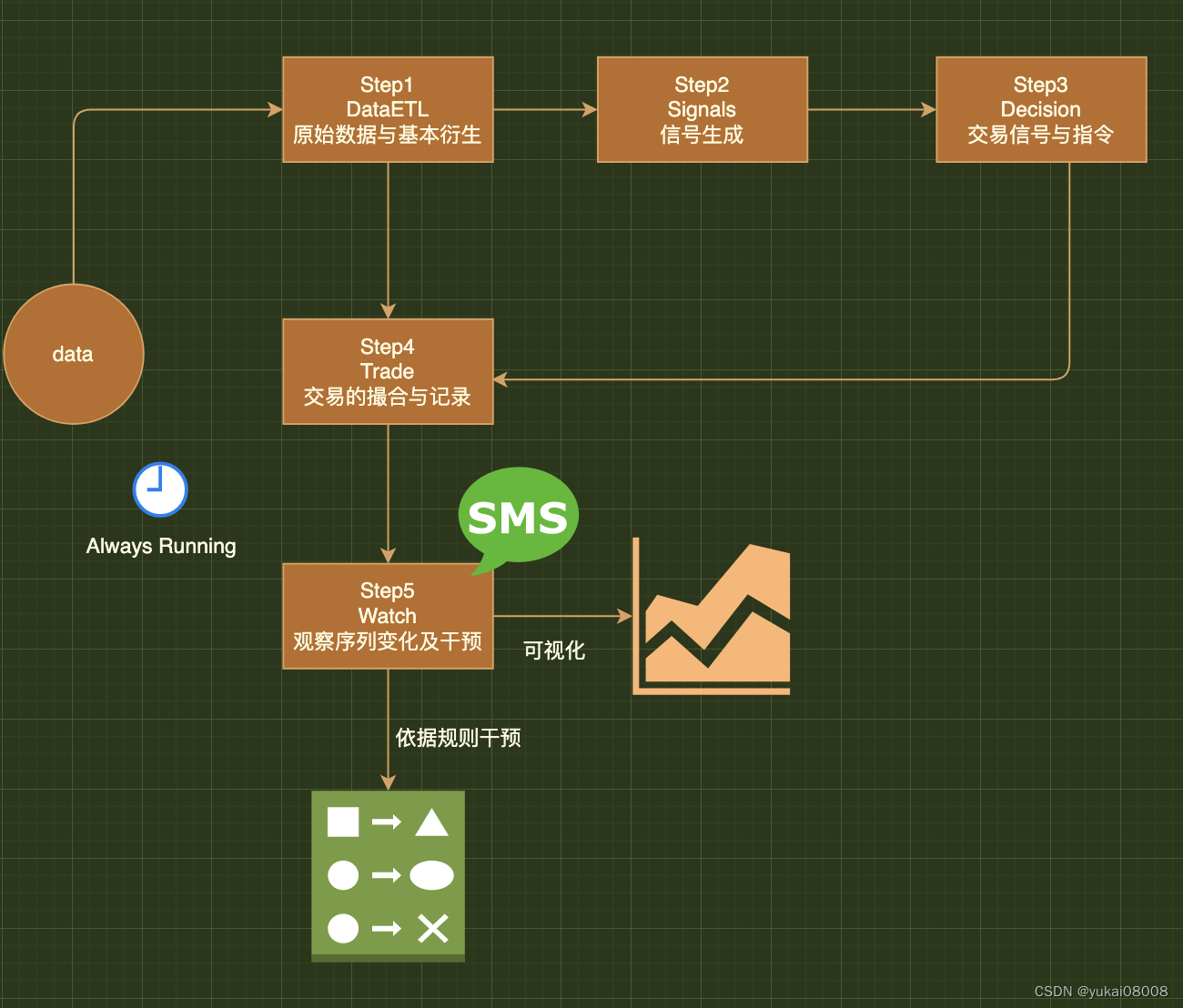
1.4 案例:查询商铺信息(缓存穿透的实现)
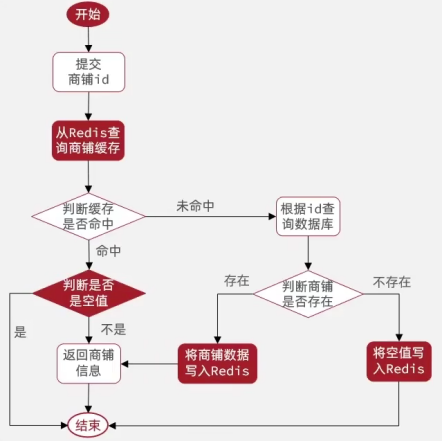
业务逻辑:
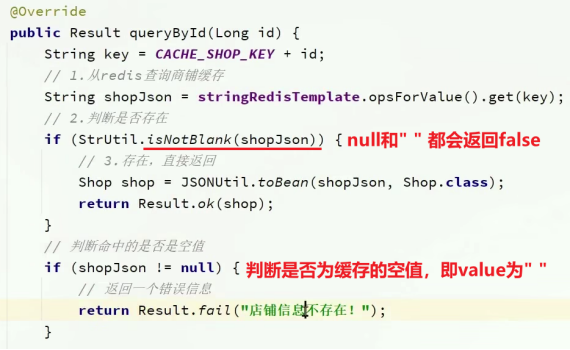
1.注入stringRedisTemplate的bean,从Redis查询商户缓存,如果命中则判断是不是空值,不是则返回商铺信息,是则返回不存在;
2.未命中则查询数据库,若不存在,报错;
3.若数据库中存在,则用stringRedisTemplate.opsForVlaue将商铺信息更新到Redis中,并更新TTL有效时间(兜底)!
4.如果数据库中也不存在(缓存穿透),则将空值写入Redis,即value=“”;

效果:
发送id不存在的查询请求,查询Redis和数据库,缓存穿透了,返回“不存在”,会在Redis缓存一个空值;
假设再发送同样的请求,则查询到Redis中的空字符串数据,还是返回“不存在”,但是不走数据库了!

总结:1. 缓存穿透则写入空值 2. Redis命中时需要判断是否为空字符串;
二. 缓存雪崩
2.1 概念
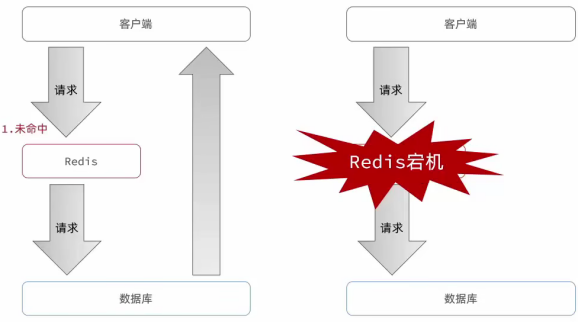
定义:同一时段内有①大量的缓存Key同时失效过期 或者 ②Redis服务宕机,导致大量请求发往数据库,带来巨大压力;
2.2 解决方案
(1)针对大量缓存同时失效:
- 给不同的key的TTL添加随机值;
- 给缓存业务添加降级限流策略,牺牲部分服务,保护数据库;
(2)针对Redis宕机:
- 启用熔断机制暂停服务;
- 用主从节点的方式建立Redis高可用集群,哨兵机制 可以实现对服务的监控(类比Kafka),主从实现数据同步;
- 在多个层面建立缓存,让Nginx也做缓存,Nginx未命中,再去Redis,再去JVM,最后才是数据库
多级缓存在大型电商中如商品详情会使用,以应对亿级以上的并发;
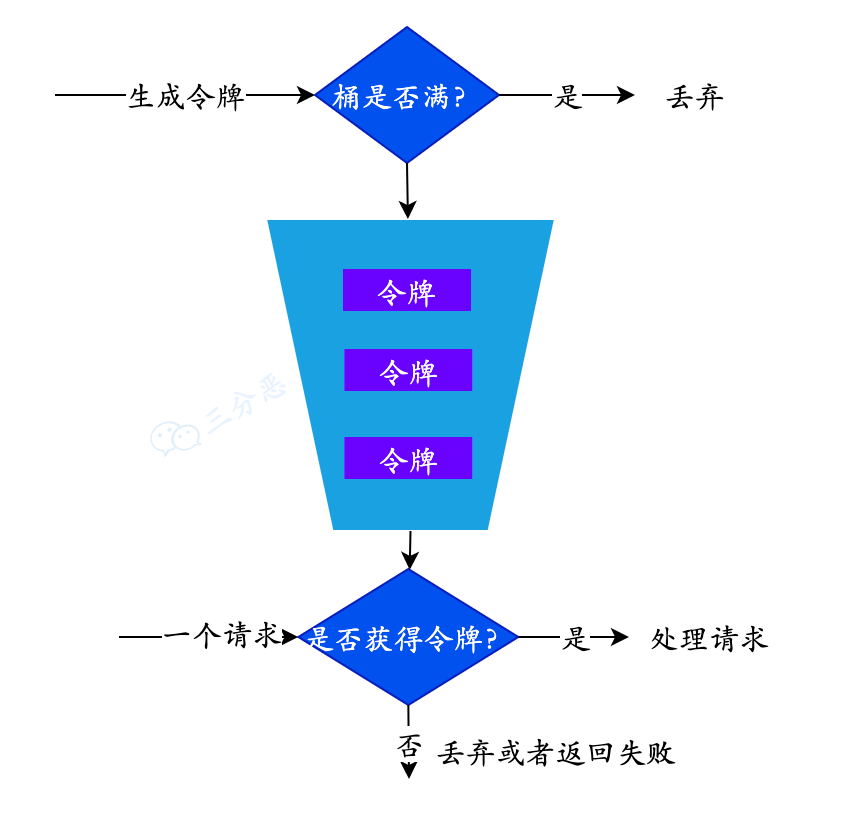
三. 缓存击穿(热点key)
3.1 概念
定义:
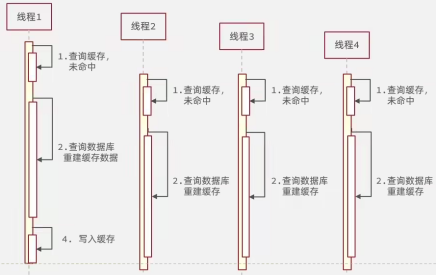
业务通常会有几个数据会被 ①频繁访问,比如秒杀活动,且 ②缓存重建业务比较复杂,这类被频地访问的数据被称为 热点数据。
如果缓存中的某个热点数据过期了且缓存重建耗时较长,此时大量的请求线程都会去缓存重建,会对数据库带来巨大冲击;
3.2 解决方案
(1)互斥锁
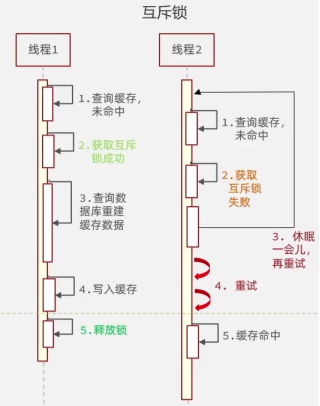
所有请求都去尝试缓存重建,所以用互斥锁的方式只让一个请求线程去缓存重建;
只有获取到锁的请求线程才能去进行缓存重建;而其他请求线程则休眠一会再查询,直到锁释放后,再访问到新的缓存;
优点:保持数据的一致性
缺点:线程需要等待,性能不好(牺牲可用性)
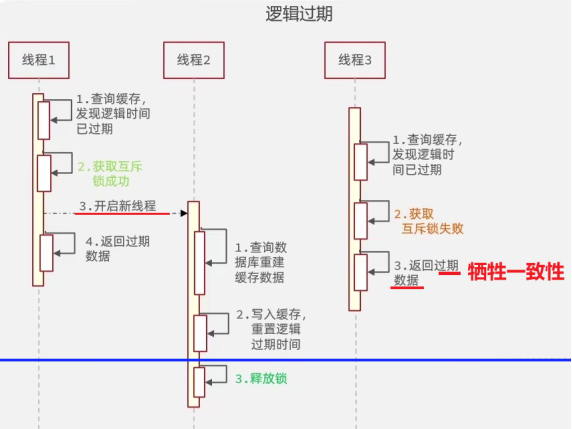
(2)逻辑过期
- 缓存穿透的原因就是因为热点数据过期,所以设置一个
逻辑过期让热点数据在Redis中永不过期(不设置TTL);
新增一个过期时间的字段放到Value中,让线程可以判断是否逻辑过期;(类似MyBatisPlus的逻辑删除),但实际上不是TTL,这样每次都能命中; - 线程发现热点数据已经逻辑过期,就尝试获取互斥锁,
①如果获取锁成功,则再 开启一个新的线程 去缓存重建,原线程返回旧数据;
②获取失败则返回旧数据;
优点:线程不需要等待,性能好(保证可用性)
缺点:牺牲一致性
注意:
互斥锁方法和逻辑过期都用了互斥锁,前者当其他线程发现锁被占用后则会一直重试等待直到缓存重建完成;
后者当其他线程发现数据逻辑过期后才去尝试获取锁,锁被占用则获取旧的热点数据,而不会一直等待;
总结:互斥锁和逻辑过期都是在解决缓存重建时的并发问题; 互斥锁即让请求线程等待,保证一致性;逻辑过期是可以拿到旧数据即保证了可用性,但是牺牲了一致性。
3.3 案例:查询商铺信息(互斥锁和逻辑过期的实现)
(1)互斥锁
流程:
1.注入stringRedisTemplate的bean,从Redis查询商户缓存,如果命中返回商铺信息,
2.如果未命中则尝试获取锁,注意锁的key不是商铺id,
3.没有拿到锁则休眠一会,再重新尝试查询Redis(递归);
4.获取到锁则缓存重建,缓存重建需要去查询数据库,查完后更新Redis,释放锁;
5.返回结果;
先建立加锁和解锁两个方法:
为了防止锁永不释放,给锁加有效期(兜底)

业务逻辑:


测试:
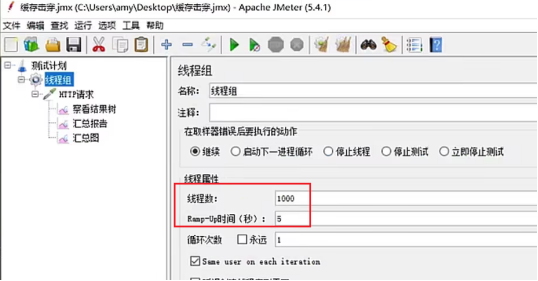
使用JMeter模拟多线程并发的场景;
设置1000个线程,时间共5s,QPS=200/s;
结果:
Idea中显示只查询了一次数据库,成功;
补充:SETNX(setIfAbsent)
SETNX / setIfAbsent:(NX=not exist)即key不存在时才能set成功! 用来作 互斥锁 使用;
例:
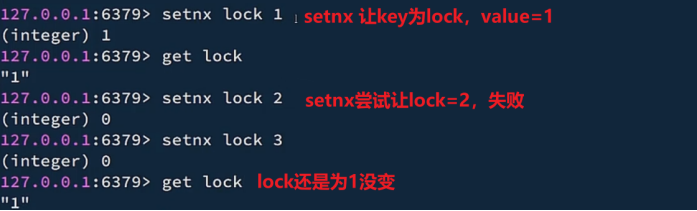
即相当于是互斥锁,只有第一个能成功!后面的都失败了!
释放锁:

为了防止锁永远不被释放,一般加有效期(兜底):假设10秒,一般业务执行在1秒内;