文章目录
- 📚数组操作
- 🐇np数组的构造
- 🥕np数组的构造
- 🥕特殊补充
- 🐇np数组的变形和合并
- 🥕转置
- 🥕合并操作
- 🥕维度变换
- 🐇np数组的切片和索引
- 🥕一维数组索引与切片
- 🥕二维数组索引和分片
- 🥕补充布尔索引
- 🥕分片规则大致理解
- 📚常用函数
- 🐇numpy常用统计函数
- 🥕离中趋势
- 🥕集中趋势
- 🐇numpy实用方法
- 📚补充
- 🐇轴概念的补充
- 🐇二维数组计算
- 📚小结
📚数组操作
import numpy as np
🐇np数组的构造
🥕np数组的构造
ndarray 是 N-dimensional array,即 N 维数组。数组是一系列 相同类型 数据的集合,它其实和列表很相似,只是列表中的元素类型可以是任意的。

-
建一个多维数组很简单,将一个列表作为参数传入numpy中的array()方法即可,打印出来的多维数组和列表也很像,只是少了分隔的逗号
import numpy as np data = np.array([1, 2, 3]) print(data) # 输出:[1 2 3] print(type(data)) # 输出:<class 'numpy.ndarray'> -
两个快速创数组实用方法——
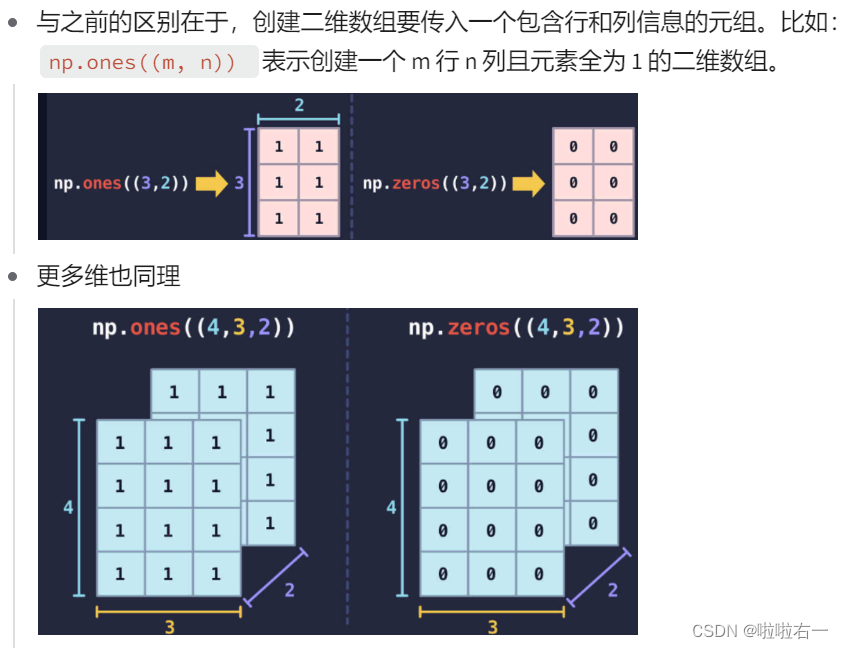
np.ones()和np.zeros()ones = np.ones(3) print(ones) # 输出:[1. 1. 1.] zeros = np.zeros(3) print(zeros) # 输出:[0. 0. 0.]- 分别生成元素全为1和0的多维数组,np.ones() 和 np.zeros() 的参数用于指定生成的多维数组里有多少个元素。
- 生成出来的不是 1 和 0,而是
1.和0.。这是因为默认生成的是浮点数,numpy 会省略小数点后的 0,因此1.0和0.0变成了1.和0.。
-
单位矩阵生成——
np.eyes(3)

-
和列表进行类比,二维数组相当于单层的嵌套列表。
# 单层嵌套列表 nested_list = [[1, 2], [3, 4]] print(nested_list) # 输出:[[1, 2], [3, 4]] # 二维数组 data = np.array(nested_list) print(data) # 输出: # [[1 2] # [3 4]]- 嵌套列表就是列表中的元素也是列表的列表。
- 可以看到,通过嵌套列表创建的二维数组也是用空格分隔的,并且分成了两行。列表中的第一个元素 [1, 2] 在第一行,第二个元素 [3, 4] 在第二行。
- 更多维的数组的创建,只要传入嵌套层数更多的列表即可。创建三维数组的方式如下

-
ones()和zeros()在二维数组的应用
🥕特殊补充
- 等差数列
np.linspace(起始,终止(包含),样本个数)

np.arange(起始,终止(不包含),步长)

- 关于
arange()- 一个参数时:参数值为终点(不包括),起点取默认值0,步长取默认值1
- 两个参数时:第一个参数为起点,第二个参数为终点(不包括),步长取默认值1
- 三个参数时:第一个参数为起点,第二个参数为终点(不包括),第三个参数为步长,步长支持小数
# 生成 1-9 的数组 print(np.arange(1, 10)) # 输出:[1 2 3 4 5 6 7 8 9] # 生成 0-9 的数组 print(np.arange(10)) # 输出:[0 1 2 3 4 5 6 7 8 9] # 生成 1-9 的数组,步长为 2 print(np.arange(1, 10, 2)) # 输出:[1 3 5 7 9] - 随机矩阵
np.random.uniform(5, 15, 3), 从5到15随机生成3个数np.random.randn(3),生成标准正态分布np.random.randint(low, high, size), randint可以指定生成随机整数的最小值最大值(不包含)和维度大小
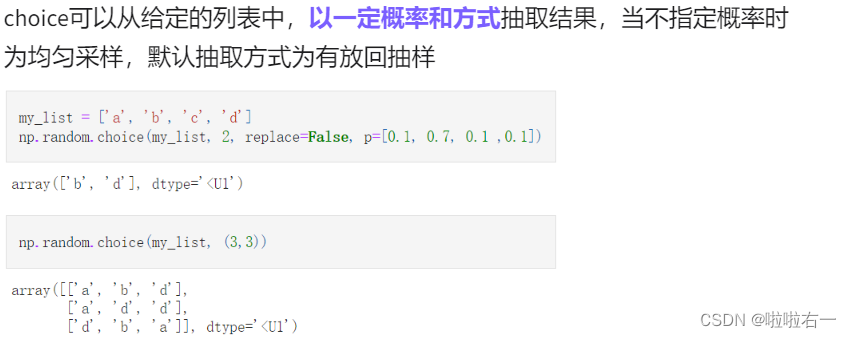
# 不传入形状时 print(np.random.randint(0, 5)) # 输出:3 # 形状为一维数组时 print(np.random.randint(0, 5, 3)) # 输出:[4 0 1] # 形状为二维数组时 print(np.random.randint(0, 5, (2, 3))) # 输出: # [[0 2 1] # [4 2 0]]np.random.choice(my_list, 2, replace=False, p=[0.1, 0.7, 0.1 ,0.1])
- numpy 中的
np.random.rand()方法和 Python 中random.random()方法类似,都是生成 [0, 1) 之间的随机小数。不同的是,numpy 中的 np.random.rand() 方法可以生成多个 [0, 1) 之间的随机小数,只需我们传入要生成的随机数组的形状(shape)即可。# 不传参数时 print(np.random.rand()) # 输出:0.1392571183916036 # 传入一个参数时 print(np.random.rand(3)) # 输出:[0.7987698 0.52115291 0.70452156] # 传入多个参数时 print(np.random.rand(2, 3)) # 输出: # [[0.08539006 0.97878203 0.23976172] # [0.34301963 0.48388704 0.63304024]]
🐇np数组的变形和合并
🥕转置

🥕合并操作

🥕维度变换
参考博客
reshape——能够帮助用户把原数组按照新的维度重新排列。在使用时有两种模式,分别为C模式和F模式,分别以逐行和逐列的顺序进行填充读取。

🐇np数组的切片和索引
🥕一维数组索引与切片
-
索引——和列表基本相同
data = np.array([1, 2, 3]) print(data[0]) # 输出:1 -
分片——和列表基本相同
data = np.array([1, 2, 3]) print(data[0:2]) # 获取索引为 0 和 1 的元素 # 输出:[1 2] # 获取前 2 个元素 print(data[:2]) # 输出:[1 2] # 获取后 2 个元素 print(data[-2:]) # 输出:[2 3] # 获取所有元素 print(data[:]) # 输出:[1 2 3]
# 列表 lst_data = [1, 2, 3] lst_data2 = lst_data[:] lst_data2[0] = 6 print(lst_data) # 输出:[1, 2, 3] # 多维数组 arr_data = np.array([1, 2, 3]) arr_data2 = arr_data[:] arr_data2[0] = 6 print(arr_data) # 输出:[6 2 3]
-
分片支持传入第三个参数——步长。即分片时每隔几个数据取一次值,步长的默认值为 1。
data = np.array([1, 2, 3, 4, 5, 6]) print(data[::2]) # 省略前两个参数 # 输出:[1 3 5]-
当步长为负数时,会将顺序反转。我们可以利用这个特性来实现列表或多维数组的快速反转。
data = np.array([1, 2, 3, 4, 5, 6]) print(data[::-1]) # 省略前两个参数 # 输出:[6 5 4 3 2 1]
-
🥕二维数组索引和分片
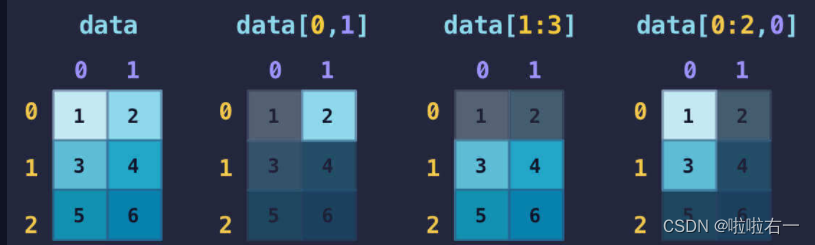
二维数组的索引和分片同样和一维数组类似,只是在行索引的基础上再加上列索引。形如 data[m, n],其中 data 是二维数组,m 是行索引或分片,n 是列索引或分片。

data = np.array([[1, 2], [3, 4], [5, 6]])
print(data[0, 1])
# 输出:2
print(data[:, 0])
# 输出:[1 3 5]
print(data[1:3])
# 输出:
# [[3 4]
# [5 6]]
data[0:2, 0] 和 data[0:2, 0:1] 获取的都是 1 和 3 这两个元素,但其结果一个是 [1 3],一个是 [[1] [3]],实际上并不相同。
🥕补充布尔索引

区别在于:and 改用 &,or 改用 |,not 改用 ~,并且每个条件要用括号括起来。
🥕分片规则大致理解

📚常用函数
🐇numpy常用统计函数
写法都是数组名.函数()
🥕离中趋势

🥕集中趋势


🐇numpy实用方法
-
genfromtxt():用于文件的读取- 常用的参数有两个。第一个参数是数据源,可以是本地文件的路径,也可以是网络文件的地址。delimiter 参数用于指定分隔符,CSV 文件一般是用逗号作为分隔符,当遇到其他符号分隔的文件时,用 delimiter 参数进行指定即可。
- genfromtxt() 方法的返回值是一个多维数组
data = np.genfromtxt('data.csv', delimiter=',')
-
numpy求均方误差

- 均方误差和方差形式上相似,不同在于:方差是数据集与均值的关系,而均方误差是数据集与真实值之间的关系
-
where:一种条件函数,可以指定满足条件与不满足条件位置对应的填充值

-
nonzero返回非零数的索引,argmax,argmin分别返回最大和最小数的索引

-
数组名.any()指当序列至少 存在一个True或非零元素时返回True,否则返回False -
数组名.all()指当序列元素全为True或非零元素时返回True,否则返回False
📚补充
🐇轴概念的补充
关注一维和二维axis=0所指方向的不同
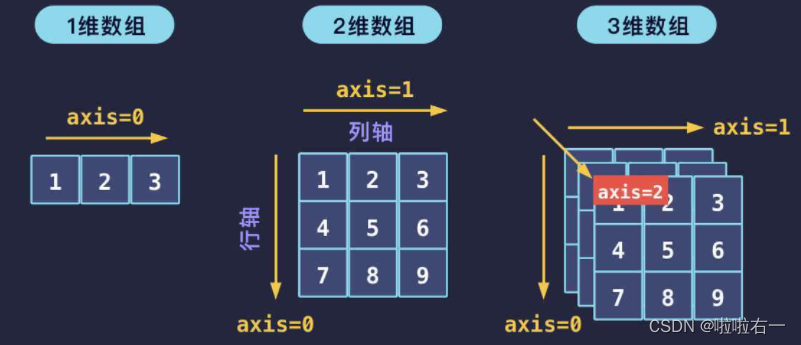
在通用方法中,通过 axis 参数可以指定计算方向。

data = np.array([[1, 2], [5, 3], [4, 6]])
# 不指定 axis
print(data.max())
# 输出:6
# axis=0
# 每一列都比一比
print(data.max(axis=0))
# 输出:[5 6]
# axis=1
# 每一行都比一比
print(data.max(axis=1))
# 输出:[2 5 6]
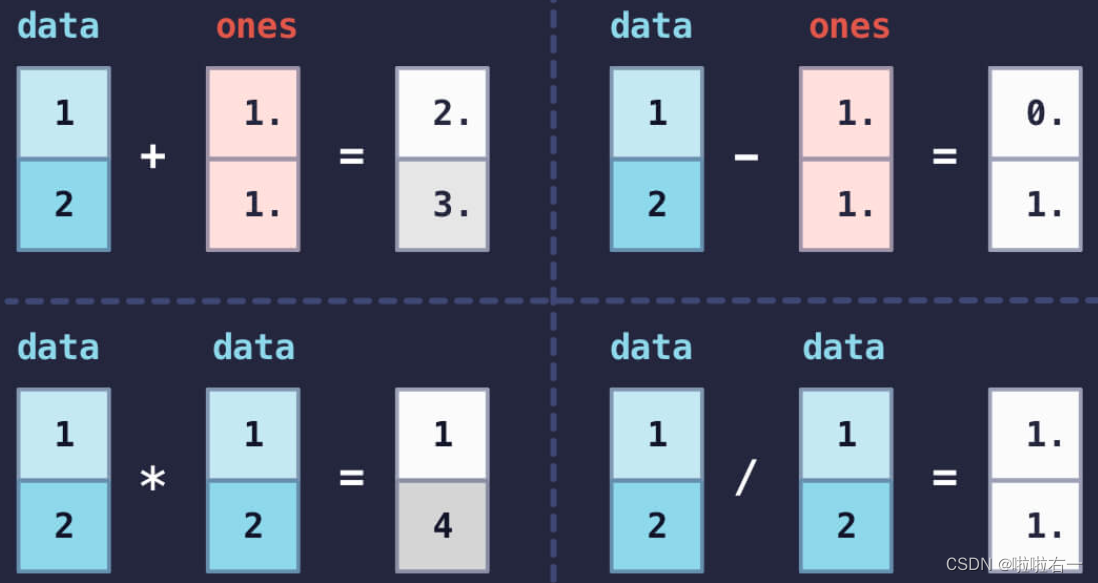
🐇二维数组计算

📚小结