前言: 之前在某大型保险公司担任技术经理,负责优化话务系统模块,由于系统已经运行10年之久,尤其在话务系统中,沉积了几十亿的话务信息表,业务人员反馈,话务系统历史数据查询部分已经完全查询不动,且数据增量仍然已每天200w+以上,数据库频繁报警,优化迫在眉睫。
在我接手之前,该系统已经经历过几个版本的优化。
1 冷热分离,热表存储三个月内数据,历史表存储历史数据,每天凌晨通过oracle的存储过程迁移。同时通过修改业务,页面上加了个按钮,是否查询历史数据,如果查询历史数据需要勾选上,当然,在如此大的数据量面前,即使勾选上也是查询不出来的,页面上无限转圈,功能处于不可用状态。
2 请了外援,由某为公司优化,当时给的方案是所有数据使用gaussdb存储,通过设置分片分区键,改动原有业务,单独启动一个jar包提供接口服务,集成了mybatils,通过sql拦截器,校验,如果有sql没有带上分区或者分片键,则不给查询。最后所有的查询就变成了
select * from xxx where 分区键='' and 分片键 = ''数据迁移部分,利用过年放假期间,采用停机迁移的方式。新版本改动较大,虽然经历了较长时间的测试,但是也不敢保证不出问题,所以在业务测也保留了原有业务,随时切换到原有业务,业务代码变成了这样。
if(开启新业务) {
http.post();
} else {
原有业务代码
}据老员工说,这次改动性能确实不错,相关查询处于可用的状态,但是数据库稳定性不高,经常报警,也不是很稳定,后来由于大领导们的某些不可控因素,合作终止,gaussdb没人维护,自然这个方案也就被否决了。
3 这时候我入职了,这部分优化工作就落到了我的头上,由于公司和腾讯合作,免费提供了Tbase给我们应用,这样的话,我们就可以采用华为的思路,用Tbase替代了gaussdb,同时做了sql的适配。做了技术预研,只分配了一个分片键的数据到数据库中,大概4000多w的数据,用时间做分区,效果还是不理想,业务侧需求是至少每次查询要查询一个月内的数据,由于还要通过其他表的数据来做关联查询,sql是这样的
select * from a left join b left join c left join da,b,c,d四张表都是上亿的数据,虽然有分片分区键,效果仍然很差,只有时间范围精确到天的时候,才能做到秒级响应,也就是页面上的筛选条件需要由"月" 改成 "天",但是这样业务员是无法接受的。
4 第四版优化,由于第三版技术调研失败,我们换了个思路,利用大数据组件来做这部分优化。
思路是 通过Elasticsearch来做条件筛选,里面存储话务表的id,然后通过id去Hbase做数据查询。
通过技术调研,将一个省分的全量数据放到es和hbase后,通过省份做es的分片,查询可以做到秒级返回。
但是这样就涉及到了数据同步问题,如果做到Tbase数据表 -》 es + hbase
因为我们在关系型数据库,同步到es+hbase的时候,由于数据类型以及业务逻辑不一样,是需要做比较重的逻辑处理,所以这部分只能通过代码实现,于是写了一个数据同步组件。
数据同步组件包含两部分,一部分是离线历史数据同步,还有实时数据同步,实时数据同步架构如下。
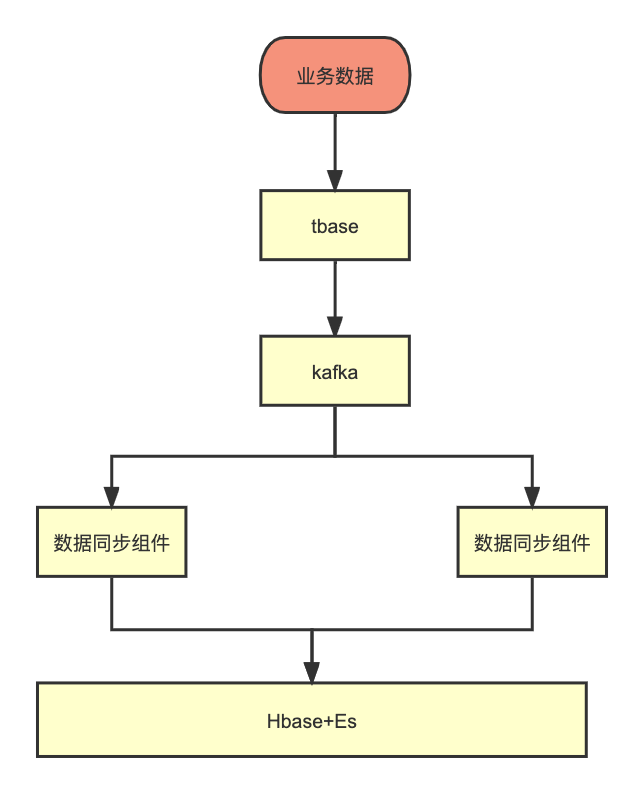
注意这里,由于数据同步需要保证顺序性,需要保证kafka的同一个partition只有一个消费者在消费,这里kafka的分区设置策略需要设置成range,代码如下
import org.apache.kafka.clients.consumer.*;
import java.util.*;
public class MyConsumer {
public static void main(String[] args) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "my_consumer_group");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, "range");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("my_topic"));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.println("Received message: " + record.value());
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
consumer.close();
}
}
}
这个架构在很多场景都得到了验证,例如上百亿的保单表也是这么存储的,Hbase存储保单详情,es存储查询条件。至此,问题得到了比较完善的解决,这里面还存在很多细节问题,比如数据同步组件包含两个方面,一个是离线同步,一个是实时同步。
离线数据同步部分要支持不停机同步,这部分内容比较多,下一篇在介绍吧。