1:数据类型处理
#
sep=‘\s+‘ 这是正则表达式,通过一定规则的表达式来匹配字符串用的 \s 表示空白字符,包括但不限于空格、回车(\r)、换行(\n)、tab或者叫水平制表符(\t)等,这个根据编码格式不同代表的含义也不一样,感兴趣可以搜索看一下 + 是重复修饰符,表示它前面与它紧邻的表达式格式相匹配的字符串至少出现一个,上不封顶 \s+ 意思就是至少有一个空白字符存在
————————————————
版权声明:本文为CSDN博主「舞动的白杨」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_37706204/article/details/120827447
#字段含义加载
#coding=utf=8
import pandas as pd
pd.set_option('display.max_columns',None)
df=pd.read_csv('./CDNOW_master.txt',header=None,sep='\s+',names=['user_id','order_dt','order_product','order_amount'])#让第一行不能作为索引,添加列索引
print(df.head())
#print(df.info())#观察数据类型和数据的缺失值
df.info
#将年月日换成时间类型
df=pd.to_datetime(df['order_dt'],format='%Y%m%d')
print(df)#查看总描述
df=pd.to_datetime(df['order_dt'],format='%Y%m%d')
print(df)#原始数据中添加一列表示月份
#coding=utf=8
import pandas as pd
pd.set_option('display.max_columns',None)
df=pd.read_csv('./CDNOW_master.txt',header=None,sep='\s+',names=['user_id','order_dt','order_product','order_amount'])#让第一行不能作为索引,添加列索引
df['order_dt']=pd.to_datetime(df['order_dt'],format='%Y%m%d')
df['Month']=df['order_dt'].values.astype('datetime64[M]')
print(df.head())
第二部分:按月数据分析
#用户每月花费的总金额
#coding=utf=8
import pandas as pd
pd.set_option('display.max_columns',None)
df=pd.read_csv('./CDNOW_master.txt',header=None,sep='\s+',names=['user_id','order_dt','order_product','order_amount'])#让第一行不能作为索引,添加列索引
df['order_dt']=pd.to_datetime(df['order_dt'],format='%Y%m%d')
df['Month']=df['order_dt'].values.astype('datetime64[M]')
print(df.head())
#绘制折线图
df.groupby(by='Month')['order_amount'].sum().plot()
plt.show()#所有用户每月产品的购买量
df.groupby(by='Month')['order_product'].sum().plot()
plt.show()#所有用户每月消费的次数
print(df.groupby(by='Month')['order_product'].count())#统计每月消费的人数
print(df.groupby(by='Month')['user_id'].nunique())2:
#求每一个用户消费的总金额
print(df.groupby(by='user_id')['order_amount'].sum())#求每一个用户消费的总次数
print(df.groupby(by='user_id')['order_amount'].count())
#散点图
user_amount_sum=df.groupby(by='user_id')['order_amount'].sum()
user_product_sum=df.groupby(by='user_id')['order_product'].count()
plt.scatter(user_product_sum,user_amount_sum)
plt.show()
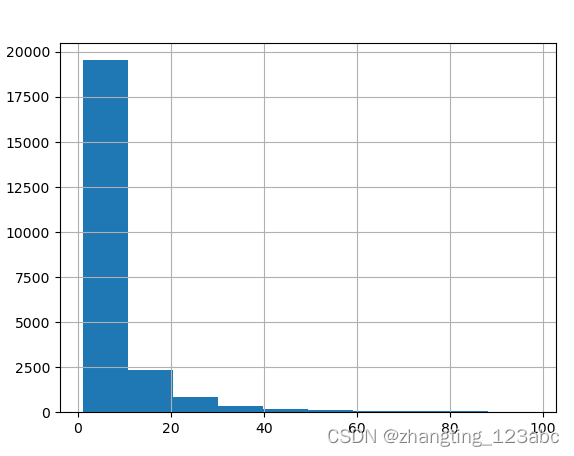
#各个用户消费总金额的直方分布图(金额在1000以内)
df.groupby(by='user_id').sum().query('order_amount<=1000')['order_amount'].hist()
plt.show() 
#各个用户消费的总数量的直方分布图(消费商品的数量在100次之内的分布
df.groupby(by='user_id').sum().query('order_product<=100')['order_product'].hist()
plt.show()