1.引子
记得之前面试过一个同学,有这么一个题目:
LinkedList<String> list = new LinkedList<>();
for (int i = 0; i < 1000; i++) {
list.add(i + "");
}
请根据上面的代码,请选择比较恰当的方式遍历这个集合,并简要解释原因。
说实话,比较出乎我的意外,很多同学都用for循环的方式来遍历:、
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
居于此,我们从头看一下这个LinkedList集合。
2. LinkedList
2.1 LinkedList类的层次结构
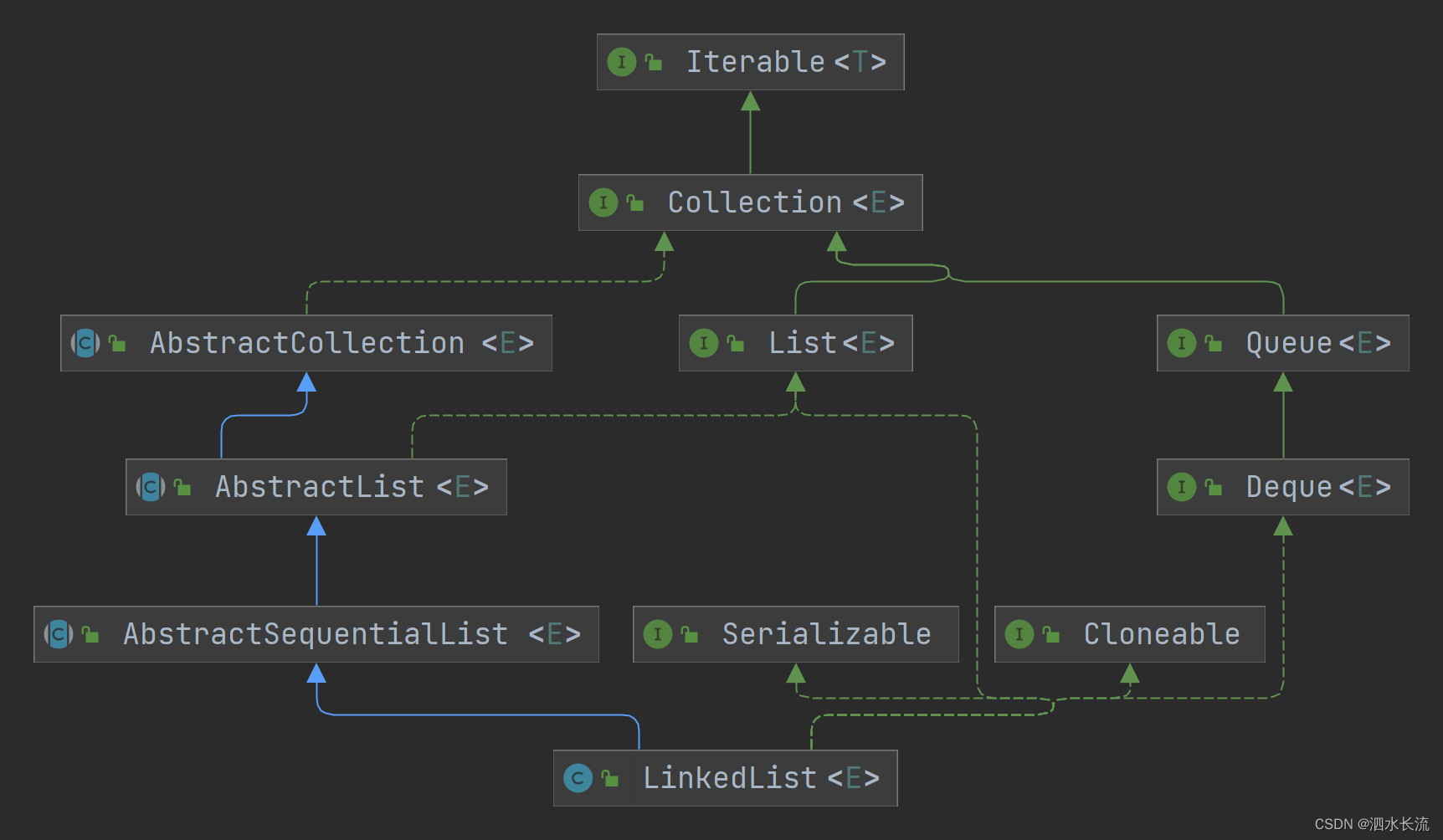
LinkedList实现了List接口、Deque接口、Cloneable接口、Serializable接口,同时继承了AbstractSequentialList抽象类。通过实现Deque接口,使其具有了Queue队列类型的特点,通过实现Cloneable、Serializable接口,可以实现克隆和序列化。
通过它的继承与实现类我们看到,与ArrayList相比,它并没有实现RandomAccess随机访问接口,在一定程度上说明了它不具备随机访问的特性。
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
2.2 LinkedList类的属性及底层实现
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
//集合的元素个数
transient int size = 0;
//链表头,即链表首个元素
transient Node<E> first;
//链表尾,即链表最后一个元素
transient Node<E> last;
}
LinkedList主要有size(节点个数)、first(链表头节点)、last(链表尾节点)。我们仔细看它的源码 ,会发现比较奇怪的地方,就是属性上也加上了transient修饰(禁止序列化),与ArrayList相比, 这里加transient修饰主要是为了避免外部序列化方法仅仅序列化头尾,所以和ArrayList一样,也自行实现了readObject 和 writeObject 进行序列化与反序列化。
我们知道,LinkedList是基于双向链表实现的,通过上面LinkedList的属性源码看到,用到了一个Node类型来表示节点,那我们看下Node这个类型。
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
这个Node中包含三个属性:item(当前节点数据),next(上一个节点)、prev(下一个节点),所以LinkedList就是由Node类型对象连接而成的一个双向链表。
2.3 LinkedList的构造函数
ArrayList一共有三个构造函数:
1.LinkedList list = new LinkedList<>();默认无参构造函数,创建一个空的列表;
2.传入一个集合类型进行初始化:
HashSet<String> set = new HashSet<>();
set.add("a");
set.add("b");
set.add("c");
set.add("a");
LinkedList<String> list = new LinkedList<>(set);
源码如下:
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index);
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
Node<E> pred, succ;
if (index == size) {
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}
2.4 LinkedList的基本方法
2.4.1 LinkedList新增元素
1.list.add(“a”) 在链表尾添加元素
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
2.list.add(4,“b”) 在链表某个下标位置添加元素
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
//如果在上半部分,从头部开始遍历
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
//如果在下半部分,从尾部开始倒序遍历
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
从上面的源码我们看到,如果添加的元素不再头或者尾,那么每添加一个元素,都要对链表进行遍历(最多需要遍历n/2次),性能是比较低下的。
3.list.addFirst(“e”);在链表头添加元素
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
4.list.addLast(“g”);在链表尾添加元素
public void addLast(E e) {
linkLast(e);
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
小结:从上面的源码我们看到,新增元素的时候,尽量不要使用指定下标的方式插入下链表中间,性能会非常差。
2.4.2 LinkedList删除元素
1.list.remove();删除第一个节点,这个和list.removeFirst();
public E remove() {
return removeFirst();
}
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
2.list.remove();list.remove(“d”);根据某个元素值,删除节点
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
从源码上看到,这个删除方法从头遍历链表,最多要遍历n次,性能比较低。
3. list.remove(n);根据下标,删除节点
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
//这里还用到了node这个方法:
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
//如果在上半部分,从头部开始遍历
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
//如果在下半部分,从尾部开始倒序遍历
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
这里还是需要对链表进行遍历,所以这种删除元素的方式,性能也比较低。
4. list.removeLast(); 删除最后一个节点
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
2.4.3 LinkedList获取元素
1.list.get(n);根据下标获取元素
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
这里又遇到了node(index)方法,只要遇到这个方法,我们就知道,又要从头或者尾来逐个遍历元素了,性能比较差。
2.list.getFirst();获取第一个节点元素
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
3.list.getLast();获取最后一节点元素
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
2.4.4 LinkedList遍历元素
2.4.4.1 使用下标索引遍历 for(; ; )
LinkedList<String> list = new LinkedList<>();
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
通过上面的源码分析,这种遍历获取元素的方式性能极差,因为每获取一个元素,都要从头或者为遍历一次,所以相当于外部循环又嵌套了一个内部循环,性能是相当差的。
2.4.4.2 使用迭代器遍历
LinkedList<String> list = new LinkedList<>();
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
2.4.4.3 使用foreach遍历
LinkedList<String> list = new LinkedList<>();
for (String s:list){
System.out.println(s);
}
但其实使用foreach遍历和使用迭代器遍历是一样的,使用foreach遍历,代码编译的时候也会转变成迭代器遍历:
LinkedList<String> list = new LinkedList();
Iterator var3 = list.iterator();
while(var3.hasNext()) {
String s = (String)var3.next();
System.out.println(s);
}








![python 绘图 —— 绘制从顶部向底部显示的柱形图[ax.bar()]](https://img-blog.csdnimg.cn/3d3c6907642c4d3d9267b9b4987d8aff.png)