硬件结构
CPU是如何执行程序的?
图灵机的工作方式
图灵机的基本思想:用机器来模拟人们用纸笔进行数学运算的过程,还定义了由计算机的那些部分组成,程序又是如何执行的。
图灵机的基本组成如下:
- 有一条「纸带」,纸带由一个个连续的格子组成,每个格子可以写入字符,纸带就好比内存,,而纸带上的格子的字符就好比内存中的数据或程序;
- 有一个「读写头」,读写头可以读取纸带上任意格子的字符,也可以把字符写入到纸带的格子;
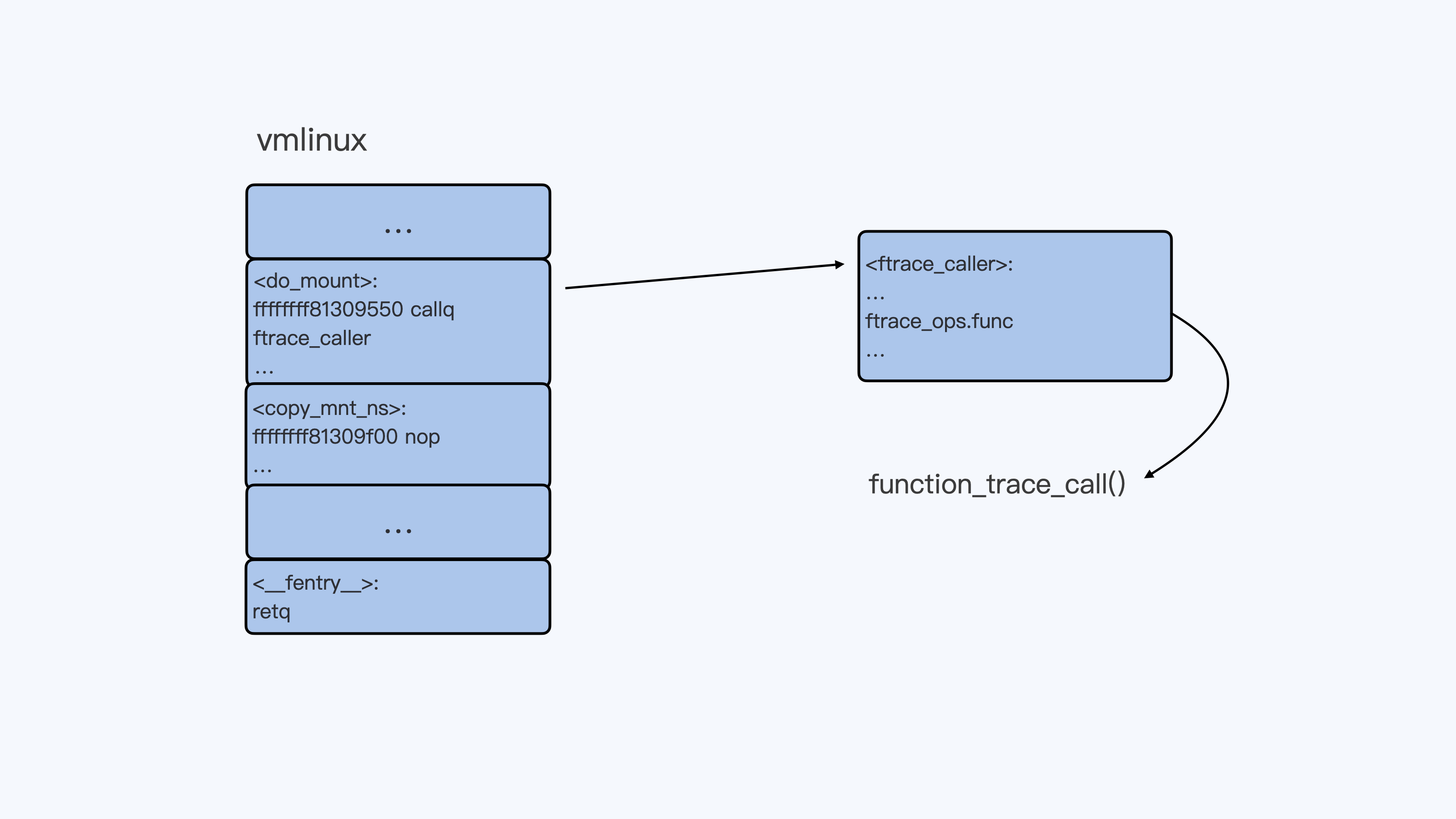
- 读写头上有一些部件,比如存储单元、控制单元以及运算单元:1、存储单元用于存放数据;2、控制单元用于识别字符是数据还是指令,以及控制程序的流程等;3、运算单元用于执行运算指令;
以1+2为例:
- 首先,用读写头把「1、2、+」这3个字符分别写入到纸带上的3个格子,然后读写头先停在1字符对应的格子上;
- 接着,读写头读入1到存储设备中,这个存储设备成为图灵机的状态;
- 然后读写头向右移动一个一个格,用同样的方式把2度如刀图灵机的状态,于是现在图灵机的状态存储着两个连续的数字,1和2;
- 读写头在往右移动一个格,就会碰到+号,读写头读到+号后,将+号传输给控制单元,控制单元发现是一个+号而不是数字,所以没有存入到状态中,因为+号是运算符指令,作用时加和目前的状态,于是通知运算淡云工作。运算单元收到要加和状态中的值的通知后,就会吧状态中的1和2读入并计算,再将计算的结果3存放到状态中;
- 最后,运算单元将结果返回给控制单元,控制单元将结果输给读写头,读写头向右移动,把结果3写入到纸带的格子中;
- 通过上面的图灵机计算1+2的过程,可以发现图灵机主要功能就是读取纸带格子中的内容,然后交给控制单元识别字符是数字还是运算指令,如果是数字则存入到图灵机状态中,如果是运算符,则通知运算符单元读取状态中的数值进行计算,计算结果最终返回给读写头,读写头把结果写入到纸带的格子中。
事实上,图灵机这个看起来很简单的工作方式,和我们今天的计算机是基本一样的。接下来,我们一同再看看当今计算机的组成以及工作方式。
冯诺依曼模型
在1945年冯诺依曼和其他计算机科学家们提出了计算机具体实现的报告,其遵循了图灵机的设计,而且还提出用电子元件构造计算机,并约定了用二进制进行计算和存储。
最重要的定义是计算机基本结构分为5个部分,分别是运算器、控制器、存储器、输入设备、输出设备,这5个部分也被称为冯诺依曼模型。
存储器
控制单元 算术逻辑单元
输入 输出
运算器、控制器是在中央处理器里的,存储器就是我们常见的内存,输入设备则是计算机外界的设备,比如键盘就是输入设备,显示器就是输出设备。
存储单元和输入输出设备要与中央处理器打交道的话,离不开总线。所以,它们之间关系如图:
寄存器 存储单元 输入/输出设备
控制单元 控制总线
数据总线
逻辑运算单元 地址总线
CPU
接下来,分别介绍内存、中央处理器、总线、输入输出设备。
内存
我们的程序和数据都是存储在内存,存储的区域是线性的。
在计算机数据存储中,数据的基本单位视字节BYTE,1字节等于8位/8bit。每一个字节都对应一个内存地址。
内存的地址是从0开始编号的,然后自增排列,最后一个地址为内存粽子结束-1,这种结构好似我们程序里的数组,所以内存的读写任何一个数据的速度都是一样的。
中央处理器
中央处理器也就是我们常见的CPU,32位和64位CPU最主要区别在于一次能计算多少字节数据:
32位CPU一次可以见4字节
64位CPU一次可以计算8字节
这里的32位和64 位,通常称为CPU的位宽。
之所以CPU要这样设计,是为了能计算更大的树枝,如果是8位的CPU,那么一次只能计算1字节0~255范围内的数值,这样就无法一次完成计算10000*500,于是为了能一次计算大数的运算
,CPU需要支持多个BYTE一起计算,所以CPU位宽越大,可以就散的数值就越大,比如说32位CPU能计算的最大整数是4294967295.
CPU 内部还有一些组件,常见的寄存器、控制单元和逻辑运算单元等。其中,控制单元丰泽控制CPU工作,逻辑运算单元负责计算,而寄存器可以分为多个种类,每种寄存器的功能又不尽相同。
CPU的寄存器主要作用是存储计算时的数据,你肯呢好奇为什么有了内存还需要寄存器?原因很简单,因为cpu离内存太远了,而寄存器就在cpu里,还紧挨着控制单元和逻辑运算单元,自然计算时速度会很快。
常见的寄存器分类:
通用寄存器,用来存放需要进行运算的数据,如需要进行加和运算的两个数据。
程序计数器,用来存储cpu要执行下一条指令「所在的内存地址」,注意不是存储了下一条要执行的指令,此时指令还在内存中,程序计数器只是存储了下一条指令的「地址」。
指令寄存器,用来存放当前正在执行的指令,也就是指令本身,指令被执行完成之前,指令都存储在这里。
总线
总线适用于CPU和内存以及其他设备之间的通信,总线可分为三种呢:
地址总线,用于指定cpu将要操作的内存地址;
数据总线,用于读写内存的数据;
控制总线,用于发送和接收信号,比如中断、设备复位等信号,CPU收到信号后自然进行相应,这是也需要控制总线;
当CPU要读写内存数据的时候一般需要通过下面这三个总线:
首先要通过地址总线来制定内存的地址;
然后通过控制总线控制是读或写命令;
最后通过数据总线来传输数据;
输入输出设备
输入设备想计算机输入数据,计算机经过计算后,把数据输出给输出设别。期间,如果输入设备是键盘,按下按键时是需要和CPU进行交互的,这时就需要用到控制总线了。
线路位宽与CPU位宽
数据是如何通过线路传输的呢?其实是通过操作电压,低电压表示0,高电压则表示1.
如果构造了高低高这样的信号,其实就是101二进制数据,十进制则表示5,如果只有一条线路,就意味着每次只能传递1bit的数据,即0或1,那么传输101这个数据就需要3次才能传输完成,这样的效率非常低。
这样一位一位传输的方式,成为串行,下一个bit必须等待上一个bit传输完成才能进行传输。当然,想一次多传输一些数据,增加线路即可,这是数据就可以并行传输。
为了避免低效率的串行传输的方式,线路的尾款最好一次就能访问到所有的内存地址。
CPU想要操作内存地址就需要地址总线:
如果地址总线只有1条,那每次只能表示0或1这两种地址,所以CPU能操作的内存地址最大数量位2个,(注意,不要理解成同时能操作2个内存地址);
如果地址总线右2条,那么能表示00、01、10、11这四种地址,所以cpu能操作的内存地址最大数量为4个。
那么想要CPU操作4G大的内存,那么就需要32条地址总线,因为2^2*2^10*2^10*2^10=2^32=4G。
知道了线路位宽的意义后,我们再来看CPU位宽。
CPU为快最好不要小雨线路位宽,比如32位CPU控制40位宽的地址总线和数据总线的话,工作起来就会非常复杂且麻烦,所以32位CPU最好和32位宽的线路搭配,因为32位CPU一次最多只能操作32位宽的地址总线和数据总线。
如果用32位CPU去加和两个64位大小的数字,就需要把这2个64位的数字分成两个低位32位数字和两位高位32位数字来计算,先加个两个低位的32位数字酸楚仅为,然后加和两位高位的32位数字,然后再加上仅为,就能计算出结果,可以发现32位CPU并不能一次性计算出加和两个64位数字的结果。
对于64位CPU就可以一次性算出加和两个64位数字的结果,因为64位CPU可以一次读如64位的数字,并且64位CPU内部的逻辑运算单元也支持64位数字的计算。但是不代表64位CPU性能比32位CPU高很多,很少应用需要算超过32位的数字,所以如果计算的数额不超过32位数字的情况下,32位和64位CPU之间没什么区别的,只有当计算超过32位数字的情况下,64位的优势才能体现出来。
另外,32位CPU最大只能操作4GB内存,就算你装了8GB内存条,也没用。而64位CPU寻址范围很大,理论最大的寻址空间位2^64即8GB。
程序执行的基本过程
冯诺依曼模型:程序实际上是一条一条指令,所以程序的运行过程就是把每一条指令一步一步的执行起来,负责执行指令的就是CPU了。
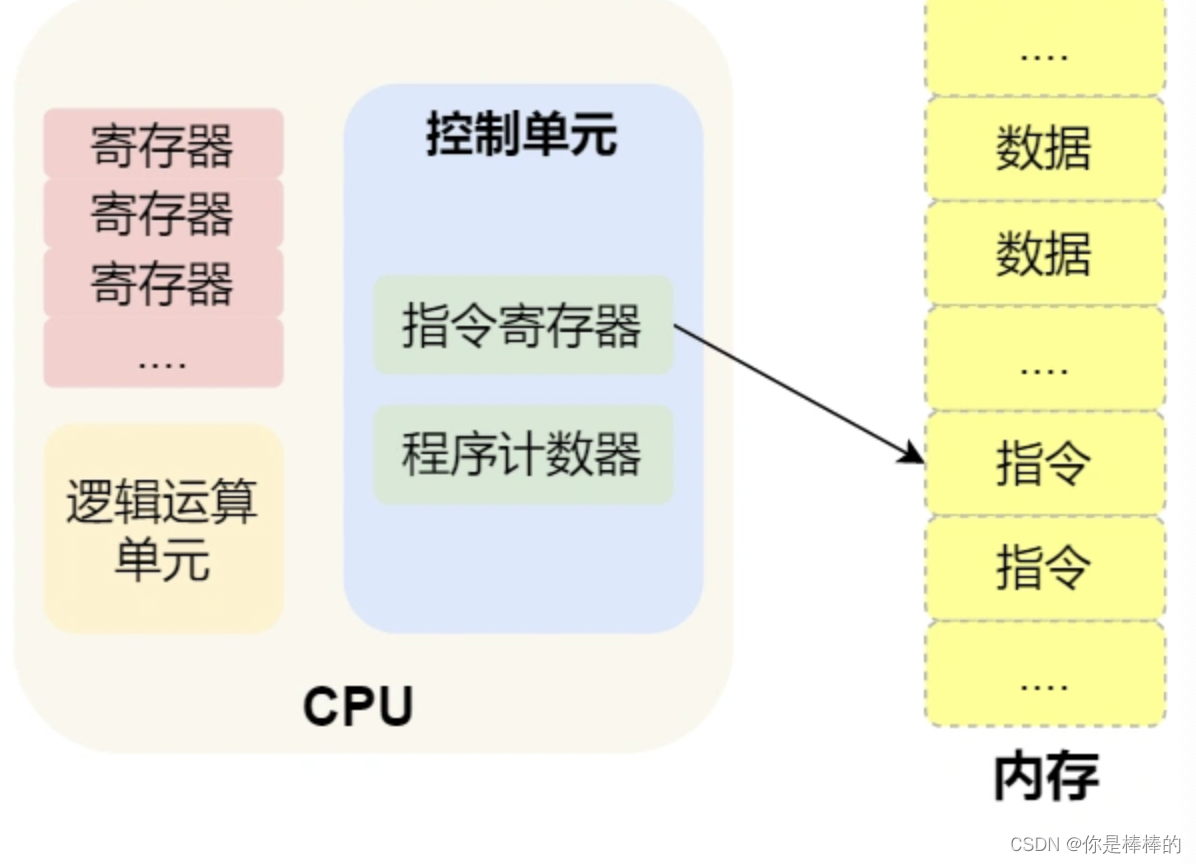
那CPU执行程序的过程如下:
第一步:CPU读取程序计数器的值,这个值是指令的内存地址,然后CPU的控制单元操作地址总线指定需要访问的内存地址,接着通知内存设备准备数据,数据准备好后通过数据总线将指令数据传给CPU,CPU收到内存传来的数据后,将这个指令数据存入指令寄存器。
第二步,程序计数器的值自增, 表示只想下一条指令。这个自增的大小,由CPU的位宽决定,比如32位的额CPU,指令时4字节,需要4个内存地址存放(一个内存地址能存一个字节的数据)因此程序计数器的值会自增4;
第三步,CPU分析指令寄存器中的指令,确定指令的类型和参数,如果是计算类型的指令,就把指令交给运算逻辑单元运算;如果是存储类型的指令,则交由控制单元执行;
简单总结一下就是,一个程序执行的时候,CPU会根据程序计数器里面的内存地址,从内存里面吧需要执行的指令读取到指令寄存器里面执行,然后根据指令长度自增,开始顺序读取下一条指令。
CPU从程序计数器去读取指令、到执行、再到下一条指令,这个过程会不断循环,直到程序执行结束,这个不断循环的过程称为cpu的指令周期。
a=1+2执行具体过程
CPU不认识a=1+2这个字符串,要把整个程序翻译成汇编语言的程序,这个过程称为编译成汇编代码。
针对汇编代码,我们还需要用汇编器翻译成机器码,这些机器码由0和1组成的机器语言,这一条条机器码就是一条条的计算机指令,这个才是CPU能够真正认识的东西。
下面来看看 a = 1 + 2 在 32 位 CPU 的执行过程:
程序编译过程中,编器器通过分析代码,发现1和2都是数据,于是程序运行时,内存会又个专门的区域来存放这些数据,这个区域就是数据段。如下图,数据1和2的区域位置:
数据1被放到0x200位置;
- 数据 2 被存放到 0x204 位置;
注意,数据和指令是分开区域存放的,存放指令区域的地方称为正文段。
0x100:load指令:将0x200地址中的数据1装入到寄存器R0;
0x104:load指令:将0x204地址中的数据2装入到寄存器R1;
0x108:add指令:将寄存器R0和R1的数据想家,并把结果存放到寄存器R2;
0x10c:set指令/store指令:将寄存器R2中的数据存回数据段中的0x208地址中,这个地址也就是变量a内存中的地址。
编一碗好吃呢过后,具体执行程序的时候,程序计数器会被设置为0x100地址,然后依次执行这4条指令。
上面的例子中,由于是在32位CPU执行的,因此一条指令是占32位大小,所以你会发现每条指令间隔4个字节(因为内存的存储单元是1字节)。
而数据的大小是根据你在程序中指定的变量类型,比如int类型的数据则占4字节,char/byte占1字节。
指令
上面的例子中,图中指令的内容我写的是建议的汇编代码,目的是为了方便理解指令的具体内容,事实上指令的内容是遗传二进制数字的机器码,每条指令都有对应的机器码,CPU通过解析机器码老知道指令的内容。
不同的CPU有不同的指令集,也就是对应着不同的汇编语言和不同的机器码,接下来最简单的mips指集,来看看机器码是如何生成的,这样也能明白二进制的机器码的具体含义。
mips的指令是一位32位的整数,高6位代表着操作吗,表示这条指令是一条什么样的指令,剩下的26位不同指令类型锁表示的内容也就不相同,主要有三种类型R和J。
R指令:用在算数和逻辑操作,里面有读取和写入数据的寄存器地址。如果是逻辑位操作,后面还有唯一操作的位移量,而最后的功能码则是再前面的操作吗不够的时候,扩展操作吗来表示对应的具体指令的;
I指令,用在数据传输、条件分支等。这个类型的指令,就没有了唯一令的功能码,也没有了第三寄存器,而是把这三部分直接合并了一个地址值或一个常数;
J指令,用在跳转,高6位之外的26位都是一个跳转之后的地址;
接下来,我们把前面例子的这条指令:add指令将寄存器R0和R 的数据相加,并把结果放入到R2,翻译成机器码。
加和运算是、add对应的mips指令里操作码是00000,以及最末尾的功能码是10000,这些数值都是固定的,查一下mips指令集的手册就能知道的;
rs代表第一个寄存器R0的编号,即00000;
rt代表第二个寄存器R 1 的编号即00001;
rd代表目标的临时寄存器R2的编号,即00010;
因为不是唯一操作,所以位移量是00000
把上面这些数字拼在一起就是一条32位的mips'假发指令了,那么用16禁止表示的机器码则是0x00011020.编译器在编译程序的时候,会构造指令,这个过程叫做指令的编码。CPU执行程序的时候,就会解析指令,这个过程叫做指令的解码。现代大所属CPU都适用流水线的方式来执行指令,所谓的流水线就是把一个任务拆分成多个小任务,于是一条指令通常分为4个阶段,称为4级流水线,如下图:
2.2磁盘比内存慢几万倍?
2.3 如何写出让 CPU 跑得更快的代码?
2.4 CPU 缓存一致性
#2.5 CPU 是如何执行任务的?
2.6 什么是软中断?
中断是什么?
中断是一种异步的时间处理机制,可以提高系统的并发处理能力。
操作系统收到了中断请求,会打断其他进程的运行,所以中断请求的相应程序,也就是中断处理程序,要尽可能快的执行完,这样可以减少对正常进程运行调度的影响。
而且,中断处理程序在响应中断时,可能还会临时关闭中断,这意味着,如果当前中断处理程序没有执行完之前,系统中其他的中断请求都无法被响应,也就是说中断有可能丢失,所以中断处理程序要短且快。
什么是软中断?
Linux系统为了解决中断处理程序执行过长和中断丢失问题,将中断过程分成了两个阶段,分别是上半部分和下半部分。
上半部分:
用来快速处理终端,一般会暂时关闭中断请求,主要负责处理跟硬件紧密相关或时间敏感的事情。
下半部分:
用来延迟处理上半部分未完成的工作,一般以内核线程的方式运行。