文章目录
- 一、项目分析
- 1、项目调研
- 2、项目需求
- 3、开发环境
- 4、项目知识框架
- 5、项目实现基本理论
- 二、项目设计
- 整体框架设计
- 代码框架设计
- 三、项目实现
- 1、系统工具模块
- 目录遍历
- 2、数据库管理模块
- 2.1、封装数据库管理类(SqliteManager)
- 2.2、封装数据管理类(DataManager)
- 3、扫描模块
- 4、监控模块
- 5、中间逻辑层模块
- 5.1、汉字转拼音函数实现
- 5.2、汉字转拼音首字母函数实现
- 5.3、高亮显示搜索关键字
- 6、系统/代码重构
- 6.1、系统重构
- 6.1.1、扫描模块的单例化及线程化
- 6.1.2、数据管理模块的单例化
- 6.2、代码重构
- 6.2.1、日志模块
- 6.2.2、RAII机制解决表结果的自动释放
- 7、搜索模块
- 8、界面模块
- 9、主函数模块
- 10、码云地址
一、项目分析
1、项目调研
当电脑上面文件繁多庞杂时,一款文档搜索工具是必备的,Linux下的find命令十分方便,查找文档非常的便捷高效,window下有系统自带的搜索功能,但是使用过此功能的用户都清楚,这个功能很鸡肋,主要原因是非常的慢,这就和我们快速查找定位某个文件的初衷相违背了,不能很好的满足用户需求。
1、Windows自带搜索工具搜索举例:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-A1uw5400-1676114096934)(C:\Users\姬新羽\AppData\Roaming\Typora\typora-user-images\image-20230211143857682.png)]](https://img-blog.csdnimg.cn/6a6ce1c5cd1e470a9a4fa68d21ae254e.png)
在Windows下有一个软件解决了这个问题,叫Everything,这个文件搜索软件十分高效,为什么如此高效呢?这款软件并不像Windows下默认搜索功能那样使用暴力遍历搜索,而是提前将文件信息存储在数据库中,当用户在查找时,直接在数据库中进行搜索,大大的提高了搜索速度。
2、Everything工具搜索举例:
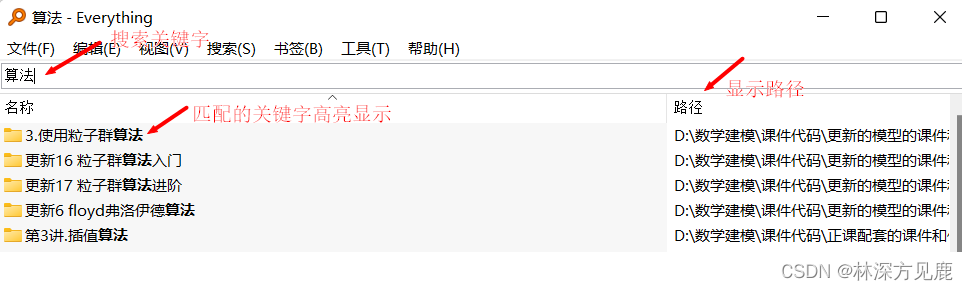
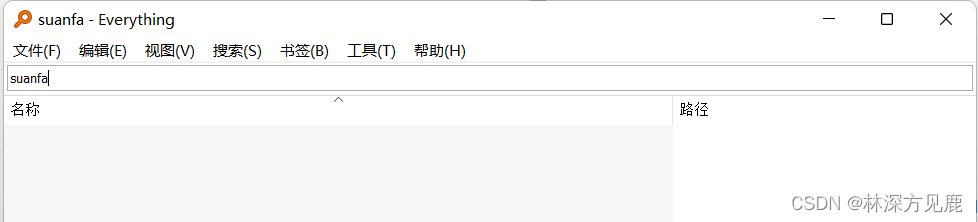
Everything目前不支持拼音搜索和首字母搜索,且适用于NTFS格式,在此项目中,将完善一下Everything上述缺陷。
2、项目需求
1、支持文档常规关键字搜索
2、支持关键字拼音全拼搜索
3、支持关键字拼音首字母搜索
4、支持搜索关键字高亮显示
5、扫描和监控
3、开发环境
1、编译器:VS2017
2、编程语言:C++ / C++11
3、数据库:sqlite3
4、项目知识框架
1、数据库操作:sqlite安装、创建表、插入数据、删除数据、创建索引、查询数据(条件查询、模糊查询)
2、静态库和动态库
3、设计模式:单例模式
4、多线程
5、同步机制(互斥量、条件变量)
6、日志
7、汉字和拼音的转换
5、项目实现基本理论
这款文档搜索工具的核心是“搜索”和“快速”,我们借助数据库可以快速返回数据的特性,将本地文件系统同步到数据库文件系统,也就是说我们搜索数据不是直接在本地文件系统中进行搜索的,是借助数据库文件系统进行搜索的,这就需要做好两个系统的数据同步问题,本地文件系统的数据变化要及时反应到数据库文件系统中去,包括文件的新增,删除、重命名等。
二、项目设计
整体框架设计
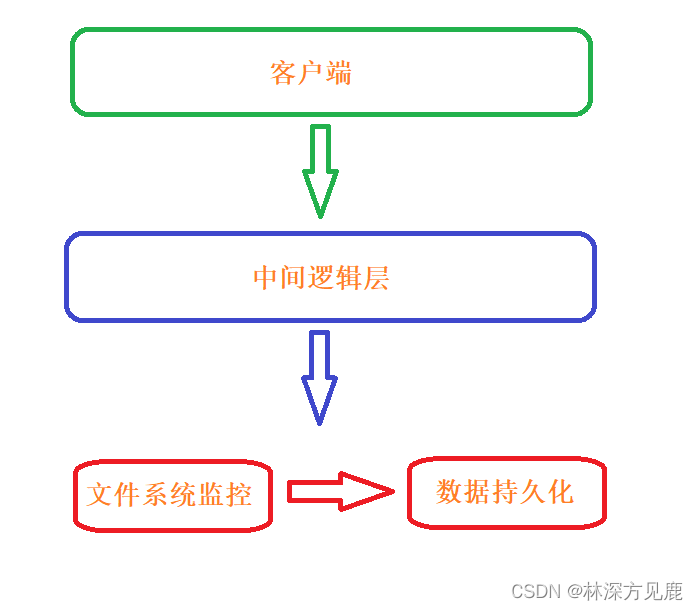
1、客户端:用户输入搜索的关键字、显示搜索结果
2、中间逻辑层:包括了对关键字的模糊匹配、输入关键字的拼音首字母及全拼搜索、高亮处理。其中模糊匹配使用数据库的like进行实现;拼音首字母搜索:存储时将文件名转换成其对应的拼音首字母存储在数据库的doc_name_initials字段,然后再利用模糊匹配;全拼搜索:和首字母搜索同理;高亮处理:对搜索出的关键字进行高亮标记处理,核心在于子串匹配。
3、文件系统监控实现对本地文件系统的实时扫描和监控,一旦发生变动,则数据库更新数据。
4、数据持久化实现数据的存储,此项目中使用sqlite3进行存储。
代码框架设计
公共模块:common.h
系统工具模块:sysutil.h sysutil.cpp
数据管理模块:DataManager.h DataManager.cpp
扫描工具模块:ScanManager.h ScanManager.cpp
系统驱动模块:Easy_Fast_DocSearchTool.cpp
三、项目实现
1、系统工具模块
目录遍历
我们需要将本地文件系统和数据库文件系统进行同步,所以进行本地文件系统的目录遍历是不可避免的,通过目录遍历获取每个路径下的本地文件系统,这是实现同步的基础,在后面的扫描模块中被调用。
在了解函数之前,需要先了解一下一个文件结构体:
struct _finddata_t {
unsigned attrib;//属性
time_t time_create;//文件创建时间
time_t time_access;//最后一次访问文件的时间
time_t time_write;//最后一次修改文件的时间
_fsize_t size;//文件大小
char name[_MAX_FNAME];//文件名
//time_t,其实就是long;_fsize_t,就是unsigned long.
//attrib,就是所查找文件的属性:_A_ARCH(存档)、
//_A_HIDDEN(隐藏)、_A_NORMAL(正常)、_A_RDONLY(只读)、
//_A_SUBDIR(文件夹)、_A_SYSTEM(系统)
};
函数如下:
//搜索与指定的文件名匹配的第一个实例,若成功则返回第一个实例的句柄,否则返回-1
//第一个参数是文件名,第二个参数是_finddata_t结构体指针
long _findfirst(char *filespec, struct _finddata_t *fileinfo);
//搜索文件名匹配的下一个实例,若成功返回0,否则返回-1
//第一个参数为文件句柄,第二个参数是_finddata_t指针
int _findnext(long handle, struct _finddata_t *fileinfo);
//关闭文件句柄,即释放_findfirst中分配的fileinfo的内存,可以停止一个_findfirst/_findnext序列
int _findclose(long handle);
我们在函数中借助两个出参,一个用来保存文件夹名,另一个用来保存文件名。
目录扫描并保存扫描数据的实现代码如下:
void DirectionList(const string &path, vector<string> &sub_dir,
vector<string> &sub_file)
{
struct _finddata_t file;
string _path = path;
_path += "\\*.*";
long handle = _findfirst(_path.c_str(), &file);
if (handle == -1)
{
printf("查找错误");
return;
}
do
{
if (file.name[0] == '.')//不显示"."和".."文件夹
continue;
if (file.attrib & _A_SUBDIR)
sub_dir.push_back(file.name);//保存文件夹名称
else
sub_file.push_back(file.name);//保存文件名称
if (file.attrib & _A_SUBDIR)//是文件夹,则递归查找
{
string temp_path = path;
temp_path += "//";
temp_path += file.name;
DirectionList(temp_path, sub_dir, sub_file);
}
} while (_findnext(handle,&file)==0);//判断下一个文件是否存在
_findclose(handle);
}
2、数据库管理模块
在这个项目中,我们使用sqlite数据库,为什么要选这个数据库呢?sqlite是一个进程内的库,实现了自给自足、无服务器的、零配置的、事务性的SQL数据库引擎,不需要在系统中配置就能进行使用,它非常小,是轻量级的;它完全兼容ACID,允许从多个进程或线程安全访问。
关于sqlite3入门基础,可以参考:https://www.runoob.com/sqlite/sqlite-tutorial.html
在使用sqlite3之前,我们要确保机器上面有sqlite库,将源码下的sqlite3.h、sqlite3.c复制到工程目录下即可。当然我们也可以生成静态库,链接静态库即可。
2.1、封装数据库管理类(SqliteManager)
sqlite3提供了简单和易于使用的API,我们用一个SqliteManager类对sqlite的接口进行一层简单的封装。
class SqliteManager
{
public:
SqliteManager();
~SqliteManager();
void Open(const string &database);//打开或创建数据库
void Close();//关闭数据库
void ExecuteSql(const string &sql);//执行SQL语句
void GetTableResult(const string &sql, char **&ppRet, int &row, int &col);//获取表结果
private:
sqlite3* _db;//指向数据库的指针
};
构造函数和析构函数:
SqliteManager::SqliteManager():m_db(nullptr)
{}
SqliteManager::~SqliteManager()
{
Close();
}
打开/创建数据库函数,如果数据库存在,则直接打开,不存在则创建数据库,代码如下:
void SqliteManager::Open(const string &database)
{
int result = sqlite3_open(database.c_str(), &m_db);
if (result != SQLITE_OK)
{
fprintf(stderr, "Can't open database : %s\n", sqlite3_errmsg(m_db));
exit(1);//异常退出
}
else
{
fprintf(stdout, "open database successfully\n");
}
}
在函数中用到了exit,就简单说一下它,exit的功能是退出当前运行的程序,并将参数value返回给主调进程。exit(0)表示程序正常退出,除了0之外,其他参数都表示程序异常退出,如exit(1)和exit(-1),exit(1)和exit(-1)是分别返回1和-1到主调程序。
关闭数据库:
void SqliteManager::Close()
{
int result = sqlite3_close(m_db);//调用接口API,关闭之前打开的数据库连接
if (result != SQLITE_OK)
{
fprintf(stderr, "Can't close database: %s\n", sqlite3_errmsg(m_db));
exit(1);//异常退出
}
else
{
fprintf(stdout,"Close database successfully\n");
}
}
执行SQL语句是借助sqlite提供的C++接口API:
sqlite3_exec(sqlite3*,const char *sql,sqlite_callback,void *data,char **errmsg)
//第一个参数是打开的数据库对象
//第二个参数是要执行的SQl语句
//第三个参数是一个回调函数,第四个参数作为该回调函数的第一个参数
//第五个参数将被返回用来获取程序生成的任何错误,在语句执行错误的时候,可以查阅该指针,这是一个出参(即主调函数将类型变量的地址传入,函数分配内存赋值给该变量),同时在执行完该函数或不需要该错误信息时,调用sqlite3_free()来释放这块内存以避免内存泄漏。
执行SQL语句函数的实现代码:
void SqliteManager::ExecuteSql(const string &sql)
{
char *zErrMsg = 0;
int result = sqlite3_exec(m_db, sql.c_str(), 0, 0, &zErrMsg);//不使用回调函数,第三、四个参数设为0
if (result != SQLITE_OK)
{
fprintf(stderr, "Execute SQL Error: %s\n", zErrMsg);
sqlite3_free(zErrMsg);
}
else
{
fprintf(stdout, "Execute SQL Successfully\n");
}
}
在sqlite3中查询数据有两种方式:第一种是借助sqlite3_exec函数,再利用函数中第三个参数是回调函数,借助回调函数实现数据的查询;第二种方法是通过获取表的形式得到结果,利用的是sqlite_get_table函数。
第一种方法的代码演示:
int callback(void *data, int argc, char **argv, char **azColName)
{
for (int i = 0; i < argc; ++i)
{
//printf("%s = %s\n", azColName[i], argv[i] ? argv[i] : "NULL");
printf("%s ", argv[i]);
}
cout << endl;
return 0;
}
int main()
{
sqlite3 *p_db;
int rc = sqlite3_open("testdoc.db", &p_db);
if (rc != SQLITE_OK)
{
fprintf(stderr, "Can't open database: %s\n", sqlite3_errmsg(p_db));
exit(1);
}
else
{
fprintf(stderr, "Opened database successfully\n");
}
const char *sql = "SELECT * from testdoc_info";
const char* data = "Callback function called";
char *zErrMsg = 0;
rc = sqlite3_exec(p_db, sql, callback, (void*)data, &zErrMsg);
if(rc != SQLITE_OK)
{
fprintf(stderr, "SQL error: %s\n", zErrMsg);
sqlite3_free(zErrMsg);
}
else
{
fprintf(stdout, "Select Data successfully\n");
}
sqlite3_close(p_db);
return 0;
}
测试代码执行结果:
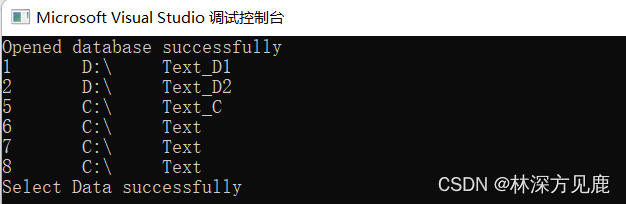
第二种方法代码演示:
int main()
{
sqlite3 *p_db;
int rc = sqlite3_open("testdoc.db", &p_db);
if (rc != SQLITE_OK)
{
fprintf(stderr, "Can't open database: %s\n", sqlite3_errmsg(p_db));
exit(1);
}
else
{
fprintf(stderr, "Opened database successfully\n");
}
const char *sql = "SELECT * from testdoc_info";//SQL语句
char* *ppResult = 0;//指向数据库表,出参
int row, col;//结果的行和列
char *zErrMsg = 0;//指向错误信息
rc = sqlite3_get_table(p_db, sql, &ppResult, &row, &col, &zErrMsg);
if (rc != SQLITE_OK)
{
fprintf(stderr, "SQL Error: %s\n", zErrMsg);
sqlite3_free(zErrMsg);
}
else
{
printf("row = %d, col = %d\n", row, col);
for (int i = 1; i <= row; ++i)
{
for (int j = 0; j < col; ++j)
cout<< *(ppResult + (i*col) + j) <<"\t";
printf("\n");
}
}
sqlite3_free_table(ppResult);//释放表结果
sqlite3_close(p_db);//关闭数据库连接
return 0;
}
得到的表结果可以理解为一个二维表,出参row表示数据的行数(不包括首行),col表示数据的列数。

测试代码执行结果:
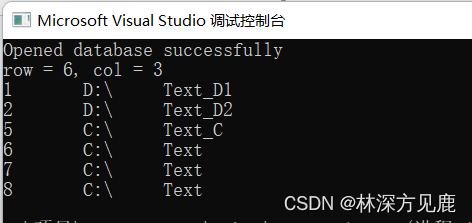
在此我选择直接通过sqlite3_get_table函数的方式,封装得到的获取数据库表的函数如下:
void SqliteManager::GetTableResult(const string &sql, char **&ppRet, int &row, int &col)
{
char *zErrMsg = 0;
int result = sqlite3_get_table(m_db, sql.c_str(), &ppRet, &row, &col, &zErrMsg);
if (result != SQLITE_OK)
{
fprintf(stderr, "SQL Error: %s\n", zErrMsg);
sqlite3_free(zErrMsg);
}
else
{
fprintf(stdout, "Get Result Table Successfully\n");
}
}
2.2、封装数据管理类(DataManager)
上面我将sqlite提供的C++接口API进行了简单的封装,主要是为了方面后面我们的使用,因为大大减小了我们调用时函数参数的复杂程度。再接着,我们将封装数据管理类(DataManager),这个类将提供数据库管理的接口,代码如下:
class DataManager
{
public:
DataManager();
~DataManager();
public:
void InitSqlite();//初始化数据库
void InsertDoc(const string &path, const string &doc);//插入数据
void DeleteDoc(const string &path, const string &doc);//删除数据
void GetDoc(const string &path, multiset<string> &doc);//获取path路径数据
private:
SqliteManager m_dbmgr;
};
封装的数据库管理类的私有成员是我们在上面封装的数据库对象,数据管理类是用来管理数据库的数据的。
类的构造函数和析构函数:
DataManager::DataManager()
{
m_dbmgr.Open(DOC_DB);//打开数据库
InitSqlite();//创建表
}
DataManager::~DataManager()
{}
在数据库管理类中我们需要有明确的被操作的数据库的名字(在函数调用中需要被用作参数),且不同用户定义的数据库名不一样,为了方便使用,所以我们对数据库名进行了宏定义,并新添加一个头文件,用来放入这些配置信息。对数据库中的表也同理,我们对数据库表也进行了宏定义,用户在使用的时候可以自行修改这些配置。
我在测试的时候用的宏定义如下:
#define DOC_DB "testdoc.db"
#define DOC_TB "testdoc_info"
在初始化数据库函数中我们创建了数据库表:
void DataManager::InitSqlite()
{
char sql[SQL_BUFFER_SIZE] = { 0 };
sprintf(sql, "CREATE TABLE if not exists %s(\
id integer primary key autoincrement,\
doc_path text,\
doc_name text)", DOC_TB);
m_dbmgr.ExecuteSql(sql);
}
向表中插入数据的参数设定是根据我们要在数据库中保存数据的表来决定的,我们直接在数据库表中保存的是文档的路径和名称,后续的拼音全拼和首字母是通过其他函数来实现的,不用我们设定拼音及首字母的参数。
我们用一个字符数组来保存SQL语句,为该SQL语句设定的字符数组的初始大小是256,该数组可以保存255个字符以及一个"\0".
void DataManager::InsertDoc(const string &path, const string &doc)
{
char sql[SQL_BUFFER_SIZE] = { 0 };//定义字符数组存放SQL语句
sprintf(sql, "INSERT INTO %s values(null,'%s','%s')",
DOC_TB, path.c_str(), doc.c_str());
m_dbmgr.ExecuteSql(sql);
}
删除表中数据:
void DataManager::DeleteDoc(const string &path, const string &doc)
{
char sql[SQL_BUFFER_SIZE] = { 0 };
sprintf(sql, "DELETE FROM %s where doc_path='%s' and doc_name='%s'",
DOC_TB, path.c_str(), doc.c_str());
m_dbmgr.ExecuteSql(sql);
}
获取表中对应路径的数据:
void DataManager::GetDoc(const string &path, multiset<string> &docs)
{
char sql[SQL_BUFFER_SIZE] = { 0 };
sprintf(sql, "SELECT doc_name from %s where doc_path='%s'",
DOC_TB, path.c_str());
char **ppRet = 0;
int row = 0, col = 0;
m_dbmgr.GetTableResult(sql, ppRet, row, col);
for (int i = 1; i <= row; ++i)
docs.insert(ppRet[i]);
sqlite3_free_table(ppRet);
}
这个函数主要是用于获取某路径的文件的,在后面扫描模块的同步数据函数中有着举足轻重的作用,用于扫描得到数据库文件系统的数据。
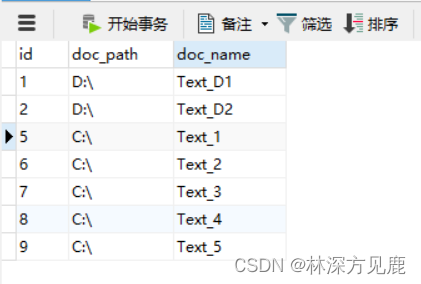
测试:
这是此时的数据库表内容:
测试主函数:
int main()
{
multiset<string> res;
DataManager dm;
dm.GetDoc("C:\\", res);
for (const auto &e : res)
cout << e << endl;
return 0;
}
测试结果如下:
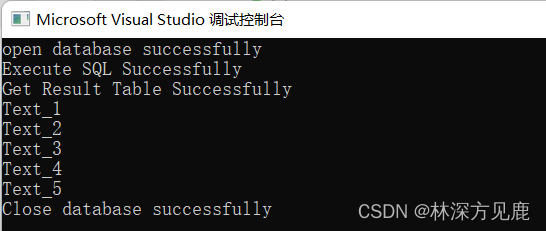
搜索函数:
在这里插入代码片
该函数的主要作用是匹配关键字,在数据库中进行查询结果通过键值对保存下来。
3、扫描模块
我们新增扫描管理类:
class ScanManager
{
public:
void ScanDirectory(const string &path);//同步数据
private:
DataManager m_dbmgr;
};
扫描模块是本地文件系统和数据库文件系统同步的重要一环,首先得知道本地文件系统和数据库文件系统都有哪些文件才能进行同步,需要注意的是,一切都是以本地文件系统为核心,如果本地文件系统有某文件,而数据库没有,那就往数据库文件系统中新增这个文件;如果本地文件系统没有某文件,但是数据库文件系统有,那就删除数据库文件系统中的这条记录。
在函数中,我用multiset来记录文件系统,主要出于以下两点考虑:第一,不同文件夹下的文件名可能会重复,所以在我们的数据库文件系统中是很有可能出现名称相同的文件的,所以得使用multiset而不是set,第二,在对数据进行同步的时候,我们是用迭代器进行比对的,根据迭代器向前迭代的速度来判断某文件是需要在数据库文件系统中进行新增还是进行删除,这个对比很重要的一点就是本地文件系统和数据库文件系统中的数据都是按照相同的规则进行排序的,我们知道multiset是有序的,用这个数据结构进行存储,我们就不用再额外对数据进行排序,可以直接根据集合中的数据进行对比同步两个文件系统中的数据了。
我们通过扫描目录函数(ScanDirectory)来同步本地文件系统和数据库文件系统,具体实现代码如下:
void ScanManager::ScanDirectory(const string &path)
{
//扫描本地文件
vector<string> local_dir;//保存本地文件夹目录
vector<string> local_file;//保存本地文件目录
DirectionList(path, local_dir, local_file);//遍历本地path目录并保存结果
multiset<string> local_set;
local_set.insert(local_file.begin(), local_file.end());
local_set.insert(local_file.begin(), local_file.end());
//扫描数据库文件
multiset<string> db_set;
m_dbmgr.GetDoc(path, db_set);//获取数据库path路径下的文件
//同步数据
auto local_it = local_set.begin();//本地文件系统的迭代器
auto db_it = db_set.begin();//数据库文件系统的迭代器
while (local_it != local_set.end() && db_it != db_set.end())
{
if (*local_it < *db_it)
{
//本地有某文件,数据库中没有此文件,数据库插入文件
m_dbmgr.InsertDoc(path, *local_it);
++local_it;
}
else if (*local_it > *db_it)
{
//本地没有某文件,数据库中有此文件,数据库删除文件
m_dbmgr.DeleteDoc(path, *db_it);
++db_it;
}
else
{
//某文件同时存在于文地和数据库文件系统中
++local_it;
++db_it;
}
}
while (local_it != local_set.end())
{
//数据库迭代完了,本地没有结束,则数据库需要插入文件
m_dbmgr.InsertDoc(path, *local_it);
++local_it;
}
while (db_it != db_set.end())
{
//本地迭代完了,数据库没有结束,则数据库需要删除数据
m_dbmgr.DeleteDoc(path, *db_it);
++db_it;
}
}
4、监控模块
我们需要对文件系统进行监控,如果文件系统有变动,我们将通知扫描模块重新进行扫描,达到本地文件系统和数据库文件系统的同步,在这个模块中,我们主要借助一些windows系统提供的接口函数。
我们在扫描管理类中添加互斥量和条件变量,当本地文件系统发生变动这个条件成立的时候再通知扫描线程重新扫描。
void ScanManager::ScanThread(const string &path)
{
//初始化扫描
ScanDirectory(path);
while (1)
{
unique_lock<mutex> lock(m_mutex);
m_cond.wait(lock);
ScanDirectory(path);
}
}
void ScanManager::WatchThread(const string &path)
{
HANDLE hd = FindFirstChangeNotification(path.c_str(), true,
FILE_NOTIFY_CHANGE_FILE_NAME | FILE_NOTIFY_CHANGE_DIR_NAME);
if (hd == INVALID_HANDLE_VALUE)
{
ERROR_LOG("监控目录失败");
return;
}
while (1)
{
WaitForSingleObject(hd, INFINITE);//永不超时等待
m_cond.notify_one();
FindNextChangeNotification(hd);
}
}
5、中间逻辑层模块
5.1、汉字转拼音函数实现
GB2312编码包括符号、数字、字母、日文、制表符等等,当然最主要的部分还是中文,它采用16位编码方式,简体中文的编码范文从B0A1一直到F7FE,完整编码表,代码就不放在这里了,如果需要的话,可以从文末的码云链接获取。
5.2、汉字转拼音首字母函数实现
和上述同理,代码可以从文末码云链接获取。
5.3、高亮显示搜索关键字
高亮显示搜索关键字,首先我在系统工具模块中新增颜色打印函数,代码如下:
//颜色高亮显示一段字符串
void ColourPrintf(const char* str)
{
// 0-黑 1-蓝 2-绿 3-浅绿 4-红 5-紫 6-黄 7-白 8-灰 9-淡蓝 10-淡绿
// 11-淡浅绿 12-淡红 13-淡紫 14-淡黄 15-亮白
//颜色:前景色 + 背景色*0x10
//例如:字是红色,背景色是白色,即 红色 + 亮白 = 4 + 15*0x10
WORD color = 9 + 0 * 0x10;
WORD colorOld;
HANDLE handle = GetStdHandle(STD_OUTPUT_HANDLE);
CONSOLE_SCREEN_BUFFER_INFO csbi;//控制台屏幕缓冲信息
GetConsoleScreenBufferInfo(handle, &csbi);
colorOld = csbi.wAttributes;
SetConsoleTextAttribute(handle, color);//设置控制台属性
printf("%s", str);
SetConsoleTextAttribute(handle, colorOld);
}
在我们有能力对一段字符串进行高亮显示时,下一个需要关注的问题就是实现高亮分割函数,将将要展示的搜索结果中搜索关键字那部分独立出来,进行高亮显示。代码如下:
void DataManager::SplitHighLight(const string &str, const string &key,
string &prefix, string &highlight, string &suffix)
{
//忽略大小的匹配
string strlower = str;
string keylower = key;
transform(strlower.begin(), strlower.end(), strlower.begin(), tolower);
transform(keylower.begin(), keylower.end(), keylower.begin(), tolower);
//原始字符串能够匹配
size_t pos = strlower.find(keylower);
if (pos != string::npos)
{
prefix = str.substr(0, pos);
highlight = str.substr(pos, keylower.size());
suffix = str.substr(pos + keylower.size(), str.size());
return;
}
//拼音全拼搜索分割
string str_py = ChineseConvertPinYinAllSpell(strlower);
pos = str_py.find(keylower);
if (pos != string::npos)
{
int str_index = 0; //控制原始字符串的下标
int py_index = 0; //控制拼音字符串的下标
int highlight_index = 0; //控制高亮显示字符串的起始位置
int highlight_len = 0; //控制高亮字符串的长度
while (str_index < str.size())
{
if (py_index == pos)
{
//记录高亮的起始位置
highlight_index = str_index;
}
if (py_index >= pos + keylower.size())
{
//关键字搜索结束
highlight_len = str_index - highlight_index;
break;
}
if (str[str_index] >= 0 && str[str_index] <= 127)
{
//原始字符串是一个字符
str_index++;
py_index++;
}
else
{
//原始字符串是一个汉字
string word(str, str_index, 2); //截取一个汉字 //校
string word_py = ChineseConvertPinYinAllSpell(word);//xiao
str_index += 2;
py_index += word_py.size();
}
}
prefix = str.substr(0, highlight_index);
highlight = str.substr(highlight_index, highlight_len);
suffix = str.substr(highlight_index + highlight_len, str.size());
return;
}
//首字母搜索
string str_initials = ChineseConvertPinYinInitials(strlower);
pos = str_initials.find(keylower);
if (pos != string::npos)
{
int str_index = 0;
int initials_index = 0;
int highlight_index = 0;
int highlight_len = 0;
while (str_index < str.size())
{
if (initials_index == pos)
{
//记录高亮的起始位置
highlight_index = str_index;
}
if (initials_index >= pos + keylower.size())
{
highlight_len = str_index - highlight_index;
break;
}
if (str[str_index] >= 0 && str[str_index] <= 127)
{
//原始字符串是一个字符
str_index++;
initials_index++;
}
else
{
//原始字符串是一个汉字
str_index += 2;
initials_index++;
}
}
prefix = str.substr(0, highlight_index);
highlight = str.substr(highlight_index, highlight_len);
suffix = str.substr(highlight_index + highlight_len, str.size());
return;
}
//没有搜索到关键字
prefix = str;
highlight.clear();
suffix.clear();
}
6、系统/代码重构
6.1、系统重构
6.1.1、扫描模块的单例化及线程化
搜索工具需要进行线程化,原因是在整个搜索过程中,本地文件系统可能会出现变化,包括文件的新增删除或者重命名,如果扫描实例只扫描一次就停止了扫描,那么可能会导致本地文件系统和数据库文件系统不对称,因此我们需要时刻对本地文件系统进行扫描,从而达到对数据库文件的实时更新,线程化之后,我们可以通过子线程来完成扫描工作,而主线程继续完成与用户的交互。
线程化:
ScanManager::ScanManager(const string &path)
{
//扫描对象
thread ScanObj(&ScanManager::ScanThread, this, path);
ScanObj.detach();
//监控对象
thread WatchObj(&ScanManager::WatchThread, this, path);
WatchObj.detach();
}
单例化:
在整个工具的使用过程中,扫描实例只需要一个,这个扫描实例只需要把需要扫描的路径下面的文档及其子目录全部扫进数据库即可,不需要多个扫描对象,如果有多个扫描对象可能会造成数据库数据重复,或者很可能产生脏数据,从而导致搜索结果出现偏差。
单例化将构造函数私有化:
private:
ScanManager(const string &path);
ScanManager(ScanManager &);
ScanManager& operator=(const ScanManager&);
ScanManager& ScanManager::GetInstance(const string &path)
{
static ScanManager _inst(path);
return _inst;
}
6.1.2、数据管理模块的单例化
和扫描实例同理,在整个搜索过程中需要用到的数据库实例一个即可,当本地文件系统出现变动的时候,我们会更新数据库文件系统,不需要多个数据库实例。
private:
DataManager();
DataManager(const DataManager &);
DataManager& operator=(const DataManager &);
public:
static DataManager& GetInstance();
DataManager& DataManager::GetInstance()
{
static DataManager _inst;
return _inst;
}
6.2、代码重构
6.2.1、日志模块
在上面的函数中,为了直白的看出执行成功与否,我直接用了打印,将函数的执行结果都打印到了屏幕上,效果如下:
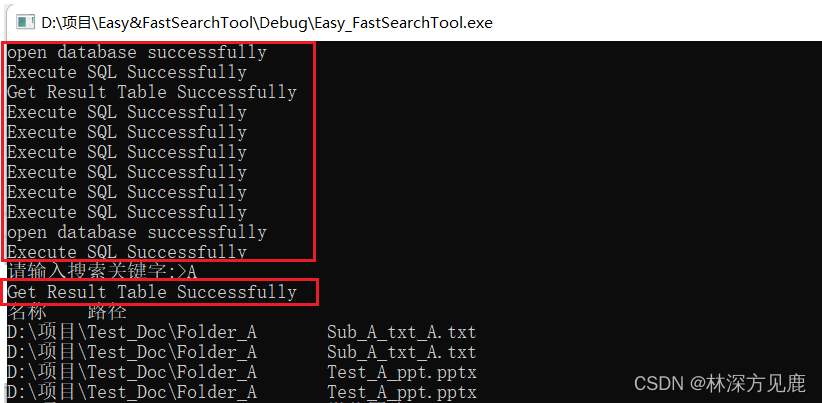
这样虽然可以直白的看到函数执行成功与否,但是这对用户来说,并不是必要的,这些信息对于项目开发者来说又是必要的,所以我们引入日志模块。
日志的作用:每一行日志都记载着日期、时间、使用者及动作等相关操作的描述;记载用户访问系统的全过程,记录哪些用户从哪些渠道进入过系统,都在系统中执行了哪些操作,系统在此过过程中是否产生了错误等等信息。
日志的级别:
日志一共分成5个等级,从低到高分别是:
DEBUG //详细的信息,通常只出现诊断问题上
INFO //确认一切按预期运行
WARNING //一些意想不到的事情发生了或不久的将来可能会出现一些问题
ERROR //更严重的问题,软件没能执行某些功能
CRITICAL //一个严重的错误,表明程序本身可能无法继续运行
//五个等级,对应五种打日志的方法:debug、info、warning、error、critical。
//默认的是WARNING,当在WARNING或之上时才被跟踪
在调试的时候,知道问题是出现在哪个文件中的是非常重要的一件事,于是有一个获取文件名函数是必须的。
获取文件名函数:
string GetFileName(const string &path)
{
char token = '\\';//以'\'为标志找文件名
size_t pos = path.rfind(token);
if (pos == string::npos)//'\'不存在
return path;
return path.substr(pos + 1);//截取从pos+1位置到最后的字符串
}
追踪日志:
void __TraceDebug(const char *filename, int line, const char *function,
const char *data, const char *time,
const char *format, ...)
{
#ifdef __TRACE__
fprintf(stdout, "[TRACE][%s : %d : %s %s %s]:",
GetFileName(filename).c_str(), line, function,
data, time);
//读取可变参数
va_list args;
va_start(args, format);
vfprintf(stdout, format, args);
va_end(args);
fprintf(stdout, "\n");
#endif
}
错误日志:
void __ErrorDebug(const char *filename, int line, const char *function,
const char *data, const char *time,
const char *format, ...)
{
#ifdef __ERROR__
fprintf(stdout, "[ERROR][%s :%d:%s %s %s]:",
GetFileName(filename).c_str(), line, function,
data, time);
//读取可变参数
va_list args;
va_start(args, format);
vfprintf(stdout, format, args);
va_end(args);
fprintf(stdout, "\n");
#endif // __ERROR__
}
由于追踪日志和错误日志在使用时填充参数很麻烦,所以我们有了下面的宏定义,在使用的使用用宏定义就简单很多。
#define TRACE_LOG(...) __TraceDebug(__FILE__,__LINE__,__FUNCTION__,__DATE__,__TIME__,__VA_ARGS__)
#define ERROR_LOG(...) __ErrorDebug(__FILE__,__LINE__,__FUNCTION__,__DATE__,__TIME__,__VA_ARGS__)
6.2.2、RAII机制解决表结果的自动释放
在上面的代码中,在我们利用sqlite3_get_table函数获取表结果时,都需要调用sqlite3_free_table函数来释放空间,这个需要函数需要人为的记住去调用,以防止内存泄漏,但是有可能会忘记调用,也有可能出现异常,在出现异常的时候,就算我们注意释放指针空间了,还是有可能会出现问题,于是我们利用RAII技术来改进我们的代码。
RAII是一种利用对象生命周期来控制程序资源的简单技术,简单的说,就是在对象构造时获取资源,接着控制对资源的访问使之在对象的生命周期内始终保持有效,最后在对象析构的时候释放资源,这样来看,我们实际上就把管理一份资源的责任托管给了一个对象,这样我们就不需要显式的释放资源,同时保证了对象所需的资源在其生命周期内始终保持有效。
我们在数据管理模块新增AutoGetTableResult类。
class AutoGetTableResult
{
public:
AutoGetTableResult(SqliteManager &db, const string &sql, char **&ppRet, int &row, int &col);
//在构造函数获得资源
~AutoGetTableResult();//在析构函数释放资源
private:
SqliteManager &m_db;//通过该对象调用GetTableResult函数
char **m_ppRet;//管理可能获取到的表空间
};
AutoGetTableResult::AutoGetTableResult(SqliteManager &db, const string &sql,
char **&ppRet, int &row, int &col)
:m_db(db), m_ppRet(nullptr)
{
m_db.GetTableResult(sql, ppRet, row, col);
m_ppRet = ppRet;//接收并管理空间
}
AutoGetTableResult::~AutoGetTableResult()
{
if (m_ppRet)//如果获取到表结果了
sqlite3_free_table(m_ppRet);//就调用该函数
}
7、搜索模块
我们借助数据库来提高搜索效率,将文件信息存储在数据库中,在我们搜索时,只需要在数据库中进行查询即可,以下是搜索函数的代码实现:
void DataManager::Search(const string &key, vector<pair<string, string>> &doc)
{
//汉字转拼音全拼
string doc_name_py = ChineseConvertPinYinAllSpell(key);
//汉字转首字母
string doc_name_initials = ChineseConvertPinYinInitials(key);
char sql[SQL_BUFFER_SIZE] = { 0 };
sprintf(sql, "SELECT doc_name,doc_path from %s where doc_name like '%%%s%%' or\
doc_name_py like '%%%s%%' or doc_name_initials like '%%%s%%'",
DOC_TB, key.c_str(), doc_name_py.c_str(), doc_name_initials.c_str());;
char **ppRet;
int row, col;
AutoGetTableResult at(m_dbmgr, sql, ppRet, row, col);
doc.clear();//清除之前搜索的结果
for (int i = 1; i <= row; ++i)
{
doc.push_back(make_pair(ppRet[i*col], ppRet[i*col + 1]));
}
8、界面模块
简单的界面实现,显得不那么简陋,实现代码如下:
#define WIDTH 120
#define HEIGHT 30
#define MAX_TITLE_SIZE 100
void SetCurPos(int col, int row)
{
//获取句柄
HANDLE hd = GetStdHandle(STD_OUTPUT_HANDLE);
//x代表列, y代表行
COORD pos = { col, row };
SetConsoleCursorPosition(hd, pos);
}
void HideCursor()
{
//获取句柄
HANDLE hd = GetStdHandle(STD_OUTPUT_HANDLE);
CONSOLE_CURSOR_INFO cur_info = { 100, false };
SetConsoleCursorInfo(hd, &cur_info);
}
void SystemPause()
{
system("pause");
}
void DrawCol(int x, int y)
{
for (int i = 0; i < HEIGHT; ++i)
{
SetCurPos(x, y + i);
printf("||");
}
}
void DrawRow(int x, int y)
{
for (int i = 0; i < WIDTH - 4; ++i)
{
SetCurPos(x + i, y);
printf("=");
}
}
void DrawFrame(const char *title)
{
char buffer[MAX_TITLE_SIZE + 6 + 1] = "title "; //6:title%20 1:\0
strcat(buffer, title);
system(buffer); //设置系统标题
char mode[128] = { 0 };
sprintf(mode, "mode con cols=%d lines=%d", WIDTH, HEIGHT);
system(mode); //设置控制台的长度和宽度
system("color 0F");//设置颜色
DrawCol(0, 0);
DrawCol(WIDTH - 2, 0);
DrawRow(2, 0);
DrawRow(2, 2);
DrawRow(2, 4);
DrawRow(2, HEIGHT - 4);
DrawRow(2, HEIGHT - 2);
}
extern const char *title;
void DrawMenu()
{
//标题的设置
SetCurPos((WIDTH - 4 - strlen(title)) / 2, 1);
printf("%s", title);
//名称 路径
SetCurPos(2, 3);
printf("%-30s %-85s", "名称", "路径");
//退出设置
SetCurPos((WIDTH - 4 - strlen("exit 退出系统 .")) / 2, HEIGHT - 3);
printf("%s", "exit 退出系统 .");
DrawRow(2, HEIGHT - 6);
//SetCurPos((WIDTH-4-strlen("请输入:>"))/2, 15);
SetCurPos(2, HEIGHT - 5);
printf("%s", "请输入:>");
}
void SystemEnd()
{
SetCurPos((WIDTH - 4 - strlen("请按任意键继续. . . ")) / 2, HEIGHT - 1);
}
9、主函数模块
主函数是我们的入口函数,代码如下:
const char *title = "好用快搜文档搜索工具";
int main(int argc, char *argv[])
{
const string path = "D:\\项目\\Test_Doc";
//扫描目录,通过扫描管理类对象
ScanManager &sm = ScanManager::GetInstance(path);
//搜索
DataManager &dm = DataManager::GetInstance();
vector<pair<string, string>> doc;
string key;
while (1)
{
DrawFrame(title);
DrawMenu();
cin >> key;
if (key == "exit")
break;
dm.Search(key, doc);
int row = 5;//默认五行
int count = 0;//显示的行数
string prefix, highlight, suffix;
for (const auto &e : doc)
{
//高亮分割
string doc_name = e.first;
DataManager::SplitHighLight(doc_name, key, prefix, highlight, suffix);
//设置文档名显示位置
SetCurPos(2, row + count++);
cout << prefix;
ColourPrintf(highlight.c_str());
cout << suffix;
//设置路径名显示位置
SetCurPos(33, row + count - 1);
printf("%--85s\n", e.second.c_str());
}
SystemEnd();
SystemPause();
}
SystemEnd();
return 0;
}
10、码云地址
码云地址:好用快搜文档搜索工具·林深方见鹿/项目 - 码云 - 开源中国(gitee.com)