目录
一、 数据类型详细介绍
1.类型的基本归类
二、 整形在内存中的存储
1.原码、反码、补码
对于整形来说:数据存放内存中其实存放的是补码。
三、大小端字节序介绍及判断
1、大端小端:
2、写出一个判断大小端的程序
四、练习整型存储
8个练习题 - 详解
五、整型计算总结
1、输入时:
1)char类型,则要注意截断和整型提升
2)signed 和 unsigned 则要注意如果有整型提升.
无符号unsigned类型 ,默认补位0
有符号signed类型,需要根据截断后的二进制,补符号位;
(例如:截断后10000000 则补位1;截断后00000001 则补位 0)
3)如果为正数,补码即为二进制原码,不需要额外计算。
4)如果为负数,需要 原码 反码 补码 计算
2、输出时
1)%d 打印有符号十进制数,记得把计算的补码,还原为原码
2)%u 打印无符号十进制数,补码即为结果
一、 数据类型详细介绍

以及他们所占存储空间的大小。
类型的意义:1. 使用这个类型开辟内存空间的大小(大小决定了使用范围)。2. 如何看待内存空间的视角
1.类型的基本归类




二、 整形在内存中的存储
变量的创建是要在内存中开辟空间的。空间的大小是根据不同的类型而决定的。
1.原码、反码、补码




对于整形来说:数据存放内存中其实存放的是补码。
为什么呢?在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统 一处理;同时,加法和减法也可以统一处理( CPU只有加法器 )此外,补码与原码相互转换,其运算过程 是相同的,不需要额外的硬件电路。
int main()
{
//内存里1-1=0
int a = 1;
int b = 1;
int c = a - b;
printf("%d\n", c);
//看似是1减去1得到的0,实际上是1+(-1)得到0
//1
//00000000000000000000000000000001 - 1的补码
//-1
//10000000000000000000000000000001
//11111111111111111111111111111110
//11111111111111111111111111111111 - -1的补码
//1+(-1)
//00000000000000000000000000000001 - 1的补码
//11111111111111111111111111111111 - -1的补码
//100000000000000000000000000000000 - 1+(-1)的补码
//丢掉高位得到 0
//00000000000000000000000000000000
return 0;
}
三、大小端字节序介绍及判断
1、大端小端:
大端(存储)模式 ,是指数据的 低位 保存在内存的 高地址 中,而数据的 高位 ,保存在内存的 低地址 中;小端(存储)模式 ,是指数据的 低位 保存在内存的 低地址 中,而数据的 高位 , ,保存在内存的 高地址 中
int main()
{
int a = 20;
//00000000000000000000000000010100 - 二进制补码
//00 00 00 14 - 16进制 调试监视内存可以看到 14 00 00 00
int b = -10;
//10000000000000000000000000001010 - 二进制原码
//11111111111111111111111111110101 - 反码
//11111111111111111111111111110110 - 补码
//ff ff ff f6 -16进制 调试监视内存可以看到f6 ff ff ff
return 0;
}


右边的地址:&b举例,可以看出地址是由低到高变化的,(f6的地址为E0后面依次为 E1, E2,E3,第二行开始cc的地址为E4。地址依次增大)
我们换算的补码顺序为 ff ff ff f6 (f6为低位)
地址里存储的补码顺序为 f6 ff ff ff (地址低到高变化的)
根据大小端的概念,我们发现低位 f6 存储在低地址处,高位 ff 存储在高地址处,所以推测我们目前使用的机器为小端存储
2、写出一个判断大小端的程序
/*
请简述大端字节序和小端字节序的概念,设计一个小程序来判断当前机器的字节序。(10分)
*/
int main()
{
int a = 1;
//00000000000000000000000000000001 - 1的二进制
//00 00 00 01 - 1的16进制,内存显示的是这样
//如果是小端存储 - 01 00 00 00
//如果是大端存储 - 00 00 00 01
//第一个字节就会不同,比较第一个字节就可以区分了
char* pa = (char*)&a;
int i = 0;
//for (i = 0; i < 4; i++)
//{
// printf("%d ", *pa);
// pa++;
//}
//1 0 0 0 - 小端存储
if (*pa)
{
printf("小端存储\n");
}
else
{
printf("大端存储\n");
}
return 0;
}

跟我们推测一致
四、练习整型存储
int main()
{
char a = -1;
signed char b = -1;
//char等同于siged char
//10000000000000000000000000000001
//11111111111111111111111111111110
//11111111111111111111111111111111 - -1的补码
//11111111 - 截断
//整型提升 - 因为signed 有符号数,补符号位1 (11111111)
//11111111111111111111111111111111
//11111111111111111111111111111110
//10000000000000000000000000000001 - -1 的原码
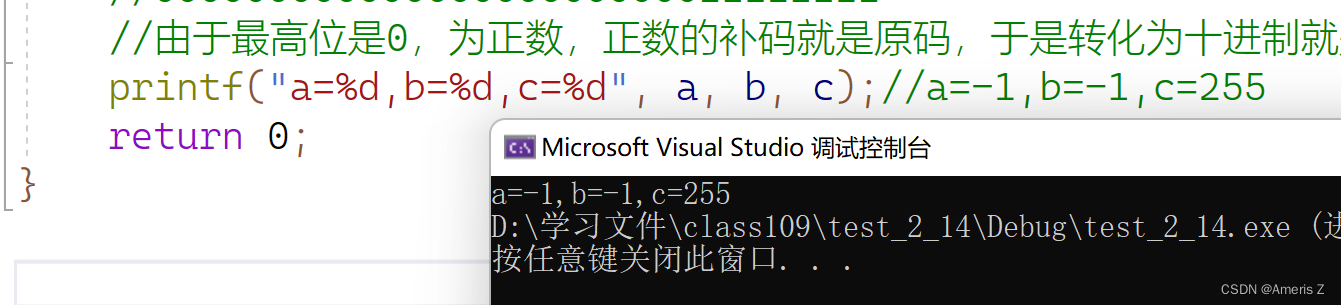
unsigned char c = -1;
//10000000000000000000000000000001
//11111111111111111111111111111110
//11111111111111111111111111111111
//11111111 - 截断
//整型提升 - 因为unsigned char c是无符号整型,默认补0
//00000000000000000000000011111111
//由于最高位是0,为正数,正数的补码就是原码,于是转化为十进制就是 255
printf("a=%d,b=%d,c=%d", a, b, c);//a=-1,b=-1,c=255
return 0;
}
2.
int main()
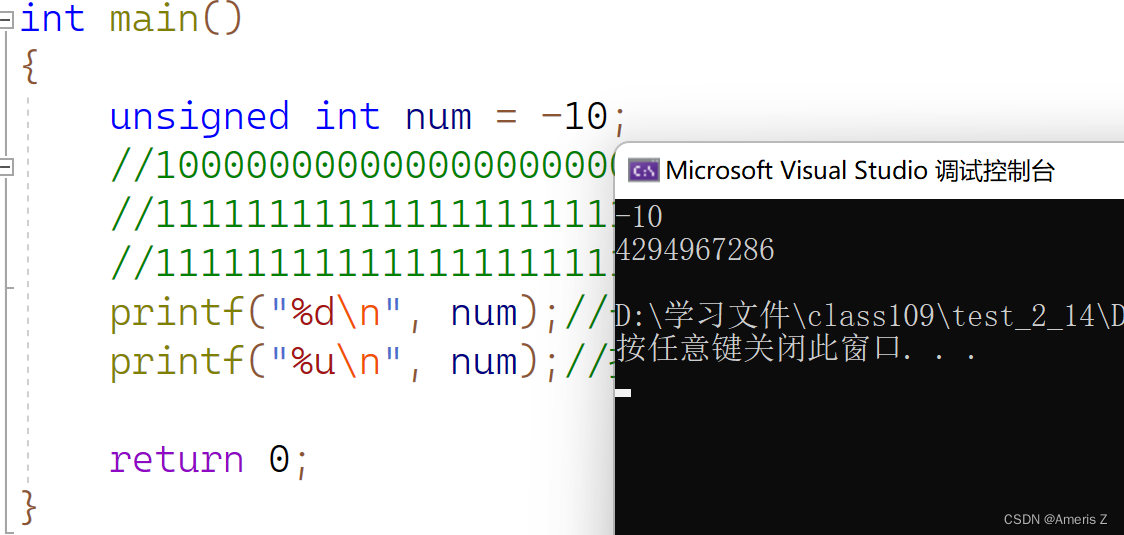
{
unsigned int num = -10;
//10000000000000000000000000001010
//11111111111111111111111111110101
//11111111111111111111111111110110 - 补码
printf("%d\n", num);//-10
printf("%u\n", num);//打印无符号的十进制,符号位失去意义,当值数值计算了4294967286
return 0;
}
3.
int main()
{
char a = -128;
//10000000000000000000000010000000
//11111111111111111111111101111111
//11111111111111111111111110000000 - 补码
//10000000 - 截断
//整型提升 - 补符号位1 (10000000)
//11111111111111111111111110000000 - 补码
printf("%u\n", a);//4294967168
//打印无符号十进制数,则该补码的符号位没有意义,
//变为数值位了,此时补码直接看作原码,化为十进制则为4294967168
return 0;
}

4.
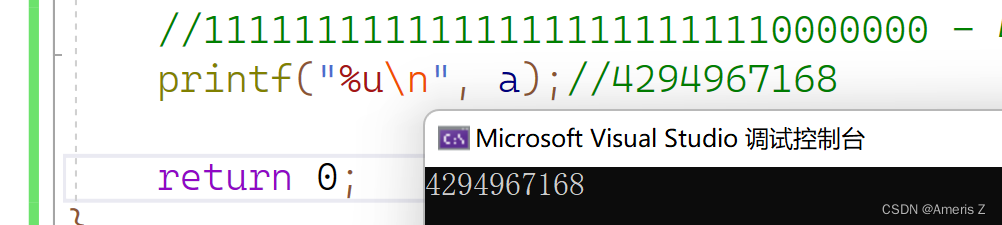
int main()
{
char a = 128;
//00000000000000000000000010000000
//01111111111111111111111101111111
//01111111111111111111111110000000 - 补码
//10000000 - 截断
//整型提升 - 有符号整型 补符号位1(10000000)
//11111111111111111111111110000000 - 4294967168
printf("%u\n", a);//4294967168
return 0;
} 
5.
int main()
{
int i = -20;
//10000000000000000000000000010100
//11111111111111111111111111101011
//11111111111111111111111111101100 -补码
unsigned int j = 10;
//00000000000000000000000000001010 - 10正数原反补相同
//11111111111111111111111111101100 - -20
//11111111111111111111111111110110 - 和(补码)
//10000000000000000000000000001001
//10000000000000000000000000001010 - -10(原码)
printf("%d\n", i + j);//-10
//按照补码的形式进行运算,最后格式化成为有符号整数
return 0;
}

6.
int main()
{
unsigned int i;
//无符号整型,没有符号位,每一位都是数值
for (i = 9; i >= 0; i--)
{
printf("%u\n", i);//死循环
Sleep(1000);//为了方便看到每一步的变化,使用函数隔一秒打印
}
//9 8 7 6 5 4 3 2 1 0之后 i--得到-1
//unsigned int i=-1
//11111111111111111111111111111111 - -1的补码
//由于无符号数,则该数的数值为4,294,967,295
//以此类推i--得到-2
//4,294,967,294
return 0;
}

7.
int main()
{
char a[1000];
//char类型的取值范围-128~127 一共有255个数,
//所以打印无法超过这个范围
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
//-1 -2 -3 ...-128 127 126 ....3 2 1 0
printf("%d", strlen(a));//255
//求数组a的字符串长度,遇到'\0'就停止,'\0'的ASCII码值就是 0
//数组最后一个元素 0 即 '\0'
//从-128~127,一共255个元素,所以strlen(a)值为255
return 0;
}

8.
unsigned char i = 0;
//范围-128~127
int main()
{
for (i = 0; i <= 255; i++)
{
printf("hello world\n");
}
//0~127打印hello world
//128~255也可打印
//unsigned char i = 128
//10000000 -补码
//unsigned char i = 255
//11111111 -补码
//当i++得到 unsigned char i=256时
//100000000 截断得到 00000000
//又变回了0,开始死循环
return 0;
}

五、整型计算总结
在计算时,我们要看输入的数据的类型(有符号 signed / 无符号unsigned 和 char 等是否要整型提升)以及数据的值(正负),还需要看是以怎样的形式输出的(有符号十进制%d / 无符号十进制 %u)
1、输入时:
1)char类型,则要注意截断和整型提升
2)signed 和 unsigned 则要注意如果有整型提升.
无符号unsigned类型 ,默认补位0
有符号signed类型,需要根据截断后的二进制,补符号位;
(例如:截断后10000000 则补位1;截断后00000001 则补位 0)
3)如果为正数,补码即为二进制原码,不需要额外计算。
4)如果为负数,需要 原码 反码 补码 计算
2、输出时
1)%d 打印有符号十进制数,记得把计算的补码,还原为原码
2)%u 打印无符号十进制数,补码即为结果