作者:深耕行业的 SmartX 金融团队
本文重点
SmartX 分布式块存储 ZBS 提供 2 种存算分离架构下的数据接入协议,分别是 iSCSI 和 NVMe-oF。其中,iSCSI 虽然具有很多优势,但不适合支持高性能的工作负载,这也是 SmartX 选择支持 NVMe-oF 的原因之一。
结合性能和网络条件这两个角度的考虑,ZBS 选择支持 NVMe over RDMA/RoCE v2 和 NVMe over TCP,以满足用户的多种需求。
ZBS 中,NVMe-oF 接入采用继承策略和均衡策略,这样的设计可以在充分利用多个存储接入点的同时避免占用所有存储接入点的处理能力,保持各个接入点的负载基本均衡。
从实验室基础性能验证和金融用户性能验证可以看出,相比 iSCSI 和 NVMe over TCP,使用 NVMe over RDMA 作为接入协议,可以取得较高的 I/O 性能输出,具体表现为更高的随机 IOPS 和顺序带宽,以及更低的延时表现。
1 背景
“分布式块存储 ZBS 的自主研发之旅|架构篇”文章提及了部分数据路径的设计实现,仅描述了当 I/O 发生时,Access 数据接入组件与 Meta 管理组件之间的通信过程,该过程属于整个 I/O 路径的后半段。
本篇文章,我们将详细介绍数据接入路径中的前半段,即计算端与 ZBS 通信的接入协议层,使读者可以更加全面地了解 ZBS 分布式存储接入协议,同时通过对比不同接入协议的原理实现、基础环境要求和性能测试数据,为客户在部署使用 ZBS,提供最佳实践参考。
本篇文章会涉及到 RDMA(Remote Direct Memory Access)技术,如果读者想更多地了解该技术细节,推荐阅读“分布式块存储 ZBS 的自主研发之旅|数据同步协议RDMA”文章。
2 Access 概述
Access 是虚拟存储对象(File/LUN/Namespace)与实际的数据块(Extent)之间的交互边界。Access 接收 NFS Client、iSCSI Initiator、NVMF initiator 的读写请求,并将不同的协议对象,例如 File、LUN、Namespace 转义成 ZBS 内部的 Volume 与 Extent 对象,并处理数据多副本等 ZBS 内部逻辑。
Access 通过 Session 机制与 Meta 建立联系,并由 Session 确保数据访问权限(Extent Lease)的唯一性。
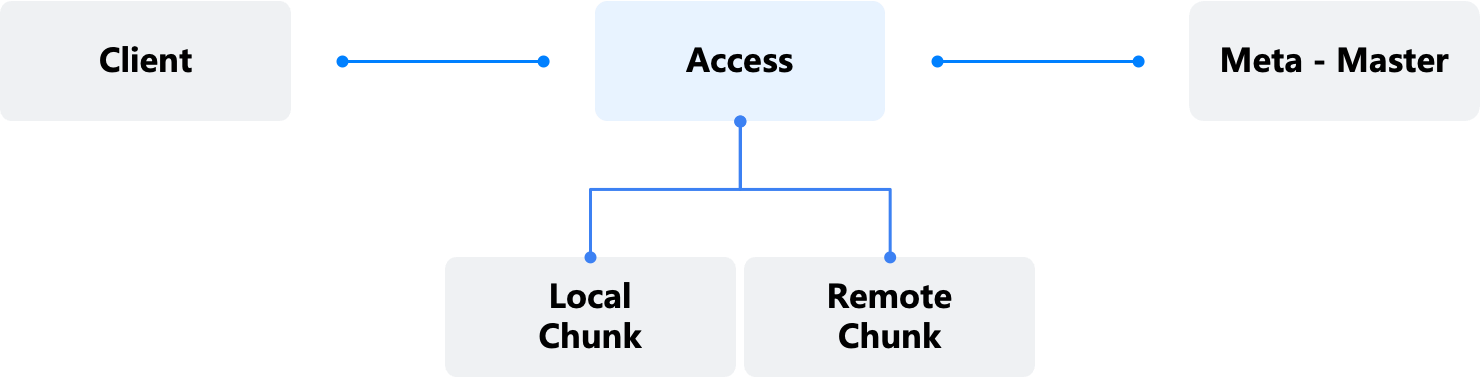
图 1:Access 接入服务
3 接入协议
目前 ZBS 提供 4 种接入协议,分别是 NFS、iSCSI、NVMe-oF 和 vHost,其中 NFS 和 vHost 主要应用场景是超融合架构(相关 vHost 详细介绍可参考文章 “SPDK vHost-user 如何帮助超融合架构实现 I/O 存储性能提升”),本文不进行过多展开,将主要介绍存算分离架构下的数据接入协议。
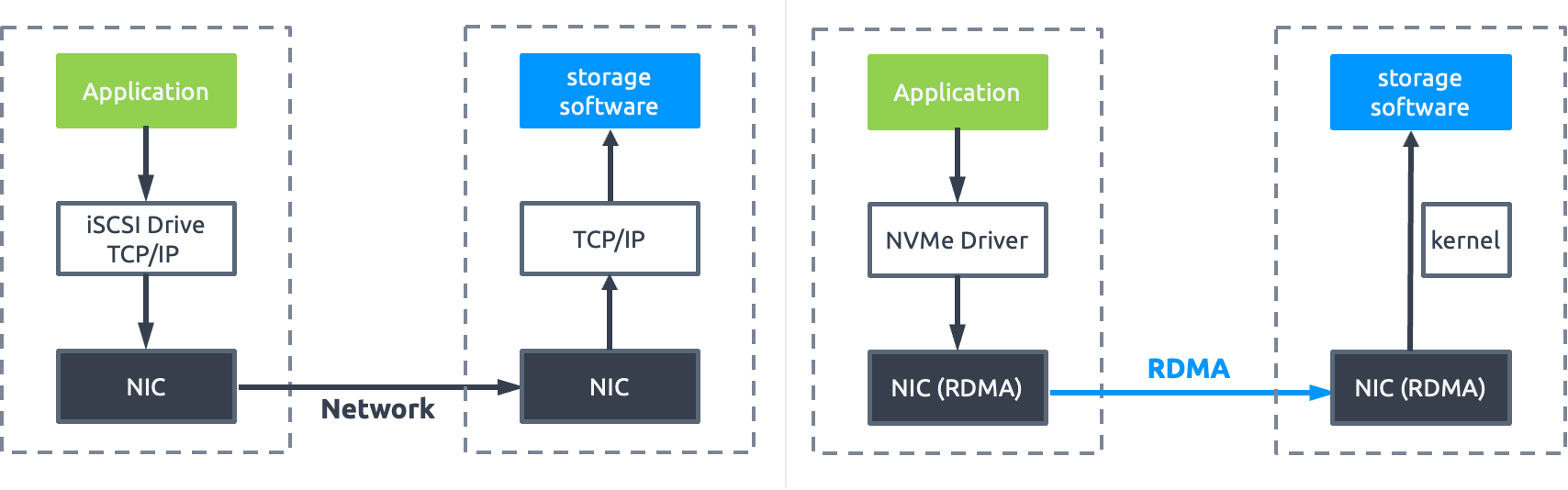
图 2:ZBS iSCSI & NVMe-oF 接入协议
3.1 ZBS iSCSI 实现
当前,在云计算块存储场景中,iSCSI 依然是分布式存储 SDS 主流的接入方法之一,其基于标准的 TCP/IP 协议栈、无需改动已有客户端系统、对服务器硬件和标准以太网有着广泛的兼容性、管理简单等特点,使 iSCSI 得到广泛的应用。
iSCSI 是目前 ZBS 支持的接入协议之一,在 ZBS 实现中,客户端(initiator)均不直接指向某个具体的存储节点 Access 作为协议接入端,而是指向 iSCSI Redirector 服务地址。当 iSCSI initiator 向 iSCSI Redirector 发起 Login 请求时,iSCSI Redirector 将登录请求转发给 Meta,Meta 根据与 Access 维护的 Session 信息寻找是否已经存在绑定的 Access Server,如有则返回对应的 Access Server 地址,否则将返回任一 Access Server 地址。客户端(initiator)将与对应的 Access Server 完成 Login 过程与后续的 I/O 处理流程。
通过 Redirector 服务可简化 iSCSI 接入高可用配置的复杂度。同样,iSCSI 也基于 Redirector 服务提供单一客户端(initiator)访问一个 iSCSI Target 仅使用一条数据链路的单点接入保证(避免同一 Target 的多点访问),以及接入链路均衡的作用。
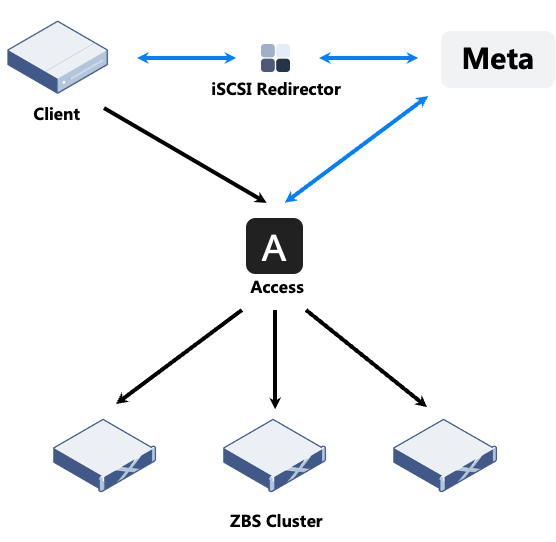
图 3 :iSCSI 接入架构
iSCSI 虽然具备很多使用上的优势,但是在性能层面,却一直存在难以充分发挥现代高速存储和网络设备性能的问题,SCSI 协议的设计和开发时间可以追溯到上个世纪,首先是当时硬件环境还是以机械磁盘为主流,协议对当今高性能硬件,例如 NVMe 介质,以及现代工作负载的要求,已显疲态。其次是协议栈层面,长期不断的开发迭代,相较新型的协议,iSCSI 相对厚重且效率低下。
对于性能提升,iSER(iSCSI Extensions for RDMA)是 iSCSI 的一次进化,通过 RDMA 能力,来提升 iSCSI 在网络层的性能。ZBS 并没有采用这样的技术栈,原因也很简单,因为 iSER 的基石依然是 iSCSI,前面也简要分析了该协议的一些不足,做个比喻,就是建筑物和地基的关系。既然要使用 RDMA,选择新型的 NVMe 协议支撑高性能的工作负载会是更优的选择。
3.2 NVMe-oF 介绍
在介绍 NVMe-oF 之前,首先简单介绍一下 NVM Express(NVMe)协议规范,该协议定义主机如何通过 PCIe 总线与非易失性存储器进行通信。NVMe 规范是为 SSD 高速存储介质而量身设计,相较于 SCSI,是一种更加高效的接口规范,支持 65535 个 I/O 队列,每个队列支持 65535 条命令(队列深度)。队列映射提供预期的 CPU 资源调度,并能适应在中断或轮询模式下的设备驱动,提供了更高的数据吞吐和更低的通信延迟。
更快的存储,则需要更快的网络才能发挥最大的存储价值。NVMe-oF 全称是 NVMe over Fabrics(本文均采用缩写 NVMe-oF),它把 NVMe 在单系统内部提供的高性能、低延迟和极低的协议开销等优势进一步发挥到客户端与存储系统互联的网络结构当中。NVMe-oF 定义了使用多种通用的传输层协议来实现 NVMe 远程连接能力。

图 4:NVMe over Fabrics
NVMe-oF 承载网络(数据平面)包括:
(1)NVMe over FC:基于传统的 FC 网络(主机总线适配器 HBA 和光纤交换机构建的专有通信网络),与 FC-SAN(SCSI)可以同时运行在同一个 FC 网络中,最大化地复用 FC 网络基础环境,发挥 NVMe 新型协议的优势。常用于传统集中存储的升级改造。
(2)NVMe over RDMA:通过远程直接内存访问技术,允许客户端程序远程访问存储系统的内存空间进行数据传输。具有数据零拷贝(不涉及网络堆栈执行数据传输)、Kernel Bypass(应用程序可以直接从用户空间执行数据传输,无需内核参与)、减少 CPU 资源消耗(应用程序可以访问远程内存,而无需在远程服务器中消耗任何 CPU Cycle)等特点。
① InfiniBand - 通过 InfiniBand 网络使用 RDMA,在高性能计算 HPC 领域非常流行,与 FC 相似,需要专有的网络适配器和交换网络支撑。
② RoCE - 全称 RDMA over Converged Ethernet,即通过以太网实现 RDMA,目前有两个版本:RoCEv1 不可路由,仅可以在 2 层工作;RoCEv2 使用 UDP/IP,具有 3 层路由能力。
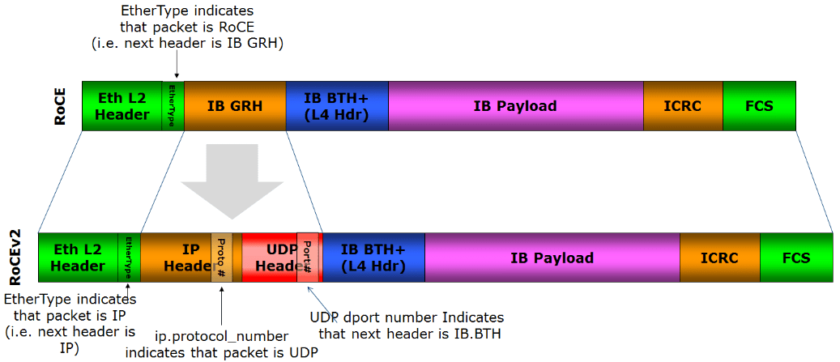
图 5:RoCEv1/v2 帧结构(来自 Wikipedia)
③ iWARP - 构建在 TCP/IP 之上。跟 RoCE 协议继承自 Infiniband 不同,iWARP 本身不是直接从 Infiniband 发展而来的。Infiniband 和 RoCE 协议都是基于 “Infiniband Architecture Specification”,也就是常说的“IB 规范”。而 iWARP 是自成一派,遵循着一套 IETF 设计的协议标准。虽然遵循着不同的标准,但是 iWARP 的设计思想受到了很多 Infiniband 的影响,并且目前使用同一套编程接口。
(3)NVMe over TCP:与前两种实现方式不同,该方案无需任何特殊的硬件要求,基于通用标准以太网环境。成本低是该协议的优势,缺点是需要更多的 CPU 资源参与数据处理,受限于 TCP/IP 协议,在数据传输中相对 RDMA 会引入更多的延迟。
ZBS 不支持 FC 和 IB 的主要原因是其依赖专有网络,这与 ZBS 的产品定位相冲突(基于标准以太网构建分布式存储网络)。而不支持 iWARP 原因是对比 RoCE 来看(这是一个二选一问题),在生态、协议效率和复杂度等多方面因素评估下,SmartX 更加看好 RoCE 未来的发展,在极致的性能诉求下,RoCE 也会比 iWARP 具有更强的潜力。当然,RoCE 在数据重传和拥塞控制上受限于协议,需要无损网络的环境(RoCE 对于丢包 PSN 的 NACK 重传机制,性能非常差)。这样的客观条件,是任何一个存储厂家需要结合自身产品权衡的选择题。
总结一下,应用 NVMe-oF,可以选择的技术路线有 3 条,分别是 FC、RDMA 和 TCP,从性能和网络条件这两个维度出发,ZBS 选择支持 RDMA/RoCE v2 和 TCP,这样的组合,可以非常好地适配不同客户的个性需求。
对性能敏感,并愿意为提高性能而投入更多的网络成本,可以选择使用 RDMA/RoCE v2 接入方案。
对成本敏感或受网络条件限制,可以选择 TCP 的接入方案。
3.3 ZBS NVMe-oF 实现
NVMe-oF 在 ZBS 中支持两种形态,即 RDMA/RoCE v2 和 TCP,这两个形态区别仅体现在外部客户端使用哪种协议接入 Access,在元数据管理上并没有区别。
NVMe-oF 协议本身与 iSCSI 协议有很多相似的地方,例如客户端标识为 initiator 端,服务端为 Target 端,NVMe-oF 协议中使用与 iSCSI IQN 近似的 NQN 来作为协议通讯双方的标识等。同时,NVMe-oF 定义了 Subsystem(子系统,相当于 SCSI 体系下的 Target)和 Namespace(命名空间,类似于 SCSI 体系下的 LUN)专有标准。
相比于 iSCSI 通过 initiator + Target 的数据链路控制,NVMe-oF 可以支持 initiator + Namespace 这样更小的链路控制粒度。NVMe-oF 在路径策略选择上(协议原生支持 Multipath)是通过 ANA(Asymmetric Namespace Access)机制指定 Target 链路优先级,再由客户端结合优先级与自身的链路状态探测结果选择 I/O 具体路径。
ANA 状态包括:Optimized 最优/Non-Optimized 次优/Inaccessible 不可达/Persistent Loss 失去连接/Change 状态变更。
ZBS 会将所有的可用链路设置为 OP(最优链路)和 Non-OP(次优链路)两种状态,其他状态未发生异常或变化时由 Driver 自动标记。对于每个 initiator + Namespace 的组合,仅返回 1 个最优接入点和 2 个次优接入点。在最优接入点可用时,客户端将仅通过最优接入点访问数据,在异常时选择 2 个次优接入点中的一个进行访问(出于简化安全性处理的考虑,部署时会要求客户端配置为 AB 模式,即使 2 个次优接入点是等价的,也不会进入 AA 模式,同时从两个接入点中下发 I/O)。
ZBS 接入策略:
继承策略,同一客户端访问同一 Subsystem 中的所有 Namespace 使用同一接入点。
均衡策略,保证同一 Namespace Group 中的 Namespace 尽量使用不同接入点。
ZBS 接入点分配策略可以实现以下目标:
在客户端视角,允许利用多个存储接入点的处理能力。
在客户端视角,保证不同客户端的公平性,避免占用所有存储接入点的处理能力。
在存储接入点视角,保持各个接入点的负载基本均衡,同时又尽可能发挥多个接入点的处理能力。

图 6:NVMe-oF 接入架构
4 实验室性能验证数据
4.1 环境信息
存储集群,由 3 节点组成,安装 SMTX ZBS 5.2 OS,存储内部网络开启 RDMA ,分层存储结构,所有存储节点的硬件配置相同,节点环境信息如下:

计算端安装 CentOS 8.2 操作系统,使用 FIO 压测工具(模型 direct=1,numjobs=1,ioengine=libaio),硬件环境信息如下:

4.2 性能数据
在相同的测试环境和测试方法下,分别使用不同的接入协议进行性能验证(iSCSI、NVMe over TCP 和 NVMe over RDMA),测试基于单卷(单节点性能,测试 1 个 2 副本卷)和多卷(集群性能,对于 3 节点集群,将测试 3 个 2 副本卷)的存储基准性能(4K 随机 I/O,256K 顺序 I/O)。
4.2.1 单卷性能
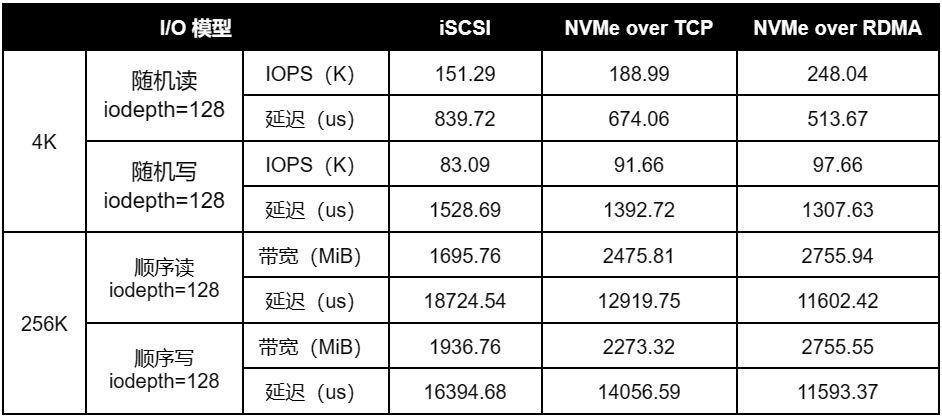
4.2.2 多卷性能

4.3 测试结论
通过以上基准测试数据,可以看到,相同软硬件环境以及测试方法下,使用 NVMe over RDMA 作为接入协议,可以取得较高的 I/O 性能输出,其表现为更高的随机 IOPS 和顺序带宽,以及更低的延时表现。
5 某股份制银行性能验证数据
与实验室基准测试数据不同,用户关注的是贴合自身应用业务的真实 I/O 模型。某股份制银行性能验证要求如下:
在相同环境下,验证 iSCSI、NVMe over TCP 和 NVMe over RDMA 性能表现。
I/O 模型为 8K 和 16K 随机读写,读写比例 5 : 5。
验证写平均延迟不大于 300us 和 500us 下的 IOPS 的性能表现以及对应的 iodepth。
所有接入协议场景,分布式存储内部均开启 RDMA。
5.1 环境信息
存储集群,由 3 节点组成,安装 SMTX ZBS 5.0 OS,存储内部网络开启 RDMA ,所有存储节点的硬件配置相同,节点环境信息如下:
3 台计算端,安装 CentOS 8.4 操作系统,使用 vdbench 压测工具,硬件环境信息如下:

5.2 性能数据
在相同的测试环境和测试方法下,分别使用不同的接入协议进行性能验证(iSCSI、NVMe over TCP 和 NVMe over RDMA),测试多卷集群性能(3 节点存储集群,将测试 3 个 2 副本卷)。
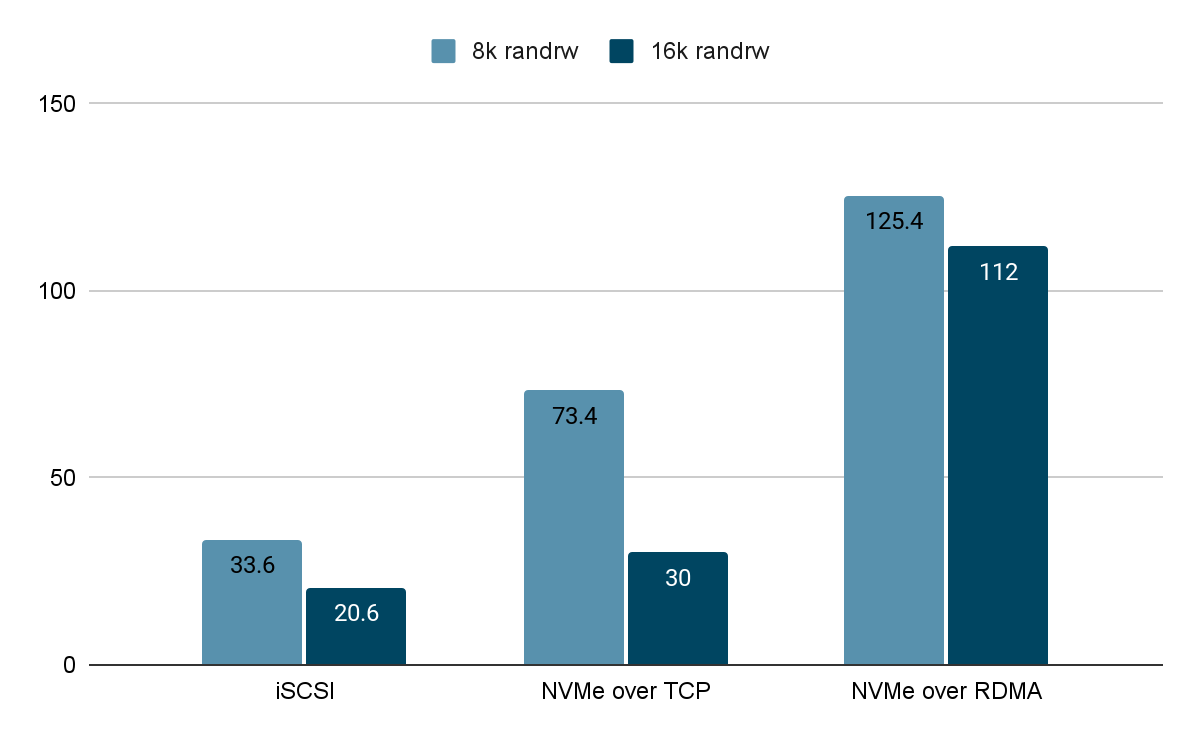
5.2.1 延时 <= 300us 测试数据 IOPS(单位:K)
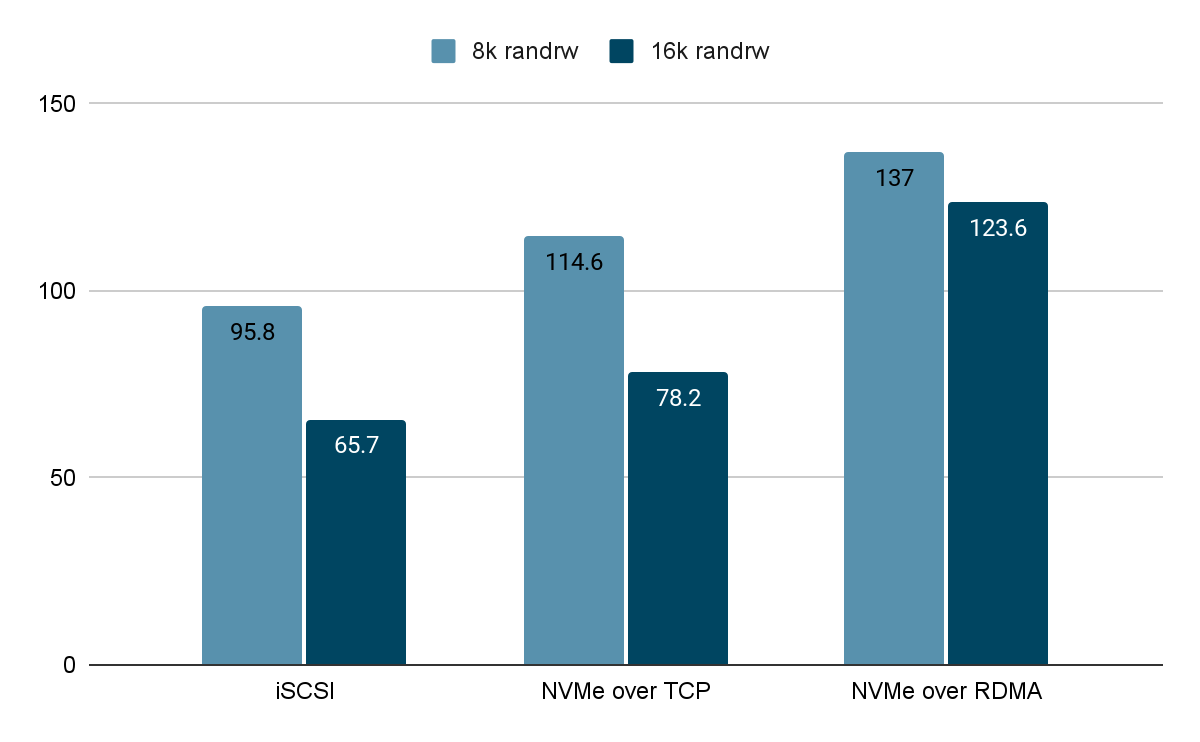
5.2.2 延迟 <= 500us 测试数据 IOPS(单位:K)
5.3 测试结论
通过固定写入延迟,观察在调整 iodepth 深度下不同接入协议所能发挥的 IOPS 性能。从测试结果可以看出,在 8K 和 16K 混合读写测试场景中,NVMe over RDMA 依然发挥出最高的随机 I/O 性能。
6 结论
本文详细描述 ZBS 分布式块存储的数据接入原理,同时分别介绍了所支持的多种接入协议的实现方式,以及背后的思考。通过原理介绍和实际验证数据,希望给读者一个全面的视角理解 ZBS 接入服务,为更好部署和使用 ZBS 提供参考。
参考文章:
1. RDMA over Converged Ethernet. Wikipedia.
https://en.wikipedia.org/wiki/RDMA_over_Converged_Ethernet
2. How Ethernet RDMA Protocols iWARP and RoCE Support NVMe over Fabrics.
https://www.snia.org/sites/default/files/ESF/How_Ethernet_RDMA_Protocols_Support_NVMe_over_Fabrics_Final.pdf