起因
恰逢周末, 最近公司接入了分布式定时任务,我是负责接入这块的,正好在网上想起了之前看过的分布式任务的文章,然后学习一下 各路框架发现看了很多框架比如 elasticjob
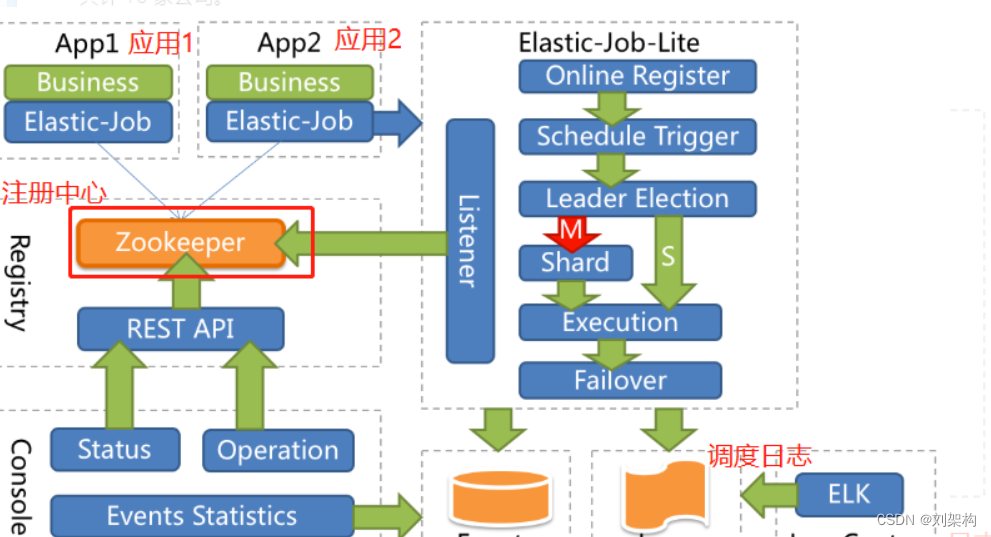
跟xxl-job不同的是,elasticjob是采用zookeeper实现分布式协调,实现任务高可用以及分片。
最后还是下面这个框架适合整合,所以写了这篇文章, 为什么不自己从零到一去写一个分布式定时任务, 下面也写了对应的回答,
因为要站在巨人的肩膀上, 学习借鉴前辈的思路
为什么不自己写一套?
需要很大的时间成本,还要从各种层面去考虑 生态性、健全性、以及和第三方扩展、还要各种 设计 技术选型,画PPT、所以 划不来,而且市面上本来就存在通用的这一套框架,所以就使用了XXL-Job

概述
XXL-JOB任务 :

XXL-JOB 是一个轻量级分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
- XXL-JOB 官方文档: https://www.xuxueli.com/xxl-job/
- XXL-JOB 交流社区: https://www.xuxueli.com/page/community.html
1、简单:支持通过Web页面对任务进行CRUD操作,操作简单,一分钟上手;
2、动态:支持动态修改任务状态、启动/停止任务,以及终止运行中任务,即时生效;
3、调度中心HA(中心式):调度采用中心式设计,“调度中心”自研调度组件并支持集群部署,可保证调度中心HA;
4、执行器HA(分布式):任务分布式执行,任务”执行器”支持集群部署,可保证任务执行HA;
5、注册中心: 执行器会周期性自动注册任务, 调度中心将会自动发现注册的任务并触发执行。同时,也支持手动录入执行器地址;
6、弹性扩容缩容:一旦有新执行器机器上线或者下线,下次调度时将会重新分配任务;
7、触发策略:提供丰富的任务触发策略,包括:Cron触发、固定间隔触发、固定延时触发、API(事件)触发、人工触发、父子任务触发;
8、调度过期策略:调度中心错过调度时间的补偿处理策略,包括:忽略、立即补偿触发一次等;
9、阻塞处理策略:调度过于密集执行器来不及处理时的处理策略,策略包括:单机串行(默认)、丢弃后续调度、覆盖之前调度;
10、任务超时控制:支持自定义任务超时时间,任务运行超时将会主动中断任务;
11、任务失败重试:支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;其中分片任务支持分片粒度的失败重试;
12、任务失败告警;默认提供邮件方式失败告警,同时预留扩展接口,可方便的扩展短信、钉钉等告警方式;
13、路由策略:执行器集群部署时提供丰富的路由策略,包括:第一个、最后一个、轮询、随机、一致性HASH、最不经常使用、最近最久未使用、故障转移、忙碌转移等;
14、分片广播任务:执行器集群部署时,任务路由策略选择”分片广播”情况下,一次任务调度将会广播触发集群中所有执行器执行一次任务,可根据分片参数开发分片任务;
15、动态分片:分片广播任务以执行器为维度进行分片,支持动态扩容执行器集群从而动态增加分片数量,协同进行业务处理;在进行大数据量业务操作时可显著提升任务处理能力和速度。
16、故障转移:任务路由策略选择”故障转移”情况下,如果执行器集群中某一台机器故障,将会自动Failover切换到一台正常的执行器发送调度请求。
17、任务进度监控:支持实时监控任务进度;
18、Rolling实时日志:支持在线查看调度结果,并且支持以Rolling方式实时查看执行器输出的完整的执行日志;
19、GLUE:提供Web IDE,支持在线开发任务逻辑代码,动态发布,实时编译生效,省略部署上线的过程。支持30个版本的历史版本回溯。
20、脚本任务:支持以GLUE模式开发和运行脚本任务,包括Shell、Python、NodeJS、PHP、PowerShell等类型脚本;
21、命令行任务:原生提供通用命令行任务Handler(Bean任务,”CommandJobHandler”);业务方只需要提供命令行即可;
22、任务依赖:支持配置子任务依赖,当父任务执行结束且执行成功后将会主动触发一次子任务的执行, 多个子任务用逗号分隔;
23、一致性:“调度中心”通过DB锁保证集群分布式调度的一致性, 一次任务调度只会触发一次执行;
24、自定义任务参数:支持在线配置调度任务入参,即时生效;
25、调度线程池:调度系统多线程触发调度运行,确保调度精确执行,不被堵塞;
26、数据加密:调度中心和执行器之间的通讯进行数据加密,提升调度信息安全性;
27、邮件报警:任务失败时支持邮件报警,支持配置多邮件地址群发报警邮件;
28、推送maven中央仓库: 将会把最新稳定版推送到maven中央仓库, 方便用户接入和使用;
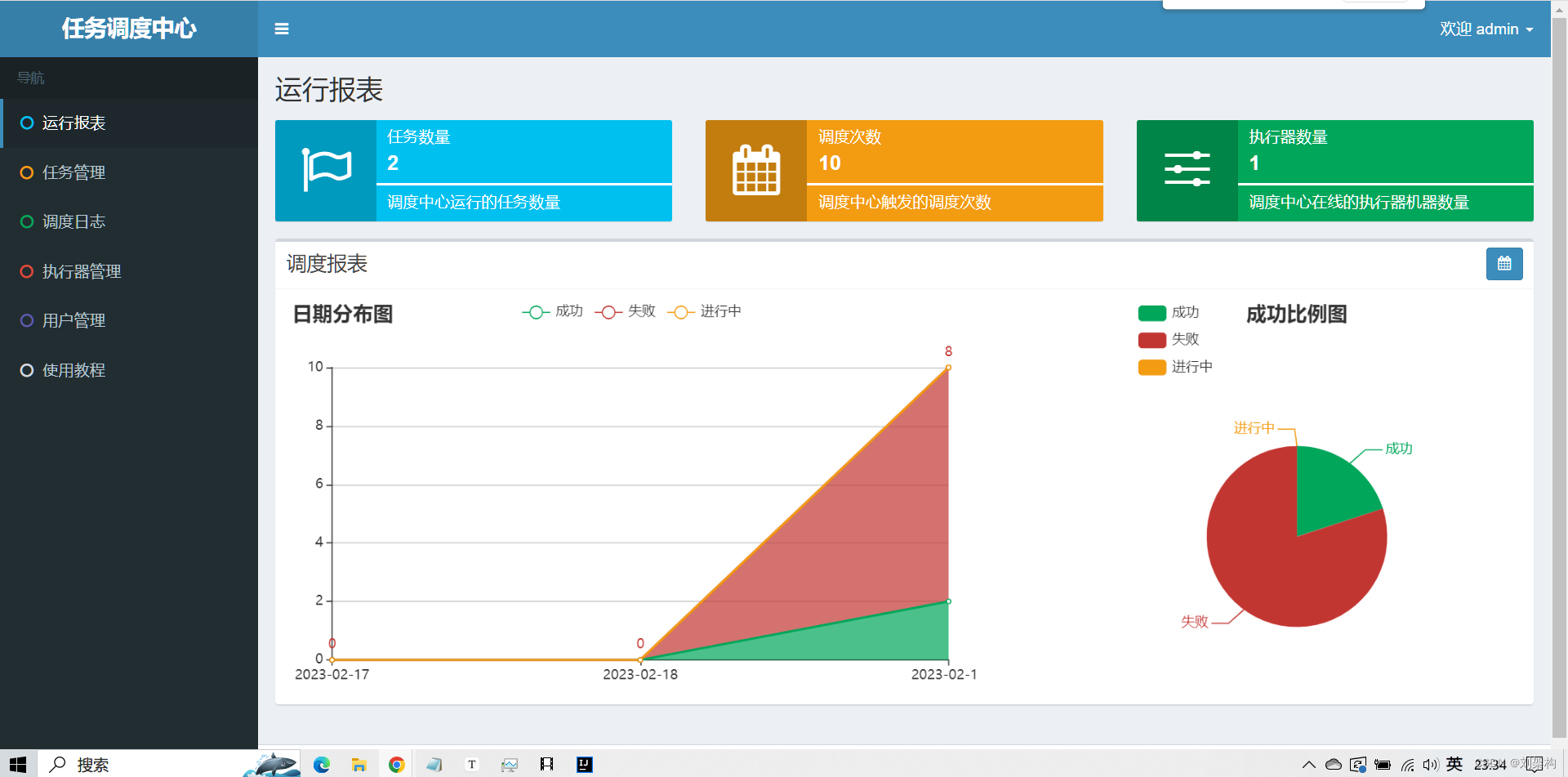
29、运行报表:支持实时查看运行数据,如任务数量、调度次数、执行器数量等;以及调度报表,如调度日期分布图,调度成功分布图等;
30、全异步:任务调度流程全异步化设计实现,如异步调度、异步运行、异步回调等,有效对密集调度进行流量削峰,理论上支持任意时长任务的运行;
31、跨语言:调度中心与执行器提供语言无关的 RESTful API 服务,第三方任意语言可据此对接调度中心或者实现执行器。除此之外,还提供了 “多任务模式”和“httpJobHandler”等其他跨语言方案;
32、国际化:调度中心支持国际化设置,提供中文、英文两种可选语言,默认为中文;
33、容器化:提供官方docker镜像,并实时更新推送dockerhub,进一步实现产品开箱即用;
34、线程池隔离:调度线程池进行隔离拆分,慢任务自动降级进入”Slow”线程池,避免耗尽调度线程,提高系统稳定性;
35、用户管理:支持在线管理系统用户,存在管理员、普通用户两种角色;
36、权限控制:执行器维度进行权限控制,管理员拥有全量权限,普通用户需要分配执行器权限后才允许相关操作;
本地部署
1. 克隆代码到本地
git clone https://gitee.com/xuxueli0323/xxl-job
-
项目结构
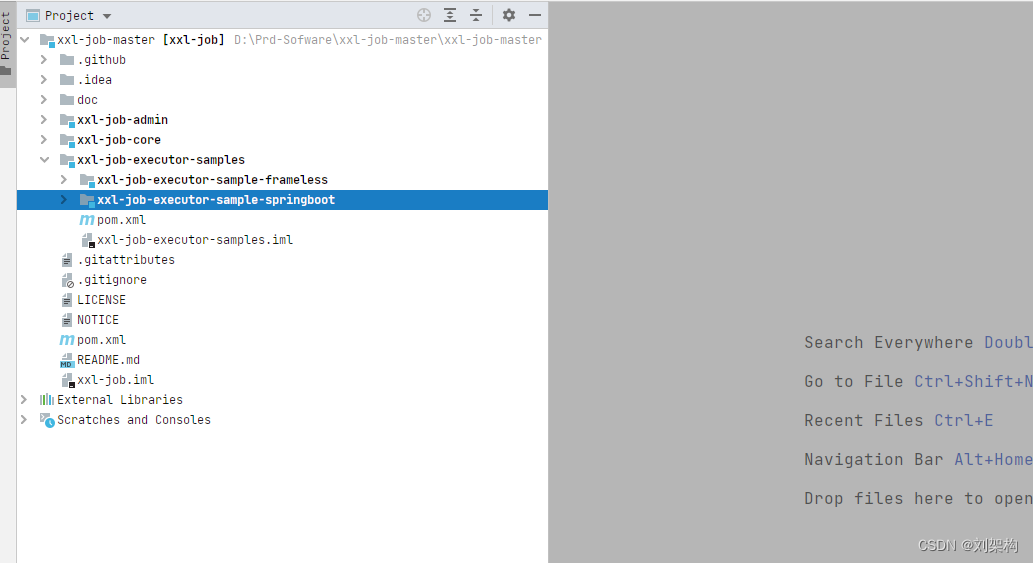
-
模块分析
- xxl-job-admin:调度中心
- xxl-job-core:公共依赖
- xxl-job-executor-samples:执行器Sample示例(选择合适的版本执行器,可直接使用,也可以参考其并将现有项目改造成执行器)
xxl-job-executor-sample-springboot:Springboot版本,通过Springboot管理执行器,推荐这种方式;
xxl-job-executor-sample-frameless:无框架版本;
上面的核心默认其实就是
调度中心项目 :xxl-job-admin 作用:统一管理任务调度平台上调度任务,负责触发调度执行,并且提供任务管理平台。
下载好之后,你可以通过修改Springboot的数据连接
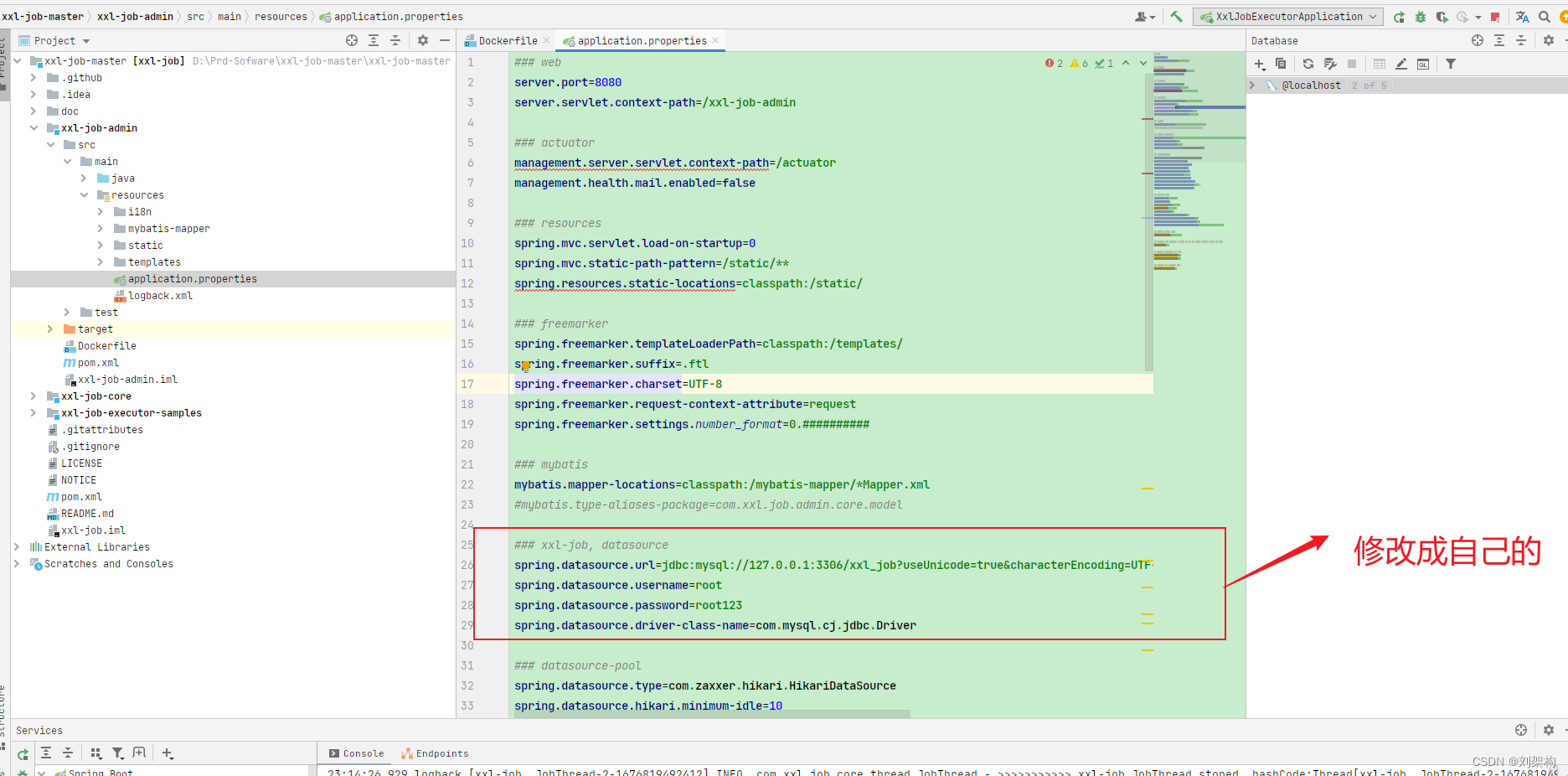
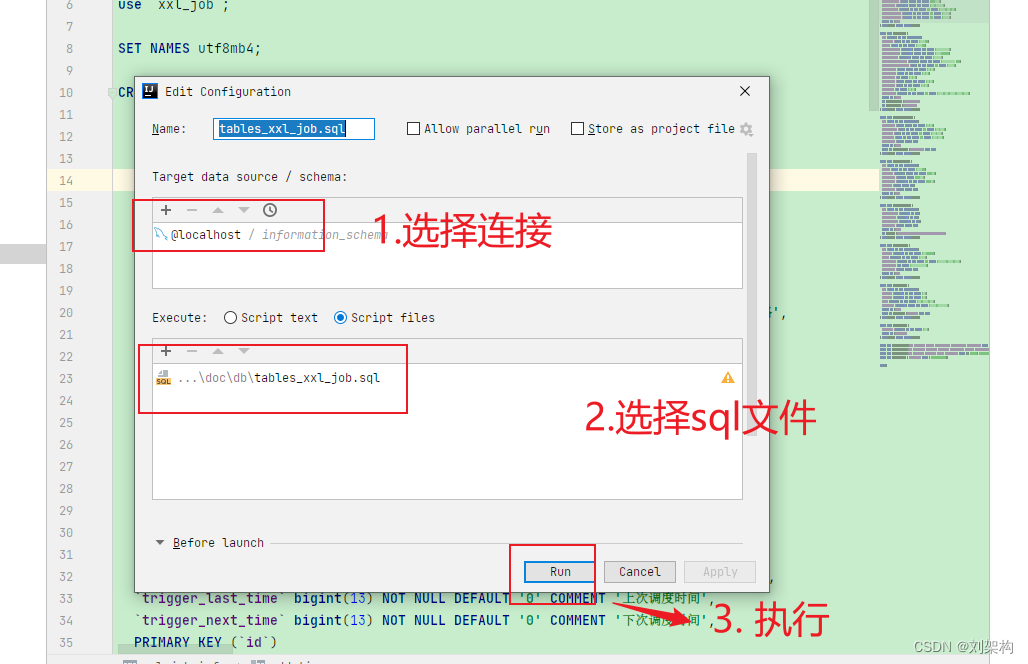
- 2. 使用IDEA 工具 快速执行sql
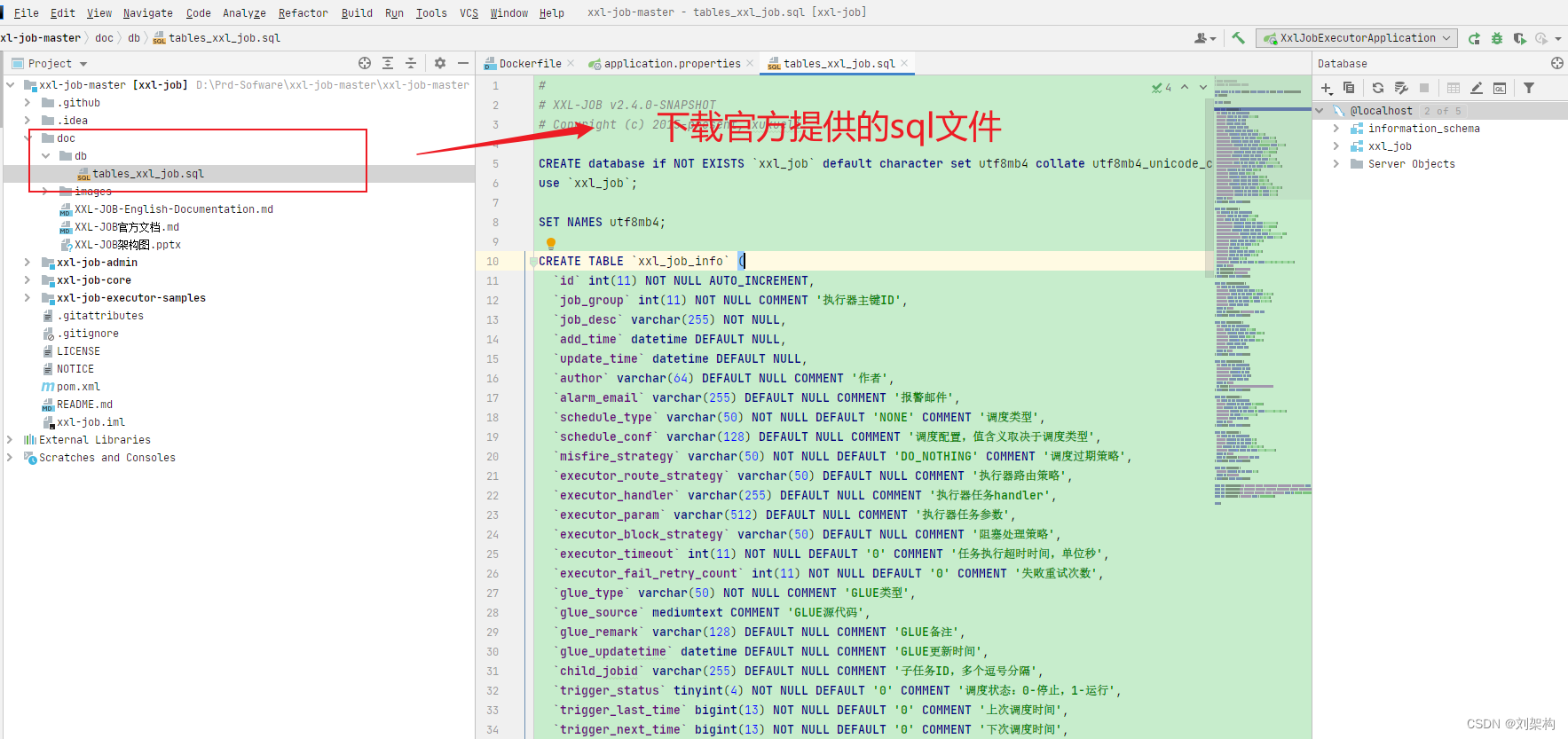
右键
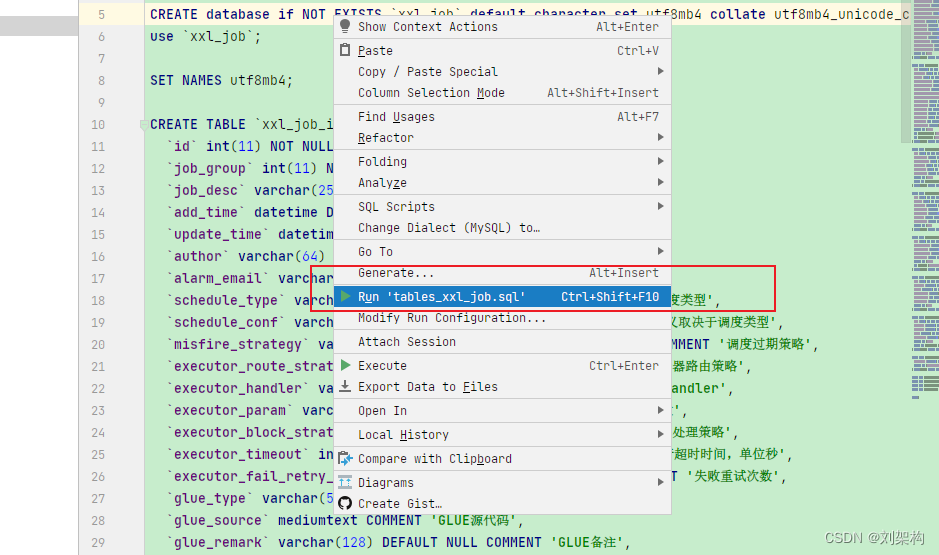
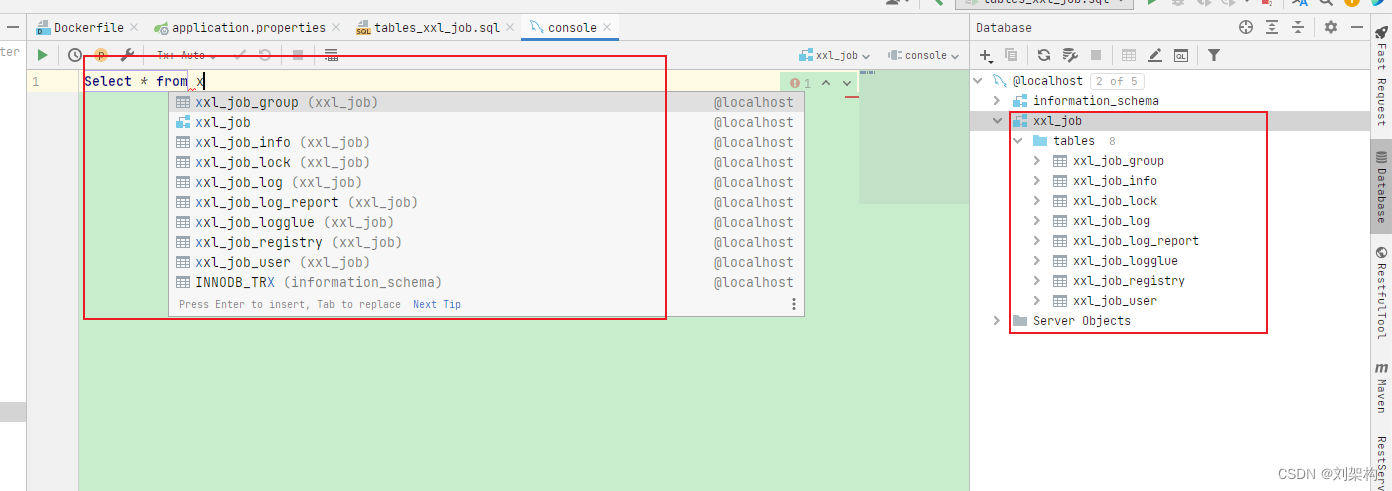
- 当你执行之后你就可以查询到了
下面是分布式任务默认提供的表
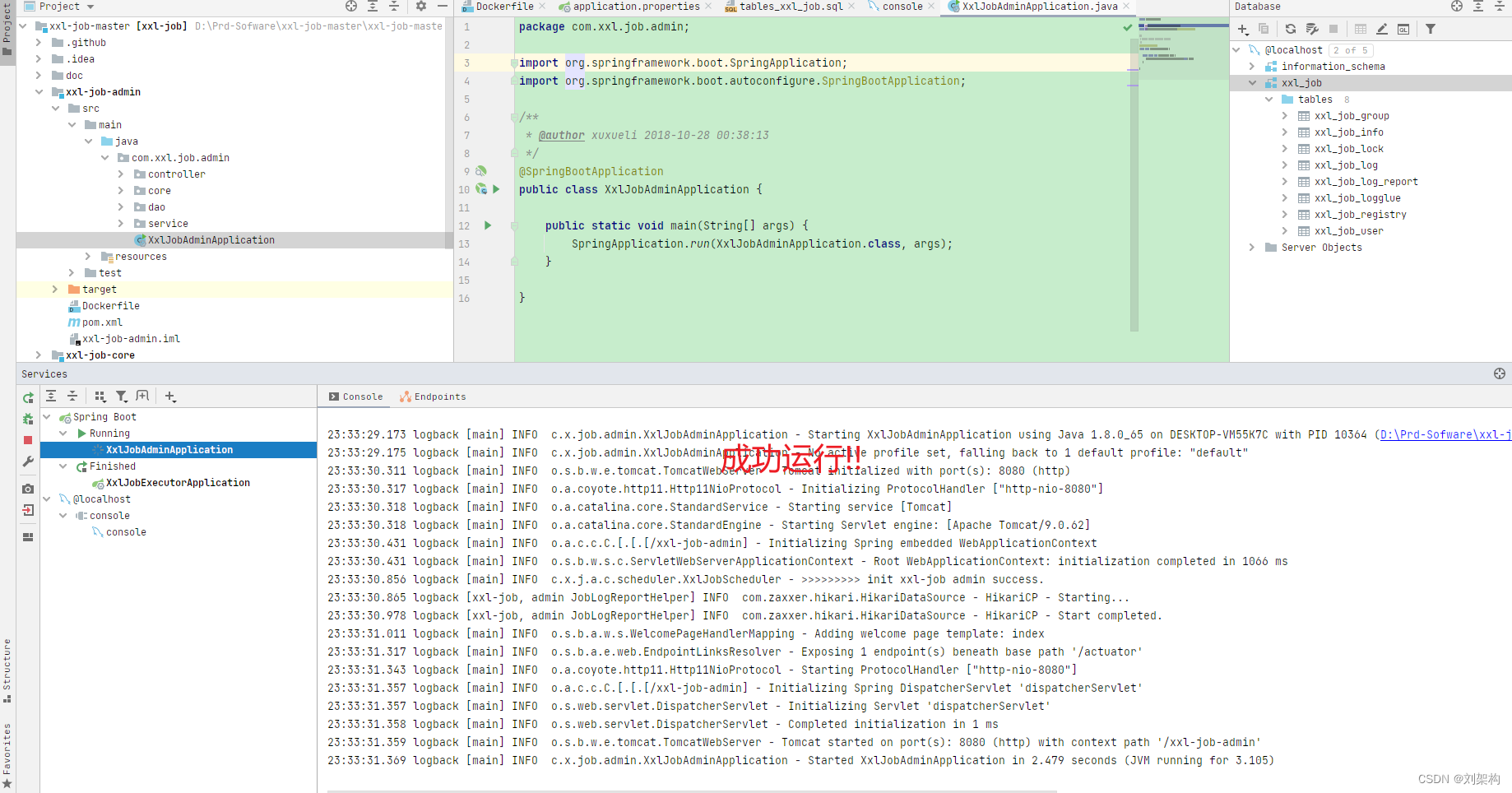
调度中心访问地址:http://localhost:8080/xxl-job-admin (该地址执行器将会使用到,作为回调地址)
默认登录账号 “admin/123456”, 登录后运行界面如下图所示。
Docker 部署
// Docker地址:https://hub.docker.com/r/xuxueli/xxl-job-admin/ (建议指定版本号)
docker pull xuxueli/xxl-job-admin
docker run -p 8080:8080 -v /tmp:/data/applogs --name xxl-job-admin -d xuxueli/xxl-job-admin:{指定版本}
/**
* 如需自定义 mysql 等配置,可通过 "-e PARAMS" 指定,参数格式 PARAMS="--key=value --key2=value2" ;
* 配置项参考文件:/xxl-job/xxl-job-admin/src/main/resources/application.properties
* 如需自定义 JVM内存参数 等配置,可通过 "-e JAVA_OPTS" 指定,参数格式 JAVA_OPTS="-Xmx512m" ;
*/
docker run -e PARAMS="--spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-
- “执行器”项目:xxl-job-executor-sample-springboot (提供多种版本执行器供选择,现以 springboot 版本为例,可直接使用,也可以参考其并将现有项目改造成执行器)
作用:负责接收“调度中心”
的调度并执行;可直接部署执行器,也可以将执行器集成到现有业务项目中。
(公司级) 快速开始
恭喜你 ! 运行起来以后,就可以开始写代码了
官方其实已经提供了一个最初始的Hello World 模块大家可以看一下
如果说是我们自己的项目那么我们需要做一下操作 具体参考以上例子,才能跟 XXL-JOB 进行整合
- 导入依赖
<!-- xxl-job-core -->
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>${project.parent.version}</version>
</dependency>
- 创建配置类(无需修改)
@Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
/**
* 针对多网卡、容器内部署等情况,可借助 "spring-cloud-commons" 提供的 "InetUtils" 组件灵活定制注册IP;
*
* 1、引入依赖:
* <dependency>
* <groupId>org.springframework.cloud</groupId>
* <artifactId>spring-cloud-commons</artifactId>
* <version>${version}</version>
* </dependency>
*
* 2、配置文件,或者容器启动变量
* spring.cloud.inetutils.preferred-networks: 'xxx.xxx.xxx.'
*
* 3、获取IP
* String ip_ = inetUtils.findFirstNonLoopbackHostInfo().getIpAddress();
*/
}
3. 配置 yaml 文件
xxl:
job:
admin:
# 调度中心部署跟地址 [选填]:如调度中心集群部署存在多个地址则用逗号分隔。
# 执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";为空则关闭自动注册;
addresses: http://127.0.0.1:8086/xxl-job-admin
# 执行器通讯TOKEN [选填]:非空时启用;
accessToken:
executor:
# 执行器AppName [选填]:执行器心跳注册分组依据;为空则关闭自动注册
appname: xxl-job-executor-mileage
# 执行器注册 [选填]:优先使用该配置作为注册地址,为空时使用内嵌服务 ”IP:PORT“ 作为注册地址。
#从而更灵活的支持容器类型执行器动态IP和动态映射端口问题。
address:
# 执行器IP [选填]:默认为空表示自动获取IP,多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;
# 地址信息用于 "执行器注册" 和 "调度中心请求并触发任务";
ip:
# 执行器端口号 [选填]:小于等于0则自动获取;默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口;
port: 8088
# 执行器运行日志文件存储磁盘路径 [选填] :需要对该路径拥有读写权限;为空则使用默认路径;
logpath: /data/applogs/xxl-job/jobhandler
# 执行器日志文件保存天数 [选填] : 过期日志自动清理, 限制值大于等于3时生效; 否则, 如-1, 关闭自动清理功能;
logretentiondays: 30
logging:
config: classpath:logback.xml
当然你也可以配置 properties 都可以 (二者选其一)
# web port
server.port=8081
# no web
#spring.main.web-environment=false
# log config
logging.config=classpath:logback.xml
### xxl-job admin address list, such as "http://address" or "http://address01,http://address02"
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
### xxl-job, access token
xxl.job.accessToken=default_token
### xxl-job executor appname
xxl.job.executor.appname=xxl-job-executor-sample
### xxl-job executor registry-address: default use address to registry , otherwise use ip:port if address is null
xxl.job.executor.address=
### xxl-job executor server-info
xxl.job.executor.ip=
xxl.job.executor.port=9999
### xxl-job executor log-path
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
### xxl-job executor log-retention-days
xxl.job.executor.logretentiondays=30
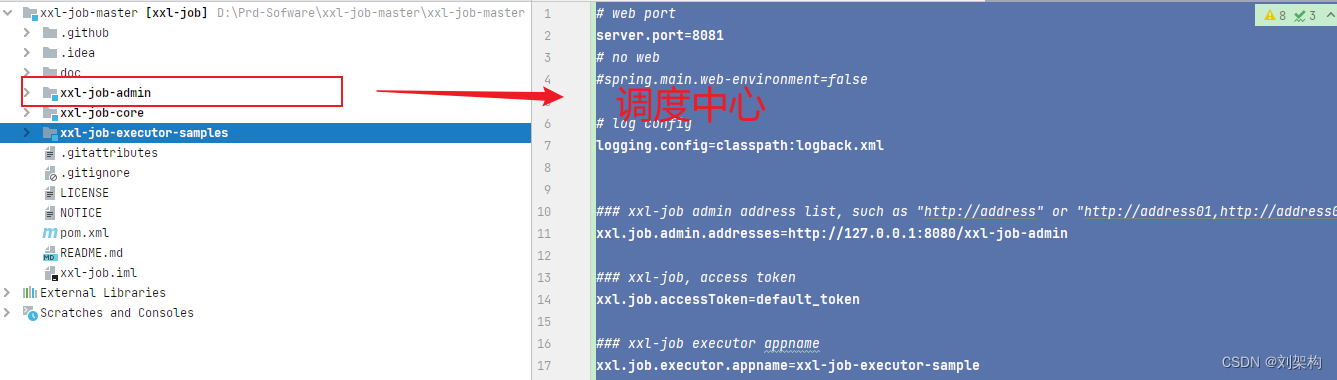
配置完成之后,我们需要 明白上面核心的配置,yaml文件其实 配置的就是我们 之前看到的那个图形化界面 的地址

因为我们这个调度中心的地址是 8080 ,所以我们的新模块需要向 这里去进行注册 ,才能将任务发送到 调度中心上面去
4. 配置核心处理器Handler
@Component
public class MileageXxlJob {
private static Logger logger = LoggerFactory.getLogger(SampleXxlJob.class);
/**
* 1、简单任务示例(Bean模式)
*/
@XxlJob("mileageJobHandler")
public void mileageJobHandler() throws Exception {
XxlJobHelper.log("XXL-JOB, Hello World.");
for (int i = 0; i < 5; i++) {
XxlJobHelper.log("beat at:" + i);
System.out.println("ok");
TimeUnit.SECONDS.sleep(2);
}
// default success
}
}
5 . 图形化再次配置
加入我们新项目的端口地址 ,方便进行注册
-
执行器管理
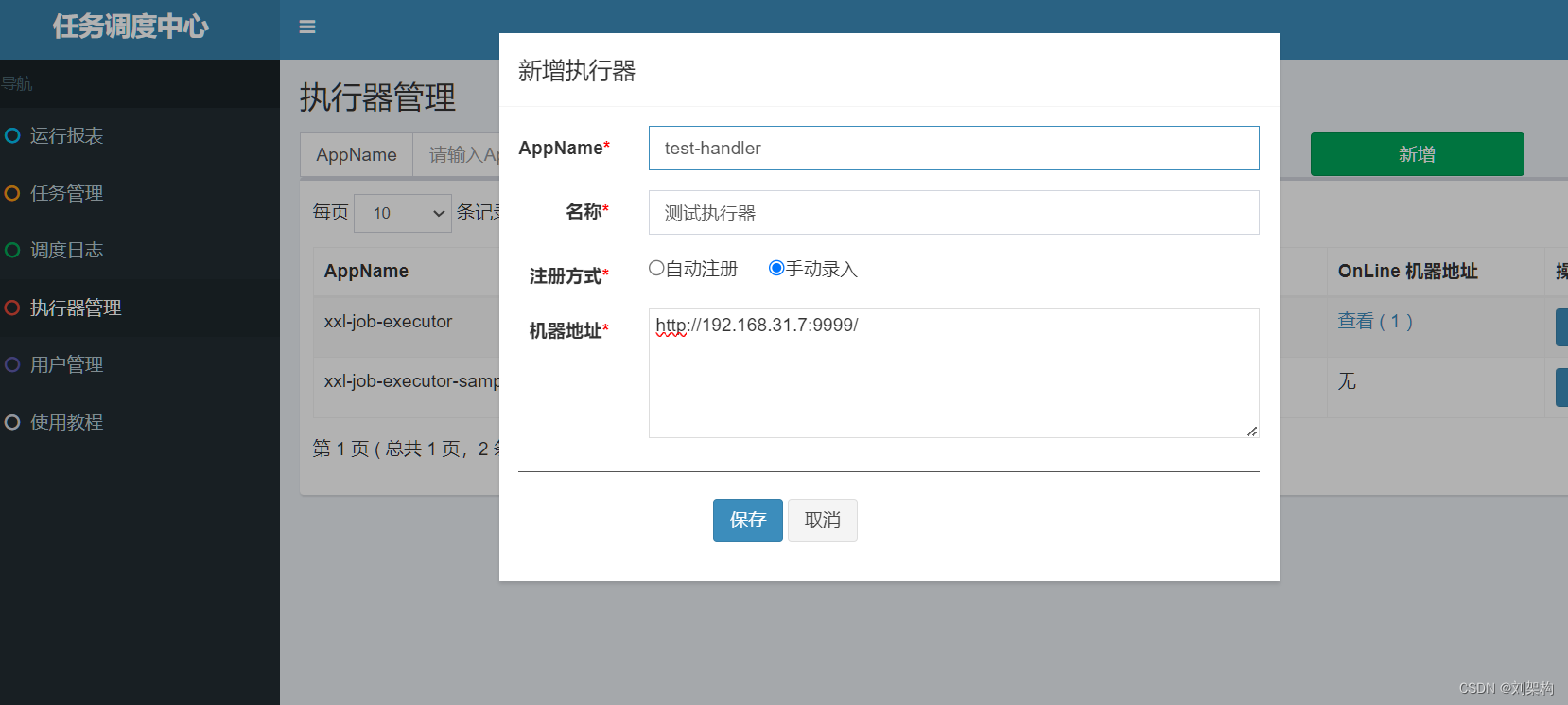
-
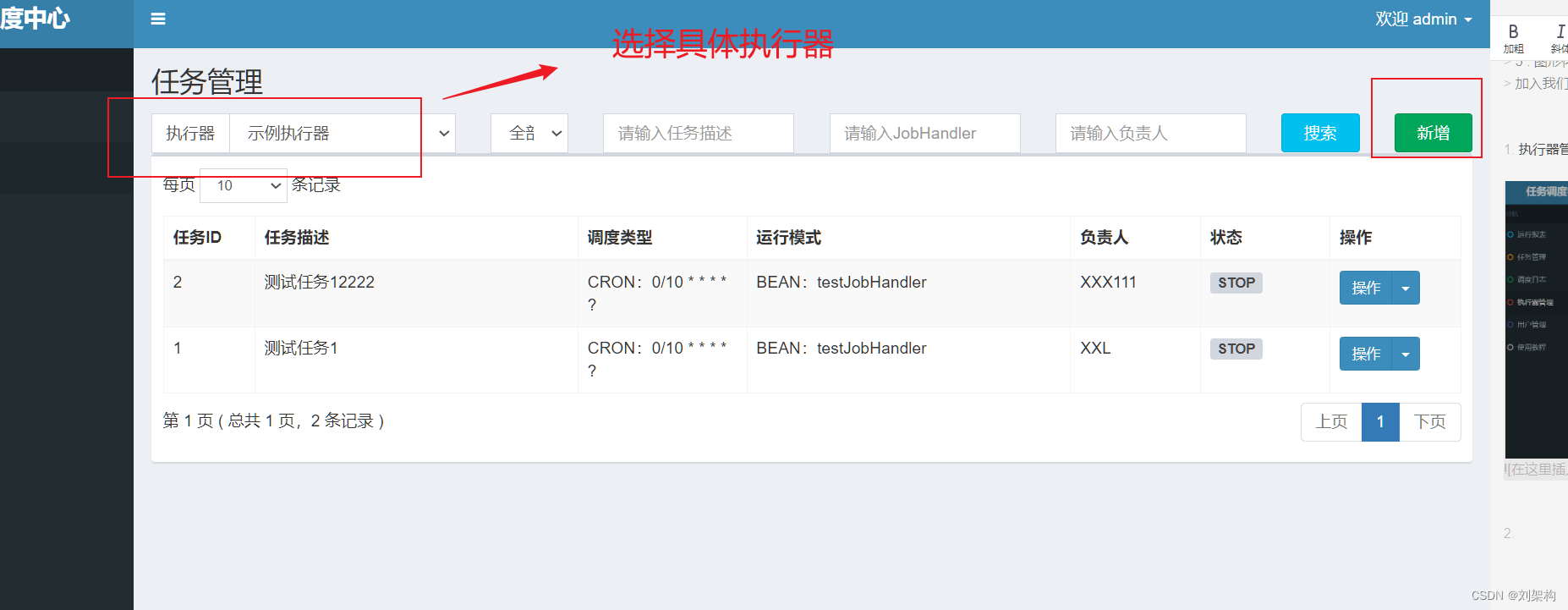
选择刚刚创建的执行器 ,然后创建任务,输入刚刚的执行器
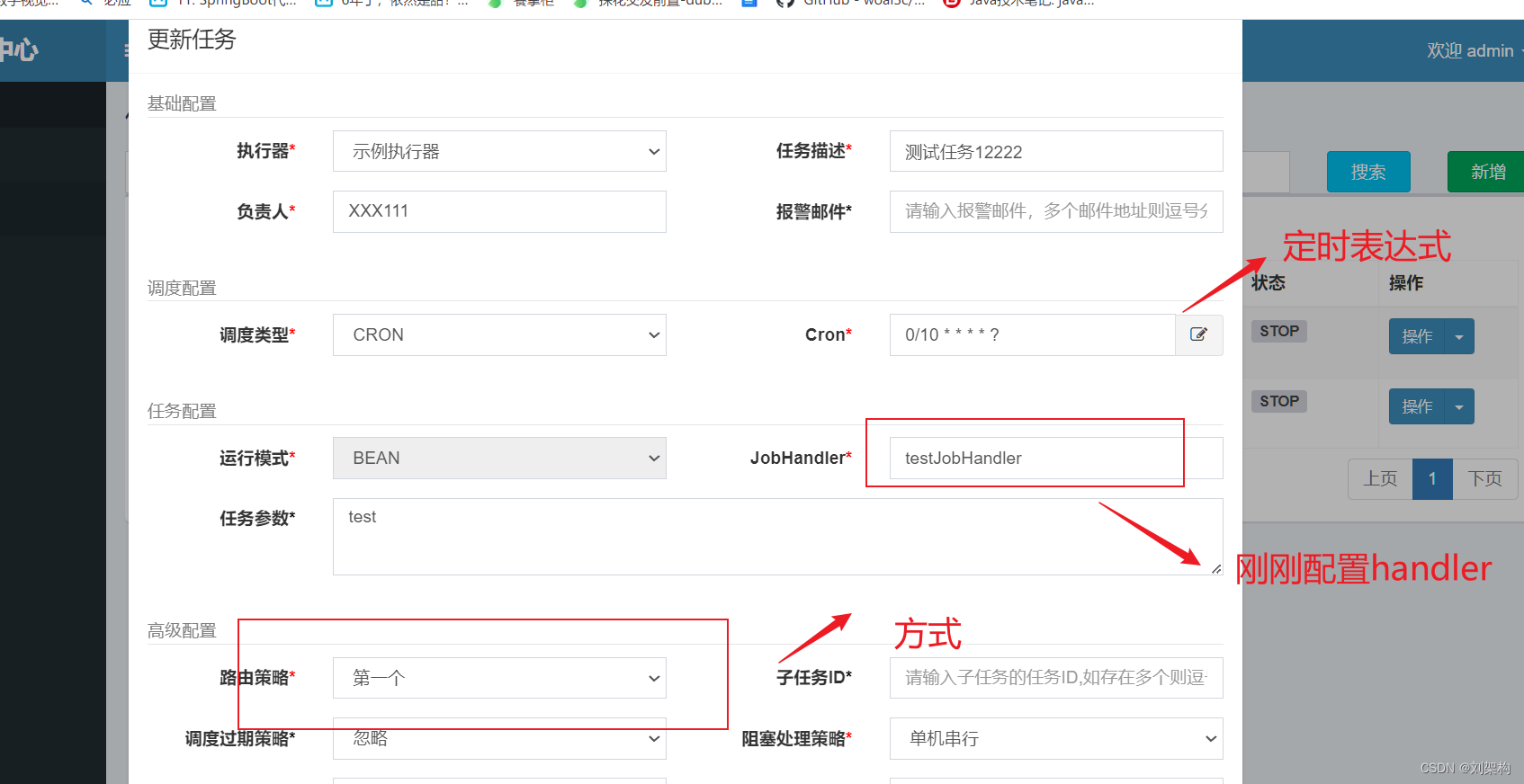
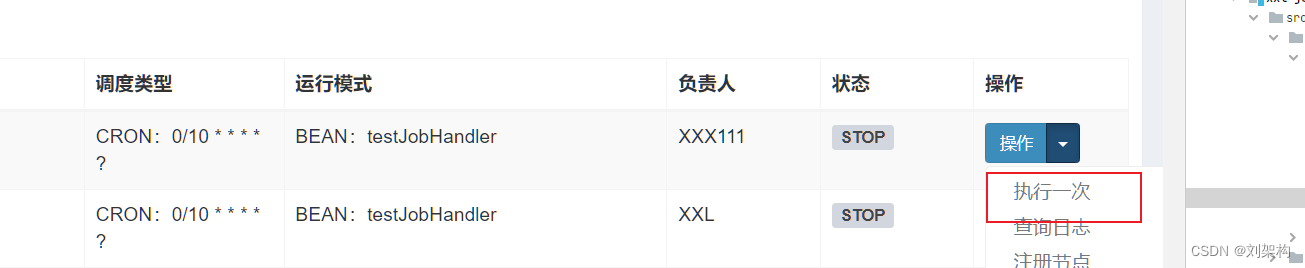
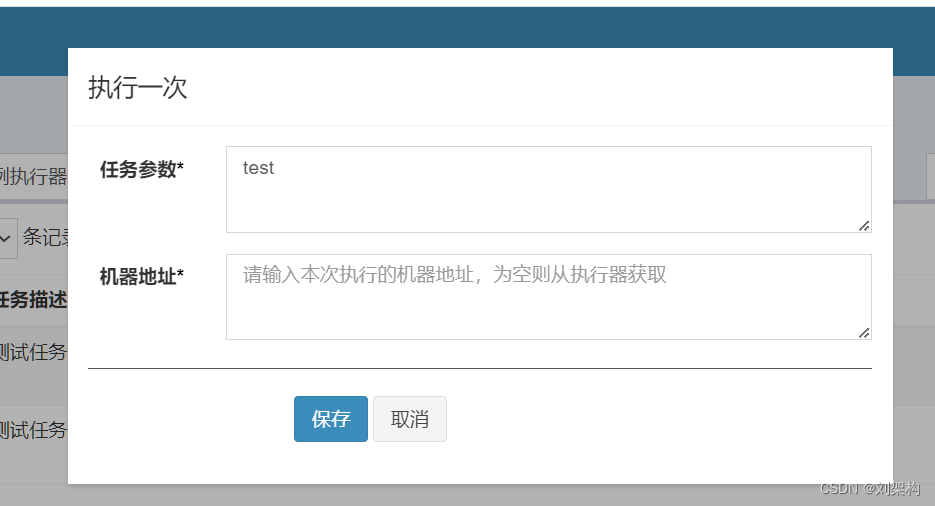
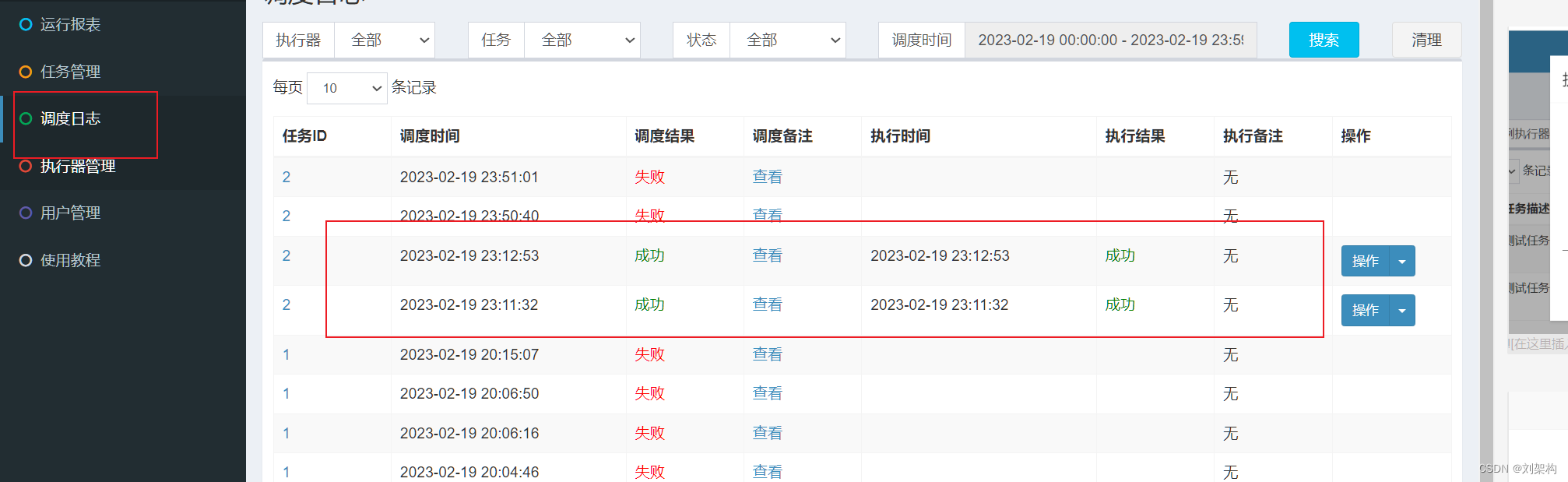
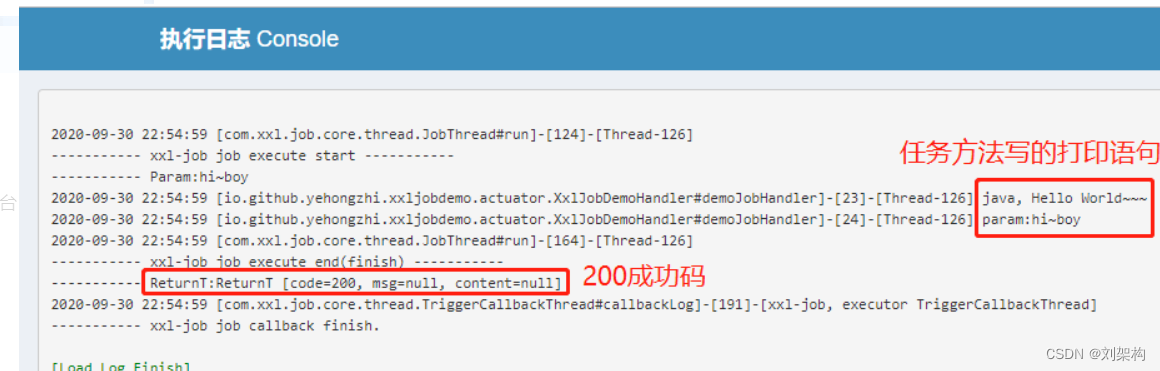
通过下面我们可以看到控制台输出的日志 ,也就是配置的
XxlJobHelper.log("java, Hello World~~~");
XxlJobHelper.log("param:" + param);

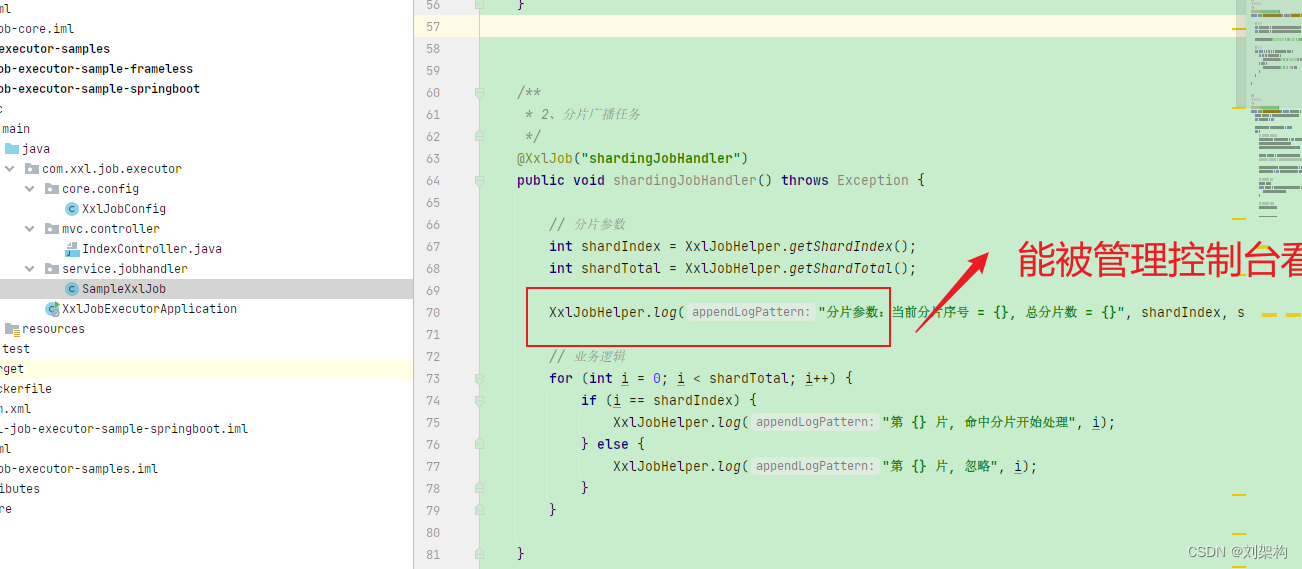
只有上面这种 专属的工具类,做了封装的才能被控制台看到