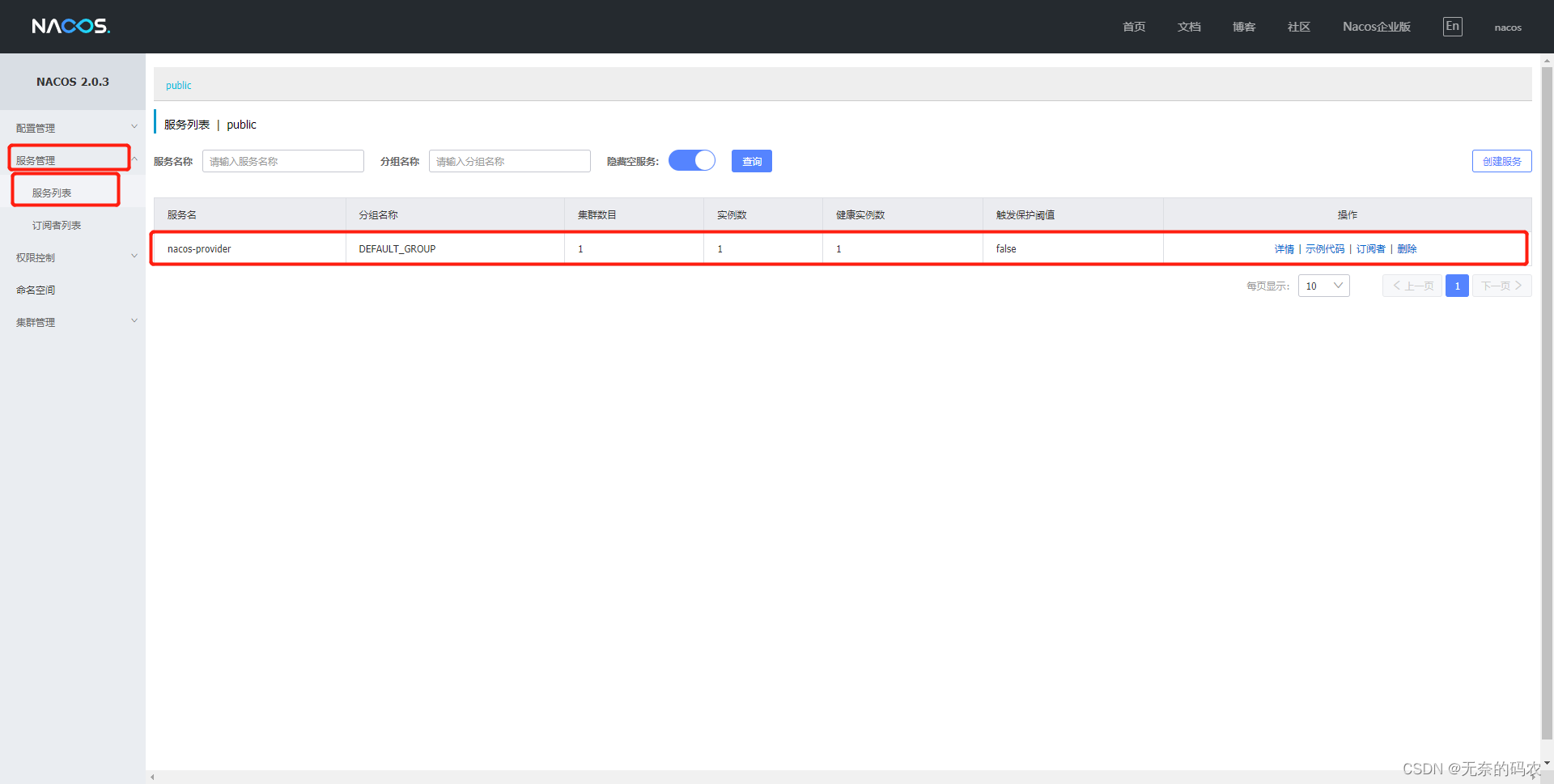
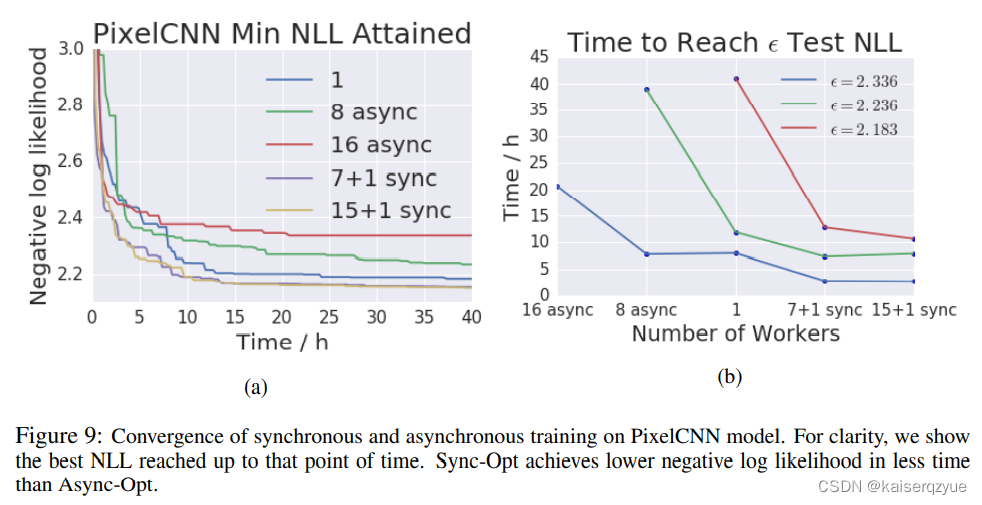
文章目录
- 1.xml
- 1.1概述【理解】(不用看)
- 1.2标签的规则【应用】
- 1.3语法规则【应用】
- 1.4xml解析【应用】
- 1.5DTD约束【理解】
- 1.5.1 引入DTD约束的三种方法
- 1.5.2 DTD语法(会阅读,然后根据约束来写)
- 1.6 schema约束【理解】
- 1.6.1 编写schema约束
- 1.6.2 引入schema约束
properties文件变量名指定定义一个,多个对象全路径名时不方便阅读
xml就方便许多了,对配置有自己的一套语法格式,很健全,很强大实用
1.xml
1.1概述【理解】(不用看)
-
万维网联盟(W3C)
万维网联盟(W3C)创建于1994年,又称W3C理事会。1994年10月在麻省理工学院计算机科学实验室成立。
建立者: Tim Berners-Lee (蒂姆·伯纳斯·李)。
是Web技术领域最具权威和影响力的国际中立性技术标准机构。
到目前为止,W3C已发布了200多项影响深远的Web技术标准及实施指南,-
如广为业界采用的超文本标记语言HTML(标准通用标记语言下的一个应用)、
-
可扩展标记语言XML(标准通用标记语言下的一个子集)
-
以及帮助残障人士有效获得Web信息的无障碍指南(WCAG)等
-

-
xml概述
XML的全称为(EXtensible Markup Language),是一种可扩展的标记语言
标记语言: 通过标签来描述数据的一门语言(标签有时我们也将其称之为元素)
可扩展:标签的名字是可以自定义的,XML文件是由很多标签组成的,而标签名是可以自定义的 -
作用
- 用于进行存储数据和传输数据
- 作为软件的配置文件
-
作为配置文件的优势
- 可读性好
- 可维护性高
1.2标签的规则【应用】
-
标签由一对尖括号和合法标识符组成
<student> -
标签必须成对出现
<student> </student> 前边的是开始标签,后边的是结束标签 -
特殊的标签可以不成对,但是必须有结束标记
<address/> -
标签中可以定义属性,属性和标签名空格隔开,属性值必须用引号引起来
<student id="1"> </student> -
标签需要正确的嵌套
这是正确的: <student id="1"> <name>张三</name> </student> 这是错误的: <student id="1"><name>张三</student></name>
1.3语法规则【应用】
-
语法规则
-
XML文件的后缀名为:xml
-
文档声明必须是第一行第一列
<?xml version=“1.0” encoding=“UTF-8” standalone=“yes”?>version:该属性是必须存在的 (值也固定1.0吧 不要写别的)
encoding:该属性不是必须的 打开当前xml文件的时候应该是使用什么字符编码表(一般取值都是UTF-8)
standalone: 该属性不是必须的,描述XML文件是否依赖其他的xml文件,取值为yes/no
-
必须存在一个根标签,有且只能有一个
-
XML文件中可以定义注释信息
-
XML文件中可以存在以下特殊字符
< < 小于 > > 大于 & & 和号 ' ' 单引号 " " 引号 -
XML文件中可以存在CDATA区
<![CDATA[ …内容… ]]>
-
-
示例代码
<?xml version="1.0" encoding="UTF-8" ?>
<!--文档声明必须第一行第一列 上面连空格 空行都不能有-->
<students> <!--根标签 有且只能有一个-->
<!--学生1 通过id区分是哪个学生-->
<student id="1">
<name>张三</name>
<age>23</age>
<info>张三信息[特殊字符:小于:< 大于:> 且:& 单引号:' 双引号:"]</info>
<message><![CDATA[直接用CDATA域: 这里的所有东西都当做简简单单的文本,不会被转义 < > & ' "]]></message>
</student>
<!--学生2 id=2-->
<student id="2">
<name>李四</name>
<age>24</age>
</student>
</students>
1.4xml解析【应用】
-
概述
xml解析就是从xml中获取到数据
-
常见的解析思想
DOM(Document Object Model)文档对象模型:就是把文档的各个组成部分看做成对应的对象。
会把xml文件全部加载到内存,在内存中形成一个树形结构,再获取对应的值![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oP971TUR-1676788762135)(.\img\02_dom解析概述.png)]](https://img-blog.csdnimg.cn/5b3a188b62da402999dcf9d0d94223d9.png)
-
常见的解析工具
- JAXP: SUN公司提供的一套XML的解析的API
- JDOM: 开源组织提供了一套XML的解析的API-jdom
- DOM4J: 开源组织提供了一套XML的解析的API-dom4j,全称:Dom For Java
- pull: 主要应用在Android手机端解析XML
-
解析的准备工作
-
我们可以通过网站:https://dom4j.github.io/ 去下载dom4j
今天的资料中已经提供,我们不用再单独下载了,直接使用即可
-
将提供好的dom4j-1.6.1.zip解压,找到里面的dom4j-1.6.1.jar
-
在idea中当前模块下新建一个libs文件夹,将jar包复制到文件夹中
-
选中jar包 -> 右键 -> 选择add as library即可
-
-
需求
- 解析提供好的xml文件
- 将解析到的数据封装到学生对象中
- 并将学生对象存储到ArrayList集合中
- 遍历集合
-
代码实现
注意,新建目录,复制好jar包之后得,右键导入一下才能使用
导入成功后就可以展开了
- student.xml
<?xml version="1.0" encoding="UTF-8" ?>
<students>
<!--学生1 通过id区分是哪个学生-->
<student id="1">
<name>张三</name>
<age>23</age>
</student>
<!--学生2 id=2-->
<student id="2">
<name>李四</name>
<age>24</age>
</student>
</students>
- Student.java
public class Student {
private String id;
private String name;
private int age;
//全参构造,无参构造,set/get, toString\
}
- XmlParse.java
/**
* 利用dom4j解析xml文件
*/
public class XmlParse {
public static void main(String[] args) throws Exception {
//1.获取Document对象
//1.1先得获取一个解析器对象(SAXReader)
SAXReader saxReader = new SAXReader();
//1.2利用解析器把xml文件加载到内存中,并返回一个文档对象(Document对象)
Document document = saxReader.read(new File("myxml/xml/student.xml"));
//2.逐步获取标签对象
//2.1 获取根标签
Element rootElement = document.getRootElement();
//2.2 通过根标签获取Student标签
//方法1:elements(),返回调用者所有子标签,放在一个List中
/*List list = rootElement.elements();
System.out.println(list.size());//3 不仅<student>,连<aaa>也都获取到了*/
//方法2:★ elements("标签名"),返回调用者所有指定名称子标签,放在一个List中
/*List list = rootElement.elements("student");
System.out.println(list.size());//2 只有所有<student>了*/
List<Element> studentElements = rootElement.elements("student");
//用来装学生对象
ArrayList<Student> list = new ArrayList<>();
//2.3 遍历集合得每一个student标签
for (Element studentElement : studentElements) {
// 2.4 继续读取每一个student子标签以及属性
//2.4.1 获取id属性,以及其值
Attribute attribute = studentElement.attribute("id");//获取id属性
String id = attribute.getValue();//获取id属性值
//2.4.2 获取各个子标签 以及其值(标签体内容)
//element("标签名"): 获取调用者指定子标签(单个)
Element nameElement = studentElement.element("name");//name标签
String name = nameElement.getText();//name标签体内容(需要的值)
Element ageElement = studentElement.element("age");
String age = ageElement.getText();
//3. 最后根据获取到的值 封装对象了
//System.out.println(id+" "+name+" "+age);
Student stu = new Student(id, name, Integer.parseInt(age));
list.add(stu);
}
System.out.println(list);
}
}

1.5DTD约束【理解】
-
什么是约束
用来限定xml文件中可使用的标签以及属性
-
约束的分类
- DTD
- schema
-
编写DTD约束
-
步骤
-
创建一个文件,这个文件的后缀名为.dtd
-
看xml文件中使用了哪些元素
<!ELEMENT> 可以定义元素 -
判断元素是简单元素还是复杂元素
简单元素:没有子元素。
复杂元素:有子元素的元素;
-
-
代码实现
-
- persondtd.dtd
<!ELEMENT persons (person)>
<!ELEMENT person (name,age)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
- person.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE persons SYSTEM 'persondtd.dtd'>
<!--persons根标签 SYSTEM表示引入本地约束-->
<!--引入之后再编写也有提示了-->
<persons>
<person>
<name>张三</name>
<age>18</age>
</person>
</persons>
1.5.1 引入DTD约束的三种方法
- 引入本地dtd
<!DOCTYPE 根元素名称 SYSTEM ‘DTD文件的路径'>
- 在xml文件内部引入
<!DOCTYPE 根元素名称 [ dtd文件内容 ]>
- 引入网络dtd
<!DOCTYPE 根元素的名称 PUBLIC "DTD文件名称" "DTD文档的URL">
-
代码实现
-
引入本地DTD约束
<!DOCTYPE 根元素名称 SYSTEM ‘DTD文件的路径'>persondtd.dtd
<!ELEMENT persons (person)> <!ELEMENT person (name,age)> <!ELEMENT name (#PCDATA)> <!ELEMENT age (#PCDATA)>person1.xml
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE persons SYSTEM 'persondtd.dtd'> <!--方法1:引入本地约束--> <persons> <person> <name>张三</name> <age>18</age> </person> </persons> -
在xml文件内部引入
<!DOCTYPE 根元素名称 [ dtd文件内容 ]>person2.xml
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE persons [ <!ELEMENT persons (person)> <!ELEMENT person (name,age)> <!ELEMENT name (#PCDATA)> <!ELEMENT age (#PCDATA)> ]> <!--方法2:xml文件内部引入约束--> <persons> <person> <name>张三</name> <age>18</age> </person> </persons> -
引入网络dtd
<!DOCTYPE 根元素的名称 PUBLIC "DTD文件名称" "DTD文档的URL">暂时了解 后面使用
-
1.5.2 DTD语法(会阅读,然后根据约束来写)
-
定义元素
定义一个元素的格式为:<!ELEMENT 元素名 元素类型>
简单元素: EMPTY: 表示标签体为空
ANY: 表示标签体可以为空也可以不为空
PCDATA: 表示该元素的内容部分为字符串
复杂元素:
直接写子元素名称. 多个子元素可以使用",“或者”|"隔开;
","表示定义子元素的顺序 ; “|”: 表示子元素只能出现任意一个
"?"零次或一次, "+"一次或多次, "*"零次或多次;如果不写则表示出现一次![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VLD3cCeg-1676796640554)(.\img\03_DTD语法定义元素.png)]](https://img-blog.csdnimg.cn/0ebbd736674c48d08adf10eb7fc9dddb.png)
不限制个数,就是只能写一次 -
定义属性
格式
定义一个属性的格式为:<!ATTLIST 元素名称 属性名称 属性的类型 属性的约束>
属性的类型:
CDATA类型:普通的字符串属性的约束:
// #REQUIRED: 必须的
// #IMPLIED: 属性不是必需的
// #FIXED value:属性值是固定的 -
代码实现
-
代码实现
<!ELEMENT persons (person+)> <!--person+ 1个或多个 person 只能写一个--> <!ELEMENT person (name,age)> <!ELEMENT name (#PCDATA)> <!ELEMENT age (#PCDATA)> <!ATTLIST person id CDATA #REQUIRED> <!ATTLIST name id CDATA #FIXED "p1"> <!-- 属性值定死为name了 --> <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE persons SYSTEM 'persondtd.dtd'> <persons> <person id="001"> <name>张三</name> <age>23</age> </person> <person id = "002"> <name>张三</name> <age>23</age> </person> </persons>
1.6 schema约束【理解】
-
schema和dtd的区别
- schema约束文件也是一个xml文件,符合xml的语法,这个文件的后缀名.xsd
- 一个xml中可以引用多个schema约束文件,多个schema使用名称空间区分(名称空间类似于java包名)
- dtd里面元素类型的取值比较单一常见的是PCDATA类型,但是在schema里面可以支持很多个数据类型
- schema 语法更加的复杂
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c1FtCyDj-1676797603638)(.\img\04_schema约束介绍.png)]](https://img-blog.csdnimg.cn/c9b88c943ce8453b8c03ed0c0ede4969.png)
1.6.1 编写schema约束
-
步骤
1,创建一个文件,这个文件的后缀名为.xsd。
2,定义文档声明
3,schema文件的根标签为:<schema>
4,在<schema>中定义属性:
xmlns=http://www.w3.org/2001/XMLSchema
5,在<schema>中定义属性 :
targetNamespace =唯一的url地址,指定当前这个schema文件的名称空间。
6,在<schema>中定义属性 :
elementFormDefault="qualified“,表示当前schema文件是一个质量良好的文件。
7,通过element定义元素
8,判断当前元素是简单元素还是复杂元素![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rmgpmrHZ-1676797603638)(.\img\05_schema约束编写.png)]](https://img-blog.csdnimg.cn/b892de4d7a4b4fd7a1f04e74bf6eb3b4.png)
-
代码实现
-
person.xsd
<?xml version="1.0" encoding="UTF-8" ?> <!--根标签有三个固定属性--> <schema xmlns="http://www.w3.org/2001/XMLSchema" targetNamespace="http://www.whu.cn/javase" elementFormDefault="qualified" > <!--定义persons复杂元素--> <element name="persons"> <complexType> <!--sequence表示子标签必须按顺序来--> <sequence> <!--定义person复杂元素--> <element name="person"> <complexType> <sequence> <!--定义name和age简单元素--> <element name="name" type="string"></element> <element name="age" type="string"></element> </sequence> </complexType> </element> </sequence> </complexType> </element> </schema>
-
1.6.2 引入schema约束
-
步骤
1,在根标签上定义属性xmlns=“http://www.w3.org/2001/XMLSchema-instance”
2,通过xmlns引入约束文件的名称空间
3,给某一个xmlns属性添加一个标识,用于区分不同的名称空间
格式为: xmlns:标识=“名称空间地址” ,标识可以是任意的,但是一般取值都是xsi
4,通过xsi:schemaLocation指定名称空间所对应的约束文件路径
格式为:xsi:schemaLocation = "名称空间url 文件路径“ -
代码实现





![[软件工程导论(第六版)]第6章 详细设计(复习笔记)](https://img-blog.csdnimg.cn/c31446d26dc446ea8956b7c8b910f6d1.png)