学习教材《统计学习方法(第二版)》李航
学习内容:第1章 统计学习及监督学习概论
第2章 感知机
感知机(perceptron)是二类分类的线性分类模型。其输入为实例的特征向量,输出为实例的类别,取+1和-1二值。感知机对应于输入控件(特征空间)中将实例划分为正负两类的分离超平面,属于判别模型(对应于生成模型)。感知机学习旨在求出将训练数据进行线性划分的分离超平面,为此,导入基于误分类的损失函数,利用梯度下降法对损失函数进行极小化,求得感知机模型。
2.1感知机模型
定义:假设输入空间(特征空间)是,输出空间是
。输入
表示实例的特征向量,对应于输入空间的点;输出
表示实例的类别。由输入空间到输出空间的如下函数:
称为感知机。其中,和
为感知机模型参数,
叫做权值或权值向量,
叫做偏置,
表示
和
的内积。sign是符号函数,即
感知机是一种线性分类模型,属于判别模型。感知机模型的假设空间是定义在特征空间中的所有线性分类模型(linear classification model)或线性分类器(linear classifier),即函数集合
几何解释:线性方程,对应于特征空间
中的一个超平面S,其中w是超平面的法向量,b是超平面的截距。这个超平面将空间划分为两个部分。位于两部分的点被分为正负两类。因此超平面S称为分离超平面(separating hyperplane)

以上图为例,假设线性方程为。
位于分离超平面S左侧的点(例如(0,0)点)是小于0的点,得到的分类结果是-1;
位于分离超平面S右侧的点(例如(2,2)点)是大于0的点,得到的分类结果是+1。
2.2感知机学习策略
2.2.1数据集的线性可分性
定义2.2(数据集的线性可分性)给定一个数据集
其中,,
,如果存在某个超平面S
能够将数据集的正实例点和负实例点完全正确的划分到超平面两侧,即对所有的实例i,有
;对所有
的实例i,有
,则称数据集T为线性可分数据集;否则,称数据集T线性不可分。
2.2.2感知机策略
感知机的学习目标就是求得一个能够将训练集正实例点和负实例点完全正确分开的分离超平面。为了找出这样的超平面,即确定感知机模型参数,需要确定一个学习策略,即定义(经验)损失函数并将损失函数最小化。
损失函数的一个自然选择时五分类点的总数。但这个函数不是w,b的连续可导函数,不以优化。所以选择误分类点到超平面的总距离。为此,首先写出输入输入空间中任一点
到超平面S的距离:
这里,是
的
范数。
其次,对于误分类的数据来说,
此处的理解为:
正确分类时:
当
时,则
,则结果>0;
当
时,则
,结果>0
以上为误分类的点,所以结果正好相反。
所以:
因此误分类点距离S的距离是
这样,假设超平面S的误分类点集合为M,那么所有误分类点到超平面S的总距离为
不考虑,就得到感知及学习的损失函数。
其中M为误分类点的集合。这个损失函数就是感知机学习的经验风险函数。
2.3感知机学习算法
感知机学习问题转化为求解损失函数(2.4)的最优问题。最优化的方法是随机梯度下降法。本届将原始形式和对偶形式,并证明在训练数据线性可分条件下感知机学习算法的收敛性。
2.3.1感知机学习算法的原始形式
给定一个数据集
其中,,
,求参数
,使其为一下损失函数极小化问题的截
其中M为误分类点的集合。
感知机学习算法是误分类驱动的,具体采用随机梯度下降法。具体步骤,首先任意选取一个超平面,然后用梯度下降法不断地极小化目标函数。极小化过程中不是一次使用M汇总的所有误分类点的梯度下降,而是随机选取一个误分类点使其梯度下降。
假设误分类点集合M是固定的,那么损失函数的梯度由
给出。
随机选取一个误分类点,对
进行更新:
式中是步长,在统计学习中又称为学习率。这样,通过迭代可以期待损失函数
不断缩小,直到为0。综上所述,得到如下算法:
算法2.1 感知机学习算法的原始形式
输入:训练数据集其中
,
,
;学习率
输出:;感知机模型
.
(1)选取初值;
(2)在训练集中选取数据;
(3)如果
(4)转至(2),直至训练集中没有误分类点。
例2.1 如图所示的训练数据集,正实例点是,负实例点是
,用感知机学习算法的原始形式求感知机模型
。这里
,
。
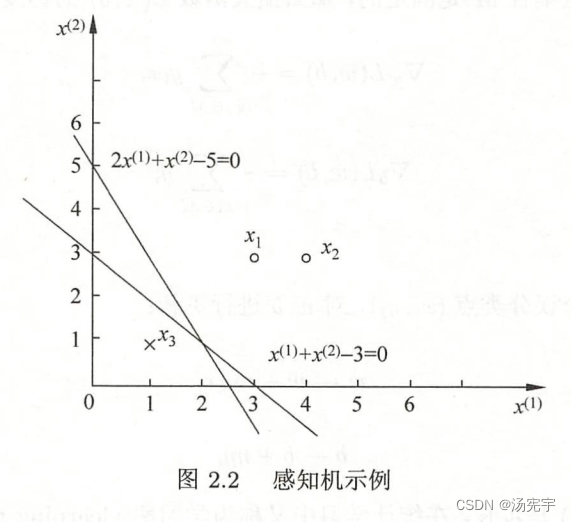
解 构建最优化问题:
按照算法2.1求解。取
。
(1)取初值
(2)对第一个点,
,未能呗正确分类,更新
得到线性模型
(3)对,显然
,被正确分类,不修改
;
由于
,
则
成立
同理
成立
但是对于,
,
,则
,被误分类,更新
。
得到线性模型:
如此继续下去
| 迭代次数 | 误分类点 | |||
| 0 | 0 | 0 | 0 | |
| 1 | ||||
| 2 | ||||
| 3 | ||||
| 4 | ||||
| 5 | ||||
| 6 | | |||
| 7 | | |||
| 8 | 0 |
直到,对所有的数据点
,没有误分类点,损失函数达到极小。
分离超平面为
感知机模型为:
2.3.2算法的收敛性
证明过程略
2.3.3感知机学习算法的对偶形式
输入:线性可分得数据集,其中
,
,
学习率
输出:, 感知机模型
,其中
(1)
(2)在训练集中选取数据(x_i,y_i);
(3)如果
(4)转至(2)直到没有误分类数据。
对偶形式中训练实例仅以内积的形式出现,为了方便可以预先将训练集中实例间的内积计算出来并以矩阵的形式存储,这个矩阵就是所谓的Gram矩阵。
例2.2 同例2.1正样本是负样本点是
,试用感知机学习算法对偶形式求感知机模型。
(1)取
(2)计算Gram矩阵
(3)误分条件
更新参数

附视频讲解网址:21. 第三章第5节—感知机学习算法的对偶形式_哔哩哔哩_bilibili
自己的理解过程:
第0步:初始化
第1步:从开始计算
符合条件。进行更新。
计算
不更新
第2步:计算
更新
此时
然后计算其判别公式都是大于0的,不更新
第三步: 计算的判别公式
此时
依次递推计算可以得到上图递推推过程。 #
课后习题
习题2.1
Minsky和Papert指出:感知机因为是线性模型,所以不能表示复杂的函数如异或(XOR)。验证感知机为什么不能表示异或。
解答:
解题思路:
1.列出异或函数的输入输出;
2.使用图例法证明异或问题是线性不可分的;
3.使用反证法证明感知机无法表示异或
解题步骤:
第1步,列出异或函数的输入和输出
| 0 | 0 | -1 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | -1 |
使用图立法证明异或问题是线性不可分的
mport matplotlib.pyplot as plt
import numpy as np
import pandas as pd
%matplotlib inline
# 使用Dataframe表示异或的输入与输出数据
x1 = [0, 0, 1, 1]
x2 = [0, 1, 0, 1]
y = [-1, 1, 1, -1]
x1 = np.array(x1)
x2 = np.array(x2)
y = np.array(y)
data = np.c_[x1, x2, y]
data = pd.DataFrame(data, index=None, columns=['x1', 'x2', 'y'])
data.head()
pos = data.loc[data['y']==1]
neg = data.loc[data['y']==-1]
# 绘制数据图
# 绘制坐标轴
plt.xlim(-0.5, 1.5)
plt.ylim(-0.5, 1.5)
plt.xticks([-0.5, 0, 1, 1.5])
plt.yticks([-0.5, 0, 1, 1.5])
# 添加坐标轴文字
plt.xlabel("x1")
plt.ylabel("x2")
# 绘制正、负样本点
plt.plot(pos['x1'], pos['x2'], "ro")
plt.plot(neg['x1'], neg['x2'], "bx")
# 添加图示
plt.legend(['Positive', 'Negative'])
plt.show()
from sklearn.linear_model import Perceptron
import numpy as np
# 构造异或问题的训练数据集
X_train = np.array([[1, 1], [1, 0], [0, 1], [0, 0]])
y = np.array([-1, 1, 1, -1])
# 使用sklearn的Perceptron类构建感知机模型
perceptron_model = Perceptron()
# 进行模型训练
perceptron_model.fit(X_train, y)
# 打印模型参数
print("感知机模型的参数:w=", perceptron_model.coef_[
0], "b=", perceptron_model.intercept_[0])习题2.2
模仿例题2.1,构建从训练数据集求解感知机模型的例子。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
%matplotlib tkimport numpy as np
from matplotlib import pyplot as plt
%matplotlib tk
class Perceptron:
def __init__(self, X, Y, lr=0.001, plot=True):
"""
初始化感知机
:param X: 特征向量
:param Y: 类别
:param lr: 学习率
:param plot: 是否绘制图形
"""
self.X = X
self.Y = Y
self.lr = lr
self.plot = plot
if plot:
self.__model_plot = self._ModelPlot(self.X, self.Y)
self.__model_plot.open_in()
def fit(self):
# (1)初始化weight, b
weight = np.zeros(self.X.shape[1])
b = 0
# 训练次数
train_counts = 0
# 分类错误标识
mistake_flag = True
while mistake_flag:
# 开始前,将mistake_flag设置为False,用于判断本次循环是否有分类错误
mistake_flag = False
# (2)从训练集中选取x,y
for index in range(self.X.shape[0]):
if self.plot:
self.__model_plot.plot(weight, b, train_counts)
# 损失函数
loss = self.Y[index] * (weight @ self.X[index] + b)
# (3)如果损失函数小于0,则该点是误分类点
if loss <= 0:
# 更新weight, b
weight += self.lr * self.Y[index] * self.X[index]
b += self.lr * self.Y[index]
# 训练次数加1
train_counts += 1
print("Epoch {}, weight = {}, b = {}, formula: {}".format(
train_counts, weight, b, self.__model_plot.formula(weight, b)))
# 本次循环有误分类点(即分类错误),置为True
mistake_flag = True
break
if self.plot:
self.__model_plot.close()
# (4)直至训练集中没有误分类点
return weight, b
class _ModelPlot:
def __init__(self, X, Y):
self.X = X
self.Y = Y
@staticmethod
def open_in():
# 打开交互模式,用于展示动态交互图
plt.ion()
@staticmethod
def close():
# 关闭交互模式,并显示最终的图形
plt.ioff()
plt.show()
def plot(self, weight, b, epoch):
plt.cla()
# x轴表示x1
plt.xlim(0, np.max(self.X.T[0]) + 1)
# y轴表示x2
plt.ylim(0, np.max(self.X.T[1]) + 1)
# 画出散点图,并添加图示
scatter = plt.scatter(self.X.T[0], self.X.T[1], c=self.Y)
plt.legend(*scatter.legend_elements())
if True in list(weight == 0):
plt.plot(0, 0)
else:
x1 = -b / weight[0]
x2 = -b / weight[1]
# 画出分离超平面
plt.plot([x1, 0], [0, x2])
# 绘制公式
text = self.formula(weight, b)
plt.text(0.3, x2 - 0.1, text)
plt.title('Epoch %d' % epoch)
plt.pause(0.01)
@staticmethod
def formula(weight, b):
text = 'x1 ' if weight[0] == 1 else '%d*x1 ' % weight[0]
text += '+ x2 ' if weight[1] == 1 else (
'+ %d*x2 ' % weight[1] if weight[1] > 0 else '- %d*x2 ' % -weight[1])
text += '= 0' if b == 0 else ('+ %d = 0' %
b if b > 0 else '- %d = 0' % -b)
return text
输入:
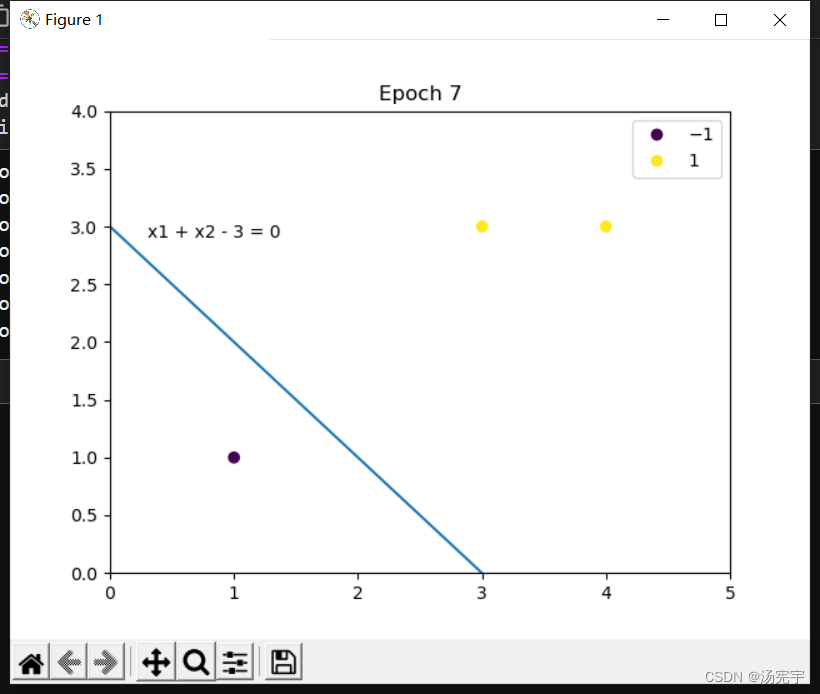
X = np.array([[3, 3], [4, 3], [1, 1]])
Y = np.array([1, 1, -1])
model = Perceptron(X, Y, lr=1)
weight, b = model.fit()得到结果
Epoch 1, weight = [3. 3.], b = 1, formula: 3*x1 + 3*x2 + 1 = 0
Epoch 2, weight = [2. 2.], b = 0, formula: 2*x1 + 2*x2 = 0
Epoch 3, weight = [1. 1.], b = -1, formula: x1 + x2 - 1 = 0
Epoch 4, weight = [0. 0.], b = -2, formula: 0*x1 - 0*x2 - 2 = 0
Epoch 5, weight = [3. 3.], b = -1, formula: 3*x1 + 3*x2 - 1 = 0
Epoch 6, weight = [2. 2.], b = -2, formula: 2*x1 + 2*x2 - 2 = 0
Epoch 7, weight = [1. 1.], b = -3, formula: x1 + x2 - 3 = 0