前言
首先很遗憾的告诉大家,今天这篇分享要关注才可以看了。原因是穷啊,现在基本都是要人民币玩家了,就比如chatGPT、copilot,这些AI虽然都是可以很好的辅助编码,但是都是要钱。入驻CSDN有些年头了,中间有几年大学毕业,失恋了没有写,沉沦了几年。后面逐渐捡起来,我们之间应该说是互相成就吧,亦师亦友亦笔记。说实话,其实CSDN之前有出一些插件,我很欣慰,也一直在用,其实我一直希望CSDN能出个copilot采用AI辅助就好了。或者国内几大技术论坛能一起搞个也行,其实大家都是有这方面的优势的,至少代码、训练库是足够的。
言归正传,今天要要分享的要是紧接之前的设计:物联网设备流水入库TDengine改造方案,这里是具体的实现过程。这个是TDengine可自动扩展列方案,这个方案实现代码绝对是目前独家,关注我,你值得拥有。
一、整体思路
整体思路:消费信息 》》 数据转换 》》组织sql 》》orm框架自动配备数据源》》执行入库TDengine》》异常处理(扩展的核心)》》DDL执行扩列》》再次执行入库。。。。
这里大家应该可以猜到具体做法了,其实要不是因为这个列不固定,实现起来可简单多了,也可以用超级表,而且性能也会好很多。更重要的是可以用ORM框架,基本不用写啥sql。而且查询结果用实体接受数据,不会出现VARCHAR字段不能正确显示字符串的问题(我就是被这个坑了下)。
其实也可以用flink等消费信息,做入库处理,当然这样处理可就不能用ORM框架了,只能用经典的JDBC。
核心思路:根据设备上报数据,做插入数据转换sql,执行入库处理异常,根据异常做DDL操作,实现自动扩列,最后入库。上报的数据:json串做数据转换,数据值做反射获取类型,转换为对应的扩列sql执行、组织入库sql。
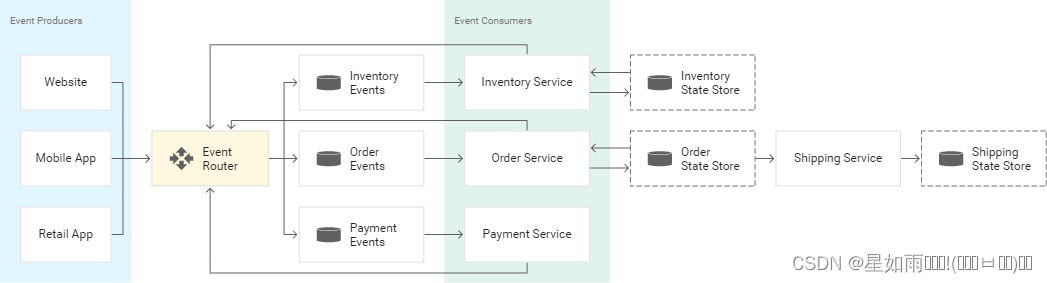
二、实现流程图
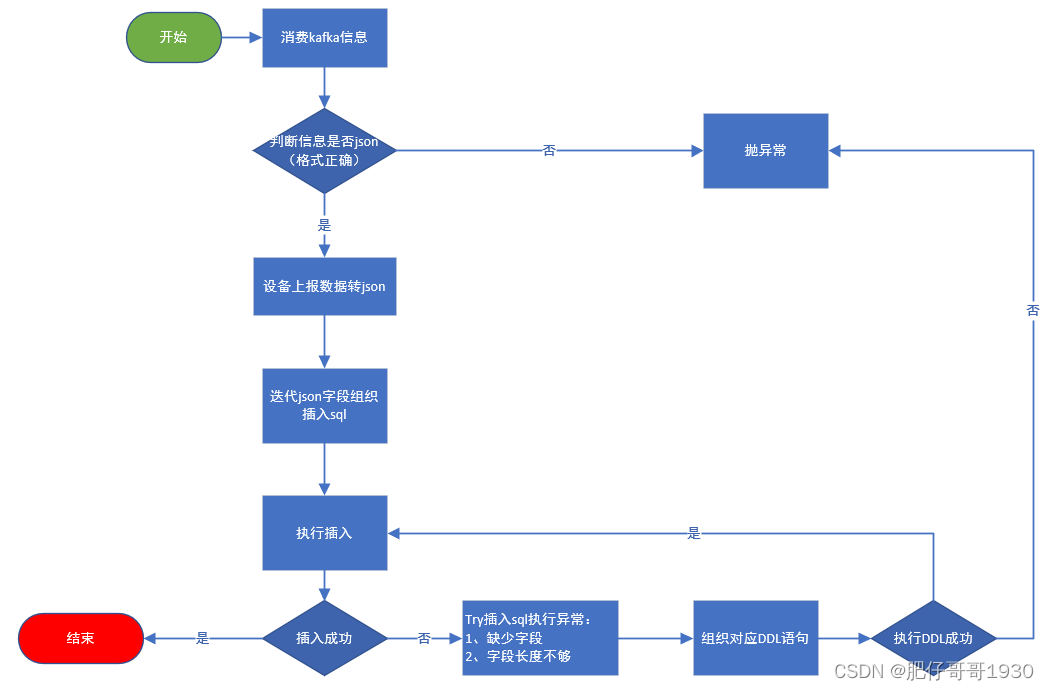
我的整体环境:SpringBoot3 + mybatisPlus + 双数据源(mysql、TDengine)+ 集成kafka
消费上游平台放入kafka的信息,然后走以上流程,目标执行入库TDengine。
三、核心代码
这里的整体框架我之前的博文有写,并且是公开独家分享到csdn的gitCode:https://gitcode.net/zwrlj527/data-trans.git
1.引入库
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
2.配置文件
spring:
#kafka配置
kafka:
#bootstrap-servers: 192.168.200.72:9092,192.168.200.73:9092
#bootstrap-servers: 192.168.200.83:9092,192.168.200.84:9092
bootstrap-servers: localhost:9092
client-id: dc-device-flow-analyze
consumer:
group-id: dc-device-flow-analyze-consumer-group
max-poll-records: 10
#Kafka中没有初始偏移或如果当前偏移在服务器上不再存在时,默认区最新 ,有三个选项 【latest, earliest, none】
auto-offset-reset: earliest
#是否开启自动提交
enable-auto-commit: false
#自动提交的时间间隔
auto-commit-interval: 1000
listener:
ack-mode: MANUAL_IMMEDIATE
concurrency: 1 #推荐设置为topic的分区数
type: BATCH #开启批量监听
#消费topic配置
xiaotian:
analyze:
device:
flow:
topic:
consumer: device-flow
3.kafka消费监听
package com.xiaotian.datagenius.kafka;
import com.xiaotian.datagenius.service.DataTransService;
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.stereotype.Component;
import java.util.List;
/**
* 消费者listener
*
* @author zhengwen
**/
@Slf4j
@Component
public class KafkaListenConsumer {
@Autowired
private DataTransService dataTransService;
/**
* 设备流水listenner
*
* @param records 消费信息
* @param ack Ack机制
*/
@KafkaListener(topics = "${easylinkin.analyze.device.flow.topic.consumer}")
public void deviceFlowListen(List<ConsumerRecord> records, Acknowledgment ack) {
log.debug("=====设备流水deviceFlowListen消费者接收信息====");
try {
for (ConsumerRecord record : records) {
log.debug("---开启线程解析设备流水数据:{}", record.toString());
dataTransService.deviceFlowTransSave(record);
}
} catch (Exception e) {
log.error("----设备流水数据消费者解析数据异常:{}", e.getMessage(), e);
} finally {
//手动提交偏移量
ack.acknowledge();
}
}
}
4.消息具体处理方法(实现)
package com.xiaotian.datagenius.service.impl;
import cn.hutool.core.collection.CollectionUtil;
import cn.hutool.json.JSONObject;
import cn.hutool.json.JSONUtil;
import com.xiaotian.datagenius.mapper.tdengine.DeviceFlowRecordMapper;
import com.xiaotian.datagenius.mapper.tdengine.TableOperateMapper;
import com.xiaotian.datagenius.service.DataTransService;
import com.xiaotian.datagenius.utils.TDengineDbUtil;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;
import java.util.*;
/**
* @author zhengwen
*/
@Slf4j
@Service
public class DataTransServiceImpl implements DataTransService {
/**
* 专门记录业务错误日志
*/
private final static Logger logger = LoggerFactory.getLogger("businessExp");
@Autowired
private KafkaTemplate kafkaTemplate;
@Autowired
private TableOperateMapper tableOperateMapper;
@Autowired
private DeviceFlowRecordMapper deviceFlowRecordMapper;
@Override
public void deviceFlowTransSave(ConsumerRecord record) {
log.debug("----设备流水转换解析存储----");
log.debug(String.format("offset = %d, key = %s, value = %s%n \n", record.offset(), record.key(), record.value()));
//字段不可控,所以没有实体可言,只能直接sql
//先直接执行插入,try异常 -> 如果是报字段不存在 -> 执行校验字段 -> dml创建字段
//再执行插入
String stableName = "device_flow_mater";
String tableName = "device_flow_record";
String recordStr = record.value().toString();
if (JSONUtil.isTypeJSON(recordStr)) {
JSONObject recordJson = JSONUtil.parseObj(recordStr);
//初始化语句
Map<String, Map<String, String>> columnData = new HashMap<>();
String insertSql = initDataInsertSql(recordJson, tableName, columnData);
//保存数据
saveRecord(recordJson, insertSql, columnData, tableName);
} else {
logger.error("---设备上报数据推送信息格式异常,无法解析---");
}
}
/**
* 初始化数据插入语句
*
* @param recordJson 记录json
* @param tableName 表名
* @param columnData 字段信息
* @return 数据插入语句
*/
private String initDataInsertSql(JSONObject recordJson, String tableName, Map<String, Map<String, String>> columnData) {
//这里先转换成sql的字段、value
StringJoiner columnSj = new StringJoiner(",");
StringJoiner valueSj = new StringJoiner(",");
String insertSql = transInitInsertSql(tableName, columnSj, valueSj, recordJson, columnData);
if (StringUtils.isBlank(insertSql)) {
logger.error("---上报数据转插入语句异常,上报数据:{}", JSONUtil.toJsonStr(recordJson));
return null;
}
return insertSql;
}
/**
* 保存记录
*
* @param recordJson 记录json对象
* @param insertSql 插入语句
* @param columnData 字段信息
* @param tableName 普通表或子表
*/
private void saveRecord(JSONObject recordJson, String insertSql, Map<String, Map<String, String>> columnData, String tableName) {
try {
//boolean insertRes = SqlRunner.db(DeviceFlowMaterRecord.class).insert(insertSql, '1');
int num = deviceFlowRecordMapper.insert(insertSql);
} catch (Exception e) {
logger.error("Error inserting,{}", e.getMessage());
Throwable throwable = e.getCause();
String msg = throwable.getMessage();
//报缺少字段、字段长度不够
if (msg.contains("Invalid column name:") || msg.contains("Value too long for column/tag")) {
transAddOrChangeColumnsSql(columnData, tableName, recordJson, insertSql);
}
}
}
/**
* 转换扩展列
*
* @param columnData 上报数据字段信息map
* @param tableName 表名
* @param recordJson 上报数据json
* @param insertSql 插入语句
*/
private void transAddOrChangeColumnsSql(Map<String, Map<String, String>> columnData, String tableName, JSONObject recordJson, String insertSql) {
String showColumnsSql = "desc " + tableName;
List<Map<String, Object>> columnLs = tableOperateMapper.operateSql(showColumnsSql);
if (CollectionUtil.isNotEmpty(columnLs)) {
//StringBuffer sbf = new StringBuffer();
//sbf.append("ALTER TABLE ").append(tableName).append(" ADD COLUMN ");
Map<String, Map<String, Object>> tableColumns = new HashMap<>();
columnLs.stream().forEach(c -> {
Object byBufferObj = c.get("field");
//获取字段
String field = TDengineDbUtil.getColumnInfoBy(byBufferObj);
tableColumns.put(field, c);
});
columnData.entrySet().forEach(c -> {
String key = c.getKey();
Map<String, String> columnMp = c.getValue();
String length = columnMp.get("length");
if (tableColumns.containsKey(key)) {
//包含字段,比较数据类型长度
Map<String, Object> tcMp = tableColumns.get(key);
Object byBufferObj = tcMp.get("length");
//获取字段长度
String dbLength = TDengineDbUtil.getColumnInfoBy(byBufferObj);
if (dbLength != null) {
if (Integer.parseInt(length) > Integer.parseInt(dbLength)) {
String changeColumnSql = TDengineDbUtil.getColumnChangeSql(tableName,length,key);
tableOperateMapper.operateSql(changeColumnSql);
}
}
} else {
//不包含需要执行增加字段
String addColumnSql = TDengineDbUtil.getColumnAddSql(tableName,length,key);
tableOperateMapper.operateSql(addColumnSql);
}
});
//复调存储
saveRecord(recordJson, insertSql, columnData, tableName);
}
}
/**
* 转换初始化插入语句sql
*
* @param tableName 表名
* @param columnSj 字段字符串
* @param valueSj 值字符串
* @param recordJson 上报数据json
* @param columnData 字段Map
* @return 插入语句sql
*/
private String transInitInsertSql(String tableName, StringJoiner columnSj, StringJoiner
valueSj, JSONObject recordJson, Map<String, Map<String, String>> columnData) {
StringBuffer sb = new StringBuffer();
//子表不能扩展列,所以超级表思路走不通
sb.append("insert into ").append(tableName);
if (!JSONUtil.isNull(recordJson)) {
JSONObject tmpRecordJson = recordJson;
JSONObject dataJson = tmpRecordJson.getJSONObject("data");
Date collectTime = tmpRecordJson.getDate("collectTime");
tmpRecordJson.remove("data");
tmpRecordJson.entrySet().forEach(entry -> {
//TODO 这里要设置调整下数据库区分大小写后去掉
//String key = entry.getKey().toLowerCase();
String key = entry.getKey();
columnSj.add("`" + key + "`");
Object val = entry.getValue();
//TODO 校验字符串类型处理sql
int length = 5;
if (val != null) {
//TODO 几个时间字段传的是long,是转时间类型,还是改字段为字符串?
String valStr = TDengineDbUtil.convertValByKey(val,key);
valueSj.add(valStr);
length = valStr.length() + 5;
} else {
valueSj.add(null).add(",");
}
//TODO 字段数据类型后面要优化处理
Map<String, String> columnMp = TDengineDbUtil.checkColumnType(key, val, length);
columnData.put(key, columnMp);
});
if (!JSONUtil.isNull(dataJson)) {
dataJson.entrySet().forEach(entry -> {
//TODO 这里要设置调整下数据库区分大小写后去掉
String key = entry.getKey();
columnSj.add("`" + key + "`");
Object val = entry.getValue();
int length = 3;
if (val != null) {
//TODO 几个时间字段传的是long,是转时间类型,还是改字段为字符串?
String valStr = TDengineDbUtil.convertValByKey(val,key);
valueSj.add(valStr);
length = valStr.length() + 1;
} else {
valueSj.add(null).add(",");
}
//TODO 字段数据类型后面要优化处理
Map<String, String> columnMp = TDengineDbUtil.checkColumnType(key, val, length);
columnData.put(key, columnMp);
});
}
//Tags
//sb.append(" TAGS (").append(dataJson).append(",").append(deviceUnitCode).append(",").append(deviceCode).append(") ");
//sb.append(" TAGS ('").append(JSONUtil.toJsonStr(dataJson)).append("') ");
//Columns
columnSj.add("`data_ts`");
sb.append("(").append(columnSj.toString()).append(") ");
//Values
//valueSj.add("'" + DateUtil.format(collectTime, DatePattern.NORM_DATETIME_MS_FORMAT) + "'");
//主键应该是时间,不能是设备上报数据的时间,因为设备上报数据万一相同就更新了
valueSj.add("NOW");
sb.append(" VALUES (").append(valueSj.toString()).append(")");
logger.debug("----插入语句sql:", sb.toString());
return sb.toString();
}
return null;
}
}
5.工具类
package com.xiaotian.datagenius.utils;
import cn.hutool.core.date.DatePattern;
import cn.hutool.core.date.DateUnit;
import cn.hutool.core.date.DateUtil;
import cn.hutool.core.date.LocalDateTimeUtil;
import io.micrometer.core.instrument.util.TimeUtils;
import lombok.extern.slf4j.Slf4j;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.time.Instant;
import java.time.LocalDateTime;
import java.time.OffsetDateTime;
import java.time.ZoneOffset;
import java.time.format.DateTimeFormatter;
import java.util.HashMap;
import java.util.Map;
/**
* TDengine数据库工具类
*
* @author zhengwen
*/
@Slf4j
public class TDengineDbUtil {
/**
* orm框架执行ddl语句返回的字段是byte数组处理
*
* @param byBufferObj byte数组object对象
* @return
*/
public static String getColumnInfoBy(Object byBufferObj) {
try {
if (byBufferObj instanceof byte[]) {
byte[] bytes = (byte[]) byBufferObj;
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.write(bytes);
oos.flush();
String strRead = new String(bytes);
oos.close();
bos.close();
return strRead;
}
} catch (IOException e) {
log.error("----字段异常:{}", e.getMessage());
}
return null;
}
/**
* 校验字段类型返回字段信息
*
* @param key 字段
* @param val 值
* @param length 长度
* @return 字段信息
*/
public static Map<String, String> checkColumnType(String key, Object val, int length) {
Map<String, String> columnMp = new HashMap<>();
columnMp.put("type", "String");
columnMp.put("length", String.valueOf(length));
return columnMp;
}
/**
* @param tableName
* @param length
* @param key
* @return
*/
public static String getColumnAddSql(String tableName, String length, String key) {
String beforeSql = "ALTER TABLE " + tableName + " ADD COLUMN ";
//TODO 处理字段类型
String addColumnSql = beforeSql + "`" + key + "` NCHAR(" + Integer.parseInt(length) + ")";
return addColumnSql;
}
/**
* @param tableName
* @param length
* @param key
* @return
*/
public static String getColumnChangeSql(String tableName, String length, String key) {
String changeLengthSql = "ALTER TABLE " + tableName + " MODIFY COLUMN ";
//TODO 处理字段类型
String changeColumnSql = changeLengthSql + "`" + key + "` NCHAR(" + length + ")";
return changeColumnSql;
}
/**
* 根据字段、字段值对插入sql的字段值做处理
*
* @param val 字段原始值
* @param key 字段
* @return 字段转换后的值
*/
public static String convertValByKey(Object val, String key) {
//其他全部当字符串处理
String valStr = "'" + val.toString() + "'";
//TODO 根据字段处理转换后的字段值,这里暂时对几个时间字段做特殊处理
if (key.equals("collectTime") || key.equals("createTime") || key.equals("storageTime")) {
if (val instanceof Long){
LocalDateTime localDateTime = LocalDateTimeUtil.of(Long.parseLong(val.toString()));
valStr = "'" + DateUtil.format(localDateTime,DatePattern.NORM_DATETIME_MS_PATTERN) + "'";
}
if (val instanceof Integer){
LocalDateTime localDateTime = LocalDateTimeUtil.of(Long.parseLong(val.toString() + 100));
valStr = "'" + DateUtil.format(localDateTime,DatePattern.NORM_DATETIME_MS_PATTERN) + "'";
}
}
return valStr;
}
}
6.Mapper的重要方法
TableOperateMapper
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xiaotian.datagenius.mapper.tdengine.TableOperateMapper">
<select id="operateSql" resultType="java.util.Map">
${sql}
</select>
</mapper>
DeviceFlowRecordMapper
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.xiaotian.datagenius.mapper.tdengine.DeviceFlowRecordMapper">
<!-- 通用查询映射结果 -->
<resultMap id="BaseResultMap" type="com.xiaotian.datagenius.entity.DeviceFlowRecord">
<id column="data_ts" property="dataTs" />
<result column="deviceUnitCode" property="deviceUnitCode" />
<result column="deviceUnitName" property="deviceUnitName" />
<result column="deviceCode" property="deviceCode" />
<result column="deviceName" property="deviceName" />
<result column="deviceTypeName" property="deviceTypeName" />
<result column="collectTime" property="collectTime" />
<result column="createTime" property="createTime" />
<result column="storageTime" property="storageTime" />
<result column="projectId" property="projectId" />
<result column="companyId" property="companyId" />
<result column="data" property="data" />
<result column="showMessage" property="showMessage" />
</resultMap>
<insert id="insert">
${sql}
</insert>
<select id="selectPageMap" resultType="java.util.Map">
${sql}
</select>
<select id="selectPageBy" parameterType="com.easylinkin.datagenius.vo.DeviceFlowRecordVo" resultType="java.util.Map">
select r.*
from device_flow_record r
where 1 = 1
<if test="param2 != null">
<if test="param2.deviceCode != null and param2.deviceCode != ''">
and r.`deviceCode` = #{param2.deviceCode}
</if>
<if test="param2.startTime != null">
<![CDATA[ and r.`collectTime` >= #{param2.startTime} ]]>
</if>
<if test="param2.endTime != null">
<![CDATA[ and r.`collectTime` <= #{param2.endTime} ]]>
</if>
</if>
order by r.`data_ts` desc
</select>
</mapper>
核心点就以上这些位置了,大家自行体会。
总结
- TDengine还不错,官方有交流群,群里也有技术支持,不过肯定不是每一个问题都有回复
- 各方面都在支持它,它的优化空间还很多,我们用开源实际也是在帮忙测试。就从开年到现在我就整这玩意,刚开始是3.0.2.3现在都迭代到3.0.2.5了
- ORM框架也在逐步支持,但是官方支持明确跟我说了可能ORM框架会拖慢,影响性能。
- 里面坑还是很多的,我就踩了乱码、返回字节码的问题
就写到这里,希望能帮到大家!!有需要帮助的可以在CSDN发消息我。