本文介绍用于3D模型合成的transformer网络与深度卷积网络。

推荐:使用 NSDT场景设计器 快速搭建 3D场景。
1、概述
从单一视角合成 3D 数据是一种基本的人类视觉功能,这对计算机视觉算法来说极具挑战性,这是一个共识。 但在 3D 传感器(如 LiDAR、RGB-D 相机(RealSense、Kinect)和 3D 扫描仪)的可用性和可负担性提高之后,3D 采集技术的最新进展取得了巨大飞跃。
与广泛可用的 2D 数据不同,3D 数据具有丰富的比例和几何信息,从而为机器更好地理解环境提供了机会。 然而,与 2D 数据相比,3D 数据的可用性相对较低,而且采集成本较高。 因此,最近提出了许多深度学习方法,以在不依赖任何 3D 传感器的情况下从可用的 2D 数据中合成 3D 数据。 但在我们深入研究这些方法之前,我们应该了解处理 3D 数据的格式。

合成的三维数据可以根据数据的最终用途用不同的格式表示。 一些常用的格式是:
- 深度图像
- 点云
- 体素
- 网格
深度图像包含场景的深度值,其形式为图像帧中每个像素与相机的距离(以米为单位)。 来自场景的深度信息对于自动驾驶汽车、增强现实、机器人技术等许多任务具有巨大价值。此类信息对于诸如在相机扫描静止场景和虚拟相机中的动画时启用运动视差等任务非常有用, 但是当强调 3D 建模场景中的特定对象时,这些信息在目前的技术水平下变得不充分和不准确。
深度图像:

点云是分布在 3D 空间中的三维点的集合。 这些 3D 点中的每一个都有一个由特定 (x, y, z) 坐标以及其他属性(如 RGB 颜色值)表示的确定性位置。 与深度图像不同,点云表示在没有任何离散化的情况下保留了更多高质量的三维空间几何信息。 然而,点云表示没有点与点之间的局部连接,从而导致自由度和高维性非常大,使得准确合成更加困难。
点云表示:

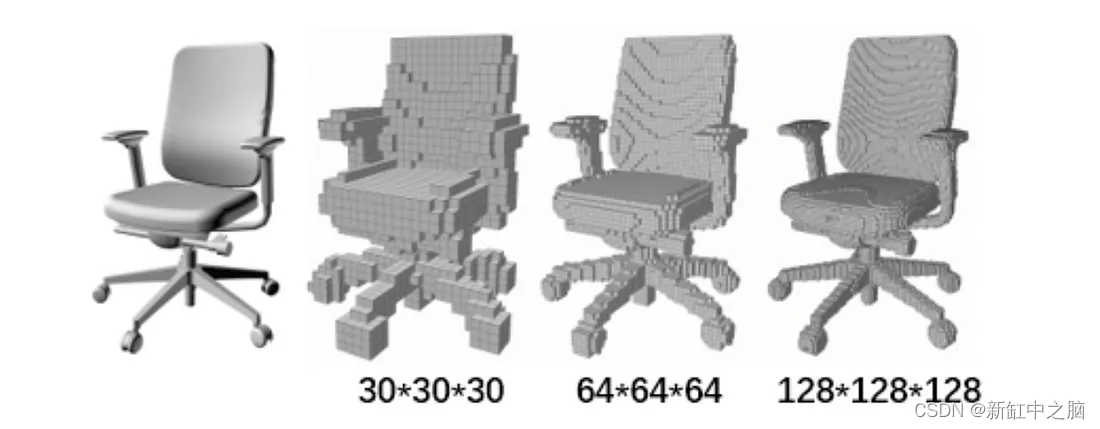
体素或体积像素是空间网格像素到体积网格体素的直接扩展。 简单来说,体素就是三维空间中的一个像素。 每个体素的相对位置共同定义了体积数据的独特结构。 体素可以看作是具有固定大小的量化点云。 然而,对于 3D 建模,体素表示过于稀疏并且在细节和计算资源之间表现出权衡,这使得它更不可行。
体素表示:
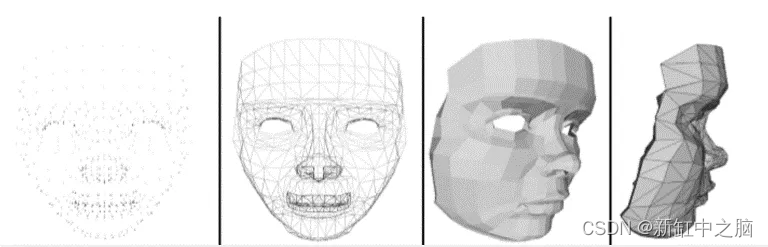
多边形网格是边、顶点和面的集合,它们共同定义了多面体对象的形状和体积。 网格的凸多边形面连接在一起以近似几何表面。 与体素类似,网格也可以看作是从一组连续曲面中采样得到的三维点云集(复杂度相对较低)。 网格面可以是三角形(triangle mesh)、四边形(quad mesh)或凸多边形(n-gon mesh)。 接近更真实的表示,网格也可以由带孔的多边形或凹多边形组成,具体取决于表示的普遍性。 然而,与丢失重要表面细节并且重建表面模型非常重要的体素和点云不同,网格对于许多实际应用来说更受欢迎。 因此,考虑到以上几点,与其他格式相比,多边形网格似乎更真实,合成效果更好。
多边形网格表示:
在这篇博客中,我们将讨论三种可用于从 2D 数据合成 3D 数据的方法。 在这三种方法中,一种方法基于基于Transformer的架构,而另外两种方法分别基于自编码器(AutoEncoder)和基于图的卷积神经网络(CNN)。 这两种方法的主要区别在于,基于 Transformer 的深度网络完全依赖于注意力机制来绘制输入和输出之间的全局依赖关系。
下面我们将首先讨论最近提出的两种使用自编码器和基于图的卷积神经网络来合成 3D 数据的方法。
2、基于自编码器的卷积神经网络
为了理解这种方法,我们将以使用自编码器网络进行 3D 人脸重建和人脸对齐为例。
人脸重建和对齐:

自编码器使用卷积网络将输入的 2D 图像降维到潜在空间,然后使用该潜在空间表示来重建原始 3D 数据格式。 许多研究已经使用自编码器(基于编码器-解码器的架构)来估计 3D 面部可变形模型系数和模型变形函数。 这些研究的目的主要是利用这些 3D 模型变形函数从单个 RGB 图像中恢复相应的 3D 形状,从而同时提供密集的 3D 人脸对齐和重建输出。
然而,此类方法的性能受到人脸模型模板定义的 3D 表示空间的限制。 同样,像体积回归网络 (VRN) 这样的方法使用全卷积层架构来估计 3D 二进制体积作为点云的离散版本。 然而,大多数输出点对应于浪费的非表面点,而且这种离散化限制了输出表示的分辨率。 因此,更好的研究应该是像位置图回归网络 (PRN) 这样的网络,它使用 UV 位置和纹理图共同预测密集对齐并重建 3D 面部形状。
UV位置和纹理贴图:
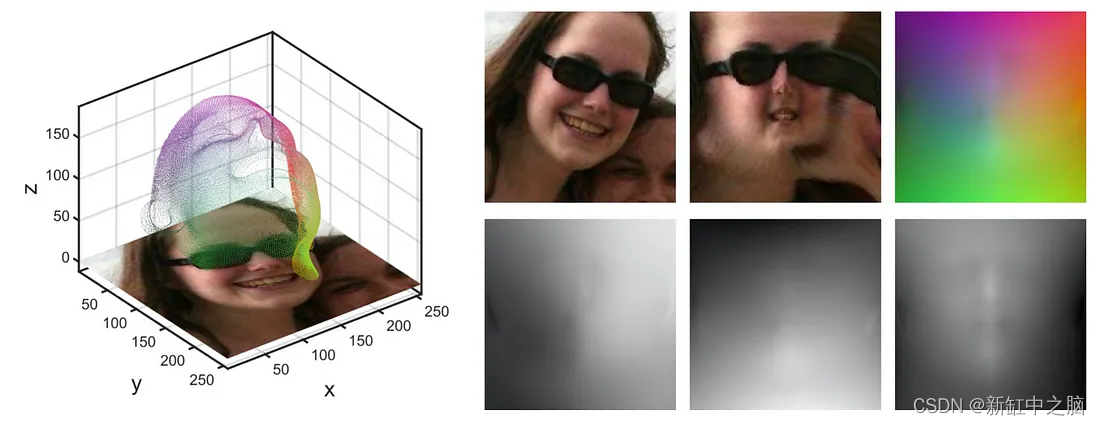
PRN 以 UV 位置图的形式构建 3D 面部结构的 2D 表示。 UV位置是记录面部点云的3D面部坐标的2D图像。 贴图还在表示中的每个位置附加了 3D 坐标的语义特征。 简单来说,UV 贴图是 3D 数据的 2D 表示,它记录了 UV 空间中所有点的 3D 坐标。
计算机图形学领域的研究人员经常使用 UV 空间和 UV 位置图将 3D 空间参数化为 2D 图像平面。 转到 PRN 的网络架构,网络使用简单的编码器-解码器结构(自编码器)获取输入 RGB 图像并将 2D 图像信息传输到 UV 位置图中。
自动码器使用 10 个下采样残差块和 17 个上采样转置卷积块来拟合此传递函数,最终预测 256×256×3 UV 位置图。 学习到的 UV 位置图有助于直接回归要合成的 3D 人脸的最终 3D 结构和语义特征。 对于像 PRN 这样的训练网络,我们只需要像 2D 图像到 3D 点云映射这样的数据集,这使得这种方法更有用,因为网络的输出格式不受特定 3D 模板或 3D 可变形模型线性空间的限制。
PRN架构:

因此,考虑到该方法的简单性和有效性,PRN 似乎是从 2D 图像合成 3D 数据以用于其网络输出格式的最佳选择之一。
3、基于图的卷积神经网络
如前一节所示,大多数基于自编码器的传统深度学习方法都利用点云和体素数据格式来合成 3D 数据。 特别强调这两种数据格式的主要原因是流行的基于网格的网络架构所施加的限制。 然而,点云和体素表示有其自身的缺点,如第一部分所述。
因此,为了避免体素或点云表示的缺点,许多研究已经转向合成 3D 多边形网格数据,从应用的角度来看,这是一种更理想的格式。 一些在合成网格数据方面非常有效的最佳架构设计方法包括基于图形的卷积神经网络。 在本节中,我们将以 Wang 等人提出的Pixel2Mesh方法为例。
使用Pixel2Mesh的实体重建:

Pixel2Mesh 是一个基于图形的端到端深度学习框架,它将单个 RGB 彩色图像作为输入,并将 2D 图像转换为更理想的相机坐标格式的 3D 网格模型。 基于图形的卷积神经网络提取并利用 2D 图像中的感知特征,通过逐渐变形椭圆体直到达到语义正确和优化的几何形状来生成 3D 网格。 采用的策略是一种由粗到精的方法,使椭球变形过程在几何上平滑稳定。 作者还定义了各种与网格相关的损失函数,以帮助网络捕获更多属性,从而保证物理和视觉上吸引人的 3D 几何结果。
图像特征网络和级联网格变形网络:
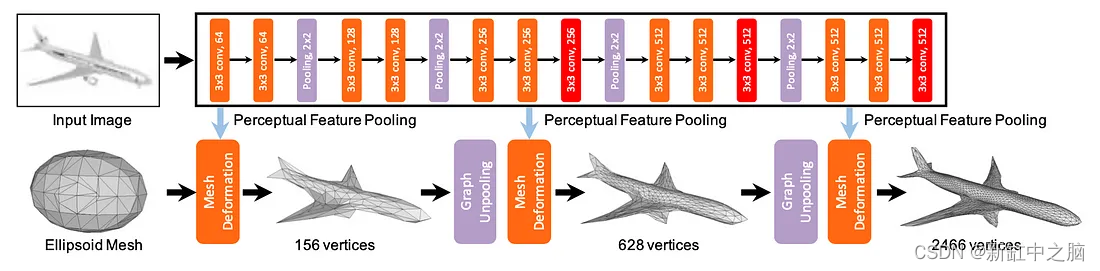
Pixel2Mesh 的架构主要由级联网格变形网络和图像特征网络组成。
图像特征网络负责从输入的 2D 图像中提取感知特征,并将这些特征逐步传递给基于图形的级联网格变形网络,以逐步将椭球网格的几何形状变形为目标对象的 3D 网格。
网格变形网络的图卷积网络包含三个变形块以及两个中间图解假脱机层。 变形块逐步处理网格模型的输入图,而中间图反池化层逐渐增加图形顶点以增加图形的信息存储容量,同时仍保持数据的三角形网格形成。
除了架构细节之外,Pixel2Mesh 基于图形的架构的主要优势之一是能够执行同步形状分析,这类似于传统的基于图表的方法,这些方法直接针对表面流形进行卷积运算。 这种方法通过合并网格对象的两种自然表示(图形和表面流形),充当基于图表的方法和 3D 重建方法之间的桥梁。
4、基于 Transformer 的深度架构
卷积神经网络被广泛用于计算机视觉任务,因为它们具有端到端的学习能力,可以直接从数据中执行任务,而无需任何手动设计的视觉特征。 然而,尽管 CNN 的架构设计对计算要求很高,但 3D 合成的任务使这种计算更加密集,并为计算优化和效率提升开辟了广阔的空间。
展望下一代神经架构,Transformers 是可扩展视觉模型的最佳家族,它们不仅与领域无关,而且计算高效且经过优化。 此外,最近的研究表明,Transformer在许多基于计算机视觉的任务上取得了最先进的结果。 为了理解 3D 数据合成中转换器的工作原理,我们将以 Deepmind 的 Polygen 为例。
Polygen生成的模型示例:
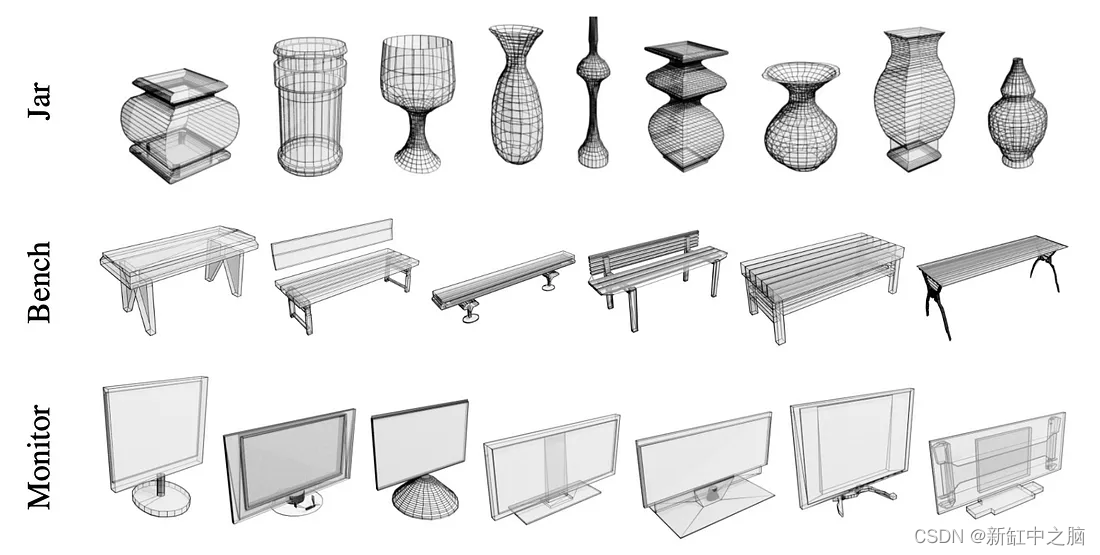
Polygen 是一种通过使用基于Transformer的架构按顺序预测网格面和顶点来直接建模 n 边形 3D 网格的方法。 模型设计使得它可以调节一系列输入(对象类、体素和 2D 图像)并以概率方式产生输出,以捕获模棱两可场景中的不确定性。
Polygen网络由顶点模型和人脸模型组成。 顶点模型是一个掩码Transformer解码器,它无条件地表达顶点序列上的分布以对网格顶点建模。 而人脸模型是一个基于pointer网络的Transfer,它有条件地表达可变长度输入顶点序列上的分布以对网格面进行建模。 因此,简单来说,这两个 transformer 模型的目标是通过首先生成网格顶点来估计 3D 网格上的分布,然后使用这些顶点生成网格面。
顶点网络和面网络:
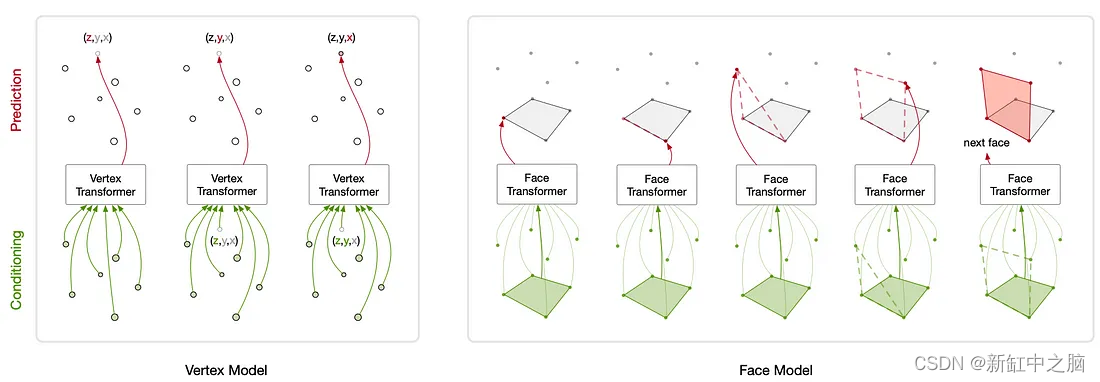
Polygen 中使用的Transformer架构的灵感来自 WaveNet、PixelRNN 和Pointer网络等顺序模型。 这项工作还从 Polygon-RNN(使用多边形分割)中获得了重要灵感,而顶点模型类似于 PointGrow 的定制自注意力架构,它使用自回归分解对 3D 点云进行建模。
与顺序自回归模型相比,PointGrow 具有更浅的自我注意架构,通过对固定长度的点云输入进行操作,使用自我注意机制来预测离散坐标分布。 因此,Polygen 可以被认为是通过新颖的基于Transformer的网络设计手段组合的一些最佳想法的均衡集合。
网格变形块及感知特征池化:
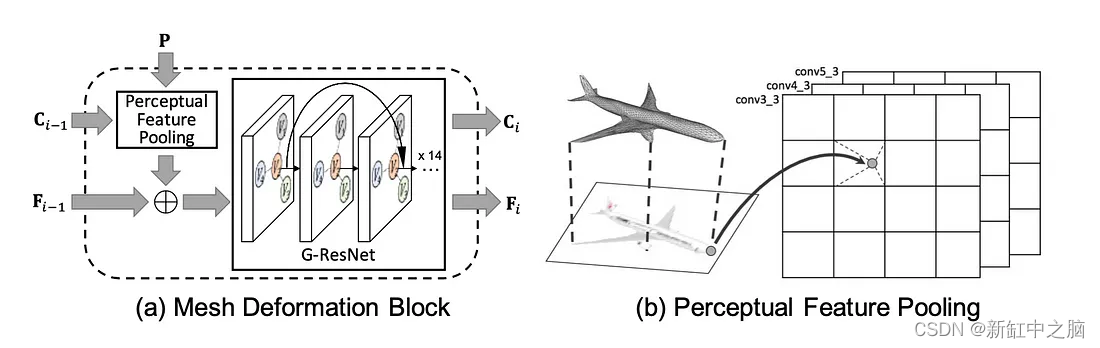
Polygen 的关键特性之一是能够根据输入上下文(上下文示例:2D 图像、对象类)调节输出。
为了实现这种条件性质,顶点和面部模型的输入流被改变以合并上下文。 对于 2D 图像和体素等输入格式,输入首先使用适合域的编码器进行编码,以检索 transformer 解码器的上下文嵌入,从而对嵌入序列执行交叉注意。
而对于像对象类这样的输入格式,预学习的类嵌入被投影到一个向量,该向量被添加到位于每个网络块中的自注意层之后的中间Transformer预测表示。 这是可能的,因为顶点模型的通用性质使用简单、表达能力强且建模能力强的Transformer-解码器架构,允许网络对来自不同领域的数据进行建模。 Transformer利用其高效信息聚合的能力来捕获网格顶点和对象几何中存在的强非局部依赖性。
5、结束语
在这篇博客中,我们讨论了两种主要类型的 3D 合成方法,即卷积深度网络和基于变换器的深度网络。 新一代网络的Transformer以计算效率更高和优化的方式设计,因此可以被认为比传统的卷积网络领先一步。
然而,在接近实时推理场景时,Transformer 要赶上我们在自动编码器部分讨论的相对轻量且推理速度快的方法,还有很长的路要走。 尽管如此,Transformer 的研究范围很广,而且它们的注意力机制能够有效地聚合信息并提取输入和输出之间的全局依赖关系,这使它们更有前途。

原文链接:3D合成深度神经网络 — BimAnt





![[Linux篇] Linux常见命令和权限](https://img-blog.csdnimg.cn/2caf27c59873404fbe70a89c7e5109f5.png#pic_center)