一、创建并进入容器
(平台使用教学详细,这部分略写)
登上服务器后,打开终端输入如下进入自己建的容器
ssh -p XXXXX root@10.XXX.XXX.XXX //按自己的宿主机端口写
二、安装Conda(miniconda3)
(平台使用教学详细,这部分略写)
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
chmod +x Miniconda3-latest-Linux-x86_64.sh
./Miniconda3-latest-Linux-x86_64.sh
进入和退出conda的base环境
三、安装Jupyter
(平台使用教学详细,这部分略写)
jupyter notebook --no-browser --port=80 --ip=0.0.0.0 --allow-root
在browser中直接输入容器端口(这里是80)对应的宿主机端口,enter即可打开Jupyter。
之前在本地配置的时候参考的是这个博客(https://blog.csdn.net/qq_42971035/article/details/118547151)写得很好,实践挺成功,但没有使用教学给的这个流程简洁。
四、安装CUDA
输入以下命令查看服务器的gpu情况,确定对应的CUDA版本
nvidia-smi
结果如下,驱动是450,CUDA是11.0
(一定要看清楚不要搞错啦,我第一次配环境的时候下的是12.1,发现错了后,试了网上的各种博客都删不掉,万念俱灰BUSHI,遂偷懒重新建了一个新的容器,嘿嘿)

(插个话题,曾有一次,输入这个命令后,报错了,报错信息为
Failed to initialize NVML: Driver/library version mismatch
找了各种解决方法,最后发现“关闭容器然后再打开”就好了,哈哈哈哈,就很玄学)
进入官网,找到CUDA Toolkit 11.0 Download
按照步骤走即可,这里没有踩雷,需要注意的是要有点耐心,一句一句复制,运行时间比较长。

下载完成后,添加路径
vi ~/.bashrc
(其实可以先到各个路径底下看看,看看nvcc在哪里,有利于理解这些代码的含义,万一与博客有出入,便于修改)
在最底端加上
export CUDA_HOME=/usr/local/cuda-11.0
export LD_LIBRARY_PATH=${CUDA_HOME}/lib64
export PATH=${CUDA_HOME}/bin:${PATH}
更新
source ~/.bashrc
测试一下,会显示cuda的版本号
nvcc -V
五、安装cudnn
(暂时还没有装)
六、安装pytorch
在小火苗Pytorch官网上ctrl+f找到CUDA 11.0安装。
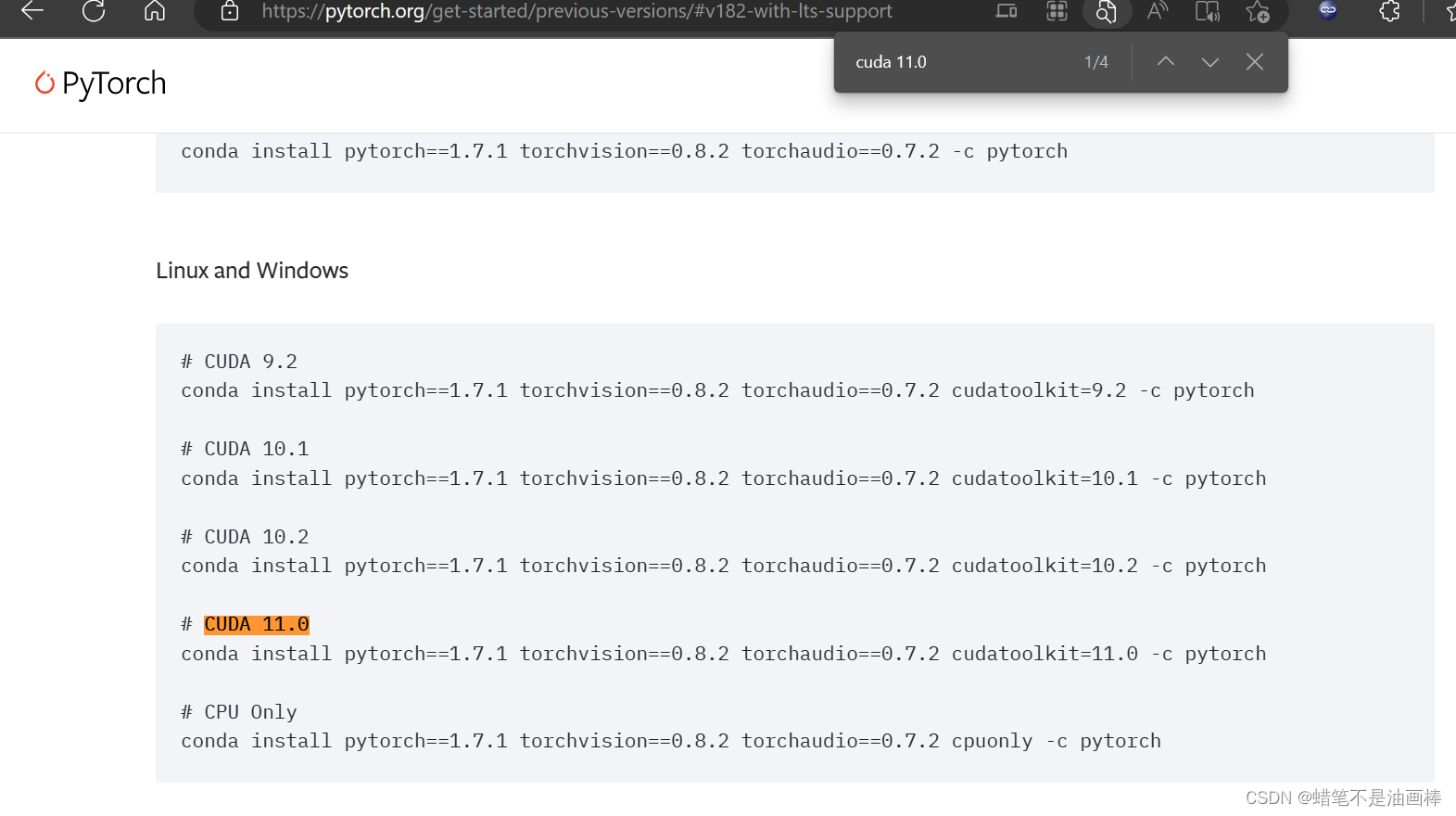
这里要检查自己python版本,第一次没有查看版本,直接用base中3.10的来运行,会产生版本不匹配的报错。我的解决方案是:不更改base里的配置,而是新建了一个虚拟环境
conda create --name python37 python=3.7
conda activate python37
在python37中打开python,测试是否安装成功(参考博客)
import torch # 如果pytorch安装成功即可导入
print(torch.cuda.is_available()) # 查看CUDA是否可用
print(torch.cuda.device_count()) # 查看可用的CUDA数量
print(torch.version.cuda) # 查看CUDA的版本号
七、废话箩筐
看着浏览器爆炸式增长的浏览记录,感觉一路上踩了好多坑,查了好多报错,遇到了好多复杂的看不懂的问题,感受到了莫大的痛苦。但真动手记录下来,就会发现这些报错和解决方案都是一些小tips,甚至写得时候会想,这真的值得一提吗。或许用“一览众山小”来形容有些夸张,但这个过程确实有点像费劲力气爬山再到登顶俯瞰大地的心路历程。由此引发了一些胡思乱想:是爬山本身就是辛苦的“历经风雨才能见彩虹”,还是要学会在爬任何山中发现乐趣,还是要选择一座风景秀丽充满趣味的山去爬。






![[ vulhub漏洞复现篇 ] Drupal Core 8 PECL YAML 反序列化任意代码执行漏洞(CVE-2017-6920)](https://img-blog.csdnimg.cn/9ed73a4d731c4c679cc7c5530e9620d4.png)