背景
深翻页,可以用id做为偏移量,但如果是uuid时,或需求是要按时间排序时,深翻页就是一个问题了。
如果要按最后修改时间倒排序,把时间做索引是可以,但有可能时间是有重的,这样结果就可能不准确
这时就要考虑 time+id 组合分页得到最后条记录了
优化前
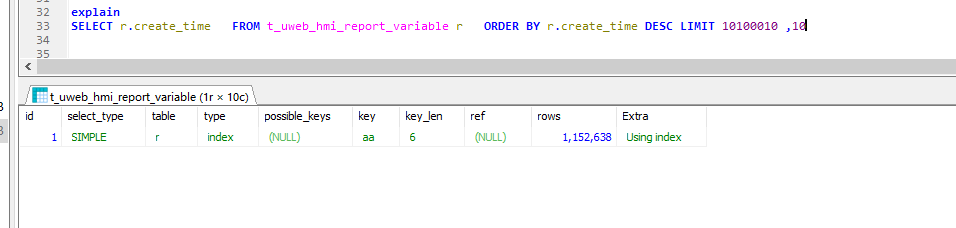
explain
SELECT * from t_report_variable r ORDER BY r.create_time desc,r.id desc LIMIT 1010010 ,10; #6.391 秒

优化后
explain
select * from t_uweb_hmi_report_variable r WHERE
r.id < ( select id from t_report_variable order by create_time desc , id desc limit 1010009,1 ) ORDER BY r.create_time desc, r.id desc limit 10; #3.031 秒 
注意
有一个很奇怪的现象
当给create_time建立索引时, 或给(create_time id)建立联合索引时,反而更慢了
SELECT * from t_report_variable r ORDER BY r.create_time desc,r.id desc LIMIT 1010010 ,10; #6.391 秒 给create_time加索引 7.093 秒 联合索引 6.594 秒
select * from t_report_variable r WHERE
r.id < ( select id from t_uweb_hmi_report_variable order by create_time desc , id desc limit 1010009,1 ) ORDER BY r.create_time desc, r.id desc limit 10; #3.031 秒 给create_time加索引 12.094 联合索引 12.672

不理解
后来发现,是翻页到后面,数据量大时,索引失效了。
从10多W起就失效了,为什么失效,没发现原因,是不是因为create_time同一时间的多,因为这一百多万数据create_time是按批报上来的,比如几十条一次,时间是一样。 但也说不清楚,又不是只有几个时间段,也有400多个不同时间; 可能是400多在100W面前,相当于时间没有几个吧。
主键id就不会有这问题
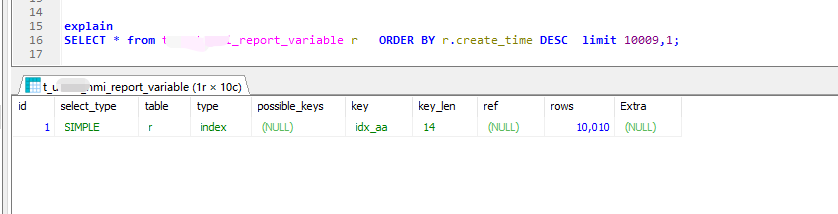
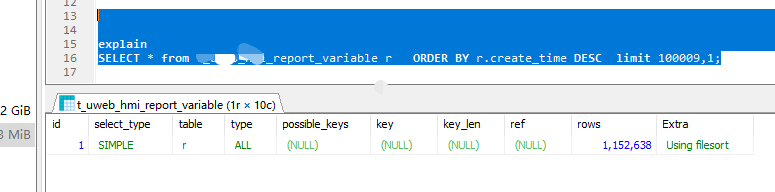
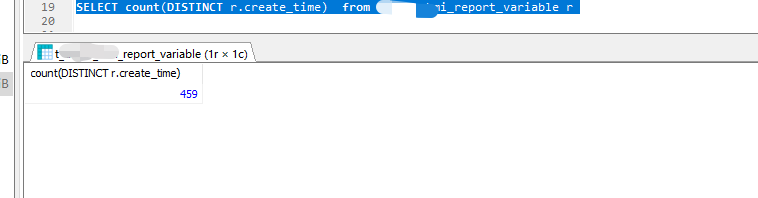

特意找了张几十万张的表,时间都不同的,效果也是一样。
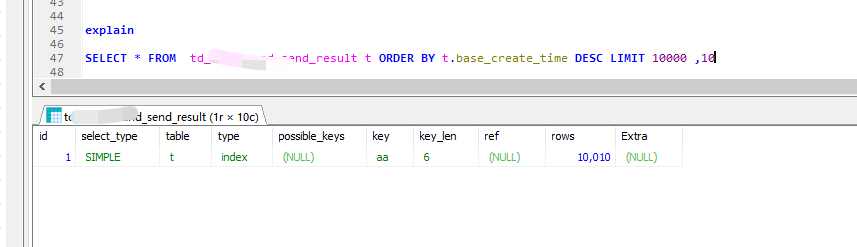
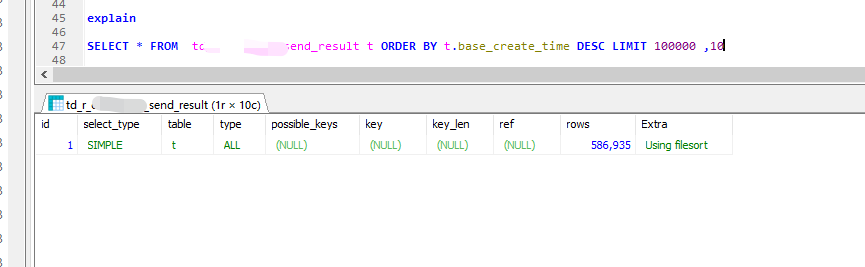
但如果,和其他字段组成联合索引就有效果
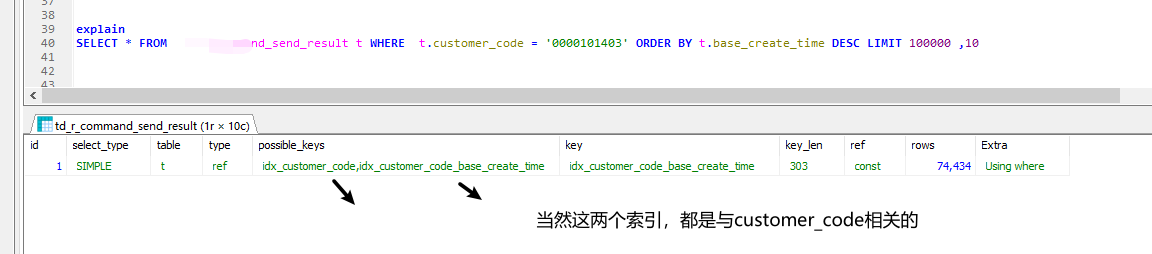
order by limit 造成优化器选择索引错误
如果要命中索引,查询结果就要和索引是同列了。
如果查询结果只有create_id 和id,是可以走索引的,如果有别的字段就不行
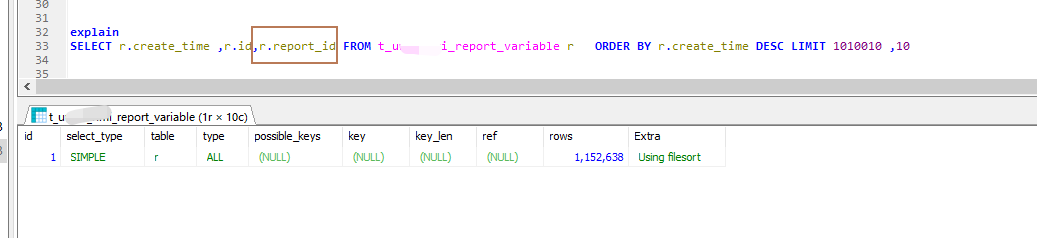
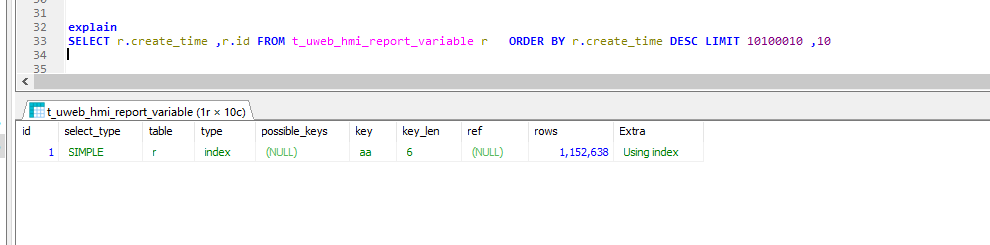
只有create_time也会走它的索引。