目录
1. BERT、GPT 核心思想
1.1 word2vec和ELMo区别
2 GPT编辑
3. Bert
3.1 Bert集大成者
extension:单向编码--双向编码区别
3.2 Bert和GPT、EMLo区别
3.3 Bert Architecture
3.3.1 explanation:是否参数多、数据量大,是否过拟合?
3.3.2 Bert training
3.4 Bert为什么要做掩码语言模型(MLM, Masked Language Model)
3.5 Bert 下句预测(NSP)
3.6 Bert下游任务改造
3.6.1 句对分类
3.6.2 单句分类
3.6.3 文本问答
3.6.4 单句标注
参考:
1. BERT、GPT 核心思想
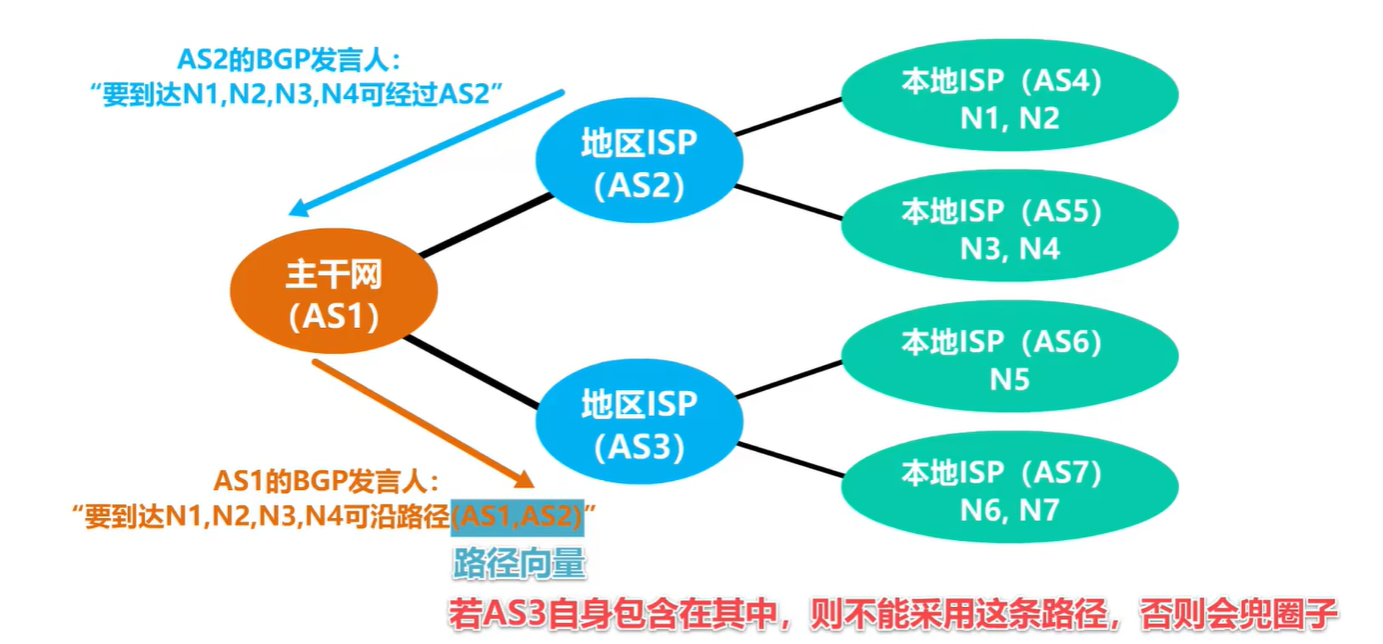
BERT:基础模型时transformer的编码器(做特征提取--> embedding vector),去认识客观世界的万事万物,并通过下游任务的改造,去发掘物与物之间的联系。
GPT:基础模型是Transformer的解码器(做生成式任务),因为decoder中有Masked,masked注定了你不能发掘后面的信息,去预测下面的东西。
缺点:Bert和GPT参数量非常大(GPT1,3亿参数;GPT2,15亿参数),训练一个模型需要几百万美金expense。
1.1 word2vec和ELMo区别
word2vec,是为了得到词向量。通过上下文得到词向量,而不是去预测下一个词。
ELMo,是为了做语言模型。通过上下文去准确预测下一个词。like BERT model。

2 GPT
3. Bert
从大量无标记数据集中训练得到的深度模型,可以显著提高各项nlp任务的准确率。
3.1 Bert集大成者
- 参考了ELMo模型的双向编码思想
- 借鉴了GPT用Transformer作为特征提取器的思路
- 采用了word2vec所使用的的CBOW方法
extension:单向编码--双向编码区别
e.g. “今天天气很{},我们不得不取消户外运动”,分别从单项编码和双向编码的角度去考虑{}中应该填什么词:
- 单向编码:单向编码只会考虑“今天天气很”,以人类的经验,大概率会从“好”、“不错”、“差”、“槽糕”这几个词中选择,这些词可以被华为截然不同的两类。
- 双向编码:双向编码会同时考虑上下文的信息,即出了会考虑“今天天气很”这五个字,还会考虑“我们不得不去取消户外运动”来帮助模型判断,则大概率会从“差”、“槽糕”这一类词中选择。
3.2 Bert和GPT、EMLo区别
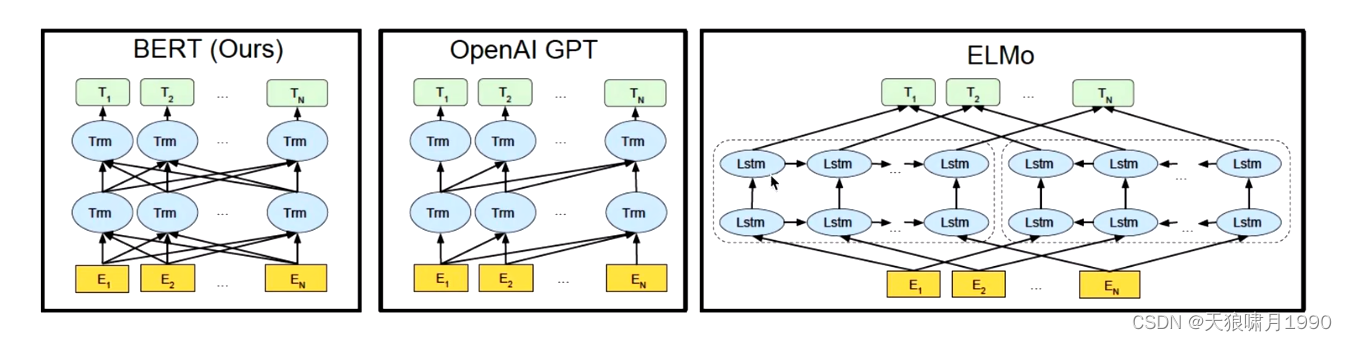
Bert是真正的双向编码;ELMo是伪双向编码,sequence传递,无法完全利用上下文信息。
3.3 Bert Architecture

从上图可以发现,Bert的模型结构其实就是Transformer Encoder模块的堆叠。在模型参数选择上,论文给出了两套大小不一致的模型。
其中,L代表Transformer Block的层数;H代表特征向量的维数(此处默认Feed Forward层中的中间隐层的维数为4H);A表示self-attention的头数,使用这三个参数基本可以确定Bert的量级。
3.3.1 explanation:是否参数多、数据量大,是否过拟合?
大参数量 -> 可能造成过拟合。
如果一个小模型,数据量大了,用大数据集就会过拟合。
但是,如果数据量大,模型也大,就不会过拟合了,就能学到更多的东西。
conclusion:不是模型越大越好,也不是数据集越多越好,而是模型与数据集进行一个匹配。
--> 当Bert总参数量为3.4亿时,它可以利用很多数据集,学习很多东西。
3.3.2 Bert training
和GPT一样,bert也采用二段式训练方法:
1. 第一阶段:使用易获取的大规模无标签语料,来训练基础语言模型。
2. 第二阶段:根据指定任务的少量带标签训练数据进行微调训练。
3.4 Bert为什么要做掩码语言模型(MLM, Masked Language Model)
Bert无法使用CBOW词袋模型思想
对于一句话,我输入的时候mask 15%的词,然后用上下文预测这个masked token是什么 --> 类似CBOW model(训练阶段才会这样做,但测试阶段没有mask词)
测试阶段给你一句话,你就要给我一句话的句向量。
预训练好一个bert模型,给你微调,
problem:这样设计MLM的训练方法会引入弊端:在模型微调训练阶段或模型测试阶段,输入的文本中将没有[MASK],进而导致产生由训练和测试数据偏差导致的性能损失。
solution:之前的做法,会让模型所有精力全部聚焦在mask上面,对于其他的词不管了
用了下述的方法,所有词都有可能是mask词,这样模型会把精力聚焦在大部分词上(包括mask)
3.5 Bert 下句预测(NSP)
目的:为了学会捕捉句子之间的语义联系,Bert采用了下句预测(NSP)作为无监督训练的一部分。
NSP具体做法是,Bert输入的语句将由两个句子构成,其中,50%的概率将语义连贯的两个句子作为训练文本(连续句对对一般选自篇章级别的语料,以此确保前后语句的语义强相关),另外50%的概率将完全随机抽取两个句子作为训练文本。
连续句对:[CLS]今天天气很槽糕[SEP]下午的体育课取消了[SEP]
随机句对:[CLS]今天天气很槽糕[SEP]鱼快被烤焦啦[SEP]
其中,[SEP]标签表示分隔符。[CLS,class label]表示标签用于类别预测,输入为连续句对时,标签为1;输入为随机句对时,标签为0。
training阶段:Bert捕捉两个句对是否连续 --> attention在做注意力机制时,[CLS]标签会和两个语句里的每一个词都会做权重叠加,Bert经过多层transformer编码后,[CLS]包含句子的信息,进而也获得了句子的语义信息。
通过训练[CLS]编码后的输出标签,Bert可以学会捕捉两个输入句对的文本语义。在连续句对的预测任务中,Bert的正确率可以达到97%-98%。
3.6 Bert下游任务改造
Bert最大作用就是提取特征向量。Bert通过transformer编码器构造获取了强大的特征编码能力,获取到了词向量,获取了句子的语义信息。
bert就像一个小孩子,学会了单词的意思,学会了句子意思和连贯,那么只要再稍微点拨一下:
- 再让他学一下句子的正面和负面意思 --》就可以做情感分类 sentiment classification;
- 再让他标注一下地点名、人名、机构 --> 词性标注pos
3.6.1 句对分类
判断两个句子是否属于同一个类别。
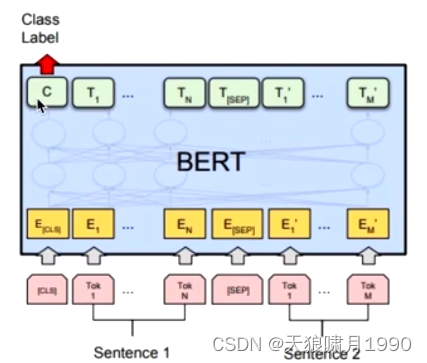
句对用[SEP]分隔符拼接成文本序列,在句首加入[CLS]标签,将句首标签所对应的输出值作为分类标签,计算预测分类标签与真实分类标签的交叉熵,将其作为优化目标,在任务数据上进行微调训练。
3.6.2 单句分类
给定一个句子,判断该句子的类别。
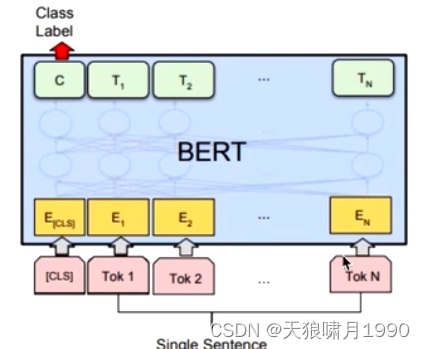
单句分类在句首加入标签[CLS],将句首标签所对应的输出值作为分类标签,计算预测分类标签与真实分类标签的交叉熵,将其作为优化目标,在任务数据上进行微调训练。
3.6.3 文本问答
上面两个是对bert的输入input进行改造,还可以对bert输出output进行改造。
给定一个问句和一个蕴含答案的句子,找出答案在句中的位置,称为文本问答。
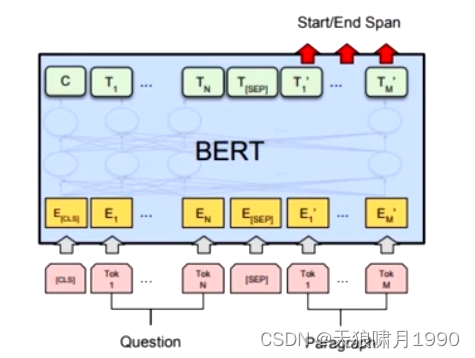
为了标注答案的起始位置和终止位置,Bert引入两个辅助向量s(start,判断答案的起始位置)和e(end,判断答案的终止位置)。
Bert判断句子B中答案位置的做法是,将句子B中的每一个词得到的最终特征向量T'经过全连接层(利用全连接层将词的抽象语义特征转化为任务指向的特征)后,分别与向量s和e求内积,对所有内积分别进行softmax操作,即可得到Tok m作为答案起始位置和终止位置的概率。最后,取概率最大的片段作为最终答案。
3.6.4 单句标注
类似命名实体识别NES。
给定一个句子,标注每个词的标签,称为单句标注。
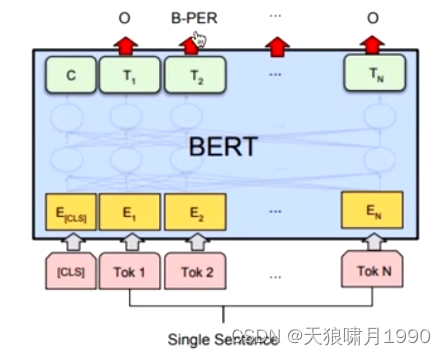
在进行单句标注任务时,需要在每个词的最终语义特征向量之后添加全连接层,将语义特征转化为序列标注任务所需的特征,单句标注任务需要对每个词都做标注,因此不需要引入辅助向量,直接对经过全连接层后的结果做softmax操作,即可得到各类标签的概率分布。
参考:
01 GPT 和 BERT 开课了(两者和 Transformer 的区别)_哔哩哔哩_bilibili