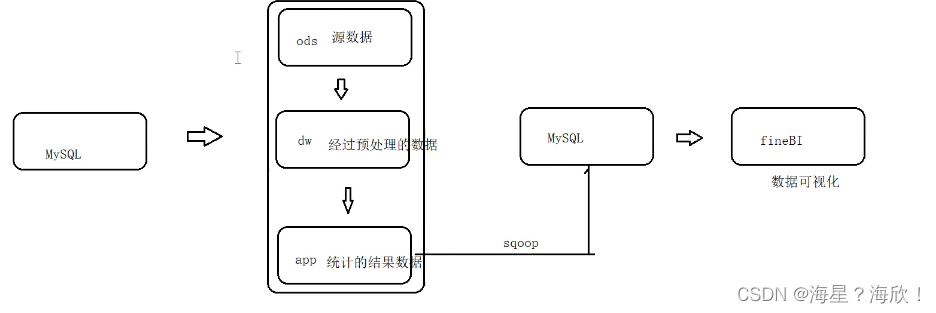
项目大致流程:
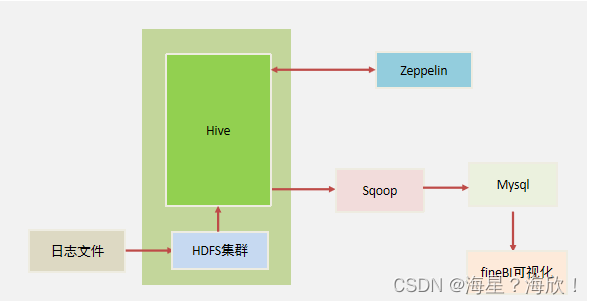
1、项目业务背景
1.1 目的
本案例将某出行打车的日志数据来进行数据分析,例如:我们需要统计某一天订单量是多少、预约订单与非预约订单的占比是多少、不同时段订单占比等
数据海量 – 大数据
hive比MySQL慢很多
1.2 项目架构
- 用户打车的订单数据非常庞大。所以我们需要选择一个大规模数据的分布式文件系统来存储这些日志文件,此处,我们基于Hadoop的HDFS文件系统来存储数据。
- 为了方便进行数据分析,我们要将这些日志文件的数据映射为一张一张的表,所以,我们基于Hive来构建数据仓库。所有的数据,都会在Hive下来几种进行管理。为了提高数据处理的性能。
- 我们将基于MR引擎来进行数据开发。
- 我们将使用Zeppelin来快速将数据进行SQL指令交互。
- 我们使用Sqoop导出分析后的数据到传统型数据库,便于后期应用
- 我们使用fineBI来实现数据可视化展示
2、日志数据集介绍
四张表:打车表,取消订单表,支付表,评价表
1,日志数据文件
处理的数据都是一些文本日志,例如:以下就是一部门用户打车的日志文件。

一行就是一条打车订单数据,而且,一条数据是以逗号来进行分隔的,逗号分隔出来一个个的字段。
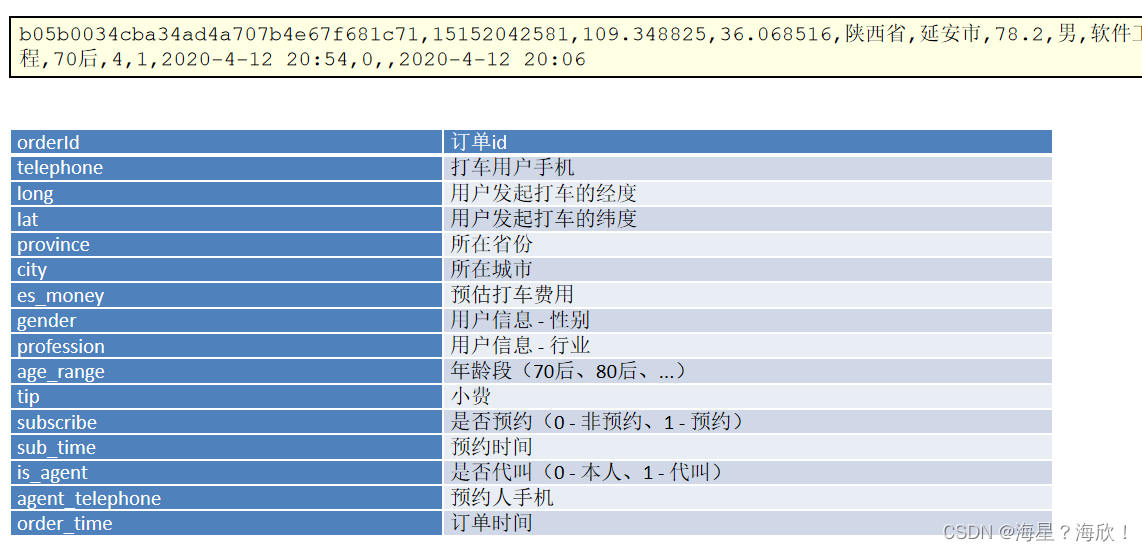
2,用户取消订单日志
当用户取消订单时,也会在系统后台产生一条日志。用户需求选择取消订单的原因。
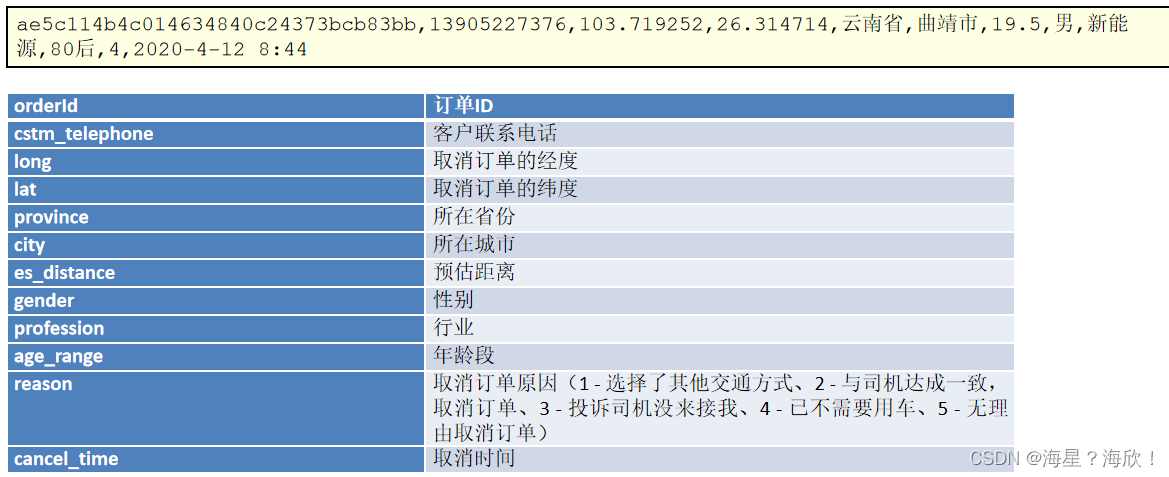
3,用户支付日志
用户点击确认支付后,系统后台会将用户的支持信息保存为一条日志。

4,用户评价日志
我们点击提交评价后,系统后台也会产生一条日志。

3、数据仓库构建
面试问题:数仓如何从0到1?
我们的目标是分析用户打车的订单,进行各类的指标计算(指标,例如:订单的总数、订单的总支付金额等等)。
思想:可以将日志数据上传到HDFS保存下来,每天都可以进行上传,HDFS可以保存海量的数据。同时,可以将HDFS中的数据文件,对应到Hive的表中。但需要考虑一个问题,就是业务系统的日志数据不一定是能够直接进行分析的,
例如:我们需要分析不同时段的订单占比,凌晨有多少订单、早上有多少订单、上午有多少订单等。但是,我们发现,原始的日志文件中,并没有区分该订单的是哪个时间段的字段。所以,我们需要对日志文件的原始数据进行预处理,才能进行分析。
我们会有这么几类数据要考虑:
- 原始日志数据(业务系统中保存的日志文件数据) ods
- 预处理后的数据 dw
- 分析结果数据 app
这些数据我们都通过Hive来进行处理,因为Hive可以将数据映射为一张张的表,然后就可以通过编写HQL来处理数据了,简单、快捷、高效。为了区分以上这些数据,我们将这些数据对应的表分别保存在不同的数据库中。
为了方便组织、管理上述的三类数据,我们将数仓分成不同的层,简单来说,就是分别将三类不同的数据保存在Hive的不同数据库中。
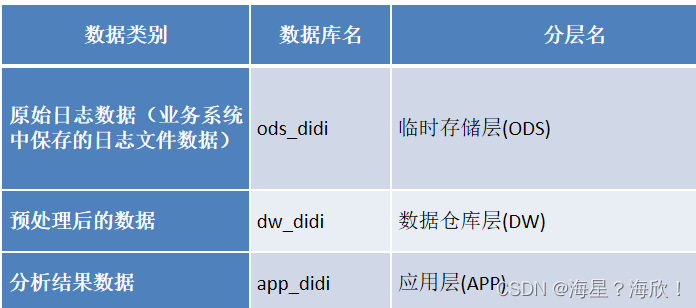
1)在hive构建三层数据仓库:ods、dw、app:
--1:创建数据库
-- 1.1 创建ods库
create database if not exists ods_didi;
-- 1.2 创建dw库
create database if not exists dw_didi;
-- 1.3 创建app库
create database if not exists app_didi;
2)在ods层创建四张表
--2:创建表
-- 2.1 创建订单表结构
create table if not exists ods_didi.t_user_order(
orderId string comment '订单id',
telephone string comment '打车用户手机',
lng string comment '用户发起打车的经度',
lat string comment '用户发起打车的纬度',
province string comment '所在省份',
city string comment '所在城市',
es_money double comment '预估打车费用',
gender string comment '用户信息 - 性别',
profession string comment '用户信息 - 行业',
age_range string comment '年龄段(70后、80后、...)',
tip double comment '小费',
subscribe int comment '是否预约(0 - 非预约、1 - 预约)',
sub_time string comment '预约时间',
is_agent int comment '是否代叫(0 - 本人、1 - 代叫)',
agent_telephone string comment '预约人手机',
order_time string comment '预约时间'
)
partitioned by (dt string comment '时间分区')
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ;
--2.2 创建取消订单表
create table if not exists ods_didi.t_user_cancel_order(
orderId string comment '订单ID',
cstm_telephone string comment '客户联系电话',
lng string comment '取消订单的经度',
lat string comment '取消订单的纬度',
province string comment '所在省份',
city string comment '所在城市',
es_distance double comment '预估距离',
gender string comment '性别',
profession string comment '行业',
age_range string comment '年龄段',
reason int comment '取消订单原因(1 - 选择了其他交通方式、2 - 与司机达成一致,取消订单、3 - 投诉司机没来接我、4 - 已不需要用车、5 - 无理由取消订单)',
cancel_time string comment '取消时间'
)
partitioned by (dt string comment '时间分区')
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ;
--2.3 创建订单支付表
create table if not exists ods_didi.t_user_pay_order(
id string comment '支付订单ID',
orderId string comment '订单ID',
lng string comment '目的地的经度(支付地址)',
lat string comment '目的地的纬度(支付地址)',
province string comment '省份',
city string comment '城市',
total_money double comment '车费总价',
real_pay_money double comment '实际支付总额',
passenger_additional_money double comment '乘客额外加价',
base_money double comment '车费合计',
has_coupon int comment '是否使用优惠券(0 - 不使用、1 - 使用)',
coupon_total double comment '优惠券合计',
pay_way int comment '支付方式(0 - 微信支付、1 - 支付宝支付、3 - QQ钱包支付、4 - 一网通银行卡支付)',
mileage double comment '里程(单位公里)',
pay_time string comment '支付时间'
)
partitioned by (dt string comment '时间分区')
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ;
--2.4创建用户评价表
create table if not exists ods_didi.t_user_evaluate(
id string comment '评价日志唯一ID',
orderId string comment '订单ID',
passenger_telephone string comment '用户电话',
passenger_province string comment '用户所在省份',
passenger_city string comment '用户所在城市',
eva_level int comment '评价等级(1 - 一颗星、... 5 - 五星)',
eva_time string comment '评价时间'
)
partitioned by (dt string comment '时间分区')
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ;
comment—注释
show tables --查看一下
4、数据分区表构建
3)表数据加载
大规模数据的处理,必须要构建分区。我们此处的需求每天都会进行数据分析,采用的是T+1的模式。
就是假设今天是2021-01-01,那么1月1日的分析结果在第二天才能看到,也就是2021-01-02查看到上一天的数据分析结果。此处,我们采用最常用的分区方式,使用日期来进行分区。
-3:给表加载数据
--3.1、创建本地路径,上传源日志文件
mkdir -p /export/data/didi
--3.2、通过load命令给表加载数据,并指定分区
load data local inpath '/export/data/didi/order.csv' into table t_user_order partition (dt='2020-04-12');
load data local inpath '/export/data/didi/cancel_order.csv' into table t_user_cancel_order partition (dt='2020-04-12');
load data local inpath '/export/data/didi/pay.csv' into table t_user_pay_order partition (dt='2020-04-12');
load data local inpath '/export/data/didi/evaluate.csv' into table t_user_evaluate partition (dt='2020-04-12');
加载完数据后也是查看一下,数据是否成功进入;
select * from t_user_order limit 1;
select * from t_user_cancel_order limit 1;
select * from t_user_pay_order limit 1;
select * from t_user_evaluate limit 1;
5、数据预处理
现在数据已经准备好了,接下来需要对ods层中的数据进行预处理。
数据预处理是数据仓库开发中的一个重要环节。目的主要是让预处理后的数据更容易进行数据分析,并且能够将一些非法的数据处理掉,避免影响实际的统计结果。
需要在预处理之前考虑以下需求:
- 过滤掉order_time长度小于8的数据,如果小于8,表示这条数据不合法,不应该参加统计。—length(order_time)>=8
- 将一些0、1表示的字段,处理为更容易理解的字段。例如:subscribe字段,0表示非预约、1表示预约。我们需要添加一个额外的字段,用来展示非预约和预约,这样将来我们分析的时候,跟容易看懂数据。—case when
- order_time字段为2020-4-12 1:15,为了将来更方便处理,我们统一使用类似 2020-04-12 01:15:00来表示,这样所有的order_time字段长度是一样的。并且将日期获取出来 为了方便将来按照年、月、日、小时统计,我们需要新增这几个字段。后续要分析一天内,不同时段的订单量,我们需要在预处理过程中将订单对应的时间段提前计算出来。例如:1:00-5:00为凌晨。

多增加了7个字段—形成宽表,包含以下字段:
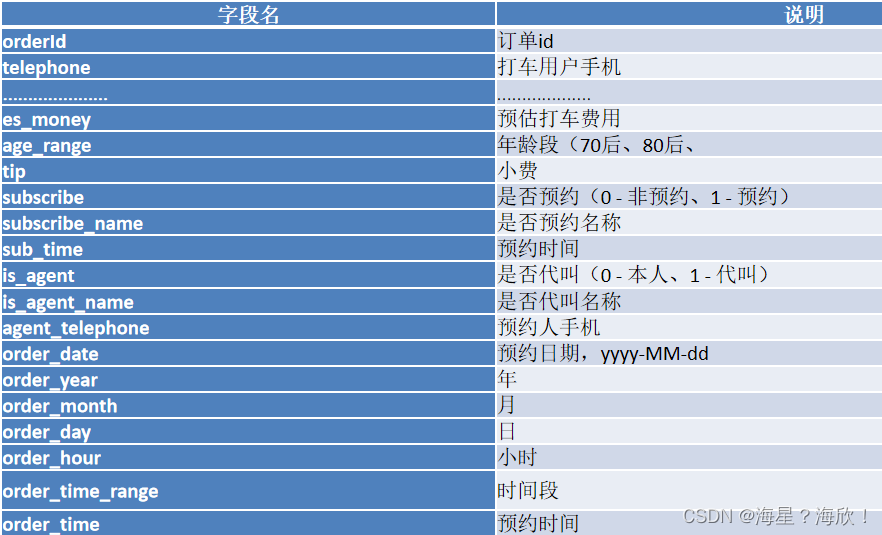
--4:数据预处理
--建表
create table if not exists dw_didi.t_user_order_wide(
orderId string comment '订单id',
telephone string comment '打车用户手机',
lng string comment '用户发起打车的经度',
lat string comment '用户发起打车的纬度',
province string comment '所在省份',
city string comment '所在城市',
es_money double comment '预估打车费用',
gender string comment '用户信息 - 性别',
profession string comment '用户信息 - 行业',
age_range string comment '年龄段(70后、80后、...)',
tip double comment '小费',
subscribe int comment '是否预约(0 - 非预约、1 - 预约)',
subscribe_name string comment '是否预约名称',
sub_time string comment '预约时间',
is_agent int comment '是否代叫(0 - 本人、1 - 代叫)',
is_agent_name string comment '是否代叫名称',
agent_telephone string comment '预约人手机',
order_date string comment '预约时间,yyyy-MM-dd',
order_year string comment '年',
order_month string comment '月',
order_day string comment '日',
order_hour string comment '小时',
order_time_range string comment '时间段',
order_time string comment '预约时间'
)
partitioned by (dt string comment '时间分区')
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ;
--转宽表HQL语句
--------------------------------------
--date_format将字符串转为日期
select date_format('2020-1-1', 'yyyy-MM-dd'); -- 2020-01-01
select date_format('2020-1-1 12:23', 'yyyy-MM-dd'); -- 2020-01-01
select date_format('2020-1-1 12:23:35', 'yyyy-MM-dd'); -- 2020-01-01
select date_format('2020-1-1 1:1:1', 'yyyy-MM-dd HH:mm:ss'); -- 2020-01-01 01:01:01
select hour(date_format('2020-1-1 1:1:00', 'yyyy-MM-dd HH:mm:ss')); -- 2020-01-01 01:01:01
--concat字符串的拼接
select concat('aaa','bbb','ccc');-- aaabbbccc
--length 获取字符串长度
select length('aaabbb'); -- 6
一天新增4500TB,一个服务器的磁盘存储容量10T
生成宽表后,往宽表中插入数据
如何将一个表的查询结果保存到另外一张表:
insert overwrite table 表名1 select 字段 from 表名2
insert overwrite table dw_didi.t_user_order_wide partition(dt='2020-04-12')
select
orderId,
telephone,
lng,
lat,
province,
city,
es_money,
gender,
profession,
age_range,
tip,
subscribe,
case when subscribe = 0 then '非预约'
when subscribe = 1 then'预约'
end as subscribe_name,
date_format(concat(sub_time,':00'), 'yyyy-MM-dd HH:mm:ss') as sub_time,
is_agent,
case when is_agent = 0 then '本人'
when is_agent = 1 then '代叫'
end as is_agent_name,
agent_telephone,
date_format(order_time, 'yyyy-MM-dd') as order_date, -- 2020-1-1 --->2020-01-01
year(date_format(order_time, 'yyyy-MM-dd')) as order_year, --2020
month(date_format(order_time, 'yyyy-MM-dd')) as order_month, --12
day(date_format(order_time, 'yyyy-MM-dd')) as order_day, --23
hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) as order_hour,
case when hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) > 1 and hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) <= 5 then '凌晨'
when hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) > 5 and hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) <= 8 then '早上'
when hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) > 8 and hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) <= 11 then '上午'
when hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) > 11 and hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) <= 13 then '中午'
when hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) > 13 and hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) <= 17 then '下午'
when hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) > 17 and hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) <= 19 then '晚上'
when hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) > 19 and hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) <= 20 then '半夜'
when hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) > 20 and hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) <= 24 then '深夜'
when hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) >= 0 and hour(date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss')) <= 1 then '深夜'
else 'N/A'
end as order_time_range,
date_format(concat(order_time,':00'), 'yyyy-MM-dd HH:mm:ss') as order_time
from ods_didi.t_user_order where dt = '2020-04-12' and length(order_time) >= 8;
6、订单指标分析
1 总订单笔数
select
count(orderid) as total_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12'
;
-- 创建保存日期对应订单笔数的app表
create table if not exists app_didi.t_order_total(
date_val string comment '日期(年月日)',
count int comment '订单笔数'
)
partitioned by (month string comment '年月,yyyy-MM')
row format delimited fields terminated by ','
;
--加载数据到app表
insert overwrite table app_didi.t_order_total partition(month='2020-04')
select
'2020-04-12',
count(orderid) as total_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12'
;
- 预约和非预约用户占比
需求:
求出预约用户订单所占的百分比:
select 预约订单总数 / 总订单数 from 预约统计订单数表,总订单数表
union all
select 非预约订单总数 / 总订单数 from 非预约统计订单数表,总订单数表
select
'2020-04-12',
'预约',
concat(round(t1.total_cnt /t2.total_cnt *100,2),'%') as subscribe
from
(
select
count(orderid) as total_cnt
from
dw_didi.t_user_order_wide
where
subscribe = 1 and dt = '2020-04-12'
)t1,
(
select
count(orderid) as total_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12'
)t2
union all --将上边的查询结果和下边的查询结果进行合并
select
'2020-04-12',
'非预约',
concat(round(t1.total_cnt /t2.total_cnt *100,2),'%') as nosubscribe
from
(
select
count(orderid) as total_cnt
from
dw_didi.t_user_order_wide
where
subscribe = 0 and dt = '2020-04-12'
)t1,
(
select
count(orderid) as total_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12'
)t2
-- 创建保存日期对应订单笔数的app表
create table if not exists app_didi.t_order_subscribe_percent(
date_val string comment '日期',
subscribe_name string comment '是否预约',
percent_val string comment '百分比'
)partitioned by (month string comment '年月yyyy-MM')
row format delimited fields terminated by ','
--加载数据到app表
insert overwrite table app_didi.t_order_subscribe_percent partition(month='2020-04')
select
'2020-04-12',
'预约',
concat(round(t1.total_cnt /t2.total_cnt *100,2),'%') as subscribe
from
(
select
count(orderid) as total_cnt
from
dw_didi.t_user_order_wide
where
subscribe = 1 and dt = '2020-04-12'
)t1,
(
select
count(orderid) as total_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12'
)t2
union all
select
'2020-04-12',
'非预约',
concat(round(t1.total_cnt /t2.total_cnt *100,2),'%') as nosubscribe
from
(
select
count(orderid) as total_cnt
from
dw_didi.t_user_order_wide
where
subscribe = 0 and dt = '2020-04-12'
)t1,
(
select
count(orderid) as total_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12'
)t2
3 不同时段的占比分析
--编写HQL语句
select
order_time_range,
count(*) as order_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12'
group by
order_time_range
--创建APP层表
create table if not exists app_didi.t_order_timerange_total(
date_val string comment '日期',
timerange string comment '时间段',
count int comment '订单数量'
)
partitioned by (month string comment '年月,yyyy-MM')
row format delimited fields terminated by ','
;
--加载数据到APP表
insert overwrite table app_didi.t_order_timerange_total partition(month = '2020-04')
select
'2020-04-12',
order_time_range,
count(*) as order_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12'
group by
order_time_range
;
4 不同地域订单占比
--编写HQL ---方式1
select
province,
count(*) as order_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12'
group by
province
;
--编写HQL ---方式2
select * from
(
select
*,
dense_rank() over(partition by province order by t.total_cnt desc) as rk
from
(
select
'2020-04-12',
province,
city,
count(orderid) as total_cnt
from dw_didi.t_user_order_wide
group by province,city
)t
)tt
where tt.rk <=3;
--创建APP表
create table if not exists app_didi.t_order_province_total(
date_val string comment '日期',
province string comment '省份',
count int comment '订单数量'
)
partitioned by (month string comment '年月,yyyy-MM')
row format delimited fields terminated by ','
;
--数据加载到APP表
insert overwrite table app_didi.t_order_province_total partition(month = '2020-04')
select
'2020-04-12',
province,
count(*) as order_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12'
group by
province
order by order_cnt desc
;
5 不同年龄段,不同时段订单占比
--不同年龄段的订单统计
select
'2020-04-12',
age_range,
count(*)
from dw_didi.t_user_order_wide
where dt='2020-04-12'
group by age_range
--不同时段的订单统计
select
'2020-04-12',
order_time_range,
count(*)
from dw_didi.t_user_order_wide
where dt='2020-04-12'
group by order_time_range
--不同年龄段,不同时段的订单统计
select
'2020-04-12',
age_range,
order_time_range,
count(*) as order_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12'
group by
age_range,
order_time_range
;
--创建APP表
create table if not exists app_didi.t_order_age_and_time_range_total(
date_val string comment '日期',
age_range string comment '年龄段',
order_time_range string comment '时段',
count int comment '订单数量'
)
partitioned by (month string comment '年月,yyyy-MM')
row format delimited fields terminated by ','
;
--加载数据到APP表
insert overwrite table app_didi.t_order_age_and_time_range_total partition(month = '2020-04')
select
'2020-04-12',
age_range,
order_time_range,
count(*) as order_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12'
group by
age_range,
order_time_range
;
7、Sqoop数据导出
Sqoop安装
-- 准备工作
#验证sqoop是否工作
/export/server/sqoop-1.4.7/bin/sqoop list-databases \
--connect jdbc:mysql://192.168.88.100:3306/ \
--username root \
--password 123456
--1:mysql创建目标数据库和目标表
#创建目标数据库
create database if not exists app_didi;
#创建订单总笔数目标表
create table if not exists app_didi.t_order_total(
order_date date,
count int
);
--2:导出订单总笔数表数据
/export/server/sqoop-1.4.7/bin/sqoop export \
--connect jdbc:mysql://192.168.88.100:3306/app_didi \
--username root \
--password 123456 \
--table t_order_total \
--export-dir /user/hive/warehouse/app_didi.db/t_order_total/month=2020-04
8、finebi数据可视化
--Superset可视化
superset run -h 192.168.88.100 -p 8099 --with-threads --reload --debugger
mysql+pymysql://root:123456@192.168.88.100/app_didi?charset=utf8