Hadoop集群搭建
再起启动一台虚拟机并且安装jdk,开启免密登录
不需要安装zookeeper
文章目录
- Hadoop集群搭建
- 时间同步4台机器
- 安装npdate
- 设置定时任务
- 集群配置图
- 将Hadoop安装包上传到zk1
- zk1---解压到soft目录下
- zk1---更名
- zk1---修改配置文件
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- yarn-site.xml
- hadoop-env.sh
- workers
- 修改 /etc/profile
- 给hadoop313修改用户和组
- 将hadoop313 /etc/profile 发送到zk2 zk3 zk4
- 刷新 zk1 zk2 zk3 zk4 /etc/profile
- 集群首次启动
- 1.启动zk集群
- 2.启动zk1,zk2,zk3的journalnode服务
- 3.在zk1格式化hfds namenode
- 4.在zk1启动namenode服务
- 5.在zk2机器上同步namenode信息
- 6.在zk2启动namenode服务
- 查看namenode节点状态
- 7.关闭所有dfs有关的服务
- 8.格式化zk
- 9.启动dfs
- 10.启动yarn
时间同步4台机器
安装npdate
[root@zk1 opt]# yum -y install ntpdate
设置定时任务
[root@zk1 opt]# crontab -e
设置每10分更新时间
*/10 * * * * /usr/sbin/ntpdate time.windows.com

加载定时任务
[root@zk1 opt]# service crond reload
重启定时任务
[root@zk1 opt]# service crond restart
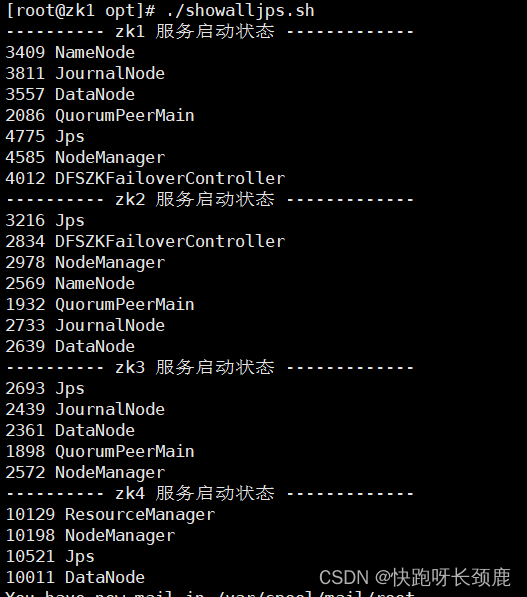
集群配置图
| zk1 | zk2 | zk3 | zk4 |
|---|---|---|---|
| NameNode | NameNode | ||
| DataNode | DataNode | DataNode | DataNode |
| NodeManager | NodeManager | NodeManager | NodeManager |
| ResourceManager | ResourceManager | ||
| JournalNode | JournalNode | JournalNode | |
| DFSZKFConler | DFSZKFConler | ||
| zookeeper | zookeeper | zookeeper | |
| JobHistory |
将Hadoop安装包上传到zk1
zk1—解压到soft目录下
[root@zk1 install]# tar -zxvf ./hadoop-3.1.3.tar.gz -C …/soft/
zk1—更名
[root@zk1 soft]# mv hadoop-3.1.3/ hadoop313

zk1—修改配置文件
切换到/opt/soft/hadoop313/etc/hadoop目录下
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://gky</value>
<description>逻辑名称,必须与hdfs-site.xml中的dfs.nameservices值保持一致</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/soft/hadoop313/tmpdata</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
<description>默认用户</description>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
<description></description>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
<description></description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description>读写文件的buffer大小为:128K</description>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>zk1:2181,zk2:2181,zk3:2181</value>
<description></description>
</property>
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>10000</value>
<description>hadoop链接zookeeper的超时时长设置为10s</description>
</property>
hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
<description>Hadoop中每一个block的备份数</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/soft/hadoop313/data/dfs/name</value>
<description>namenode上存储hdfs名字空间元数据目录</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/soft/hadoop313/data/dfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>zk1:9869</value>
<description></description>
</property>
<property>
<name>dfs.nameservices</name>
<value>gky</value>
<description>指定hdfs的nameservice,需要和core-site.xml中保持一致</description>
</property>
<property>
<name>dfs.ha.namenodes.gky</name>
<value>nn1,nn2</value>
<description>gky为集群的逻辑名称,映射两个namenode逻辑名</description>
</property>
<property>
<name>dfs.namenode.rpc-address.gky.nn1</name>
<value>zk1:9000</value>
<description>namenode1的RPC通信地址</description>
</property>
<property>
<name>dfs.namenode.http-address.gky.nn1</name>
<value>zk1:9870</value>
<description>namenode1的http通信地址</description>
</property>
<property>
<name>dfs.namenode.rpc-address.gky.nn2</name>
<value>zk2:9000</value>
<description>namenode2的RPC通信地址</description>
</property>
<property>
<name>dfs.namenode.http-address.gky.nn2</name>
<value>zk2:9870</value>
<description>namenode2的http通信地址</description>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://zk1:8485;zk2:8485;zk3:8485/gky</value>
<description>指定NameNode的edits元数据的共享存储位置(JournalNode列表)</description>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/soft/hadoop313/data/journaldata</value>
<description>指定JournalNode在本地磁盘存放数据的位置</description>
</property>
<!-- 容错 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
<description>开启NameNode故障自动切换</description>
</property>
<property>
<name>dfs.client.failover.proxy.provider.gky</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<description>失败后自动切换的实现方式</description>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
<description>防止脑裂的处理</description>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
<description>使用sshfence隔离机制时,需要ssh免密登陆</description>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
<description>关闭HDFS操作权限验证</description>
</property>
<property>
<name>dfs.image.transfer.bandwidthPerSec</name>
<value>1048576</value>
<description></description>
</property>
<property>
<name>dfs.block.scanner.volume.bytes.per.second</name>
<value>1048576</value>
<description></description>
</property>
mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>job执行框架: local, classic or yarn</description>
<final>true</final>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/soft/hadoop313/etc/hadoop:/opt/soft/hadoop313/share/hadoop/common/lib/*:/opt/soft/hadoop313/share/hadoop/common/*:/opt/soft/hadoop313/share/hadoop/hdfs/*:/opt/soft/hadoop313/share/hadoop/hdfs/lib/*:/opt/soft/hadoop313/share/hadoop/mapreduce/*:/opt/soft/hadoop313/share/hadoop/mapreduce/lib/*:/opt/soft/hadoop313/share/hadoop/yarn/*:/opt/soft/hadoop313/share/hadoop/yarn/lib/*</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>zk1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>zk1:19888</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1024</value>
<description>map阶段的task工作内存</description>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
<description>reduce阶段的task工作内存</description>
</property>
yarn-site.xml
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
<description>开启resourcemanager高可用</description>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrcabc</value>
<description>指定yarn集群中的id</description>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
<description>指定resourcemanager的名字</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>zk1</value>
<description>设置rm1的名字</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>zk4</value>
<description>设置rm2的名字</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>zk3:8088</value>
<description></description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>zk4:8088</value>
<description></description>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>zk1:2181,zk2:2181,zk3:2181</value>
<description>指定zk集群地址</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>运行mapreduce程序必须配置的附属服务</description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/opt/soft/hadoop313/tmpdata/yarn/local</value>
<description>nodemanager本地存储目录</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/opt/soft/hadoop313/tmpdata/yarn/log</value>
<description>nodemanager本地日志目录</description>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
<description>resource进程的工作内存</description>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
<description>resource工作中所能使用机器的内核数</description>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>256</value>
<description></description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description></description>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
<description>日志保留多少秒</description>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description></description>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/opt/soft/hadoop313/etc/hadoop:/opt/soft/hadoop313/share/hadoop/common/lib/*:/opt/soft/hadoop313/share/hadoop/common/*:/opt/soft/hadoop313/share/hadoop/hdfs/*:/opt/soft/hadoop313/share/hadoop/hdfs/lib/*:/opt/soft/hadoop313/share/hadoop/mapreduce/*:/opt/soft/hadoop313/share/hadoop/mapreduce/lib/*:/opt/soft/hadoop313/share/hadoop/yarn/*:/opt/soft/hadoop313/share/hadoop/yarn/lib/*</value>
<description></description>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
<description></description>
</property>
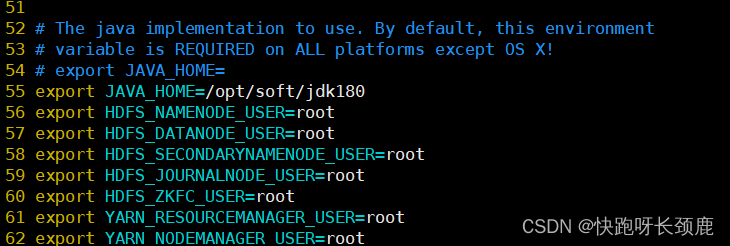
hadoop-env.sh
export JAVA_HOME=/opt/soft/jdk180
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
workers
zk1
zk2
zk3
zk4
修改 /etc/profile
在profile里配置hadoop全局环境
81 #Hadoop
82 export HADOOP_HOME=/opt/soft/hadoop313
83 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/lib

给hadoop313修改用户和组
[root@zk1 soft]# chown -R root:root hadoop313/
将hadoop313 /etc/profile 发送到zk2 zk3 zk4
[root@zk1 soft]# scp -r ./hadoop313/ root@zk2:/opt/soft
[root@zk1 soft]# scp -r ./hadoop313/ root@zk3:/opt/soft
[root@zk1 soft]# scp -r ./hadoop313/ root@zk4:/opt/soft
[root@zk1 soft]# scp /etc/profile root@zk2:/etc/
[root@zk1 soft]# scp /etc/profile root@zk3:/etc/
[root@zk1 soft]# scp /etc/profile root@zk4:/etc/
刷新 zk1 zk2 zk3 zk4 /etc/profile
[root@zk1 soft]# source /etc/profile
[root@zk2 soft]# source /etc/profile
[root@zk3 soft]# source /etc/profile
[root@zk4 soft]# source /etc/profile
集群首次启动
1.启动zk集群
[root@zk1 opt]# ./zkop.sh start
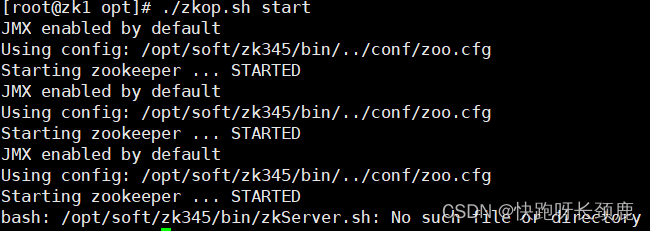
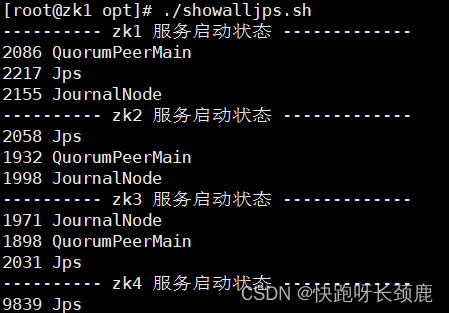
2.启动zk1,zk2,zk3的journalnode服务
hdfs --daemon start journalnode
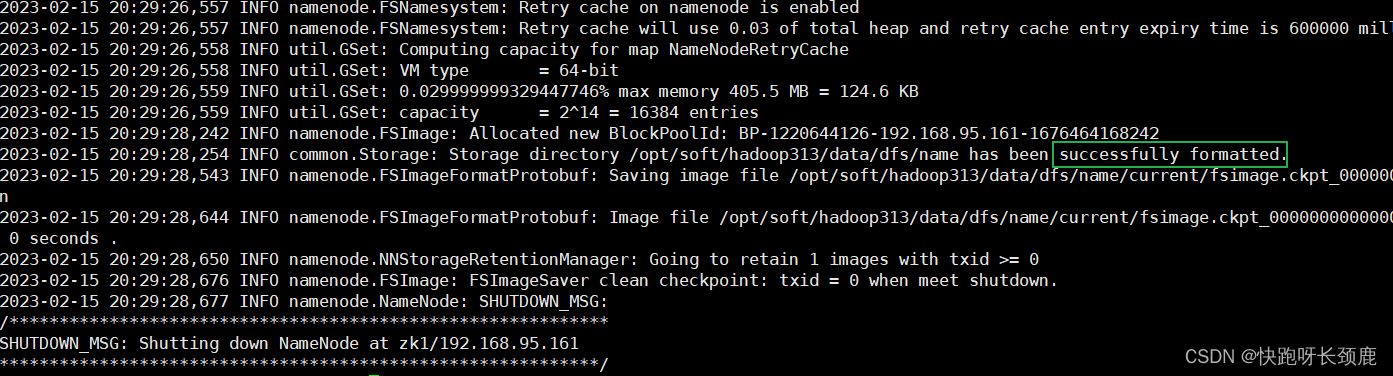
3.在zk1格式化hfds namenode
[root@zk1 opt]# hdfs namenode -format
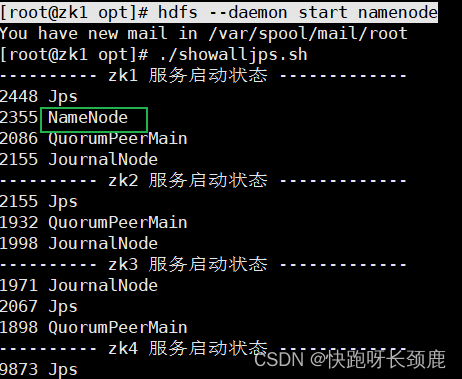
4.在zk1启动namenode服务
[root@zk1 opt]# hdfs --daemon start namenode
5.在zk2机器上同步namenode信息
[root@zk2 soft]# hdfs namenode -bootstrapStandby
6.在zk2启动namenode服务
[root@zk2 hadoop313]# hdfs --daemon start namenode
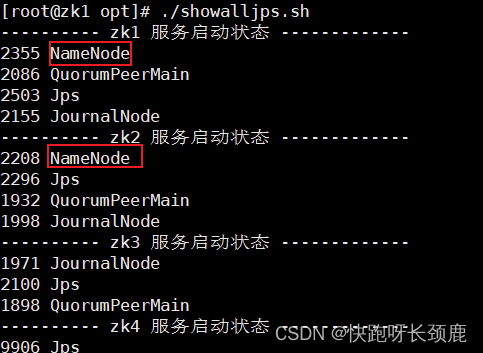
查看namenode节点状态
hdfs haadmin -getServiceState nn1|nn2
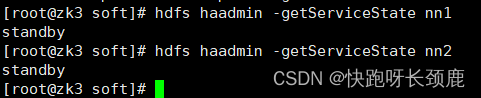
7.关闭所有dfs有关的服务
[root@zk1 soft]# stop-dfs.sh
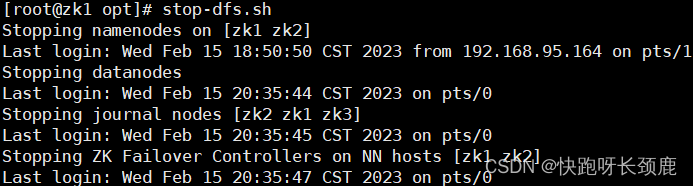
8.格式化zk
[root@zk1 soft]# hdfs zkfc -formatZK
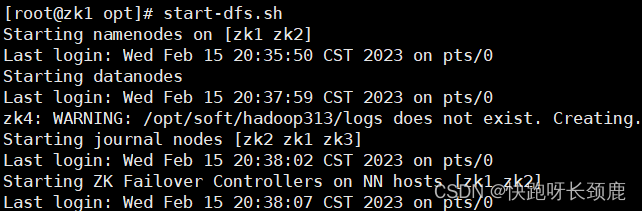
9.启动dfs
[root@zk1 soft]# start-dfs.sh
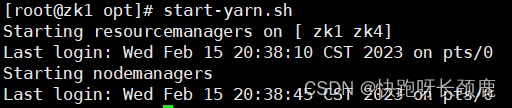
10.启动yarn
[root@zk1 soft]# start-yarn.sh
查看resourcemanager节点状态
yarn rmadmin -getServiceState rm1|rm2



![[ Azure - IAM ] Azure 中的基于角色的访问控制 (RBAC) 与基于属性的访问控制 (ABAC)](https://img-blog.csdnimg.cn/3d718d62115f497e8dcba627a8ba5c72.png)