文章目录
- 图像
- 衡量结果(损失函数)
- 预测的好坏
- 前向传播 反向传播
图像
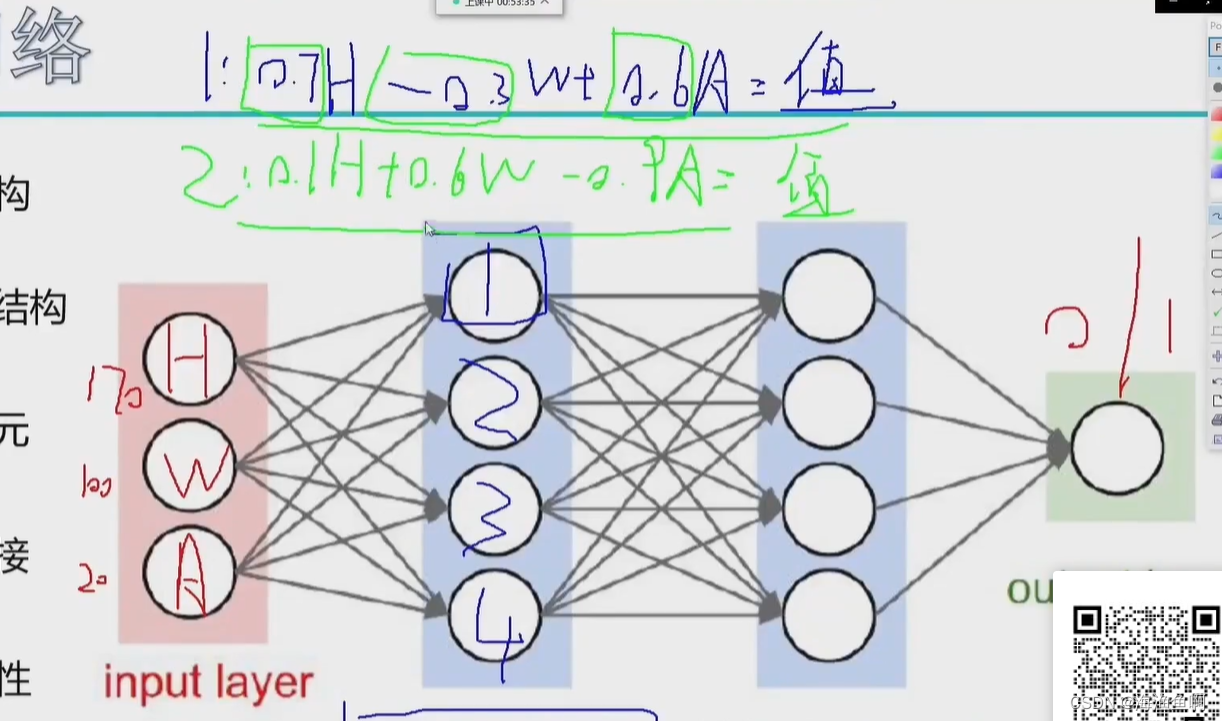
实质是矩阵
长 宽 像素通道(0-255 0 黑 255 亮)

假设这里做一个10分类

行向量✖列向量是一个数
分类

最后的结果是一个各个分类的概率值
这里的b是偏置项,对结果做微调 y = ax + b
这里的b有10个 (因为是10分类)
问题:权重参数w 哪里来的?
一开始是随机初始化的,全是随机值,(猜的,不好)
但是神经网络是“学习” 它的权重参数会不断优化

最后得到最优的权重参数
然而这里的模型训练的很不好,明明是猫 然而给猫这里是负值
(问:是x导致的还是w? 答:w 因为x本身是数据 w是我们训练的
衡量结果(损失函数)

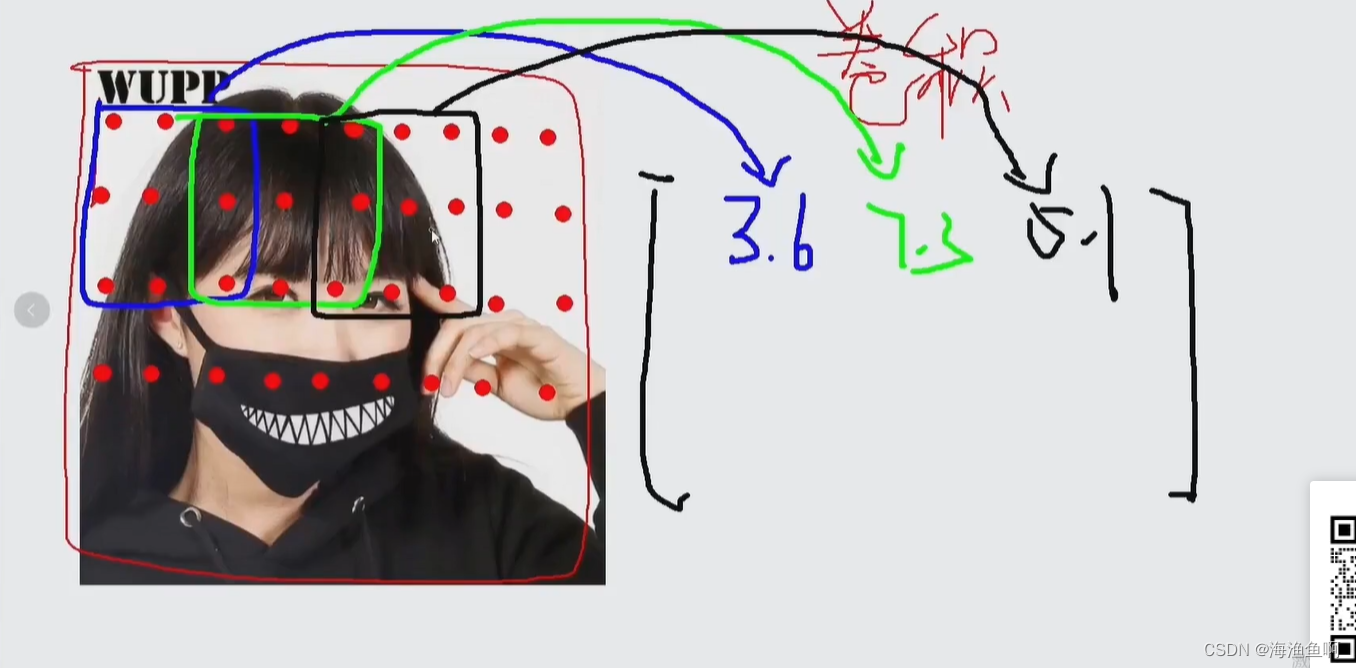
先得到一个预测值
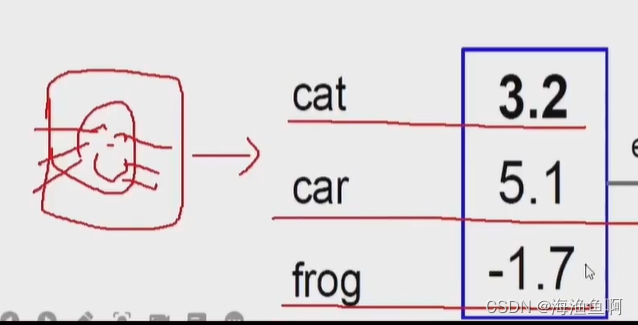
这里是只猫,属于猫的评分是3.2 属于汽车的是5.1 是青蛙的是-1.7
做一个e的x次幂的映射
为什么?
这里的得分值很接近,做e的处理,放大差异
之前得到是概率,而此处是得分,因此用归一化的方法来得到概率

关注的是属于正确类别的概率,不是说越大越好(是越接近于1越好)
预测的好坏
如果是1 则损失为0
对数函数 算损失值的多少
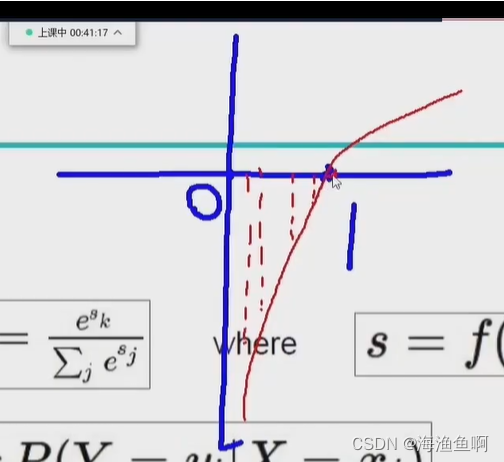
之所以有负值
是log在0-1为负值 再取一个负号
前向传播 反向传播
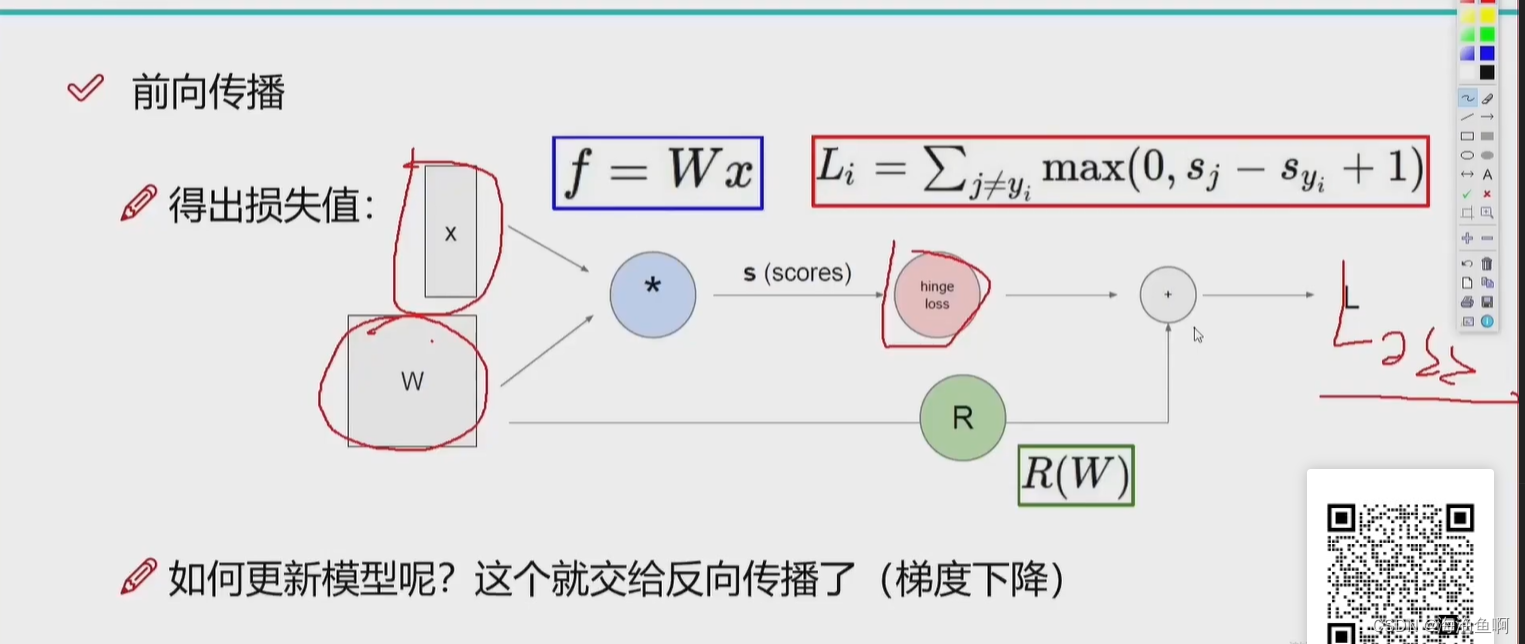
如果不合适,则更新W
期待损失越小越好
横轴是w 权重参数 纵轴是loss 损失 期待损失最小
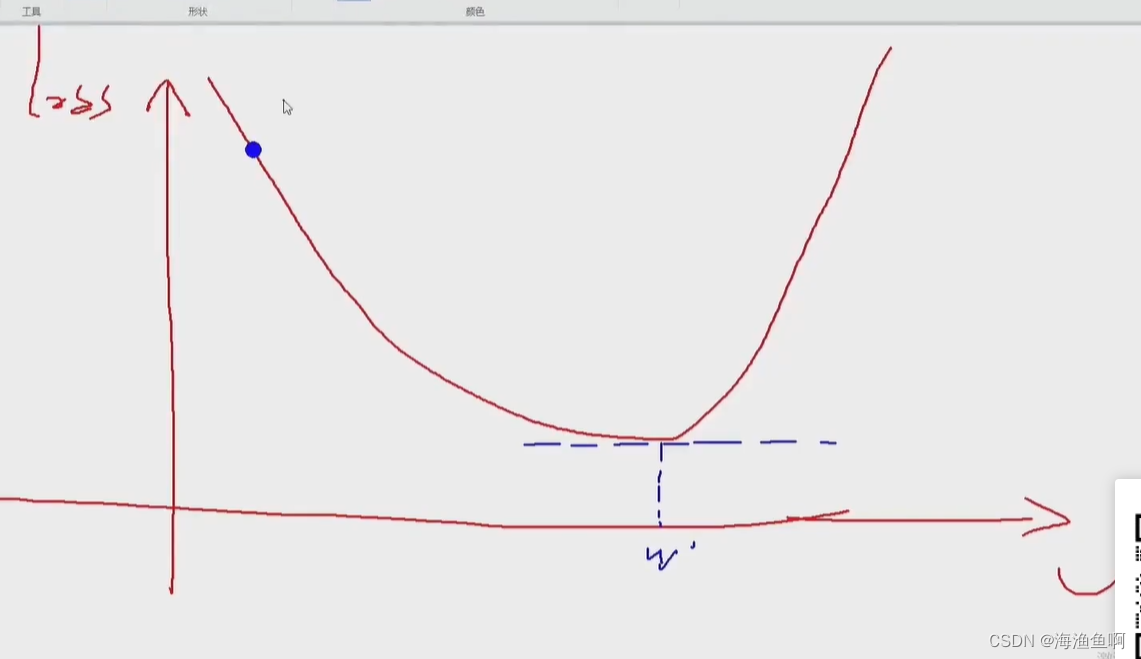
沿梯度下降 速度最快能到达loss的最低点
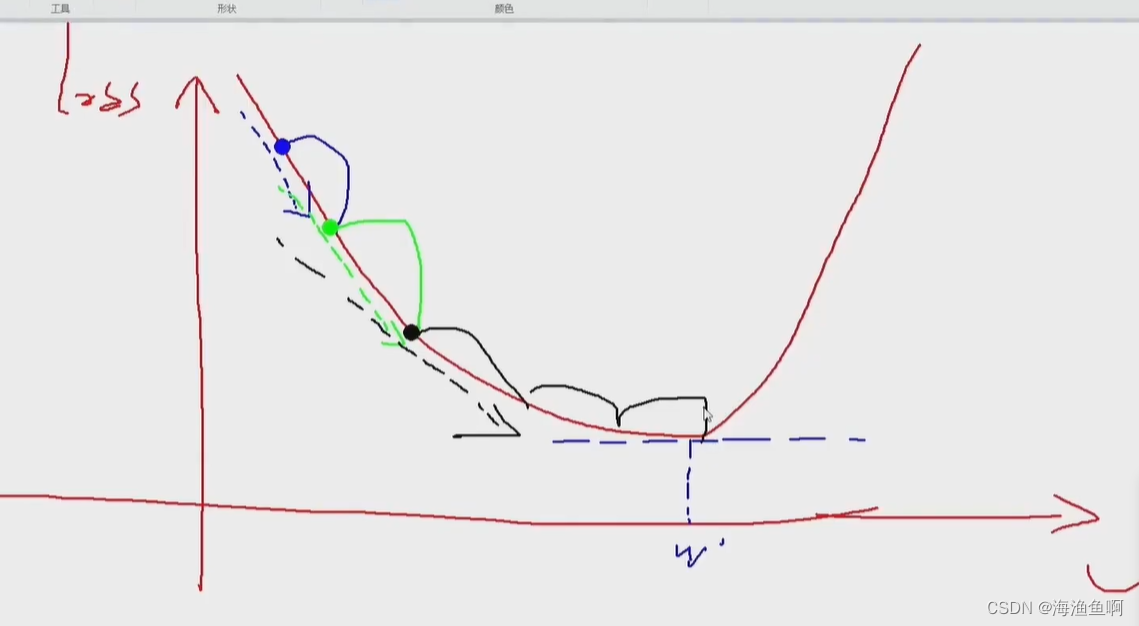
不断有新的梯度 ,为什么说是梯度下降?(不是下山,是指正常的
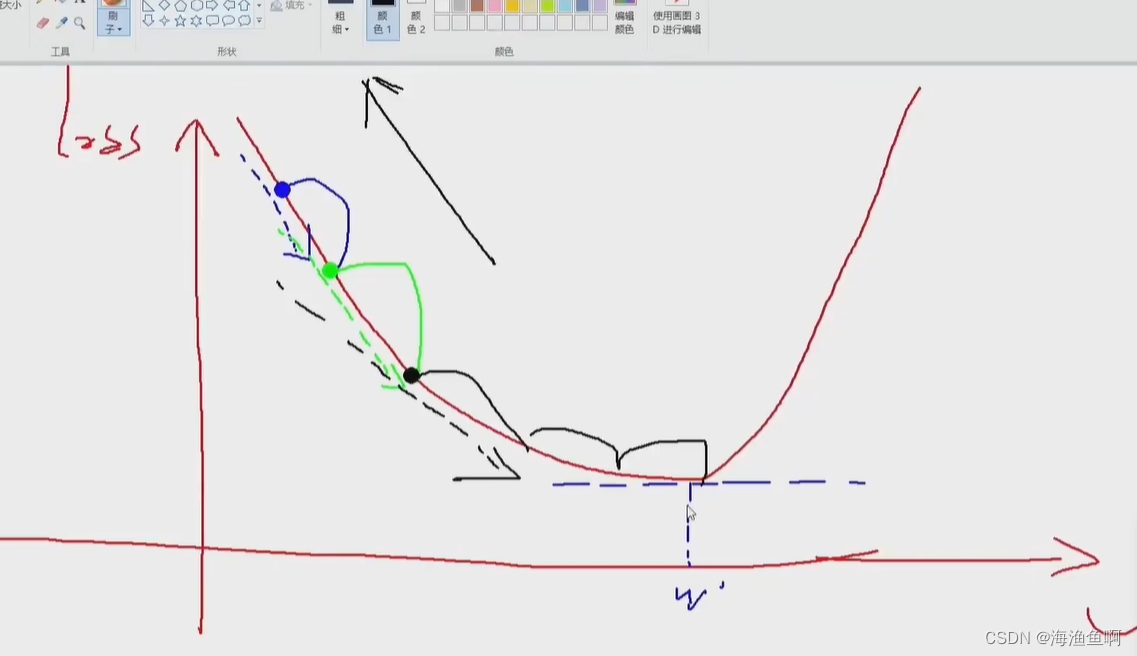
沿梯度的反方向向上
神经网络有许多层,沿后向前依次



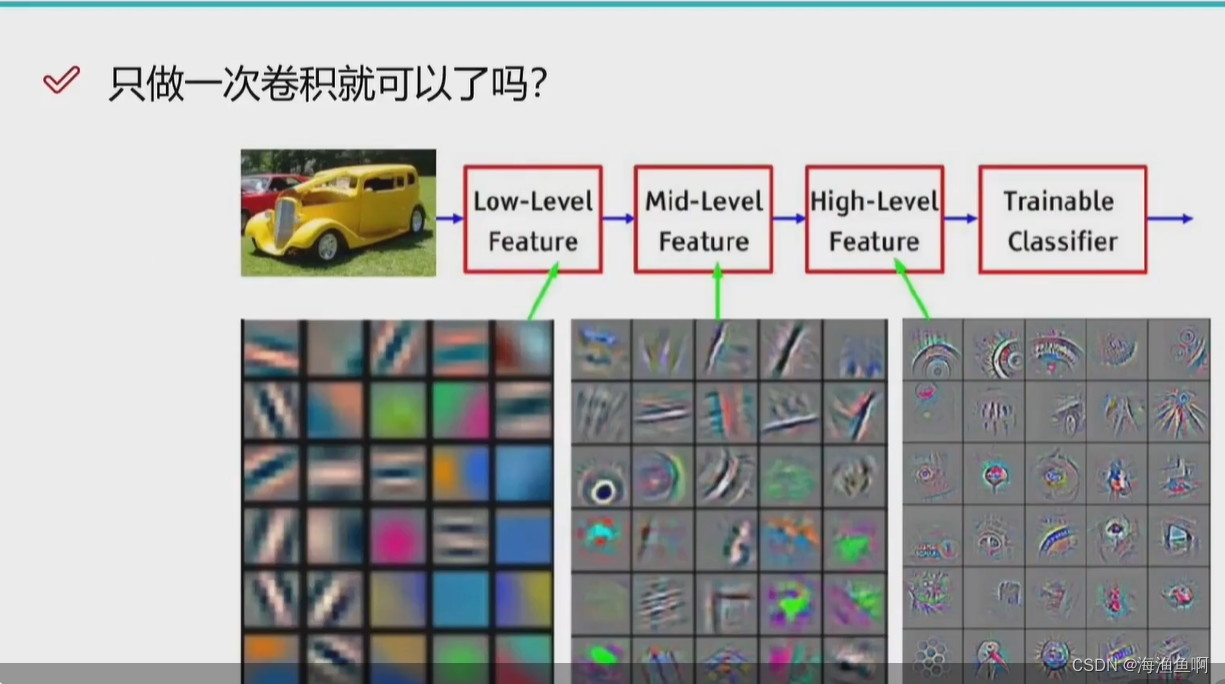
神经网络的本质是提特征
计算机不认识人类数据,它要读取计算机的0 1 语言
要做特征的转换
这里得出的系数 就是一个w矩阵,权重系数 计算机它自己学的,谁也不知道它咋想的
计算机有觉得单层太单薄了,就又来一层
无论是分类 回归 预测 都是在特征提取的好的基础上
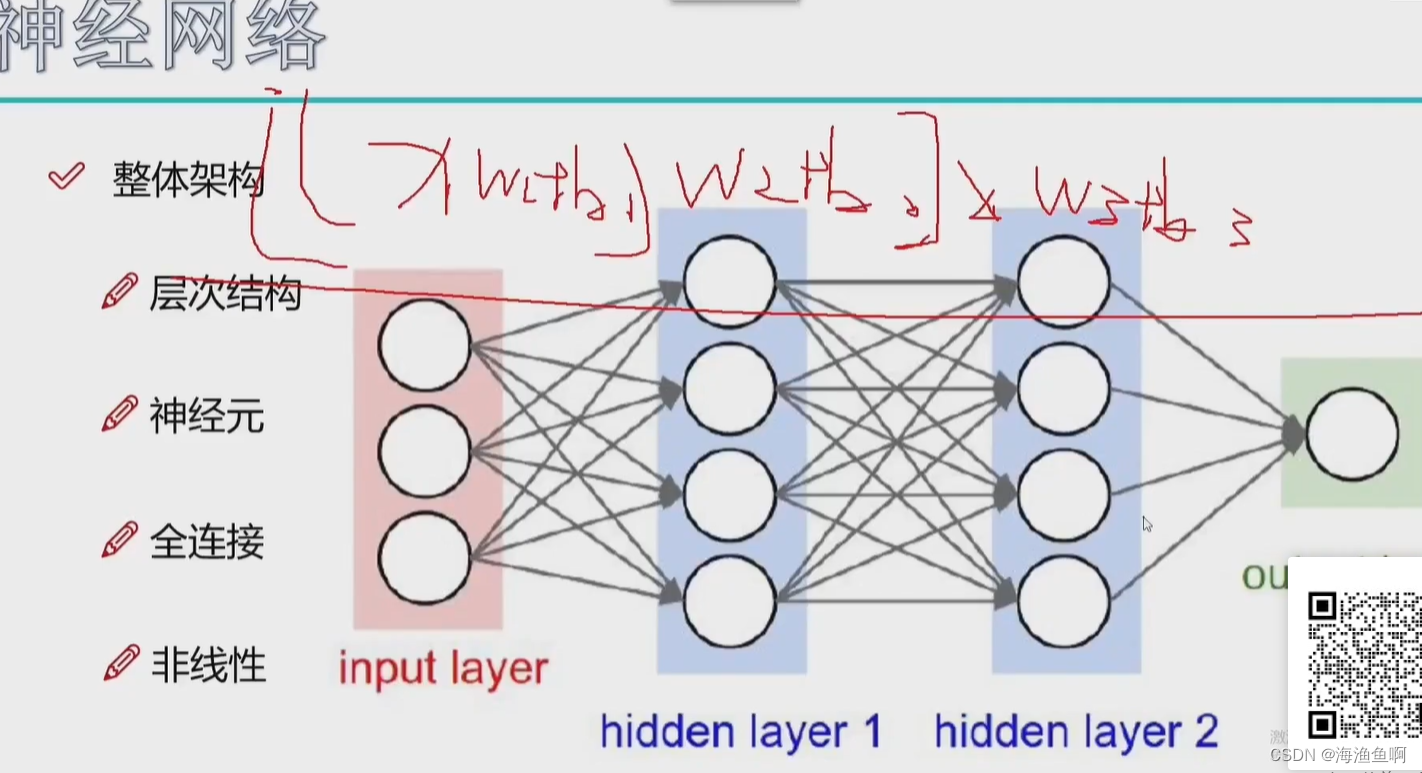
神经元个数对结果的影响
个数越多越好
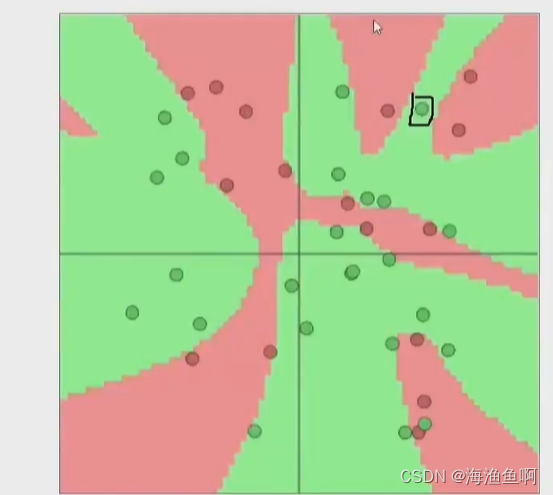
random的情况 为了识别一个异常点 但是给了它一大片 这样会导致误判别的 本来是粉色,但是为了识别出绿色 给了一大块绿色,这样会导致误判 就是过拟合
泛化能力是指


不是一个点一个点提特征,而是一个区域。
关注的是区域

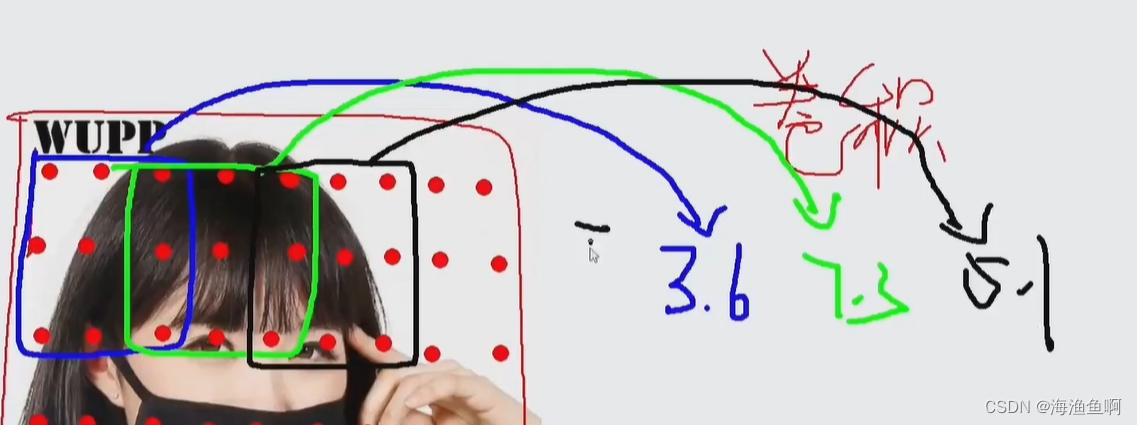
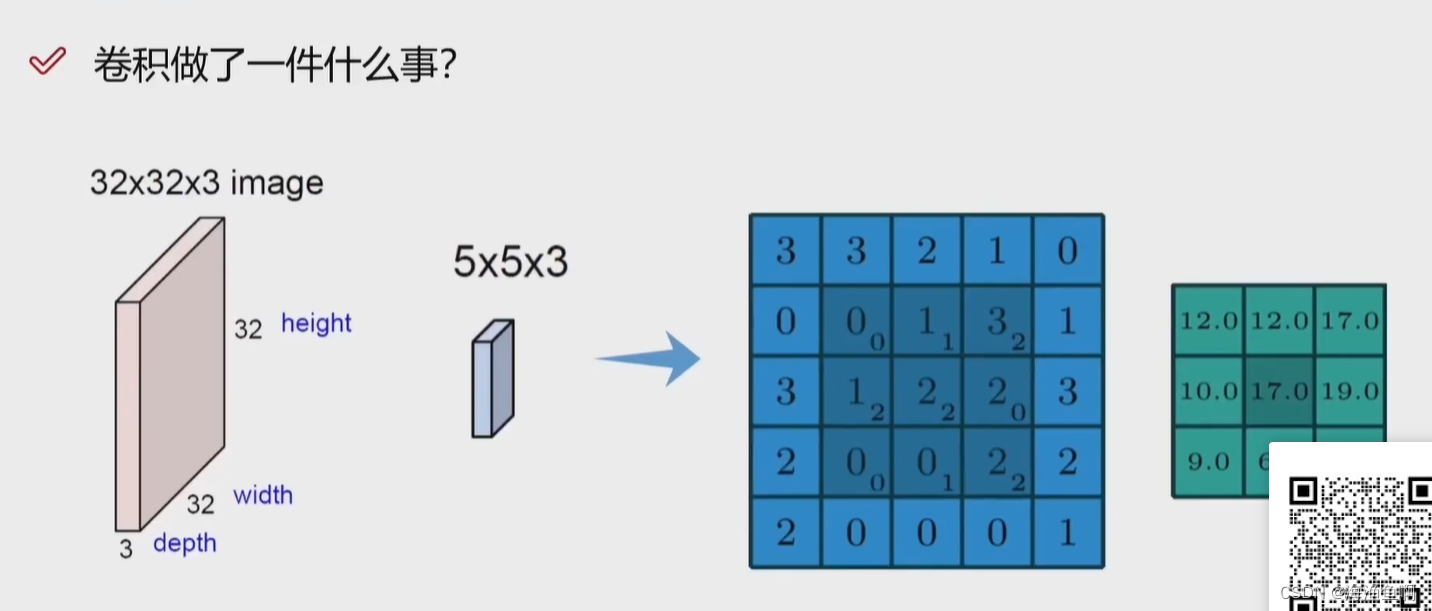
对每一个窗口做一个遍历

做内积
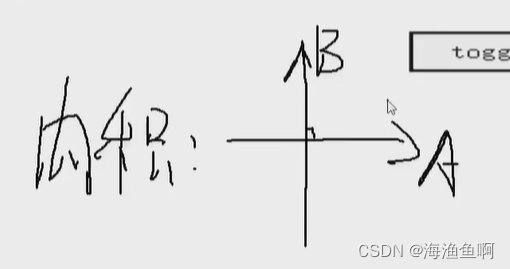
垂直是关系为最远,是0 -1反而是很强的关系(完完全全的负相关)
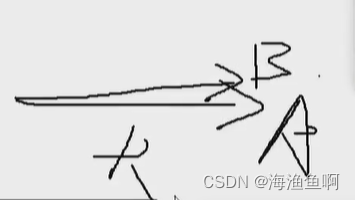
而这样的内积很大

何为卷积核 filter?就是权重参数
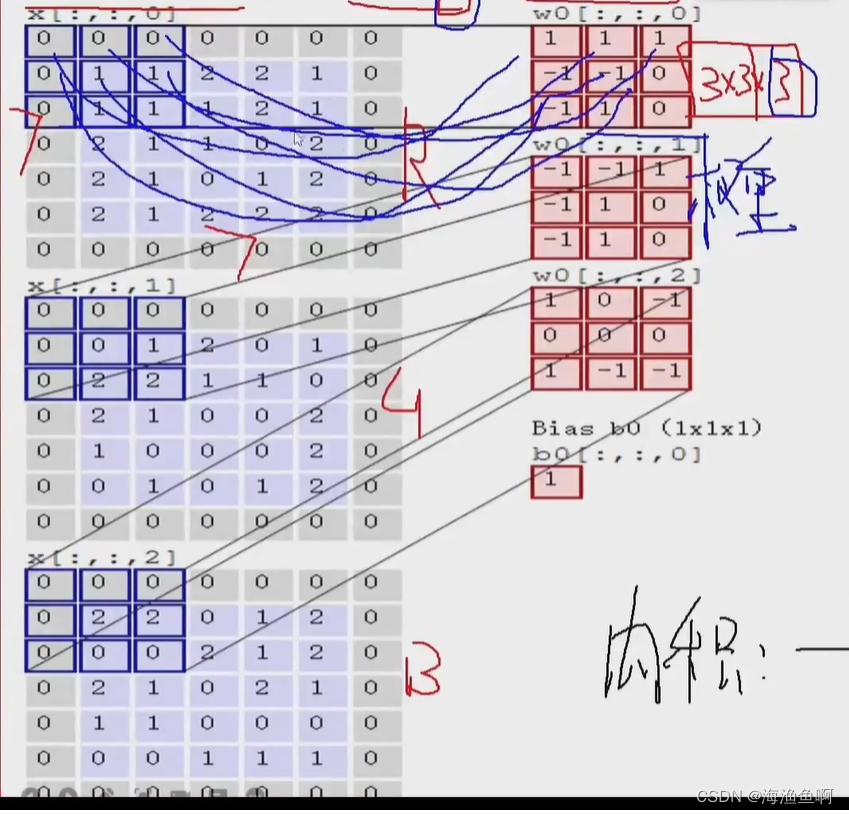
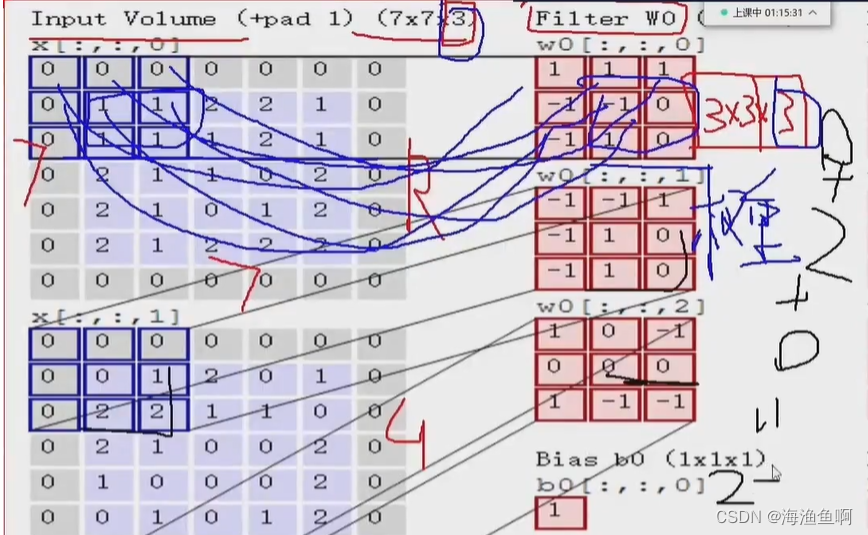
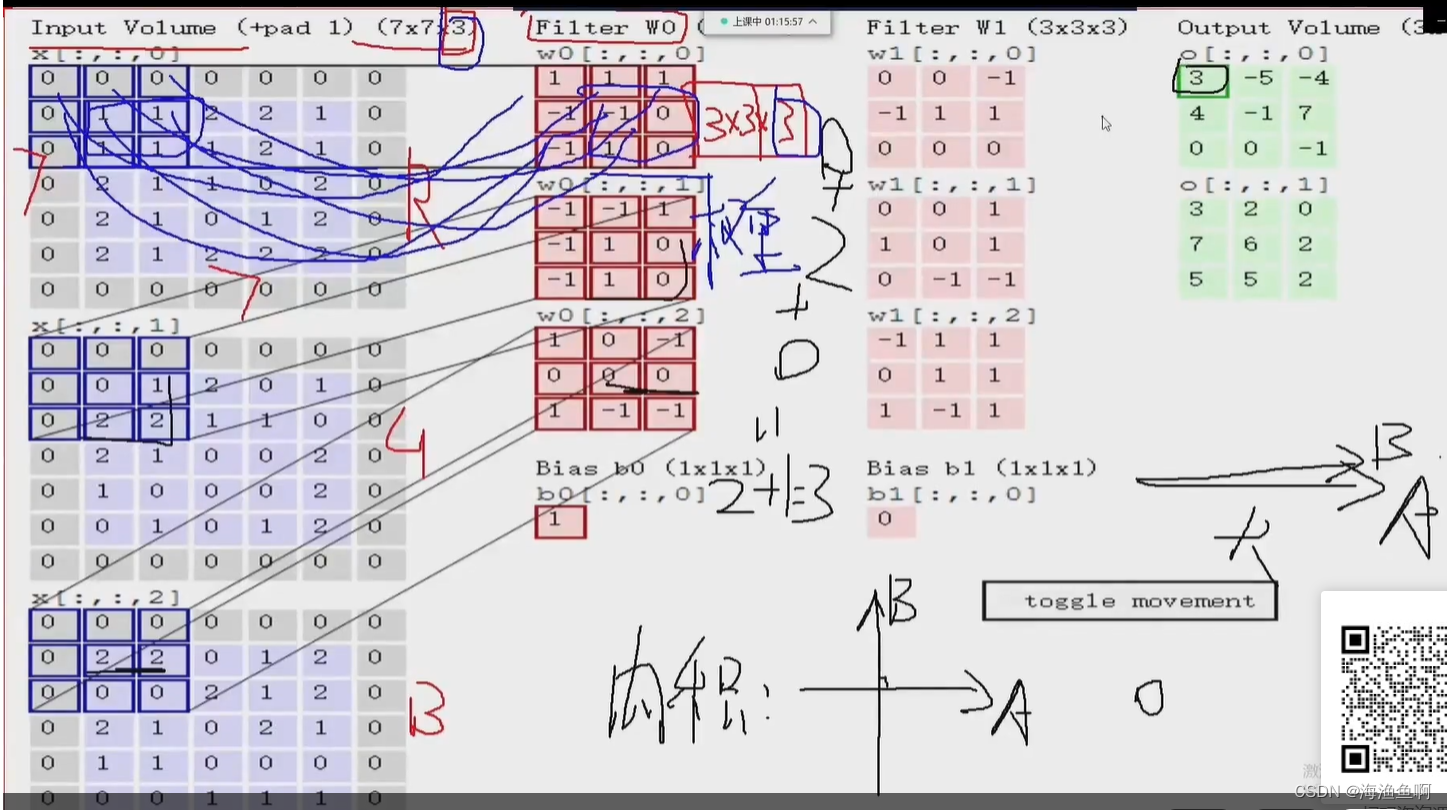
这里的1是b偏置

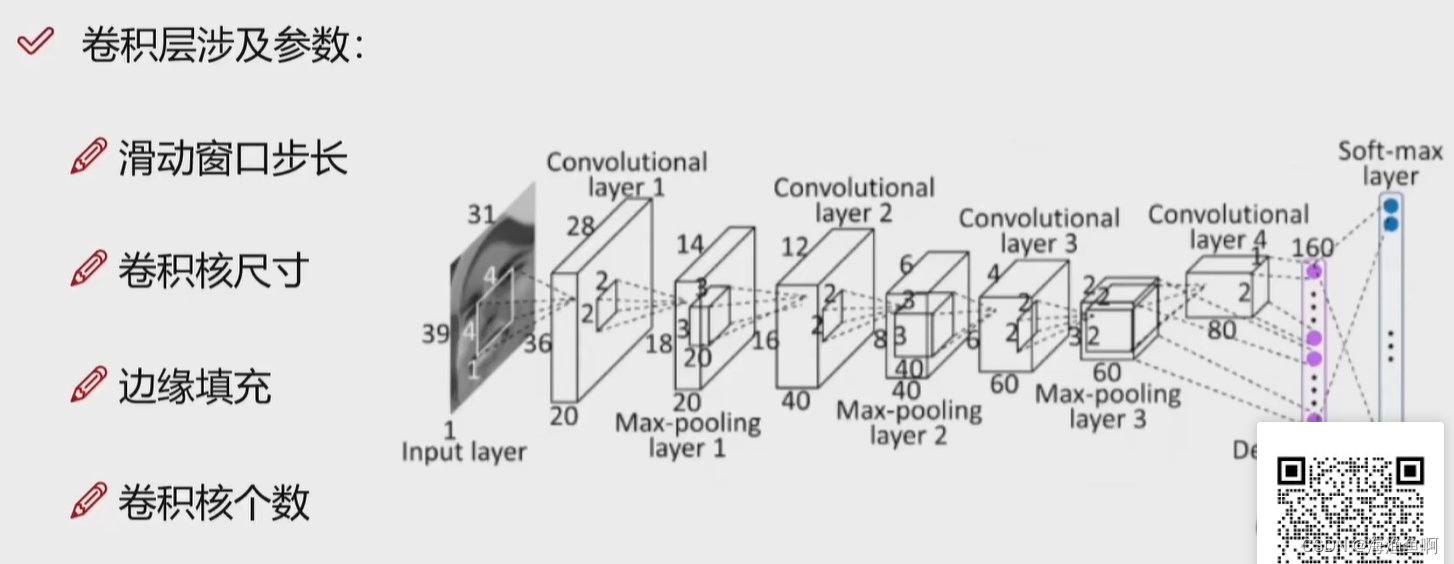
stride越小 遍历的窗口越多,特征越多
此处的卷积核是3*3 的 卷积核越大,活动窗口越少 提取的特征也越少
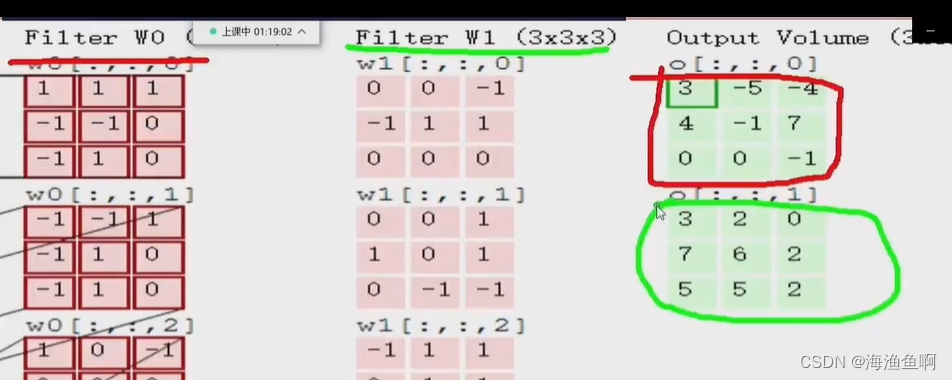
两个卷积核,两个权重图
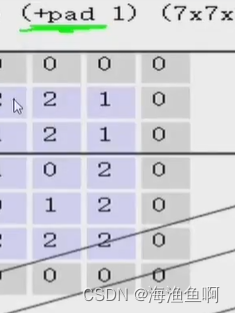
这里的pad是填充
越靠中间,重复的次数越多,边缘的信息被漏掉了,原来是5*5的 现在加了一圈0
这里只是用一下周围的数,用0来凑 称之为0填充
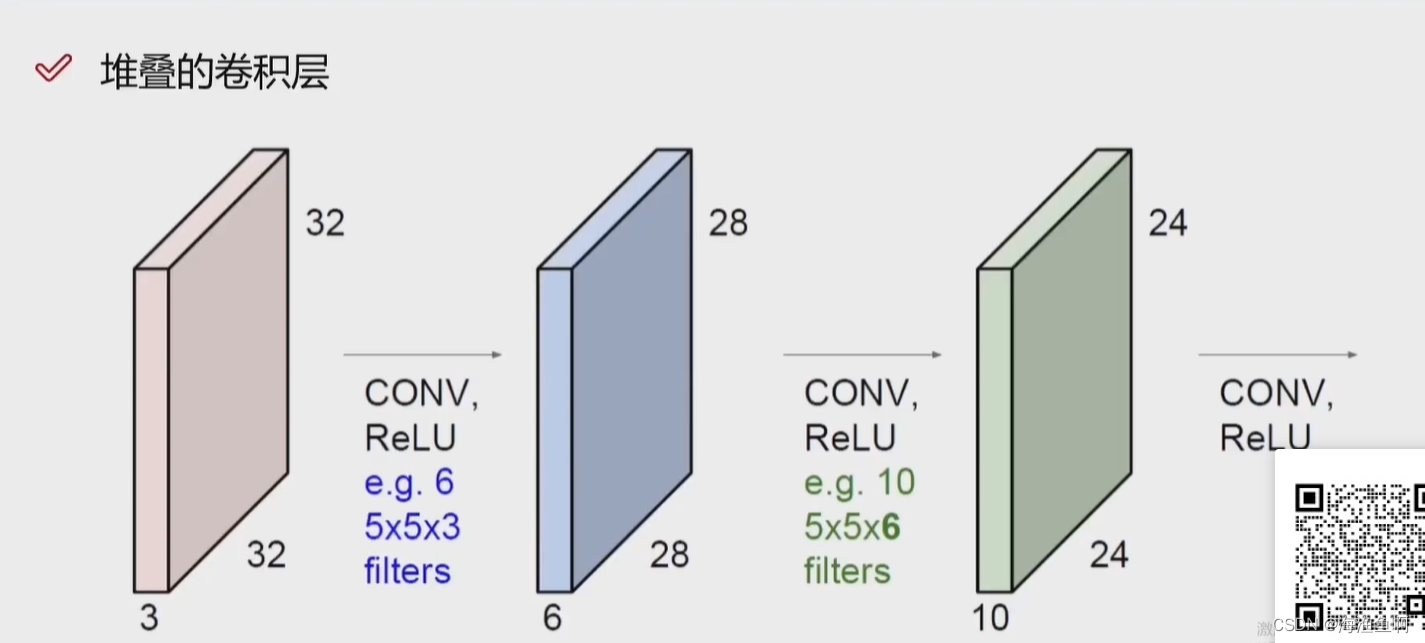
卷积网络也是有隐层的
用多个卷积
特征多了也不是最好
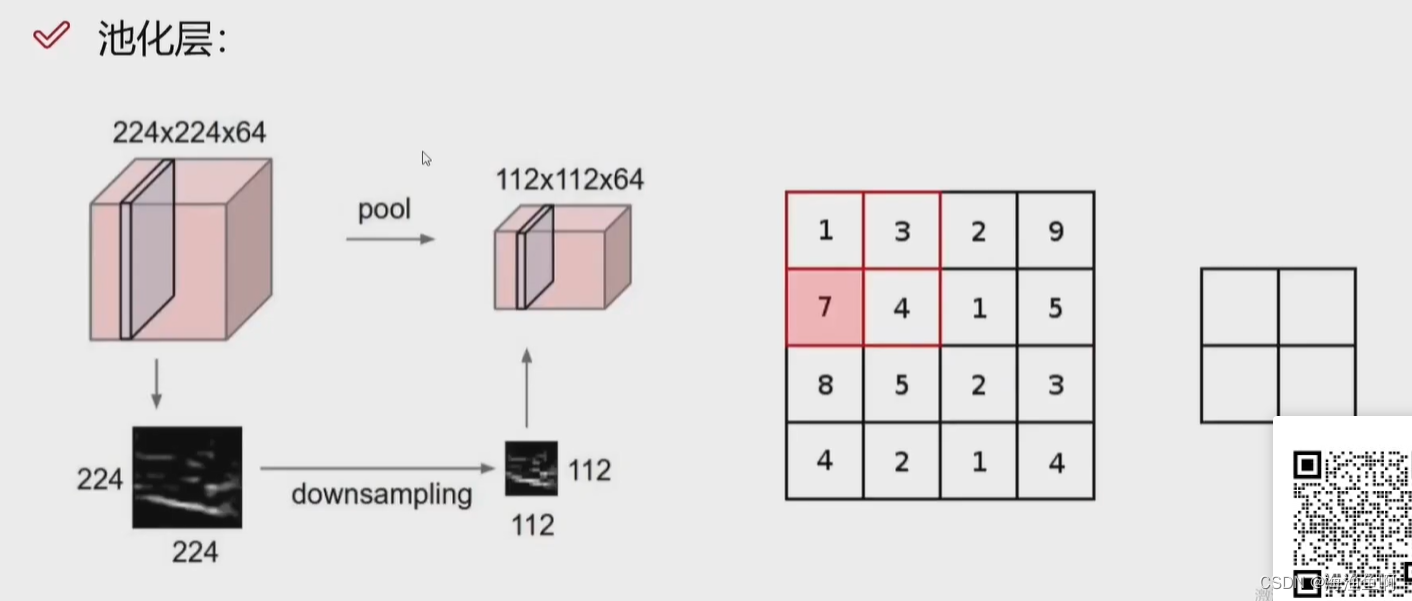
用池化层来浓缩
这里不是一个图(*64了)是一个特征图

压缩了体积
不用被训练
数值越大的特征,越重要
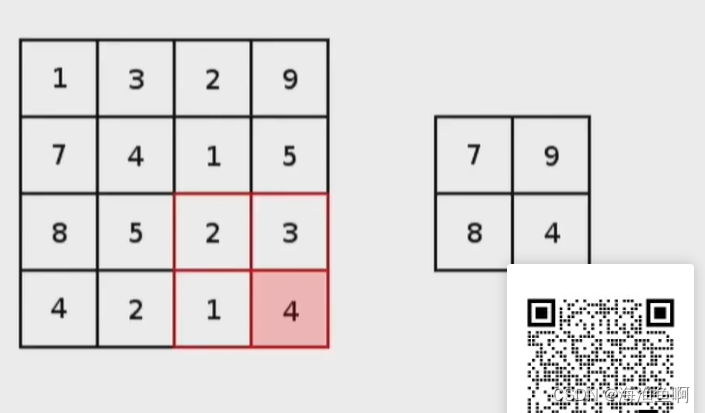
这里就是最大池化

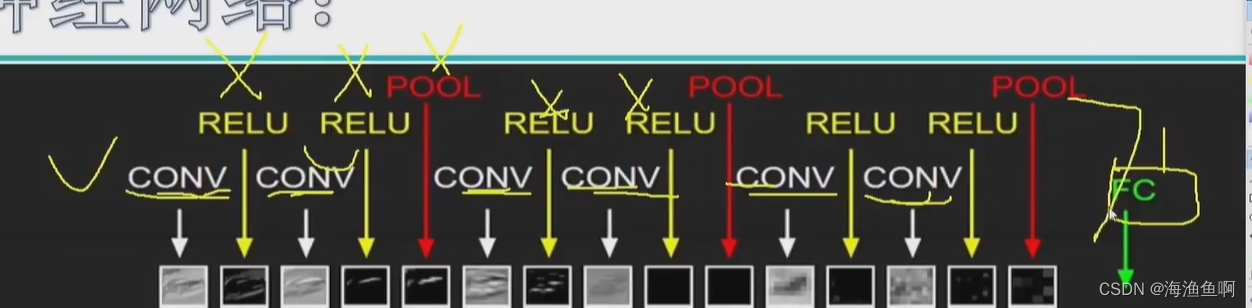
参数不更新,没权重的,不是一层
这里总共7层
RELU是激活层

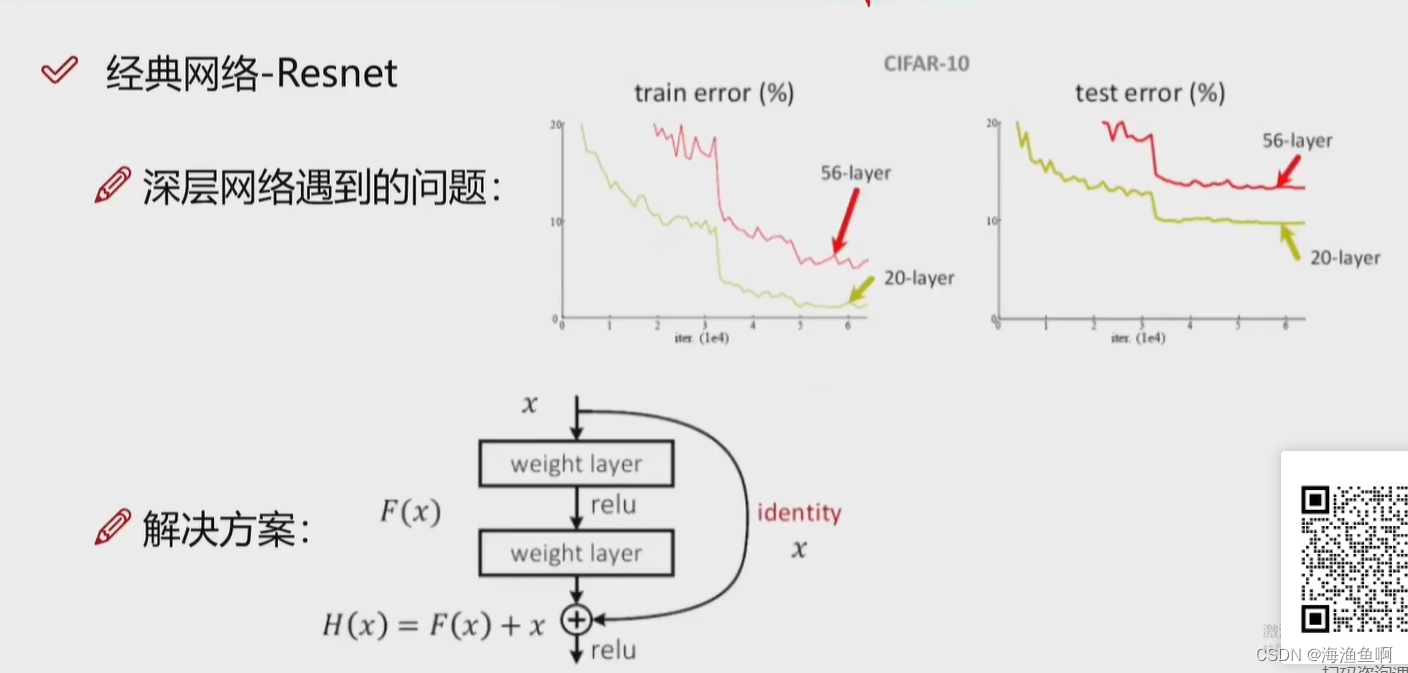
x轴是迭代次数,y轴是错误率
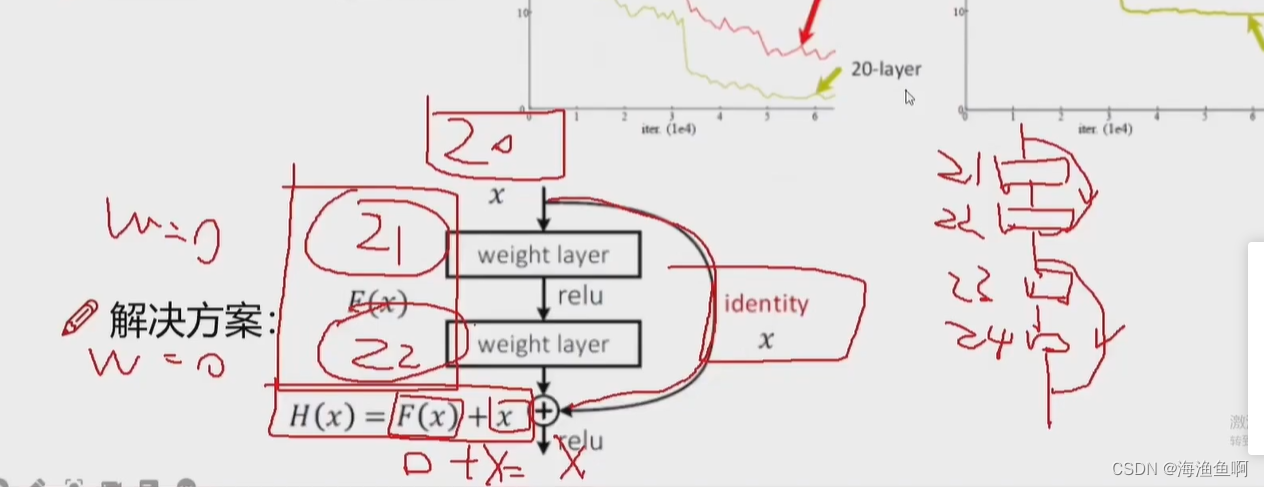
至少不比原来差

![nginx设置重定向跳转后ip:[端口]/abc变成ip/abc而报错404](https://img-blog.csdnimg.cn/img_convert/05037283ea87ef2337b896e3b89aee14.png)




![[数据结构] 深入理解什么是跳表及其模拟实现](https://img-blog.csdnimg.cn/3ca27e8a0b63461ca39cd5453e1b0491.png#pic_center)