(1)解释器
解释源程序时不生成独立的目标代码,源程序和解释程序都参与到程序执行中。
(2)编译器
编译时生成独立的目标代码,运行时是运行与源程序等价的目标程序,源程序不参与执行。
阶段补充:
两者都可以用高级语言编写,且处理源程序时都会进行优化。
程序设计语言基本成分:数据、运算、控制、传输。
运行时变量值可以改变、常量值不能改变。
左结合/右结合:从左向右/从右向左运算。
程序中数据有类型的作用:便于分配存储单元、便于对数据对象进行检查、便于规定取值范围及可执行的运算。
运算优先级越高越先算。
(3)控制结构
顺序结构、循环结构、选择结构
(4)函数
函数定义有两部分:函数首部和函数体。
参数调用有两种形式:值调用和引用调用,值调用时实参将值传递给形参,参数可以是变量、常量和表达式;引用调用时,实参将地址传递给形参,因为参数必须有地址,所以参数不能为常量和表达式,但形参实参可以双向传递。
(5)编译、解释程序流程

编译:词法分析、语法分析、语义分析、中间代码生成、优化、目标代码生成,下划线的两步可省略,但整个流程顺序不可更改。
解释:词法分析、语法分析、语义分析,整个过程不可省略、不可更改顺序。
符号表:会不断收集、记录和使用源程序中一些相关符号的类型和特征等信息,从而辅助语义检查和代码生成。
词法分析:将源程序看为从上到下、从左到右的多行字符串,按“单词”为单位识别,源程序为输出,以二元组记号流(单词种别+单词值)输出。主要作用是分析构成程序的字符以及由字符按照构成规则构成的符号是否符合规则。
语法分析:输入记号流,输出语法树,作用是根据语法规则,将单词符号序列分解为各类语法单位。可以发现所有语法错误,如果构不成语法树,说明语法有误。
语义分析:作用是进行类型分析和检查,检查源程序是否有静态语义错误,如整除取余只能对整数进行。动态语义错误在运行时才能发现。
目标代码生成:该阶段工作与具体机器息息相关,寄存器的分配处于此阶段。
动态语义错误:只有在程序运行时才能检查出来。
中间代码:常见类型有后缀式、三地址码、三元式、四元式、树、图等;其生成与具体机器无关,可以将不同平台的高级语言程序翻译成同一种中间代码,从而跨平台;有利于提高与机器无关的优化和可移植性。
(6)正规式

(7)有限自动机
词法分析的工具,能够正确的识别正规式。

确定的有限自动机(DFA):对于每一个状态,在识别某一字符后,转移的状态是确定的。
不确定的有限自动机(NFA):转移后的状态是不确定的。
特殊状态含义:a,b(识别a或b); (什么都不需要识别就可以转移)
(什么都不需要识别就可以转移)
一个状态既可以是初态又可以是终态,识别成功时必须停留在终态。
(8)上下文无关文法
由开始符号组成的表达式按规则推导为由终结符号组成的表达式,有开始符号、产生式集合和终结符号组成。程序设计中大多数语法设计都可以用上下文无关文法表示。
(9)中缀、后缀表达式(逆波兰表达式)
符号在中(a+b)、符号在后(ab+),按优先级计算。
中缀转后缀如(优先级相同从右向左):




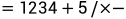
后缀转中缀时,将上述计算结果从左到右,遇到数字就入栈,遇到符号就出栈。
(10)语法树中序、后序遍历
中序遍历(左根右)得到中缀式,后序遍历(左右根)得到后缀式。
阶段补充:
对目标程序反编译无法得到源程序,只能转换成功能上等价的汇编程序。
脚本语言是动态语言,结构可改变,用解释方法实现,执行效率低。
编译时为变量分配的是逻辑地址、运行时分配的是物理地址。
正规集用正规式描述,用有限自动机识别。
c++程序执行前的流程:预处理、编译、汇编、链接