机器学习基础与相关名词
- 什么是机器学习
- 监督学习与非监督学习
- Classification And Regression
- Clustering
- Model and Function
什么是机器学习
机器学习是计算机发展到一定阶段的必然产物。相比于19世纪一个房间大小的计算机,当前的计算机更便携,性能更强,算力充足,在充足的算力的支撑下,我们希望计算机能够自己学习、自己思考,但是对于现在人类的科技来说不可能。所以现在的人工智能,机器学习,其实都是因为大量的数据与强大的算力作为支撑。
通俗理解上,当今世界人工智能就是对大量数据的分析处理。 e . g . e.g. e.g. 人类计算一道简单计算题可能需要几秒钟,但是计算机可以在几秒钟内计算成千上万道计算题,这个就体现了强大的算力,强大的算力,搭配上算法,就会使得计算机拥有非常丰富的 “经验” 而这些经验,就是机器学习、深度学习等诸多算法最想得到的宝贝核心。
大量的数据为什么也很重要呢?试想,再聪明的人要是没有后天的培养也不会成为人才。大量的数据就相当于题海战术一样,强大的算力使得计算机可以在短时间内做出人类甚至一辈子做不完的题目。这个就是现阶段的机器学习。
当然,我们学习人工智能所憧憬的机器学习当然机器可以独立思考,可以独立学习,但是这些,我认为需要人类生物学的进步,对于人类大脑的研究,对于人类怎样学习的发掘,最终应用到实际中方才能使得机器有“灵魂”。
监督学习与非监督学习
监督学习 Supervised Learning;
非监督学习 Unsupervised Learning;
监督学习与非监督学习最大的区别就是一个 有label (监督学习) 另一个 没有label (非监督学习)。我认为要是想彻底理解什么是监督学习与非监督学习,不妨继续往下看我的博文。不过我可以尝试举例让你了解一下什么是监督学习与非监督学习。
e
.
g
.
e.g.
e.g.
监督学习:
让机器去学习并判断出我的房子可以卖多少钱;(监督学习 - Regression)
让机器去学习并判断图片中是狗还是猫;(监督学习 - Classification)
非监督学习:
给一些关于用户的数据,让机器去自动将顾客分为很多类。(非监督学习 - Clustering)
Classification And Regression
Classification 分类:让机器去根据很多条件判断其属于哪个类,其输出内容为类;
Regression 回归:让机器去根据很多条件输出其对应的数值。
e
.
g
.
e.g.
e.g.
分类:去判断这个属于猫还是狗,输出结果为:class(猫),class(狗);
回归:去判断我的房子可以卖多少钱,输出结果为:10000万美元(一个数值)。
Clustering
将Clustering与Classification对比来看,Classification有条件因素,也有结果Label;而Clustering完全没有结果,只有特征,Clustering试图将没有结果的数据按照特征进行分类。
e
.
g
.
e.g.
e.g.
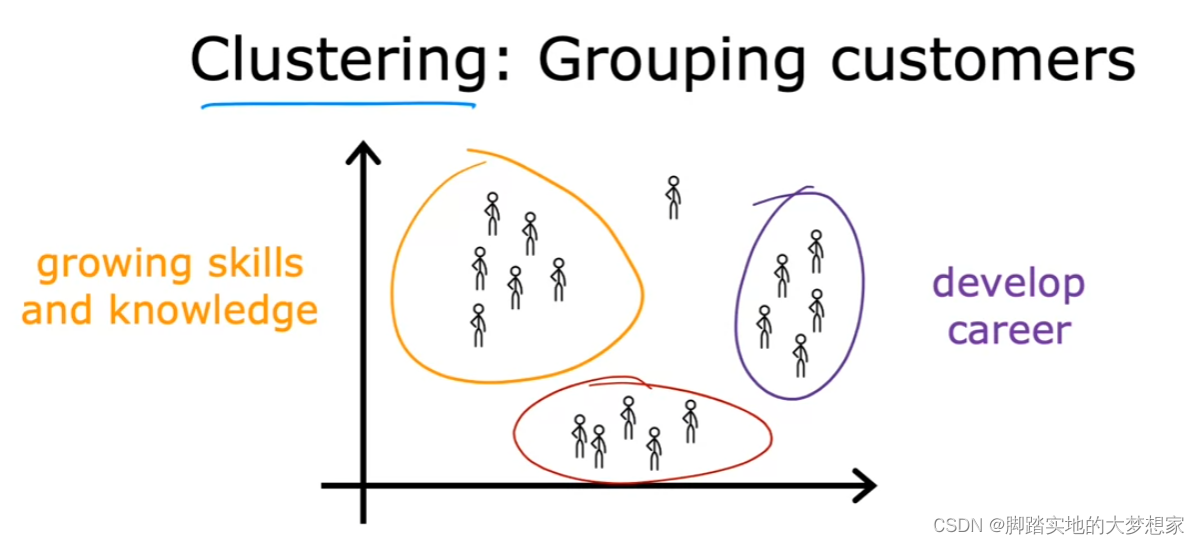
Clustering (非监督学习)
一开始没有男女之分,只有当很多人发现了男人的特征,女人的特征各不相同后,按照特征将人类分为了男女。
Classification (监督学习)
我们给机器很多张猫的图片,让机器进行分析,同时我们也给出这张图片的Label,即"猫"。这种在训练时,告诉特征对应结果的就是监督学习,而训练时不告知其结果,试图让其找不同从而分类的则是非监督学习。
F
i
g
.
Fig.
Fig. Clustering: Grouping Customers from ML of Andrew Ng
Model and Function
为了理解这个概念,我试图从一个吴恩达老师的案例阐述:
e
.
g
.
e.g.
e.g.
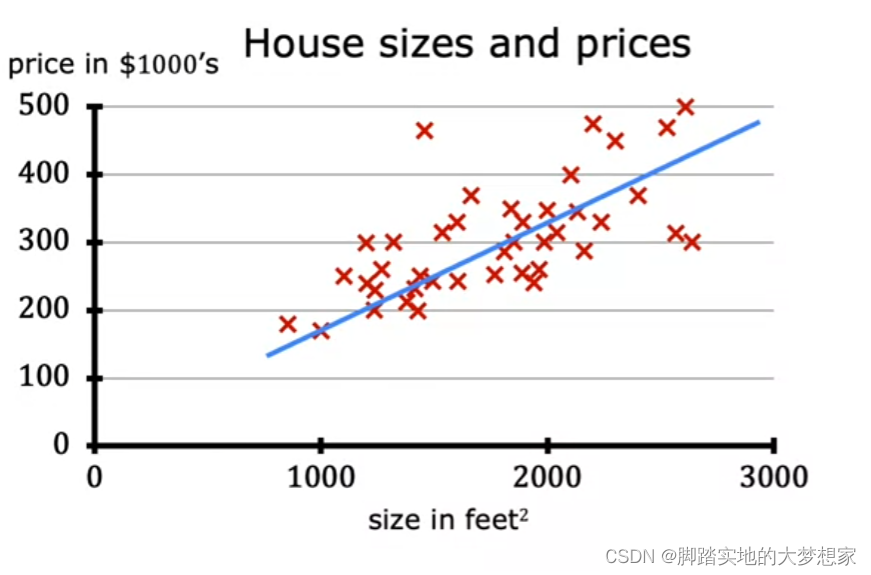
假设你要卖房子,想知道自己的房子可以卖多少,你从网上找到了很多条之前卖出的数据,其中有一个图如下:横坐标为房子的大小,纵坐标为卖出的价格,每个红色的X都是一次买卖交易。而这条蓝色的线,就是一条试图找到房子大小与房价关系的函数function。
假设我们买卖房子从不看其他因素(地段,附件商圈等),我们只按房子的大小来交易,那么我有一个1500 feet^2 的房子,差不多可以卖多少钱?根据横纵坐标得到差不多280,000左右。在这个房价预估中,我们建立了一个价格与房间大小的模型(Model),并且构建了关系函数(Function),从而我们可以预估出房子交易差不多的价格。
F
i
g
.
Fig.
Fig. Regression: Predicting House Prize of Size from ML of Andrew Ng
更新至2023.2.15