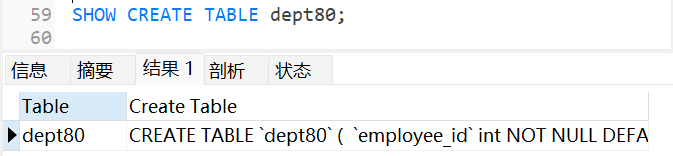
本章继续我们的爬虫教程,爬什么呢 ,还是斗图,娱乐性的东西,为什么要爬?
因为我图库空了,发现这个网址的图库还是很丰富的。
「注意:如下文,是封装后拆分的,所以详情参照源码」
因此,想了想,可以造它。

废话少说,开造!
老规矩先看地址: https://www.fabiaoqing.com/tag

再看网页,Ctrl + u

一目了然,那些事需要的属性值
如果你不行~嗯哼,那就F12或者检查元素
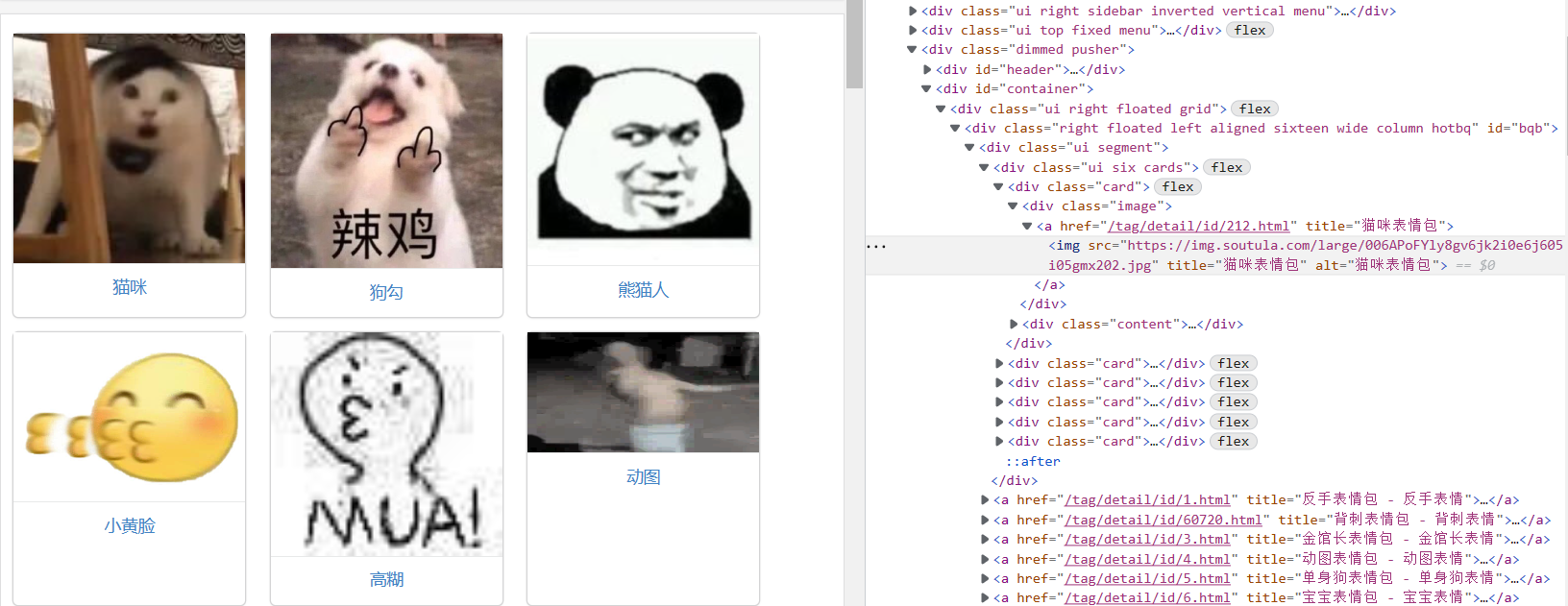

然后接下来,看定位元素
index_url = self.URL + '/index/page/1.html'
request = requests.get(url=index_url, headers=self.HEADERS).text
"""使用bs4定位全部的div内的href以及title"""
soup = BeautifulSoup(request, 'lxml')
get_href = soup.find(id='container').find(class_='ui segment').find_all(class_='content')
for hrefs in get_href:
div_string = hrefs.a.string
div_href = hrefs.a.get('href')
小小的试验一下。这里只锁定第一页,因为页数太多了,造完估计网页也崩了,不想进去,那就准备好money,不然就下手轻点!
好了,这里之锁定了部分,那么剩下的呢?剩下的我们换个定位方式
x_html = etree.HTML(request)
get_a_href = x_html.xpath('//*[@class="ui segment"]/a/@href')
get_a_title = x_html.xpath('//*[@id="bqb"]/div/a/div/text()')
for a_hrefs, a_titles in zip(get_a_href, get_a_title):
print(a_hrefs,a_titles)
没什么太大的问题,那么继续。
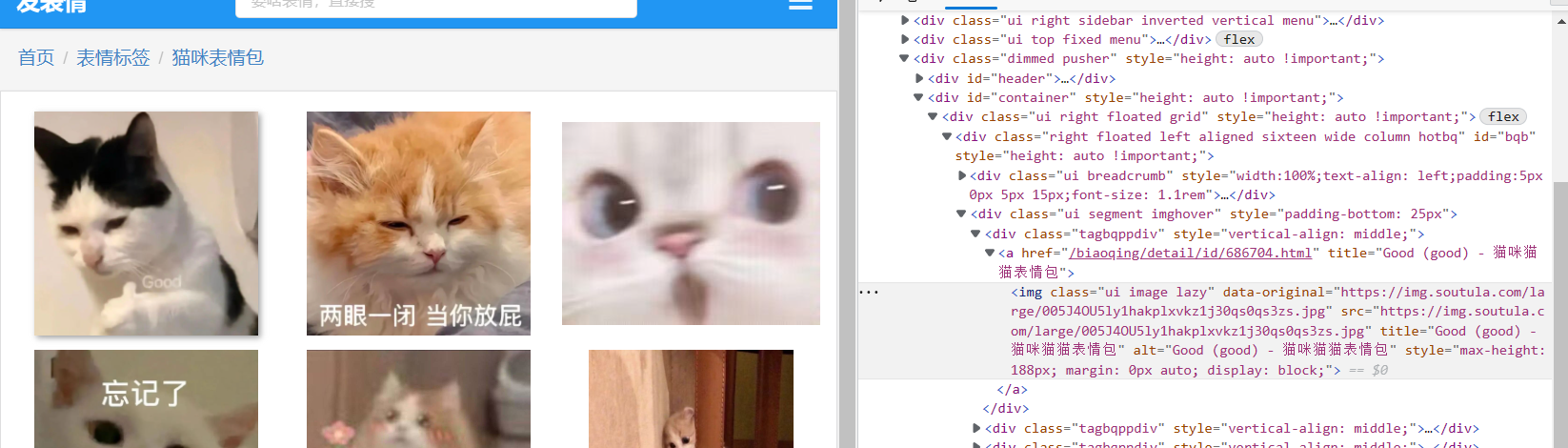
随便点个图,进去就会发现还有N多的图,N多页,浅浅算一下主页中分页300页 * 分页中还有300页 * 一页有8张图。嗯哼,自己算吧。
进来之后你会发现获取的图片地址还要再获取一次,所以我们还是需要再次发起请求
request = requests.get(url=value, headers=self.HEADERS).text
value_html = etree.HTML(request)
div_img_href = value_html.xpath('//*[@id="bqb"]/div[2]/div/a/img/@data-original')
div_img_title = value_html.xpath('//*[@id="bqb"]/div[2]/div/a/img/@title')
for img_hrefs, img_titles in zip(div_img_href, div_img_title):
get_img(img_hrefs, self.HEADERS, img_titles)
嗯哼,那么接下来,我们又不需要爬取全部,怎么办呢?
我们手动输入一个字符串,然后进行获取。
try:
name = input("请输出你要查找的表情包名称,例如:猫咪\n")
print("恭喜你。有这个表情包!")
Y_N = input("是否要爬取,请输入Y or N \n")
if Y_N == 'y' or 'Y':
return name
else:
print("害~不得劲儿,居然不爬!")
except:
print("没有你要找的表情包名称")
剩下的就是运行程序了,一起看看运行效果:

源码位置:https://gitee.com/qinganan_admin/reptile-case.git
文件名是:new_get_pic.py别看错了!!!