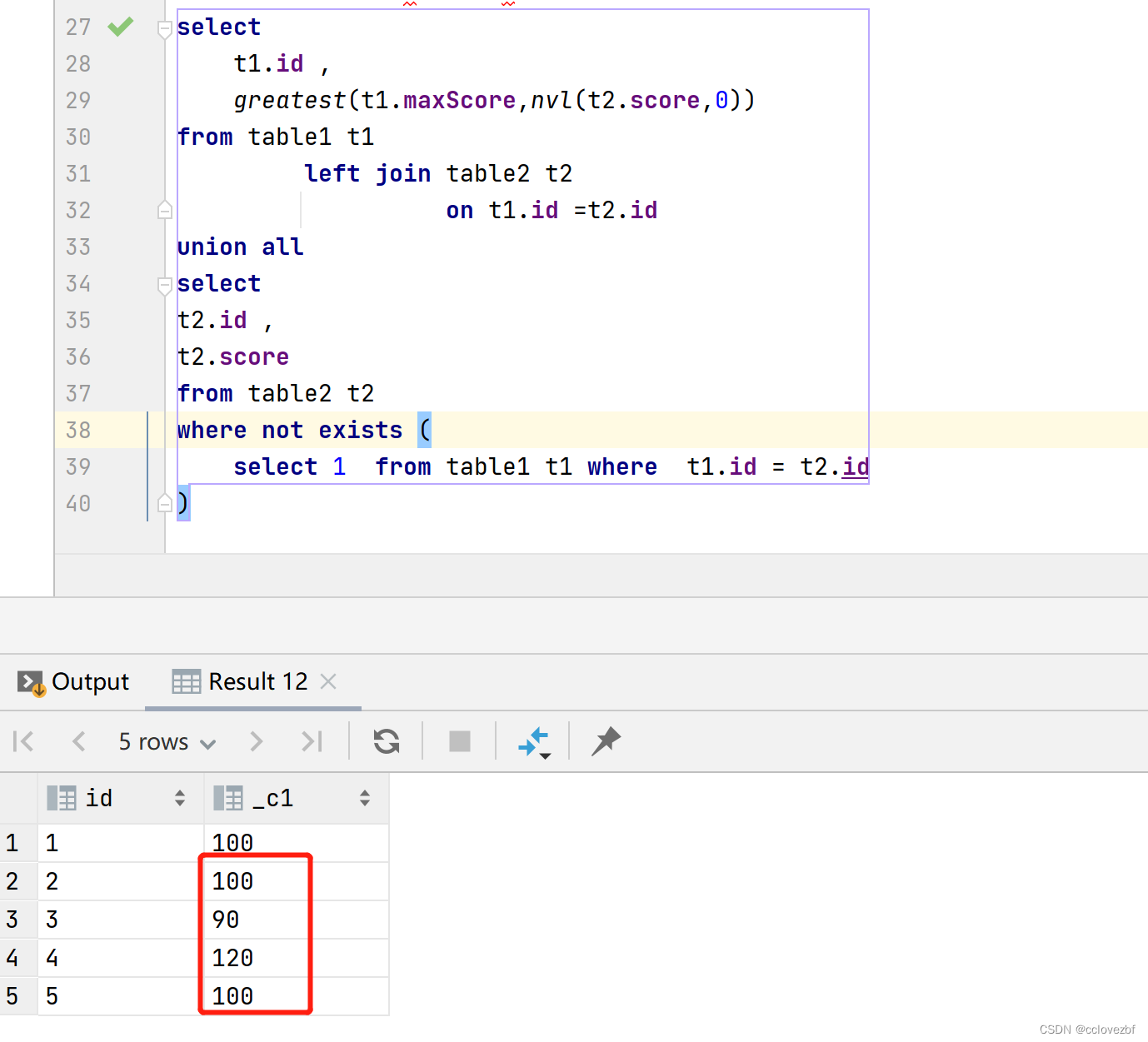
create database cc_test; use cc_test; table1 可以理解为记录学生最好成绩的表。 table2可以理解为每次学生的考试成绩。 我们要始终更新table1的数据 create table table1 ( id string , maxScore string ); create table table2 ( id string , score string ); insert into table1 values (1,100), (2,100), (3,100), (4,100); insert into table2 values (2,100), (3,90), (4,120), (5,100); -----注意这里2重复 3score减少 4score增加 . 5属于新增数据 insert overwrite table1 select t1.id , greatest(t1.maxScore,nvl(t2.score,0)) from table1 t1 left join table2 t2 on t1.id =t2.id union all select t2.id , t2.score from table2 t2 where not exists ( select 1 from table1 t1 where t1.id = t2.id )----------------------------------或者下面这种写法
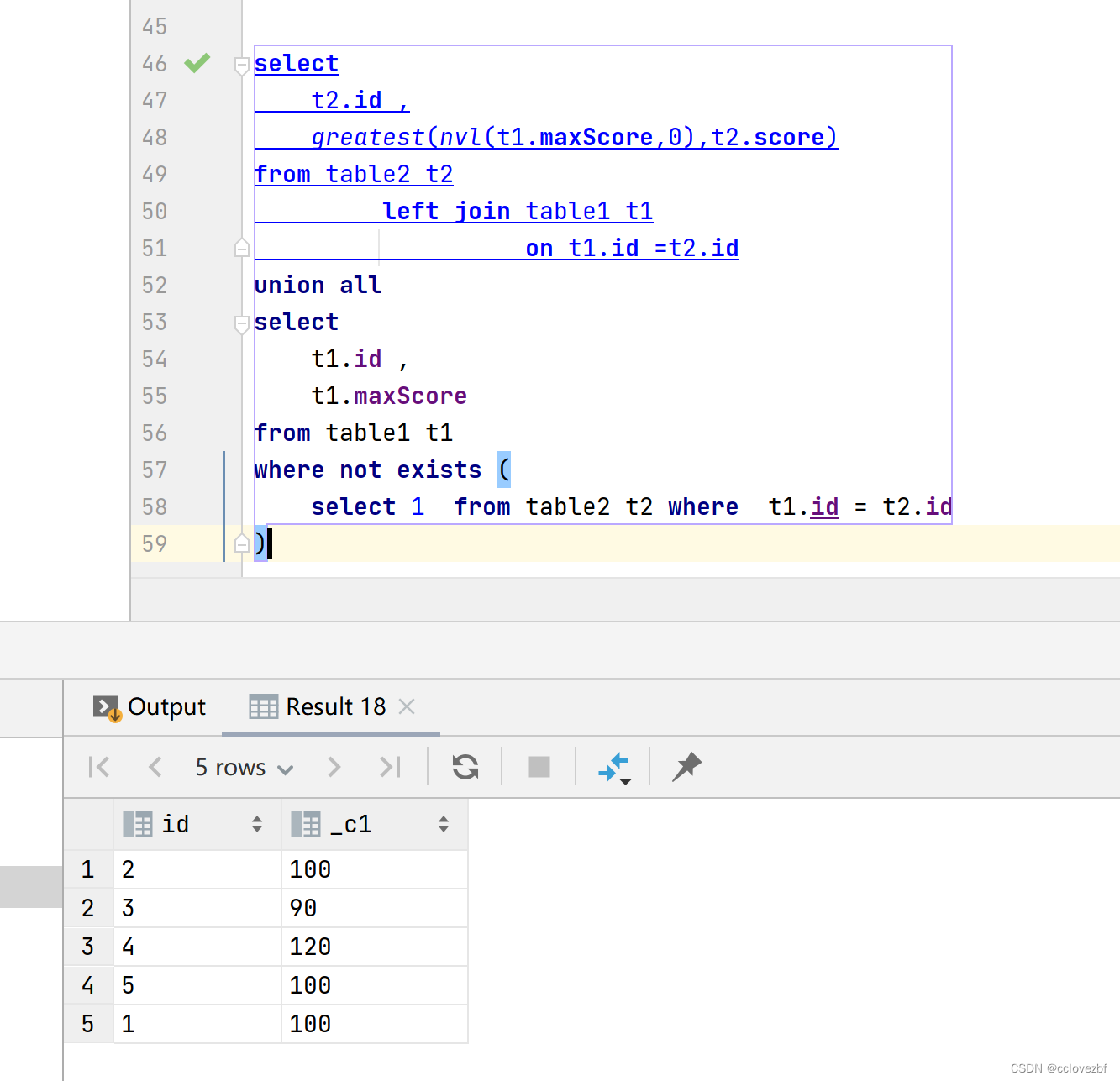
select t2.id , greatest(nvl(t1.maxScore,0),t2.score) from table2 t2 left join table1 t1 on t1.id =t2.id union all select t1.id , t1.maxScore from table1 t1 where not exists ( select 1 from table2 t2 where t1.id = t2.id )
两个的最后查询结果是ok的。
-------------------------------------------------------
最后说下思路。 table1 和table2 两个表
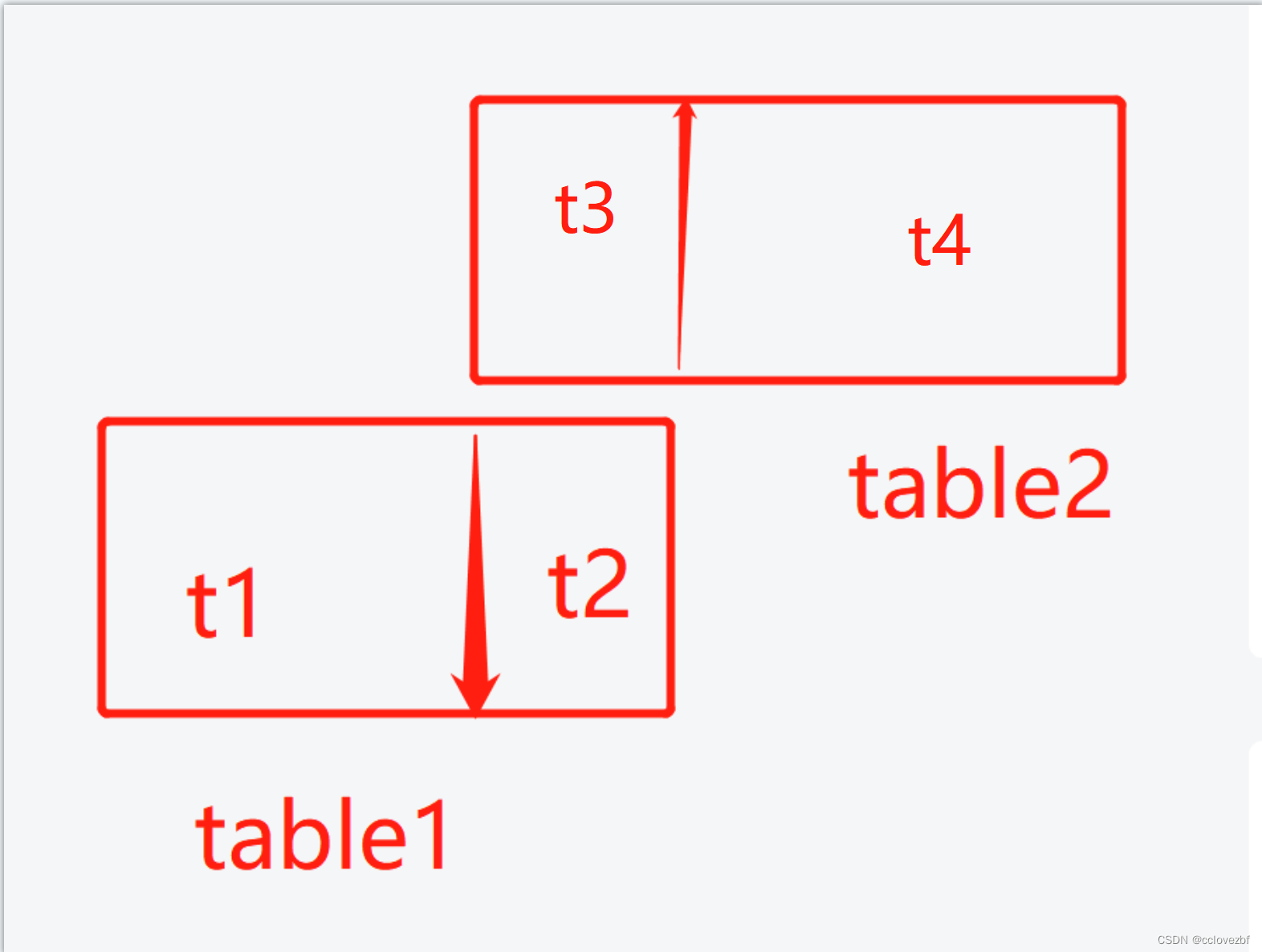
t2 和t3 相当于id重叠的部分。
因为hive没有update ,所以一般update = delete+insert 。但是hive也没有delete。。。
所以oracle的matched not match 的删掉t2 插入t3 然后插入t4。
我们可以看做 插入t1 和插入 t3+t4
也可以看做 插入 t4 和插入 t1+t2
这两种就对应我们上面的两种sql
你以为这就完了吗?怎么可能 就这么lowb的结束了。 我们要追寻更深层次的知识海洋。
两个有什么区别? 我们该选用那种好呢?
一般来说 table1 是远大于table2的。 例如学校每年的学生数量都差不多=table2.但是学校历史学生数据量是很大的=table1.
也不排除 该学校刚刚创立 第一年学生100 人 第二年学生1000人。。
但是一般来说倾向于 table1>>>>table2. 那么那种效率更高呢?
一般来说 外表大 内表小用in 。 外表小内表大用exists。
exists
insert overwrite table1 select t1.id , greatest(t1.maxScore,nvl(t2.score,0)) from table1 t1 left join table2 t2 on t1.id =t2.id union all select t2.id , t2.score from table2 t2 where not exists ( select 1 from table1 t1 where t1.id = t2.id )
in
insert overwrite table1 select t1.id , greatest(t1.maxScore,nvl(t2.score,0)) from table1 t1 left join table2 t2 on t1.id =t2.id union all select t2.id , t2.score from table2 t2 where t2.id not in ( select id from table1 )
join
insert overwrite table1 select t1.id , greatest(t1.maxScore,nvl(t2.score,0)) from table1 t1 left join table2 t2 on t1.id =t2.id union all select t2.id , t2.score from table2 t2 left join table1 t1 on t1.id =t2.id where t1.maxScore is null
个人来说是推荐用exists 和join这两种的