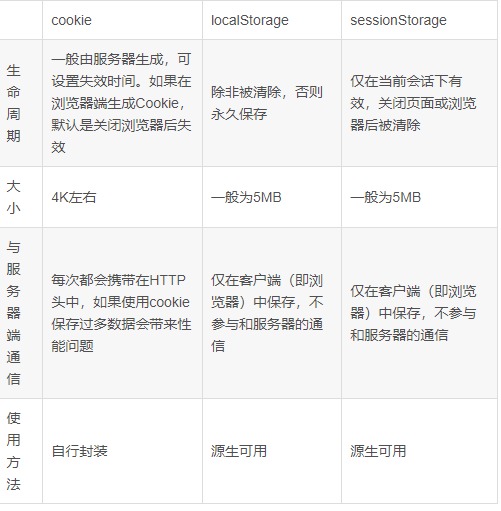
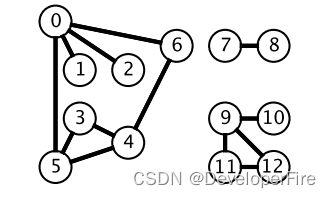
原理部分
代码实现
步骤
数据导入
数据使用开源数据集,便于实现
#数据集
import statsmodels.api as sm
from statsmodels.tsa.stattools import grangercausalitytests
import numpy as np
data = sm.datasets.macrodata.load_pandas()
demo = data.data
稳定性检验
方法与通用的时间序列方法相同
demo[['realgdp','realcons']].plot()
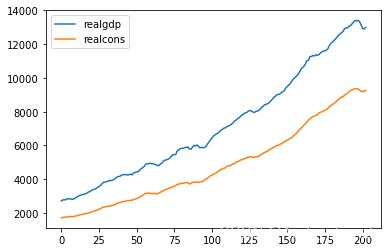
from statsmodels.tsa.stattools import adfuller
print(adfuller(demo['realgdp']))
(1.7504627967647173, 0.9982455372335032, 12, 190, {'1%': -3.4652439354133255, '5%': -2.8768752281673717, '10%': -2.574944653739612}, 2034.517123668382)
差分
demo['diff1_realgdp'] = demo['realgdp'].diff(1).fillna(0)
demo['diff1_realcons'] = demo['realcons'].diff(1).fillna(0)
demo[['diff1_realgdp','diff1_realcons']].plot()
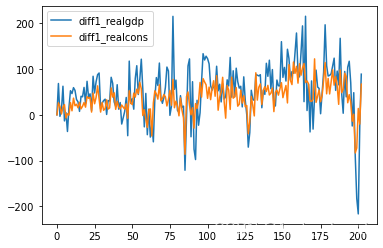
再次检验单位根
print(adfuller(demo['diff1_realgdp']))
print(adfuller(demo['diff1_realcons']))
(-6.287524437690158, 3.66693821207135e-08, 1, 201, {‘1%’: -3.4633090972761744, ‘5%’: -2.876029332045744, ‘10%’: -2.5744932593252643}, 2034.8610305811367)
(-4.206384895591229, 0.0006426930660370949, 3, 199, {‘1%’: -3.4636447617687436, ‘5%’: -2.8761761179270766, ‘10%’: -2.57457158581854}, 1793.118209620634)
协整检验
from statsmodels.tsa.stattools import coint
print(coint(demo['diff1_realgdp'], demo['diff1_realcons']))
(-14.507179284872553, 5.182509395533684e-26, array([-3.95147899, -3.36654523, -3.0655127 ]))
p=5.182509395533684e-26 < 0.05,说明在长期是存在相关性的
格兰杰检验
Granger causality test的思想
如果使用时间序列X和Y的历史值来预测Y的当前值,比仅通过Y的历史值来预测Y的当前值得到的误差更小,并且通过了F检验,卡方检验,则X对Y的预测是有一定帮助的。
了解了Granger causality test的思想之后会发现,其实Granger causality test最多能推断出X对Y的预测是有一定帮助的,至于是否能说X和Y是因果关系,则不一定。
from statsmodels.tsa.stattools import grangercausalitytests
grangercausalitytests(demo[['realgdp','realcons']], maxlag=2)
Granger Causality
number of lags (no zero) 1
ssr based F test: F=0.1851 , p=0.6675 , df_denom=199, df_num=1
ssr based chi2 test: chi2=0.1879 , p=0.6646 , df=1
likelihood ratio test: chi2=0.1878 , p=0.6647 , df=1
parameter F test: F=0.1851 , p=0.6675 , df_denom=199, df_num=1
Granger Causality
number of lags (no zero) 2
ssr based F test: F=22.9218 , p=0.0000 , df_denom=196, df_num=2
ssr based chi2 test: chi2=47.0132 , p=0.0000 , df=2
likelihood ratio test: chi2=42.2456 , p=0.0000 , df=2
parameter F test: F=22.9218 , p=0.0000 , df_denom=196, df_num=2
函数解读:
该方法接收一个包含2列的2维的数组作为主要参数:
- 第一列是当前要预测未来值的序列A,第二列是另一个序列B,该方法就是看B对A的预测是否有帮助。该方法的零假设是:B对A没有帮助。如果所有检验下的P-Values都小于显著水平0.05,则可以拒绝零假设,并推断出B确实对A的预测有用。
- 第二个参数maxlag是设定测试用的lags的最大值。
我们使用realgdp的数据集做预测,并利用Granger causality检测“realcons”这个序列是否对数据集的预测用。
df_num=1 即滞后一阶时,p>0.05,不能拒绝原假设
df_num=2即滞后二阶时,P值小于0.05,通过检验,也就是拒绝了realcons不是引起realgdp格兰杰变化的原因,即realcons是引起realgdp格兰杰变化的原因
同理可以查看
realgdp是否是引起realcons格兰杰变化的原因