一、linux用户态内核态内存结构
对于32位的linux操作系统,系统为每个进程分配0~4G的内存空间,而64位系统则更大:
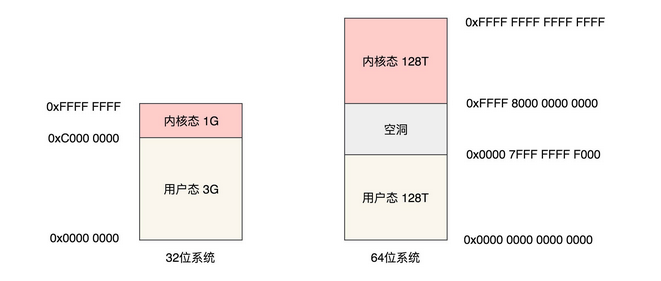
linux内存空间地址范围
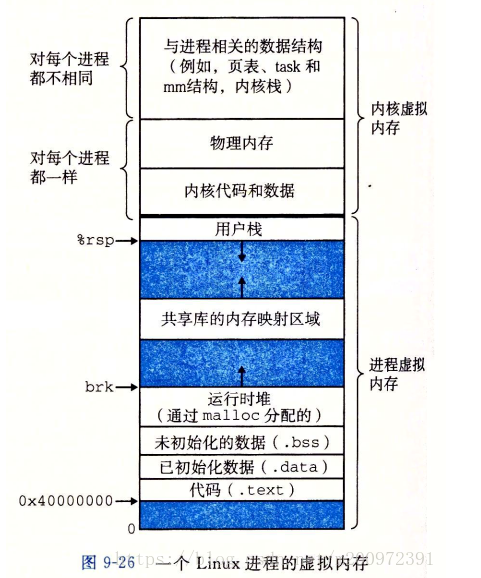
可见Linux的内存分配规则:
二、总体分配规则
1、用户态在低地址,内核态在高地址。
2、 64位的系统,目前一般使用了48位。用户态高16位都是0, 内核态高16位一直是FFFF。 都用剩下的48位来表示128T。1T==1024*1024*1024*1024。 剩下的8位直接上也只用了7位, 第48位来表示是内核空间还是用户空间。加一起 48位表示的就是128T。
其中,0x0000000000000000~0x00007fffffffffff 表示用户空间, 0xFFFF800000000000~ 0xFFFFFFFFFFFFFFFF 表示内核空间,共提供 256TB(2^48) 的寻址空间。
这两个区间的特点是,第 47 位与 48~63 位相同,若这些位为 0 表示用户空间,否则表示内核空间。所以上面那个话64位的内存分布图有点问题。用户态128T的最高地址不对。
三、用户空间分配规则
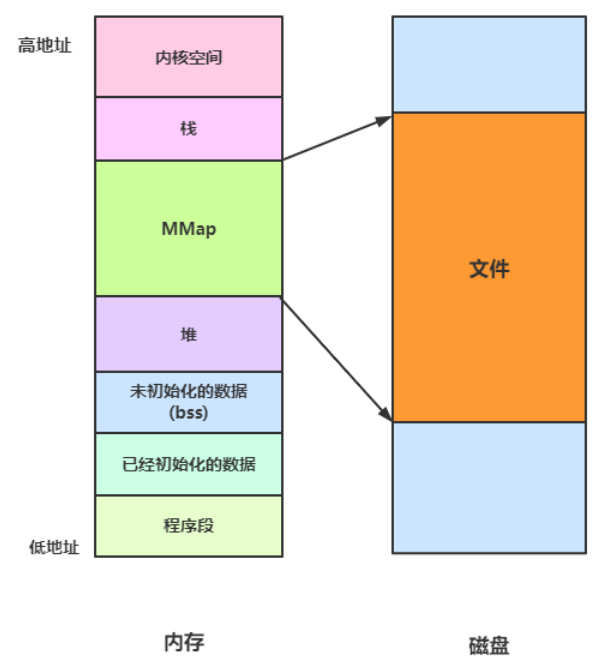
1、用户空间堆申请空间往上涨,栈申请空间往下涨,栈的地址肯定比堆的地址高。 然后栈和堆中间还有一段区域用来共享:文件映射, mmap使用。
文件映射,用于映射共享库等程序运行必须的文件,同时该区域可用于申请较大的内存

2、用户空间运行时动态申请内存
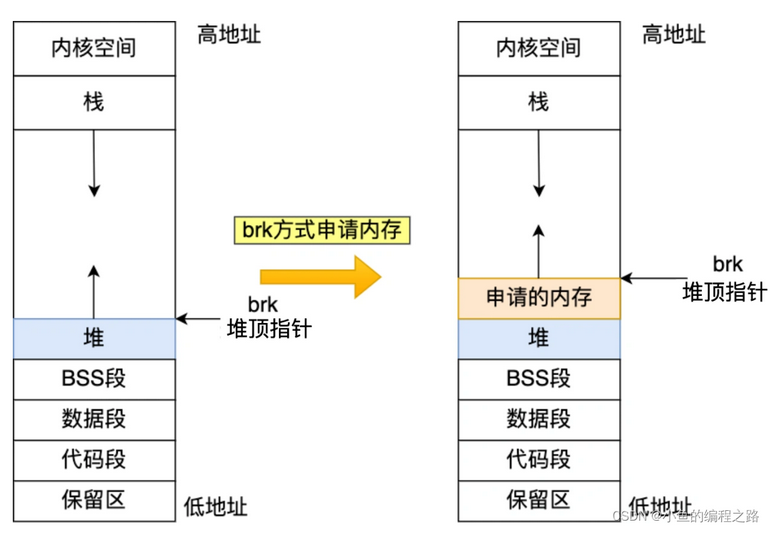
malloc的分配内存有两个系统调用,一个brk,一个mmap,brk是将.data的最高地址指针_edata往高地址走,mmap则是在进程的虚拟地址空间(在堆和栈之间的内存映射区域)找一块空间。这两种都是没有实际分配物理内存,只有当真正使用的时候才发生缺页中断,分配物理内存。
一般情况下,使用malloc,如果小于128k,则使用brk分配,如果大于128k,则使用mmap在堆和栈之间找一个空闲空间分配。
3、用户空间虚拟地址中各段内容

A.正文段。这是由cpu执行的机器指令部分。通常,正文段是可共享的,所以即使是经常执行的程序(如文本编辑程序、C编译程序、shell等)在存储器中也只需要有一个副本,另外,正文段常常是只读的,以防止程序由于意外事故而修改器自身的指令。
B.初始化数据段。通常将此段称为数据段,它包含了程序中需赋初值的变量。例如,C程序中任何函数之外的说明:
int maxcount = 99;(全局变量)
C.非初始化数据段。通常将此段称为bss段,这一名称来源于早期汇编程序的一个操作,意思是"block started by symbol",在程序开始执行之前,内核将此段初始化为0。函数外的说明:
long sum[1000];
使此变量存放在非初始化数据段中。 注意这个地方初始化和非初始化的区别。
D.栈。自动变量以及每次函数调用时所需保存的信息都存放在此段中。每次函数调用时,其返回地址、以及调用者的环境信息(例如某些机器寄存器)都存放在栈中。然后,新被调用的函数在栈上为其自动和临时变量分配存储空间。通过以这种方式使用栈,C函数可以递归调用。
E.堆。通常在堆中进行动态存储分配。由于历史上形成的惯例,堆位于非初始化数据段顶和栈底之间。
四、内核空间分配规则
1、内核空间结构
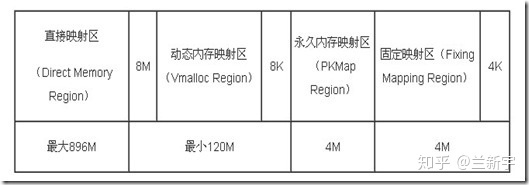
内核空间分为几大区域
直接映射区:分配的虚拟地址映射到连续的物理地址上
动态映射区:分配的虚拟地址映射到物理地址是不连续的
永久内存映射区:
固定映射区:虚拟地址是固定的,而被映射的物理地址并不固定。采用固定虚拟地址的好处是它相当于一个指针常量(常量的值在编译时确定),指向物理地址,如果虚拟地址不固定,则相当于一个指针变量。指针常量相比指针变量的好处是可以减少一次内存访问,因为指针变量需要通过内存访问才可以获得指针本身的值。
2、直接映射区
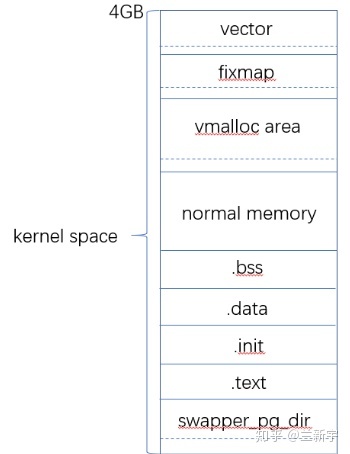
在3GB~(3GB+896MB)这段直接映射区,包含了内核初始化页表swapper_pg_dir,内核镜像等。内核也是由一个elf文件(比如vmlinux)加载启动的,加载后也有text段,data段,bss段等。可通过cat /proc/iomem命令查看kernel的text段,data段和bss段的内存分布。
normal memory区也属于直接映射区,用于kmalloc()的内存分配,kmalloc()返回的是虚拟地址,但分到的内存在物理地址上是连续的。
2、动态映射区
动态映射区即上图vmalloc area区,对应下图VMALLOC_START和VMALLOC_END之间的区域,动态内存映射区和直接映射区(直接映射的物理内存)之间有8MB的间隔。这部分间隔不作任何地址映射,相当于一个空洞,主要用做安全保护,防止不正确的越界内存访问,因为此处没有进行任何形式的映射,如果进入到空洞地带,将会触发处理器产生一个异常。
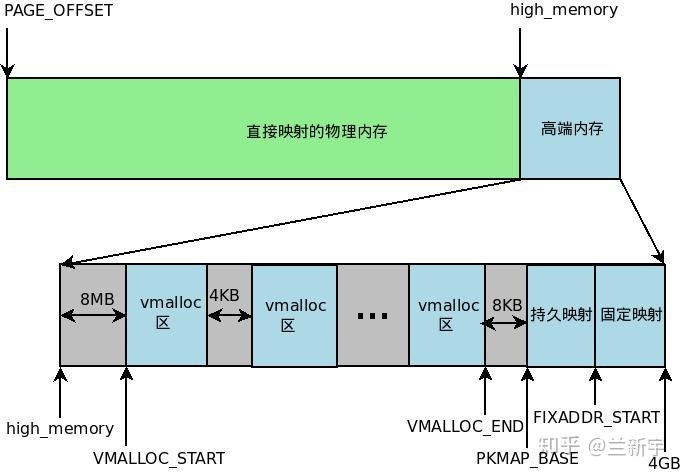
动态映射区主要供vmalloc()分配内存,同kmalloc()相比,vmalloc()分配的内存只能保证在虚拟地址上连续,不能保证在物理地址上连续。在物理地址上连续有什么好处呢?
- 可以更好的根据空间局部性原理利用cache,增加数据访问的速度。
- 由于kmalloc()基于的是直接映射,其虚拟地址和物理地址之间是一个固定的偏移,因此可以利用既有的内核页表,而不需要为新的地址增加新的page table entries,因此其分配速度也比vmalloc()更快。
- 因为物理地址不连续,通过vmalloc()获得的每个page需要单独映射,而TLB资源很有限,因此这将比直接映射造成更严重的TLB thrashing问题。
用户空间的进程通过malloc()分配内存时,获得的只是虚拟地址的使用权,要等到真正往这块内存写数据了,才会获得对应的物理页面,而且是用多少给多少,而不是要多少给多少。内核空间的vmalloc()不一样,申请的物理内存立刻满足。
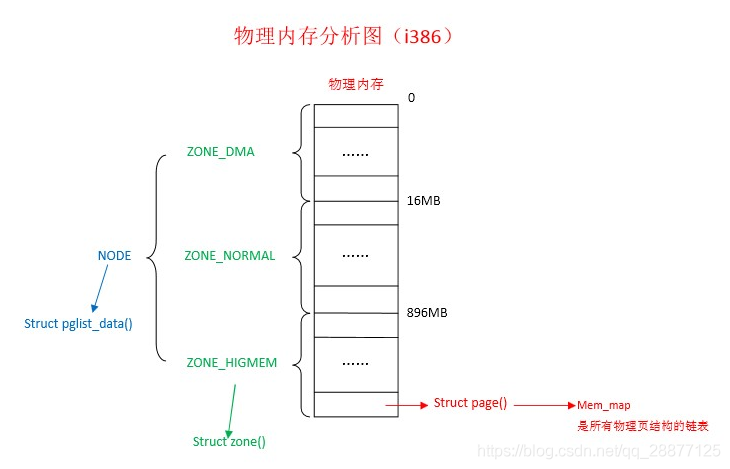
五、真实物理内存
网上有ZONE_DMA、ZONE_NORMAL、ZONE_HIGMEM的说法,主要针对真实物理内存的分区
参考:
linux 内存空间(三) 内存地址范围和例子
linux中的内核地址空间