1. “控制器”思想
kube-controller-manager 是一系列控制器的集合,这些控制器被放在 Kubernetes 项目的 pkg/controller 目录,这些控制器都以独有的方式负责某种编排功能。它们都遵循一个通用的编排模式——控制循环。
以 Deployment 为例介绍它对控制器模型的实现:
(1)Deployment 控制器从 etcd 中获取所有携带了 app: nginx 标签的 Pod,然后统计它们的数量,这就是实际状态。
(2)Deployment 对象的 Replicas 字段的值就是期望状态。
(3)Deployment 控制器比较两个状态,然后根据结果确定是创建 Pod 还是删除已有的 Pod。
一个 Kubernetes 对象的主要编排逻辑是在对比阶段完成的,这个操作称为调谐(reconcile)。调谐的过程称作调谐循环或者同步循环。
Deployment 定义的 template 字段在 Kubernetes 中有一个专属的名字:PodTemplate。
2. Deployment & ReplicaSet
如果你更新了 Deployment 的 Pod 模板,那么 Deployment 就要遵循一种叫作滚动更新的方式,来升级现有容器。这个能力的实现依赖 Kubernetes 中的一个非常重要的概念:ReplicaSet。
例子:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx-set
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9一个 ReplicaSet 对象是又副本数目的定义和一个 Pod 模板组成的。它的定义其实是一个 Deployment 的一个子集。更重要的是,Deployment 控制器实际上操纵的是 ReplicaSet 对象,而不是 Pod 对象。看下边的 Deployment 定义:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80Deployment、ReplicaSet 和 Pod 的关系如下图所示:
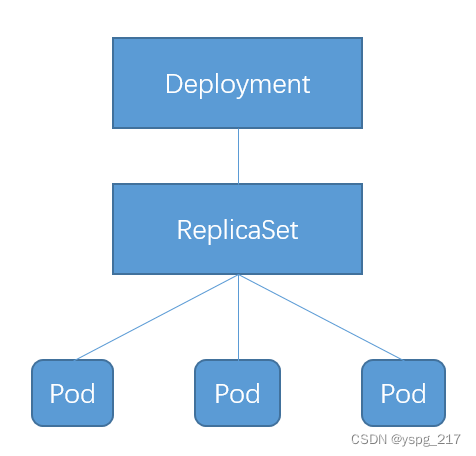
ReplicaSet 负责通过控制器模式保证系统中 Pod 的个数永远等于指定个数。这也是 Deployment 只允许容器的 restartPolicy=Always 的原因:只有在容器保证自己始终处于 Running 状态的前提下,ReplicaSet 调整 Pod 的个数才有意义。在此基础上,Deployment 同样通过控制器模式来操作 ReplicaSet 的个数和属性,进而实现水平扩展/收缩和滚动更新。
水平扩展/收缩非常容易实现,Deployment Controller 只需要修改它所控制的 ReplicaSet 的 Pod 的副本数就可以了,这个指令是 kubectl scale:
kubectl scale deployment nginx-deployment --replicas=4滚动更新的过程如下:
首先创建 Deployment:
$ kubectl create -f nginx-deployment.yaml --record检查这个 Deployment 状态信息:
$ kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 0 0 0 1s这几个字段的含义如下所示:
(1)DESIRED:用户期望的 Pod 副本个数(spec.replicas 的值)。
(2)CURRENT:当前处于 Running 状态的 Pod 的个数。
(3)UP-TO-DATE:当前处于最新版本的 Pod 的个数。所谓最新版本,指的是 Pod 的 Spec 部分与 Deployment 里 Pod 模板里定义的完全一致。
(4)AVAILABLE:当前已经可用的 Pod 的个数,即既是 Running 状态,又是最新版本,并且已处于 Ready(健康检查显示正常)状态的 Pod 的个数。
这个 AVAILABLE 字段描述的才是用户所期望的最终状态。
可以使用以下指令,实时查看 Deployment 对象的状态变化:
kubectl rollout status deployment/nginx-deployment一段时间后,可以看到 Deployment 的 3 个 Pod 进入了 AVAILABLE 状态:
$ kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 3 3 3 20s此时可以查看这个 Deployment 所控制的 ReplicaSet:
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-****** 3 3 3 20s在用户提交了一个 Deployment 对象后,Deployment Controller 会立即创建一个 Pod 副本数为 3 的 ReplicaSet。这个 ReplicaSet 的名字由 Deployment 的名字和一个随机字符串共同组成。这个随机字符串叫作 pod-template-hash。ReplicaSet 会把这个随机字符串加在它所控制的所有 Pod 的标签里,从而避免这些 Pod 与集群里其他 Pod 混淆。
ReplicaSet 的 DESIRED、CURRENT 和 READY 字段的含义和 Deployment 中是一致的。所以,Deployment 是在 ReplicaSet 的基础上添加了 UP-TO-DATE 这个跟版本有关的字段。
这时,修改 Deployment 中的 Pod 模板,就会自动触发“滚动更新”。Deployment Controller 会使用修改后的 Pod 模板创建一个新的 ReplicaSet,这个新的 ReplicaSet 初始 Pod 副本数为 0。随后,Deployment Controller 逐步将旧 ReplicaSet 管理的 Pod 的副本数从 3 变成 0,将新的 ReplicaSet 管理的 Pod 的副本数从 0 变成 3。为了保证服务的连续性,Deployment Controller 会确保在任何时间窗口内,只有指定比例的 Pod 处于离线状态,只有指定比例的新 Pod 被创建出来,这两个值默认都是 DESIRED 值的 25%。这个字段叫 RollingUpdateStrategy,其中 maxSurge 指定的是除 DESIRED 数量外,在一次滚动更新中 Deployment Controller 还能创建多少新的 Pod,而 maxUnavailable 指的是在一次滚动更新中 Deployment Controller 可以删除多少旧的 Pod。这两个配置还可以用百分比表示,表示的是 DESIRED 数量乘以百分比的值。
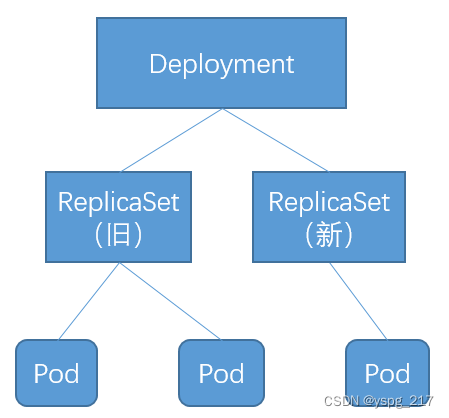
如图所示,Deployment Controller 实际控制的是 ReplicaSet 的数目,以及每个 ReplicaSet 的属性。一个应用的版本对应的正是一个 ReplicaSet,这个版本应用的 Pod 数量由 ReplicaSet 通过它自己的控制器(ReplicaSet Controller)来保证。通过多个这样的 ReplicaSet 对象,Kubernetes 项目就实现了对多个应用版本的描述。
在升级过程中,如果镜像出现错误,新版本的 ReplicaSet 的水平扩展将会停止,其中的 Pod 状态非 READY。旧版本的 ReplicaSet 的水平收缩也停止。这时,使用以下命令就可以回滚到上一个版本:
kubectl rollout undo deployment/nginx-deployment如果想回滚到更早之前的版本,可以先查看历史版本:
kubectl rollout history deployment/nginx-deployment查看具体版本的细节:
kubectl rollout history deployment/nginx-deployment --revision=2回滚:
kubectl rollout undo deployment/nginx-deployment --to-revision=2如果担心每次更新系统都会产生新的 ReplicaSet,导致资源浪费,可以使用一种方法让我们的多次操作只产生一个 ReplicaSet,先执行以下指令:
kubectl rollout pause deployment/nginx-deployment之后就可以随意使用 kubectl edit 或 kubectl set image 修改 Deployment 了,修改之后执行:
kubectl rollout resume deployment/nginx-deploymentDeployment 有一个 spec.revisionHistoryLimit 字段,可以控制历史版本个数。
3. StatefulSet
分布式应用的多个实例之间往往有依赖关系,比如主从关系、主备关系;还有数据存储类应用的多个实例往往会在本地磁盘保存一份数据。这种实例之间有不对等关系,以及实力对外部数据有依赖关系的应用,就是有状态应用。
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.9.1
ports:
- containerPort: 80
name: web这个 YAML 文件和 Deployment 的唯一区别就是多了一个 serviceName=nginx 字段,这个字段的作用就是告诉 StatefulSet 控制器,在执行控制循环时请使用 nginx 这个 Headless Service 来保证 Pod 可解析。
StatefulSet 给它所管理的所有 Pod 的名字进行了编号,这些编号是从 0 开始累加的,不重复。每个 Pod 对应不同的 Headless Service,也就意味着每个 Pod 拥有独一无二的 IP 地址。
StatefulSet 这个控制器的主要作用之一,就是使用 Pod 模板创建 Pod 时对它们进行编号,并且按照编号顺序逐一完成创建工作。而当 StatefulSet 的“控制循环”发现 Pod 的实际状态与期望状态不一致,需要新建或者删除 Pod 以进行“调谐”时,它会严格按照这些 Pod 编号的顺序逐一完成这些操作。通过 Headless Service 的方式,StatefulSet 为每一个 Pod 创建了一个固定并且稳定的 DNS 记录,来作为它的访问入口。
想使用一个 Volume,只需要以下两步:
第一步,定义一个 PVC,声明想要的 Volume 属性:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pv-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi第二步,在应用的 Pod 中声明使用这个 PVC:
apiVersion: v1
kind: Pod
metadata:
name: pv-pod
spec:
containers:
- name: pv-container
image: nginx
ports:
- containerPort: 80
name: "http-server"
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: pv-storage
volumes:
- name: pv-storage
persistentVolumeClaim:
claimName: pv-claim在这个 Pod 的 Volumes 定义中,只需要声明它的类型是 persistentVolumeClaim,然后指定 PVC 的名字,完全不必关心 Volume 本身的定义。
此时,只要创建这个 PVC 对象,Kubernetes 就会自动为它绑定一个符合条件的 Volume。这些符合条件的 PV 来自运维人员维护的 PV 对象:
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-volume
labels:
type: local
spec:
capacity:
storage: 10Gi
rbd:
monitors:
- '10.16.154.78:6789'
- '10.16.154.82:6789'
- '10.16.154.83:6789'
pool: kube
image: foo
fsType: ext4
readOnly: true
user: admin
keyring: /etc/ceph/keyring
imageformat: "2"
imagefeatures: "layering"Kubernetes 就会为我们创建的 PVC 对象绑定这个 PV。
以上边的 StatefulSet 为例,添加一个 volumeClaimTemplates 字段:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.9.1
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi凡是被这个 StatefulSet 管理的 Pod,都会声明一个对应的 PVC,这个 PVC 的定义就来自 volumeClaimTemplates 字段。这个 PVC 的名字会被分配一个与这个 Pod 完全一致的编号。这个自动创建的 PVC 与 PV 绑定成功后就会进入 Bound 状态,这就意味着这个 Pod 可以挂在并使用这个 PV 了。
在创建了 StatefulSet 之后,集群里出现两个 PVC,命名格式都是<PVC 名字>-<StatefulSet 名字>-<编号>,且处于 Bound 状态。
梳理一下 StatefulSet 的工作原理:
首先,StatefulSet 的控制器直接管理的是 Pod。其次,Kubernetes 通过 Headless Service 为这些有编号的 Pod 在 DNS 服务器中生成带有相同编号的 DNS 记录。最后,StatefulSet 还为每个 Pod 分配并创建一个相同编号的 PVC。
4. DaemonSet
DaemonSet 的主要作用是在 Kubernetes 集群中运行一个 Daemon Pod。这个 Pod 有三个特征:
① 这个 Pod 在集群里的每一个节点上运行
② 每个节点上只有一个这样的 Pod 实例
③ 当有新节点加入 Kubernetes 集群后,该 Pod 会自动地在新节点上被创建出来;而当旧节点被删除后,它上面的 Pod 也会相应地被回收。
常用的例子有:
各种网络插件的 Agent 组件、各种存储插件的 Agent 组件、各种监控组件和日志组件必须在每一个节点上运行。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v3.0.0
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers这个 DaemonSet 管理的是一个 fluentd-elasticsearch 镜像的 Pod,功能是通过 fluentd 将 Docker 中的日志转发到 Elasticsearch 中。
可以看到,DaemonSet 跟 Deployment 非常相似,只不过没有 replicas 字段;他也使用 selector 选择管理所有携带了 name: fluentd-elasticsearch 标签的 Pod。这些 Pod 的模板也是用 template 字段定义的。在该字段中,定义了一个使用 fluentd-elasticsearch:1.20 镜像的容器,而且该容器挂载了两个 hostPath 类型的 Volume,分别对应宿主机的 /var/log 目录和 /var/lib/docker/containers 目录。
DaemonSet 如何保证每个节点上有且只有一个被管理的 Pod 呢?DaemonSet Controller 首先从 etcd 里获取所有的节点列表,然后遍历所有节点,这时,就很容易检查当前节点是否有一个携带了 name: fluentd-elasticsearch 标签的 Pod 在运行。
检查的结果可能有3种情况:
(1)没有这种 Pod,这就意味着要在该节点上创建这样一个 Pod
(2)有这种 Pod,但是数量大于1,说明要删除该节点上多余的 Pod
(3)正好只有一个这种 Pod,说明该节点是正常的
如何在指定节点上新建 Pod ?可以使用 nodeSelector。不过,nodeSelector 已经是一个将要被废除的字段了,最好使用 nodeAffinity 代替它:
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: metadata.name
operator: In
values:
- node-ituringrequiredDuringSchedulingIgnoredDuringExecution 的意思是这个 nodeAffinity 必须在每次调度时予以考虑,也意味着可以设置在某些情况下不考虑这个 nodeAffinity。这个 Pod 将来只允许在 metadata.name 是 node-ituring 的节点上运行。
此外,DaemonSet 还会给这个 Pod 自动加上另外一个与调度有关的字段:tolerations。这意味着这个 Pod 会“容忍”某些节点上的“污点”(Taint)。
apiVersion: v1
kind: Pod
metadata:
name: with-toleration
spec:
tolerations:
- key: node.kubernetes.io/unschedulable
operator: Exists
effect: NoSchedule这个 Toleration 的含义是:“容忍”所有被标记为 unschedulable “污点”的节点,“容忍”的效果是允许调度。在正常情况下,被加上 unschedulable “污点”的节点是不会有任何 Pod 被调度上去的。但是,DaemonSet 自动地给被管理的 Pod 加上了这个特殊的 Toleration, 就使得这些 Pod 可以忽略这项限制,继而保证每个节点上都会被调度一个 Pod。
5. Job 与 CronJob
有一类作业属于“离线业务”,也叫 Batch Job(计算业务)。这种业务在计算完成后就直接退出了。
Job API 对象的定义非常简单,示例如下:
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
spec:
containers:
- name: pi
image: resouer/ubuntu-bc
command: ["sh", "-c", "echo 'scale=10000; 4*a(1)' | bc -l "]
restartPolicy: Never
backoffLimit: 4在这个 Job 的 YAML 文件中,可以看到 Pod 模板:spec.template。在这个模板中,定义了一个 Ubuntu 镜像的容器,它运行的程序是:echo 'scale=10000; 4*a(1)' | bc -l 。
在一个 Job 对象创建后,它的 Pod 模板被自动加上了一个 controller-uid=<随机字符串> 这样的 Label。而这个 Job 对象本身被自动加上了这个 Label 对应的 Selector,从而保证了 Job 与它所管理的 Pod 之间的匹配关系。
在 Pod 模板中定义 restartPolicy=Never 的原因是离线计算的 Pod 永远不应该被重启。事实上,restartPolicy 在 Job 对象里只允许设置为 Never 和 OnFailure;而在 Deployment 对象里,restartPolicy 只允许设置为 Always。
如果一个离线作业失败了,Job Controller 就会不断尝试创建一个新 Pod。当然,这个尝试肯定不能无限进行下去。所以,就在 Job 对象的 spec.backoffLimit 字段里定义了重试次数为4,这个字段的默认值为6。
需要注意的是,Job Controller 重新创建 Pod 的间隔是呈指数级增加的,即下一次重新创建 Pod 的动作会分别发生在 10s、20s、40s... 后。
在 Job 的 API 对象里,有一个 spec.activeDeadlineSeconds 字段可以限制运行时长。一旦超过这个时间,这个 Job 的所有 Pod 都会被终止。并且,你可以在 Pod 的状态里看到终止的原因: reason: DeadlineExceeded。
在 Job 对象中,负责并行控制的参数有两个:
(1)spec.parallelism 定义的是一个 Job 在任意时间最多可以启动多少个 Pod 同时运行。
(2)spec.completions 定义的是 Job 至少要完成的 Pod 的数目。
下面,介绍一个非常有用的 Job 对象:CronJob:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "* * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure最重要的关键词是 jobTemplate,这就意味着,CronJob 是一个 Job 对象的控制器。它创建和删除 Job 的依据是 schedule 字段定义的、一个标准的 Unix Cron 格式的表达式。
由于定时任务的特殊性,很可能某个 Job 还没有执行完,另一个新的 Job 就产生了。可以通过 spec.concurrencyPolicy 字段来定义具体的处理策略:
(1)concurrencyPolicy=Allow,这是默认情况,意味着这些 Job 可以同时存在。
(2)concurrencyPolicy=Forbid,这意味着不会创建新的 Pod。
(3)concurrencyPolicy=Replace,这意味着新产生的 Job 会替换旧的、未执行完的 Job。
如果某一次 Job 创建失败,这次创建就会被标记为“miss”。在指定时间窗口内 miss 的数目达到 100 时,CronJob 会停止再创建这个 Job。这个时间窗口可以由 spec.startingDeadlineSeconds 字段指定。