目录
- 一、线程、块、网格概念
- 二、代码分析
- 2.1 打印第一个线程块的第一线程
- 2.2 打印当前线程块的当前线程
- 2.3 获取当前是第几个线程
一、线程、块、网格概念
CUDA的软件架构由网格(Grid)、线程块(Block)和线程(Thread)组成,相当于把GPU上的计算单元分为若干(2~3)个网格,每个网格内包含若干(65535)个线程块,每个线程块包含若干(512)个线程,三者的关系如下图:
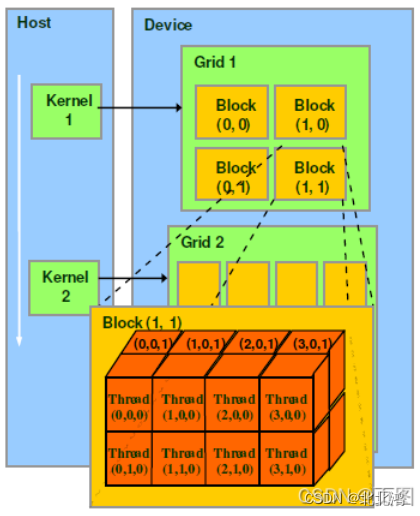
thread:一个CUDA的并行程序会被以许多个threads来执行。
block:数个threads会被群组成一个block,同一个block中的threads可以同步,也可以通过shared memory通信。
grid:多个blocks则会再构成grid。
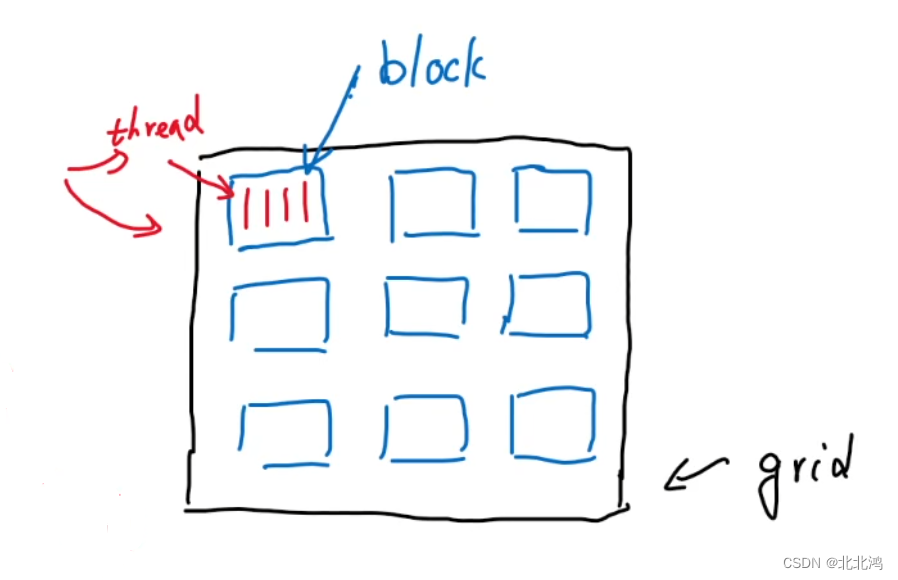
如图,1个网格有9个线程块,每个线程块有4个线程
4*9=36个线程同时运行
而block如果有1024个线程,block可以很大,所以有可能百万线程并发
开普勒架构:最大线程块1024,最大网格2^31-1,两万亿个线程
gridDim.x :该变量的数值等与执行配置中变量grid_size的数值。网格块数
blockDim.x: 该变量的数值等与执行配置中变量block_size的数值。当前块的线程数。
在核函数中预定义了如下标识线程的内建变量:
blockIdx.x :该变量指定一个线程在一个网格中的线程块指标。其取值范围是从0到gridDim.x-1。当前块索引
threadIdx.x:该变量指定一个线程在一个线程块中的线程指标,其取值范围是从0到blockDim.x-1。当前块中线程的索引
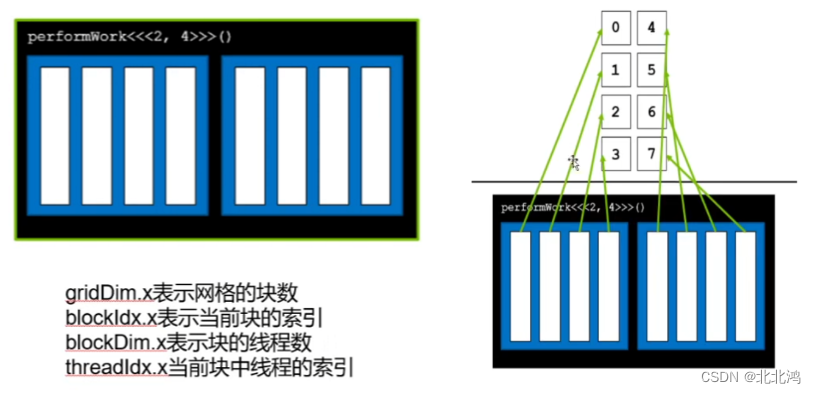
若gpu<<<2,2>>>();
则打印四次
二、代码分析
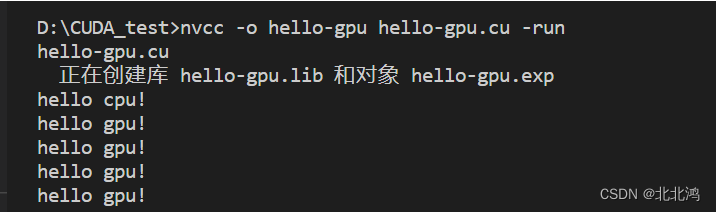
2.1 打印第一个线程块的第一线程
#include <stdio.h>
void cpu()
{
printf("hello cpu!\n");
}
__global__ void gpu()
{
//if (blockIdx.x == 2 && threadIdx.x == 0) //若线程块2,则不打印,因为只分配了0和1
if (blockIdx.x == 0 && threadIdx.x == 0) //打印第一个线程块的第一线程
{
printf("hello gpu!\n");
}
}
int main()
{
cpu();
gpu<<<2,2>>>();
cudaDeviceSynchronize();
}
2.2 打印当前线程块的当前线程
一个核函数可以指派多个线程,而这些线程的组织结构是由执行配置(<<<网格大小,线程块大小 >>>)来决定的,这是的网格大小和线程块大小一般来说是一个结构体类型的变量,也可以是一个普通的整形变量。
一个核函数允许指派的线程数是巨大的,能够满足几乎所有应用程序的要求。但是一个核函数中虽然可以指派如此巨大数目的线程数,但在执行时能够同时活跃(不活跃的线程处于等待状态)的线程数是由硬件(主要是CUDA核心数)和软件(核函数的函数体)决定的。
每个线程在核函数中都有一个唯一的身份标识。由于我们在三括号中使用了两个参数制定了线程的数目,所以线程的身份可以由两个参数确定。在程序内部,程序是知道执行配置参数grid_size和block_size的值的,这两个值分别保存在内建变量(built-in variable)中。
#include<stdio.h>
__global__ void hello_from_gpu()
{
const int bid = blockIdx.x;
const int tid = threadIdx.x;
printf("hello word from block %d and thread %d\n",bid,tid);
}
int main()
{
hello_from_gpu<<<2,4>>>();
cudaDeviceSynchronize();
printf("helloword\n");
return 0;
}
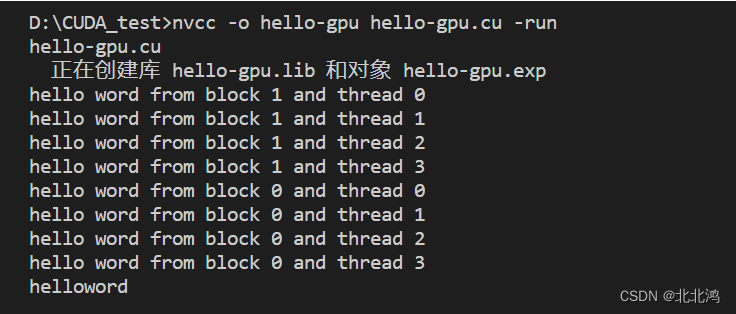
有时候线程块的顺序会发生改变,有时候是第1个先执行有时候是第0个先执行,这说明了cuda程序执行时每个线程块的计算都是相互独立的,不管完成计算的次序如何,每个线程块中间的每个线程都进行一次计算。

2.3 获取当前是第几个线程
int threadi = blockIdx.x * blockDim.x + threadIdx.x; //计算出当前是第几个线程
参考:
https://blog.csdn.net/qq_32159463/article/details/124196351
B站 爱学习的阿噜