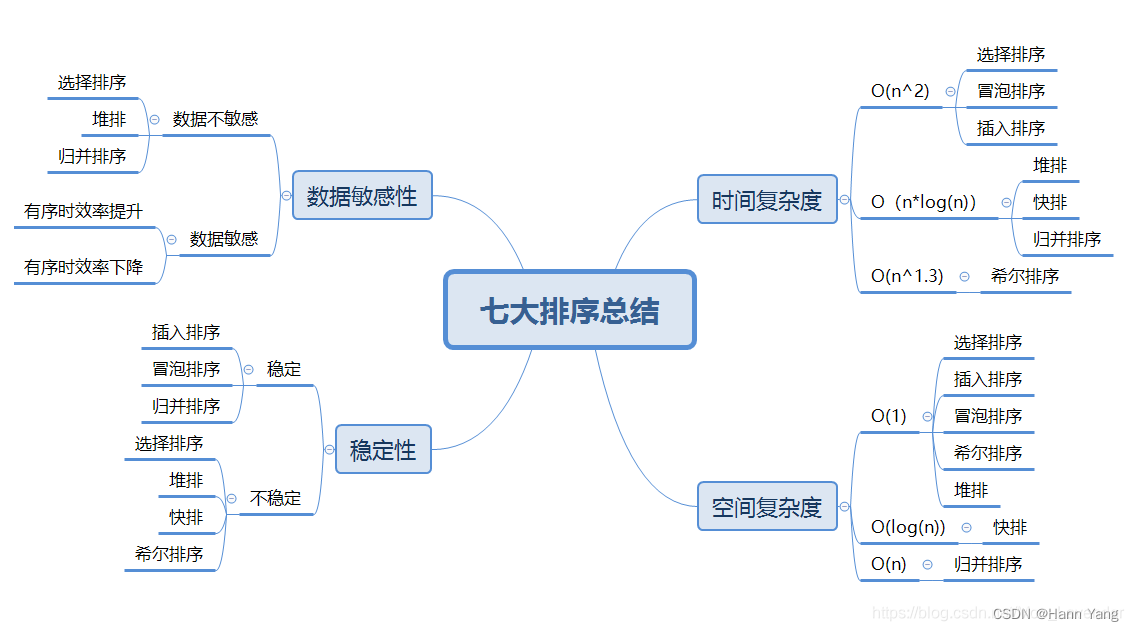
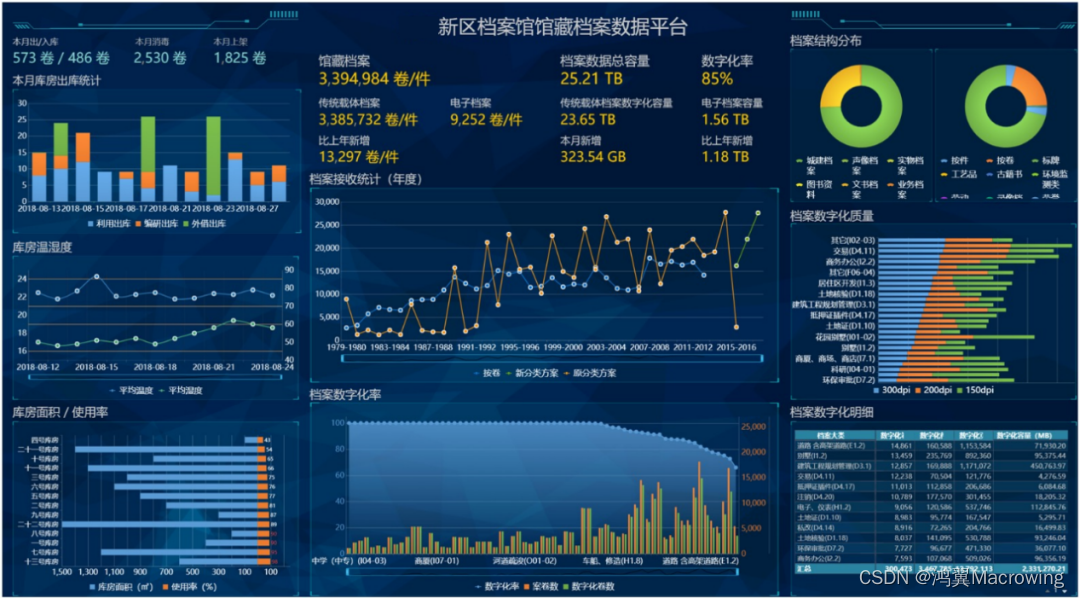
String在java中我们是用来操作字符串的,但它的底层结构确是一个char[]数组,通过数组的方式将每个字符进行保存。
使用时:String str="ABCD",内部存value确是:value=['A','B','C','D'];
如下图:
参考String源码如下:
public final class String implements java.io.Serializable, Comparable<String>, CharSequence { private final char value[]; private int hash; // Default to 0 private static final long serialVersionUID = -6849794470754667710L; ......此处省略N多代码 public String(String original) { this.value = original.value; this.hash = original.hash; } }

通过源码中的构造方法可以看到,我们传递的参数值 是直接赋值给了value。如果声明一个String a=”ABCD”,那a对象的value实际就是一个数组[A,B,C,D]
String赋值有两种,一种是“=”直接赋值,另一种是new String("xxx")赋值,这两种是有区别的。
- “=”赋值不会在堆上创建新的对象,而是在常量池中搜索,如果常量池中有这个字符串则直接引用这个字符串的地址。如果没有这个字符,则会在常量池中创建该字符串,并引用地址,字符常量池中不存在两个相同的字符串,也就是说
String str1 = "abc";
String str2 = "abc";
System.out.println(str1==str2);//true
//二者引用的地址是相同的,都指向一个字符串- new String()意味着创建了一个新的对象,会在堆上分配一块内存,但并不是说这个字符就存储在了堆上,而是存储了一个地址,这个地址仍然指向字符常量池。
String str1 = "abc";
String str2 = new String("abc");
System.out.println(str1==str2);//false
继续看下列问题
声明四个String对象如下,思考下它们之间用 == 比较的结果?
String a= “abc”;
String b = “abc”;
String c = new String(“abc”);
String d = “ab” + “c”;其中a,b,d所有他们的引用是一样的,所以String 没有被新创建对象。所以他们三个用 == 对比是true。 而c 则是new(“abc”) 新建了一个String 对象,值虽然一样,但是与 a,b,d 引用不一样,所以a,b,d 与 c 对比则是 false。
String a="a"+"b"+"c"在内存中创建几个对象?
这个问题涉及到了字符串常量池和字符串拼接,String a="a"+"b"+"c" 通过编译器优化后,得到的效果是 String a="abc"。此时,如果字符串常量池中存在abc,则该语句并不会创建对象,只是将字符串常量池中的引用返回而已。如果字符串常量池中不存在abc,则会创建并放入字符串常量池,并返回引用,此时会有一个对象进行创建。
JDK9为何要将String底层由char[]改成了byte[]?
对于JDK9后的版本,String底层由char[]改成了byte。那么将char[]改成了byte有和意义呢?
1)节省内存:char占用两个字节,byte只需要一个字节。
那么问题来了,如果存储英文或数字可以使用byte,那存储的中文或特殊字符呢?
源码内有一个:private final byte coder;用于兼容两个字节的字符
private final byte coder;
static final byte LATIN1 =0 ;// LATIN1用单个字节来表示字符
static final byte UTF16 =1; // UTF16 是用双字节来表示字符所以就可以根据存储内容的不同,去判断应该使用那种编码,如中文时使用UTF16,英文就可以是LATIN1
2)减少GC的次数:减少了内存使用之后,必然垃圾回收次数也会相对应减少