1、Hive存储数据的格式如下:
| 存储数据格式 | 存储形式 |
| TEXTFILE | 行式存储 |
| SEQUENCEFILE | 行式存储 |
| ORC | 列式存储 |
| PARQUET | 列式存储 |
2、行式存储和列式存储
解释:
1、上图左面为逻辑表;右面第一个为行式存储,第二个温列式存储;
2、行存储的特点: 查询满足条件的一整行数据的时候,行存储只需要找到其中一个值,其余的值都在相邻地方。列存储则需要去每个聚集的字段找到对应的每个列的值,所以此时行存储查询的速度更快。
3、列存储的特点: 因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
行式存储优点:
1、相关的数据保存在一起,比较符合面向对象的思维,因为一行数据就是一条记录
2、方便进行insert或update操作
行式存储缺点:
1、如果仅需要查询几列数据,它会把整行数据都读取出来,不能跳过不必要的列读取
2、由于每一行中列的数据类型不一致,导致不容易获得一个极高的压缩比(空间利用率不高)
列式存储优点:
1、查询时,只有涉及到的列才会被查询,可以跳过不必要的列查询
2、高效的压缩率,不仅节省储存空间也节省计算内存和CPU
3、任何列都可以作为索引
列式存储缺点:
1、不适合进行insert或update操作
2、不适合扫描小量的数据
3、存储格式详解:
TEXTFILE格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
ORC格式
Orc (Optimized Row Columnar)是hive 0.11版里引入的新的存储格式。
可以看到每个Orc文件由1个或多个stripe组成,每个stripe250MB大小,这个Stripe实际相当于RowGroup概念,不过大小由4MB->250MB,这样能提升顺序读的吞吐率。每个Stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer:
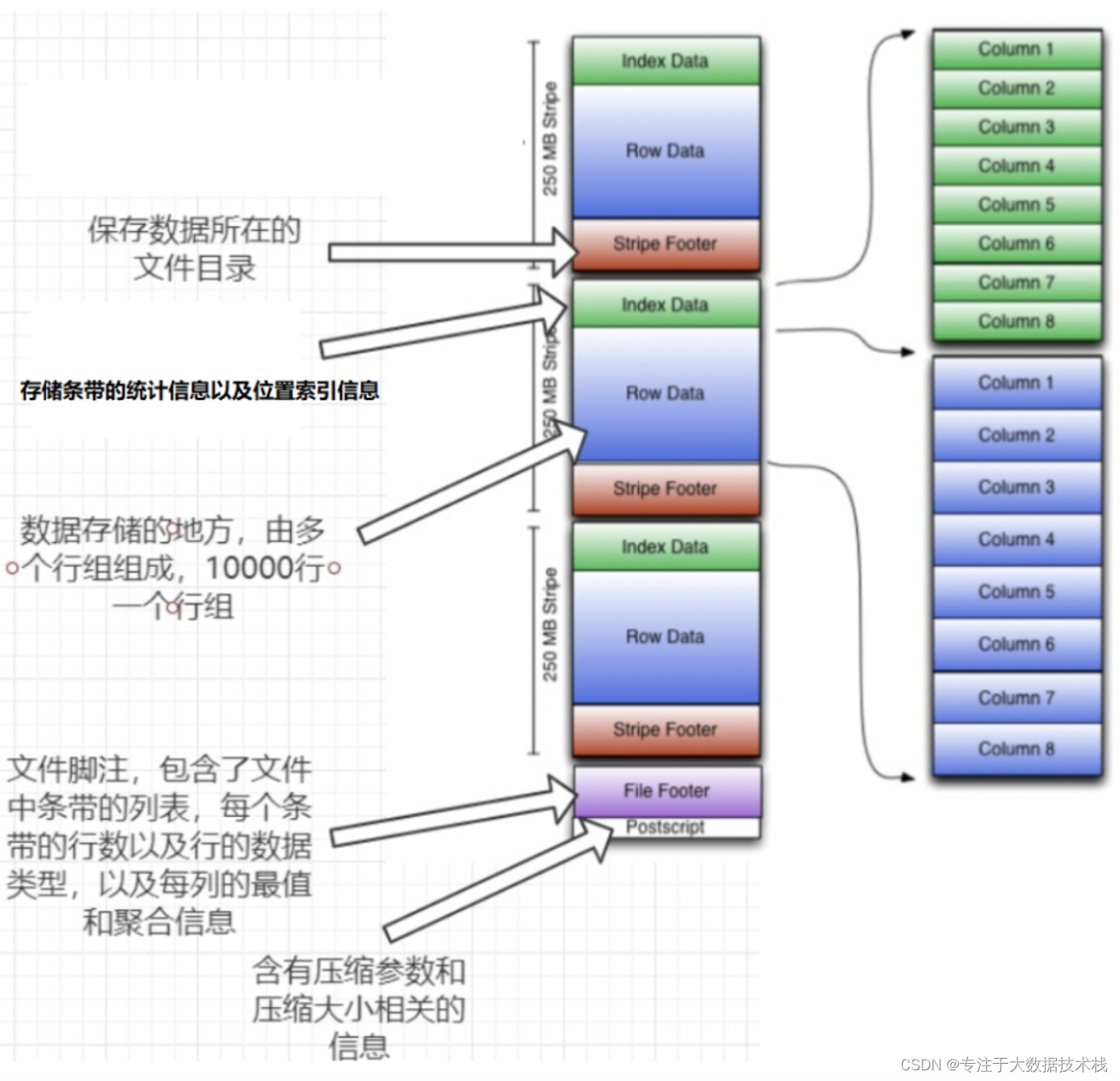
一个ORC文件可以分为若干个Stripe,一个stripe可以分为三个部分:
Index Data:一个轻量级的index,默认是每隔1W行做一个索引(目录)。这里做的索引只是记录某行的各字段在Row Data中的offset
Row Data:存储具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个Stream来存储。
Strip Footer:存储各个stripe的元数据信息
每个ORC文件文件有一个File Footer,存储的是每个Stripe的行数以及Stripe中每个Column的数据类型信息等;
每个ORC文件文件的尾部是一个Post Script,这里面记录了整个文件的压缩类型以及File Footer的长度信息等。
在读取文件时,会seek到文件尾部读Post Script,从里面解析到File Footer长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
parquet
面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目
parquet文件是以二进制方式存储的,所以是不可以直接读取。文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的
通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。
ORC和Parquet区别
- ORC存储格式比Parquet压缩率更好
- Parquet格式对嵌套列的支持比较友好,可以只查询某个列中的嵌套子列,而不用查询其他的子列。
- ORC支持ACID事务,而Parquet目前还不支持。
问题:
1、Zlib和Snappy两种压缩算法的对比?
Zlib 压缩率 高, 解压速度 慢
Snappy则与Zlib相反,按照业务情况来选择使用
2、什么是压缩率?
压缩率(Compression rate),描述压缩文件的效果名,是文件压缩后的大小与压缩前的大小之比,例如:把100m的文件压缩后是90m,压缩率为90/100*100%=90%,压缩率一般是越小越好,但是压得越小,解压时间越长。
3、什么是解压速度?
解压速度是指将一个通过软件压缩的文件释放到目标地址,恢复为压缩前文件的速度。