为什么需要GBDT+LR
协同过滤和矩阵分解存在问题:
仅利用了用户与物品相互行为信息进行推荐, 忽视了用户自身特征, 物品自身特征以及上下文信息等,导致生成的结果往往会比较片面。
FFM 存在问题
FFM特征交叉能力有限:虽然 FFM 模型采用引入特征域的方式增强了模型的特征交叉能力,只能做二阶的特征交叉,如果继续提高特征交叉的维度,会不可避免地产生组合爆炸和计算复杂度过高的问题。
LR 存在问题
表达能力不强, 无法进行特征交叉, 特征筛选等一系列“高级“操作(这些工作都得人工来干, 这样就需要一定的经验, 否则会走一些弯路), 因此可能造成信息的损失。
GBDT算法详解
传送门
GBDT+LR 模型 思路是什么样?
- 利用GBDT自动进行特征筛选和组合,进而生成新的离散特征向量;
- 再把该特征向量当做LR模型的输入, 来产生最后的预测结果;
GBDT+LR 模型 步骤是什么样?
训练时,GBDT 建树的过程相当于自动进行的特征组合和离散化,然后从根结点到叶子节点的这条路径就可以看成是不同特征进行的特征组合,用叶子节点可以唯一的表示这条路径,并作为一个离散特征传入 LR 进行二次训练。
预测时,会先走 GBDT 的每棵树,得到某个叶子节点对应的一个离散特征(即一组特征组合),然后把该特征以 one-hot 形式传入 LR 进行线性加权预测。
GBDT为什么可以做特征组合?
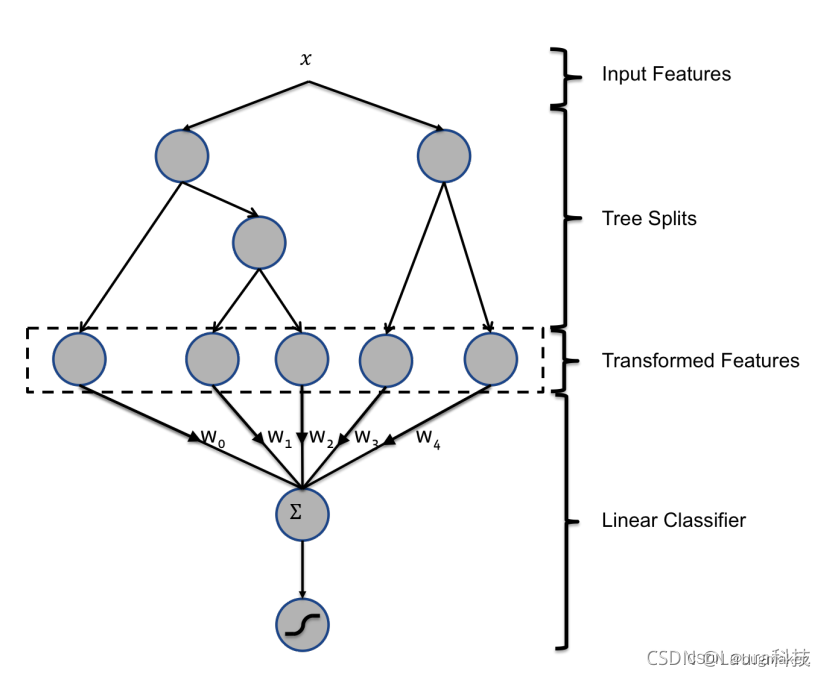
在GBDT中,每个叶子节点就是这个树最终的预测结果,那么从根节点到叶子节点的路径就是我们这个树用来判别这个样本的根据,说白就是这个树是通过这条路径的特征组合来实现这个样本分类的,再换句话说,就是我们产生了一个特征组合,就是这条路径的特征组合,利用这个特征组合我们就可以区分这个根节点的样本,那么我们就可以获取所有树的根节点的特征组合。
举个例子,我们定义GBDT树的个数为2,那么我们就会有两棵树,如果第一个树的叶子节点个数为3,第二颗树的叶子节点个数为2,那么我们就会产生一个新的5维特征向量,如果一个样本落到了对应的叶子节点,则这个节点对应的向量值为1,比如一个样本落在了第一颗树的第2个叶子节点,落到了第二棵树的第1个节点,那么产生的特征组合向量为 【0,1,0,1,0】,这是我们就可以将这个5维向量与原来的特征进行拼接融合,作为新的特征矩阵交给逻辑回归模型中进行建模。