- Neo4j 图的组件
- 节点(Nodes)
- 标签(Labels)
- 关系(Relationships)
- 属性(Properties)
- 建模过程
- 了解领域并为应用程序定义特定用例(问题)。
- 开发初始图形数据模型。
- 对节点(实体)建模。
- 对节点之间的关系建模。
- 针对初始数据模型测试用例。
- 使用 Cypher 使用测试数据创建图形(实例模型)。
- 测试用例,包括针对图表的性能。
- 由于关键用例的变化或性能原因,重构(改进)图形数据模型。
- 在图上实施重构并使用 Cypher 重新测试。
- 图数据建模是一个迭代过程。
- 重构在开发过程中很常见。与 RDBMS 中的模式不同,Neo4j 图形有一个非常灵活的可选模式。Cypher 开发人员可以轻松修改图形以表示改进的数据模型。
- 领域
- 了解应用程序的域
- 确定应用程序的利益相关者和开发人员。
- 与利益相关者和开发人员
- 详细描述应用程序。
- 识别应用程序的系统和用户。
- 就应用程序的用例达成一致。
- 对用例的重要性进行排序。
- 了解应用程序的域
- 模型的目的
- 模型类型
- 数据类型(Data model)
- 数据模型描述了图形的标签、关系和属性。它没有将在图表中创建的特定数据。
- 图形数据模型很重要,因为它定义了在应用程序创建和使用图形时将用于标签、关系类型和属性的名称。
- 实例类型(Instance model)
- 图数据建模过程的一个重要部分是针对用例测试模型。
- 帮助我们确认我们的数据模型可以满足应用程序的用例。
- 数据类型(Data model)
- 建模风格指南
- 标签是以大写字母开头的单个标识符,可以是CamelCase。
- 示例:个人、公司、GitHubRepo
- 关系类型是单个标识符,全部为大写字母并带有下划线字符。
- 示例:FOLLOWS、MARRIED_TO
- 节点或关系的属性键是以小写字母开头的单个标识符,可以是CamelCase式。
- 示例:deptId、firstName
- 标签是以大写字母开头的单个标识符,可以是CamelCase。
- 模型类型
- 建模节点(Modelig Nodes)
- 名词
- 定义标签(实体)
- 用例的实体将是图形数据模型中的标记节点。
- 节点属性
- 作用
- 唯一标识一个节点。
- 回答应用程序用例的具体细节。
- 返回数据。
- 作用
- 创建节点
- MATCH (n) DETACH DELETE n;
- MERGE (:节点名 {标签1: '属性', 标签2: '属性', 标签3: '属性', 标签4: [属性数组]})
- 建模关系(Modeling Relationships)
- 动词
- 关系是实体之间的联系
- 命名关系
- 使用所有大写字母/下划线字符的 Neo4j 最佳实践作为关系的名称。
- 关系方向
- 在 Neo4j 中创建关系时,方向必须明确指定或由指定模式中的从左到右方向推断。
- 在运行时,在查询期间,通常不需要方向。
- 关系属性
- 关系的属性用于丰富两个节点的相关方式。
- 定义关系时,必须定义
- 关系的起始节点(带有标签)。
- 关系的结束节点(带有标签)。
- 关系的名称(类型)。
- 创建关系
- MERGE ( 起始节点 )-[ :关系名 { 关系属性名: '属性值' } ]->( 结束节点 )
- 用于 MATCH 查找用户和电影节点,然后用于 MERGE 创建两个节点之间的关系。请记住,在创建关系时必须指定或推断(从左到右)方向。
- 测试用例期间需要做什么
- 向图中添加更多数据以测试可扩展性。
- 测试和修改用于测试用例的任何 Cypher 代码。
- 如果无法回答用例,则重构数据模型。
- 测试用例
- MATCH ( 别名1 : 节点/标签1 ) - [ 关系标签 : 关系 ] - ( 别名2 : 节点/标签2 ) WHERE 条件1 AND/OR 条件2 AND ['值1','值2'...] IN 列名 RETURN 列名/关系属性 AS 列名(列名长用反引号)ORDER BY 列名 DESC/ASC Limit 数字
- 节点计数
- MATCH ( 标签 : 节点 ) RETURN count(*)
- 关系计数
- MATCH () - [ :关系 ] - () RETURN count(*)
- 重构图表
- 重构是更改数据模型和图形的过程。
- 重构的原因
- 建模的图表并没有回答所有的用例。
- 出现了一个新的用例,您必须在数据模型中考虑该用例。
- 用例的 Cypher 表现不佳,尤其是当图形缩放时
- 重构步骤
- 设计新的数据模型。
- 编写 Cypher 代码来转换现有图形以实现新的数据模型。
- 重新测试所有用例,可能使用更新的 Cypher 代码。
- 图中的标签
- 节点标签用作查询的锚点。
- 向节点添加标签的主要原因
- 使用标签有助于减少检索的数据量。
- 最佳做法是将节点的标签数限制为 4
- 返回图中的所有节点。
- MATCH (n) RETURN n
- 返回图中的所有Person节点。
- MATCH (n:Person) RETURN n
- 使用 PROFILE 分析查询
- PROFILE MATCH (n:Person) RETURN n

- 执行的次数和执行的时间,越小越优。

- PROFILE MATCH (n:Person) RETURN n
- 不要过度的使用标签
- 最佳做法是将节点的标签数限制为 4
- 因为缓存是自动填充的,所以有时很难用小数据集来衡量性能。也就是说,数据库命中率和运行时间可能无法比较。
- 用PROFILE分析查询
- 重构模型
- 重构图表
- MATCH (p:Person) WHERE exists ((p)-[:ACTED_IN]-()) SET p:Actor
- 重构图表后
- 为受重构影响的用例重写任何 Cypher 查询。
- 重新测试受重构影响的所有用例及所有查询。
- 避免这些标签
- 主义正交:标签之间应该没有任何关系
- 表示类层次结构
- 消除重复数据
- 重构图表已消除重复数据
- 提高查询性能。
- 减少图形所需的存储量。
- 添加节点属性
- MATCH ( m:Movie { m.title : 'Apollo13'} ) SET m.languages=['English']
- 查询重复数据
- MATCH ( 别名 : 节点 ) WHERE [ ' 值1 ' , ' 值2 ' ] IN 列名 RETURN 返回的列
- 重构重复数据

- 如Oracle数据库,新添加一个表,将重复的列的惟一值写到新表中
- 创建新节点及属性
- 创建节点关系
- 删除旧节点属性
- 使用分隔列表元素 UNWIND
- 消除节点的复杂数据
- 原因
- 重复数据。许多节点可能在特定位置有生产公司,并且数据在许多节点中重复。如Oracle中的列名不能重复,主键惟一。
- 与节点中的信息相关的查询需要检索所有节点。
- 重构节点中包含复杂数据的图
- 消除多个节点中的数据重复。
- 提高查询性能。
- 原因
- 重构图表已消除重复数据
- 使用特定关系
- 重构以专门化关系

- 重构图形以添加这些专用关系的代码使用 APOC 库。
- apoc.merge.relationship 允许您在图中动态创建关系的过程。
- 原因
- 减少需要检索的节点数。
- 提高查询性能。
- 重构以专门化关系
- 中间结点
- 创建原因
- 在单个上下文中连接两个以上的节点。
- 具有 from 和 to 属性超边(n 关系)
- 将某事与一段关系联系起来。
- 在实体之间共享图中的数据。
- 在单个上下文中连接两个以上的节点。
- 重构来创建中间节点
- 在单个上下文中连接两个以上的节点。
- 在图中共享数据。
- 将某事与一段关系联系起来。
- 添加角色节点
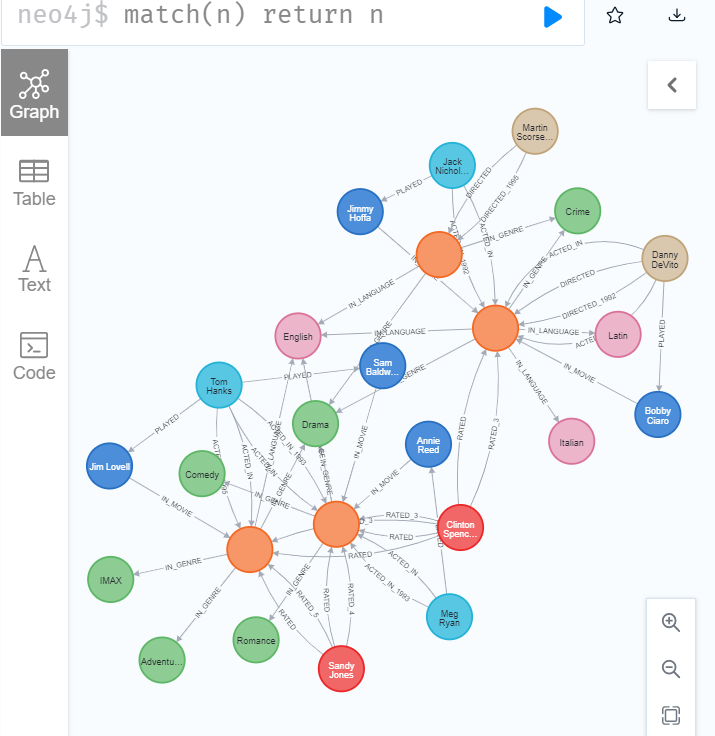
-
- match(a:Actor)-[r:ACTED_IN]->(m:Movie)
- merge (x:Role{name:r.role})
- merge(a)-[:PLAYED]->(x)
- merge(x)-[:IN_MOVIE]->(m)
-
- 创建原因
图数据建模基础
news2026/2/11 13:49:20
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/343740.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
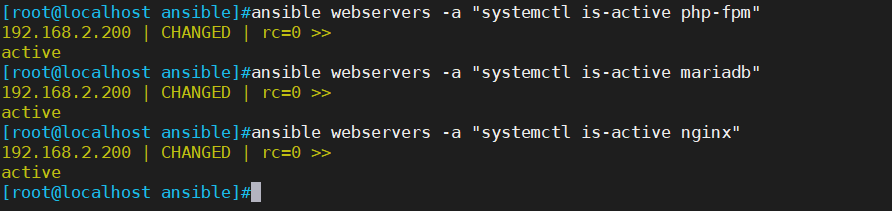
ansible的剧本(playbook)
一、playbooks 概述以及实例操作
1、playbooks 的组成
playbooks 本身由以下各部分组成
(1)Tasks:任务,即通过 task 调用 ansible 的模板将多个操作组织在一个 playbook 中运行
(2)Variables࿱…
多模式支持无线监控技术:主动式定位、被动式定位
物联网空间信息与数字技术发展至今,已经催生了一大批优秀的践行者。在日常与商业应用中,室内外定位领域依托于这一技术的发展,更是在近几年风光无限。但是并不是说室内定位与室外定位都已经相当成熟,相对来说,室内定位…
简单实用的内网穿透实现教程
内网穿透,字面理解就是网络地址穿透,是一种比较常用的将内网地址转换成公网地址的方式。通过内网穿透,可以将本地内网局域网提供给外网公网上访问,在外网也能连接访问内网主机和应用,当用户有日常远程和异地外网访问的…
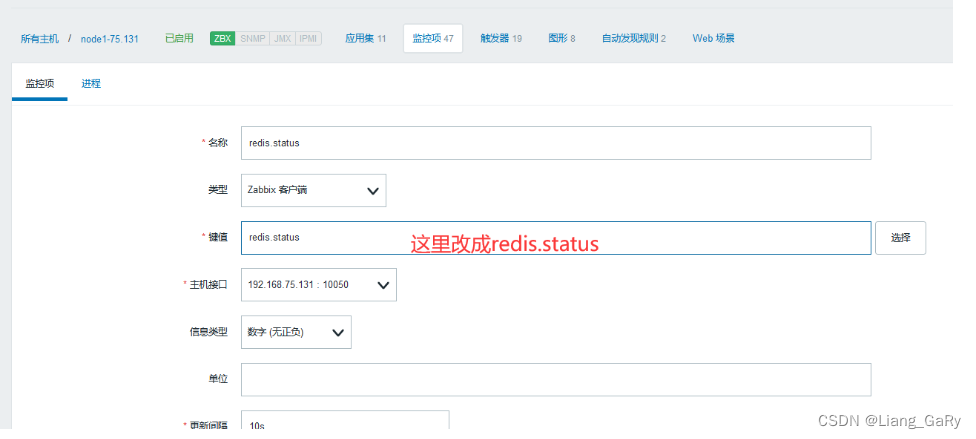
Zabbix的自定义监控
Zabbix的自定义监控
zabbix自动可以提供很多监控项;但是往往不能满足需求;尝尝需要我们自己创建一系列的监控项,这就是自定义监控;
监控项:zabbix进行监控的一个指标,zabbix成为item;
它的值…

C++7:STL-模拟实现vector
目录
vector的成员变量
构造函数
reserve
size()
capacity()
push_back 一些小BUG
赋值操作符重载
析构函数 【】操作符重载
resize
pop_back
Insert 迭代器失效
erase
二维数组问题
总结一下 vector,翻译软件会告诉你它的意思是向量,但其…

面试腾讯测开岗,结束后被面试官吐槽“什么阿猫阿狗都敢来面试大厂了吗?”.....
前一阵子有个小徒弟向我诉苦,说自己在参加某大厂测试面试的时候被面试官怼得哑口无言,场面让他一度十分尴尬
印象最深的就是下面几个问题: 根据你以前的工作经验和学习到的测试技术,说说你对质量保证的理解? 非关系型…
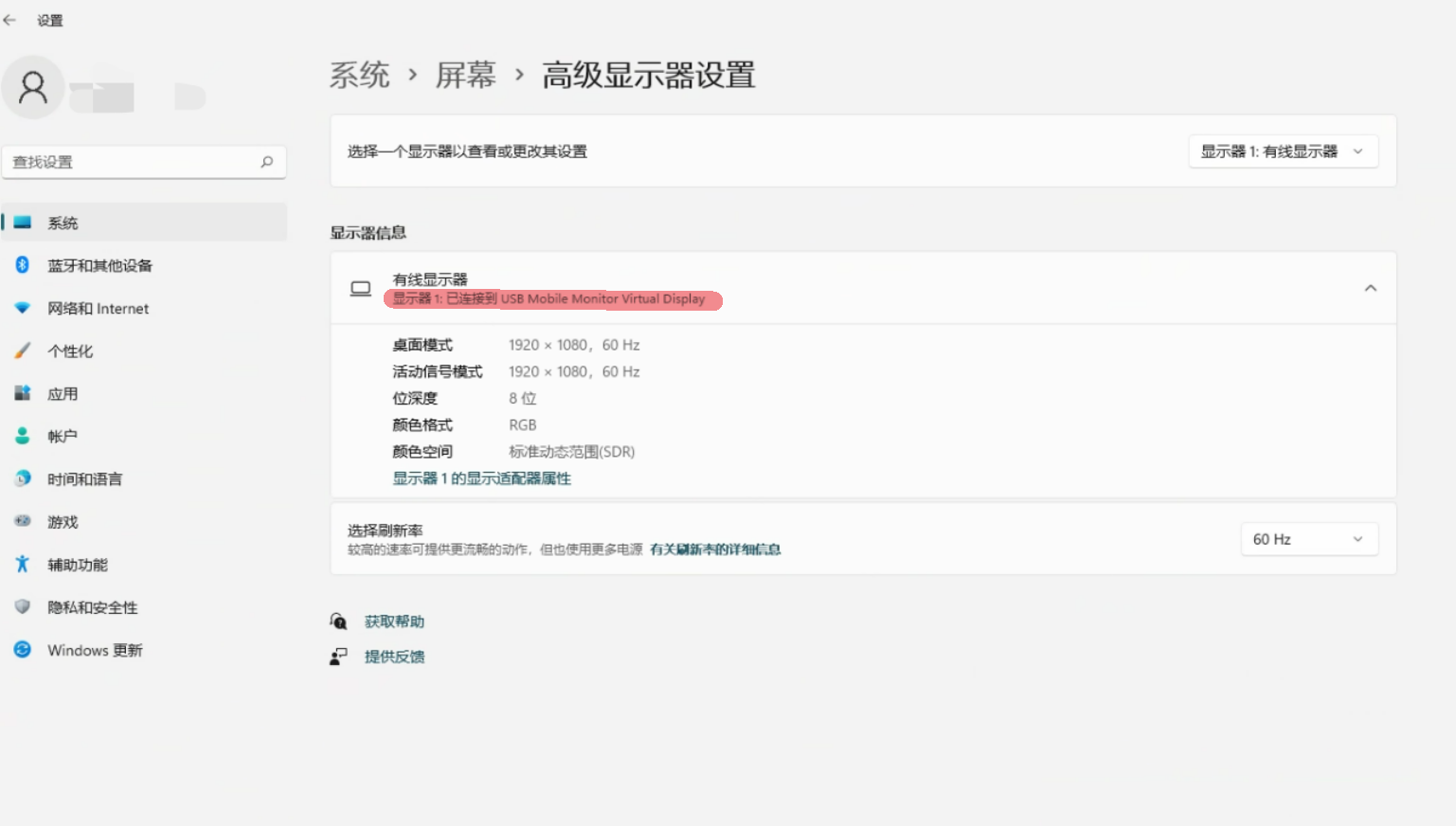
不连接显示器或者HDMI欺骗器来 使用Moonlight串流游戏
环境:WIN11NVIDIA显卡Moonlight串流 问题:当主机不连接显示器时,Moonlight客户端黑屏 解决办法:使用虚拟显示器来使显卡工资 背景:当SteamDeck 大卖的时候,我开始思考是否也需要购买一台Steam Deck来躺在床…

【Linux】动静态库以及动静态链接
环境:centos7.6,腾讯云服务器Linux文章都放在了专栏:【Linux】欢迎支持订阅🌹链接扩展我们在使用Linux的时候,不禁会有这么一个疑问:为什么我们能够在Linux下进行c/c代码的编写以及编译呢?这是因…
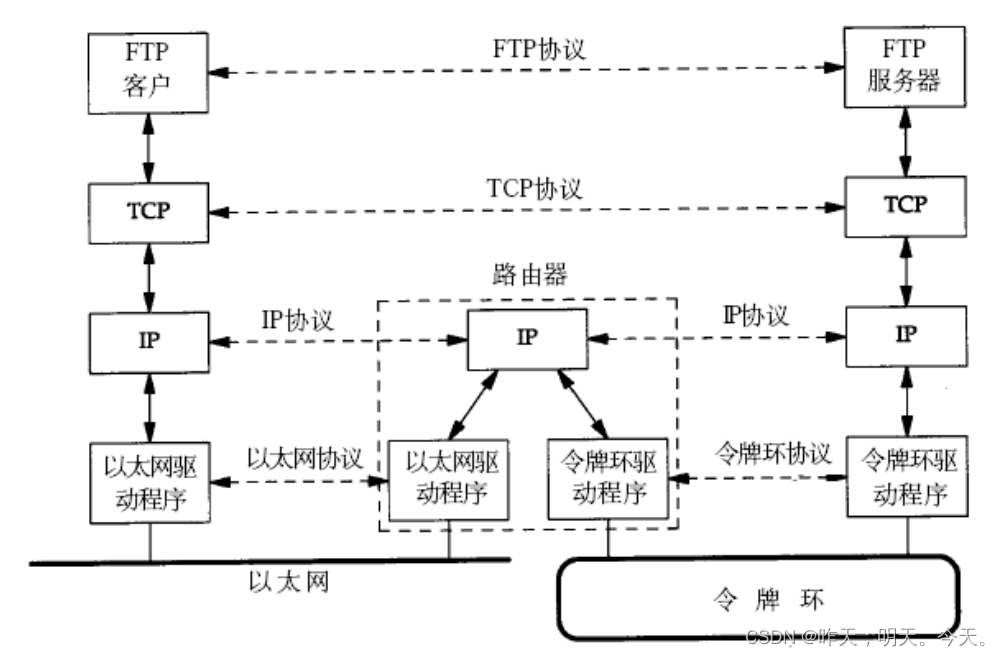
_Linux(网络基础)
文章目录1. 相关基础概念2. 认识 "协议"3. 网络协议初识协议分层OSI七层模型TCP/IP五层(或四层)模型4. 网络传输基本流程网络传输流程图数据包封装和分用小结5. 网络中的地址管理认识IP地址认识MAC地址认识端口号1. 相关基础概念
独立模式: 计算机之间相互独立网络互…
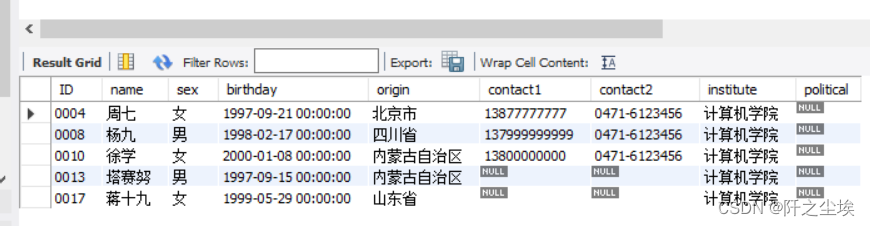
MySQL数据库13——插入数据(INSERT)
下面的语句用于向student表插入数据。
插入语句:
INSERT INTO student(ID,name,sex,birthday,origin,contact1,contact2,institute)
VALUES (0013,塔赛努,男,1997/9/15,内蒙古自治区,NULL,NULL,计算机学院);INSERT INTO student
VALUES (0014,呼和嘎拉,男,1995-02…

字节青训营——秒杀系统设计学习笔记(一)
如何做系统设计
1. 场景分析(Scenario)
什么系统,需要哪些功能,多大的并发量
2. 存储设计(Storage)
数据如何组织,Sq|存储, NoSq|存储
3. 服务设计(Service)
业务功能实现和逻辑整合
4. 可扩展性(Scale)
解决设计缺陷&…
Go的web开发Gin框架1(八)——Gin
一、重点内容:
知识要点有哪些?
1、了解Gin框架
2、导入使用Gin框架
3、尝试配合GORM开发
4、整合html,css,js
二、详细知识点介绍:
1、Gin框架介绍
Gin是一个golang的微框架,封装比较优雅&…
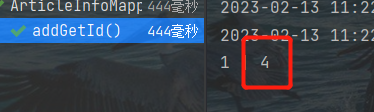
MyBatis无法通过getGenerateKeys获得自增主键的问题
我遇到这个问题的法伤原因比较蠢,查阅了网上相关经验都没有能够解决。看看这个经验能否帮助到你。问题描述:设置了属性的自增后想通过getGenerateKeys获得MySQL对应表单中自增主键id,检查了类、映射器、xml都没有发现问题,但是进行…

如何使用 Python 编程进行多线程
多线程:理论上能在同一个时间段执行多个程序片段,每个程序片段就看作是一个线程。为什么要说理论上,因为实际在操作系统中真正的在同一时间段基本是不存在的,但是在软件编程中我们可以理解为它是在同一时间段执行的。
同步&#…
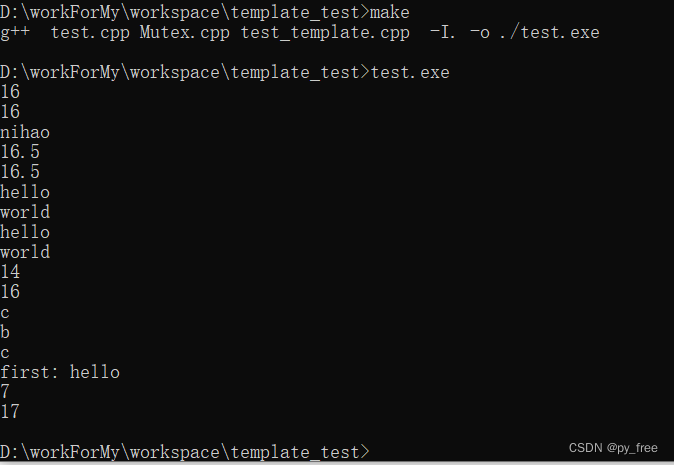
c/c++开发,无可避免的模板编程实践(篇一)
一、c模板 c开发中,在声明变量、函数、类时,c都会要求使用指定的类型。在实际项目过程中,会发现很多代码除了类型不同之外,其他代码看起来都是相同的,为了实现这些相同功能,我们可能会进行如下设计…
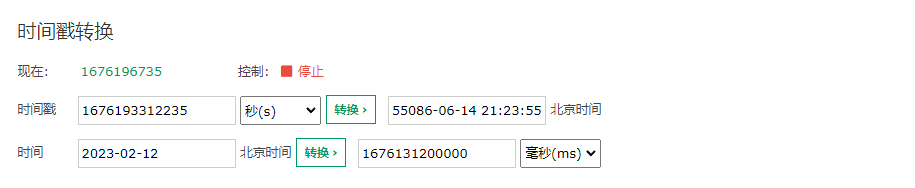
SpringBoot自定义JsonSerializer和JsonDeserializer,兼容LocalDateTime和LocalDate
1.前言 JDK1.8中添加新的时间日期API,LocalDate、LocalDateTime、LocalTime,但是我们在开发中使用时间戳作为参数值来传递是比较常用的,然而在SpringBoot中并没有为我们提供合适的JsonSerializer和JsonDeserializer。 我们先看看使用默认的Js…
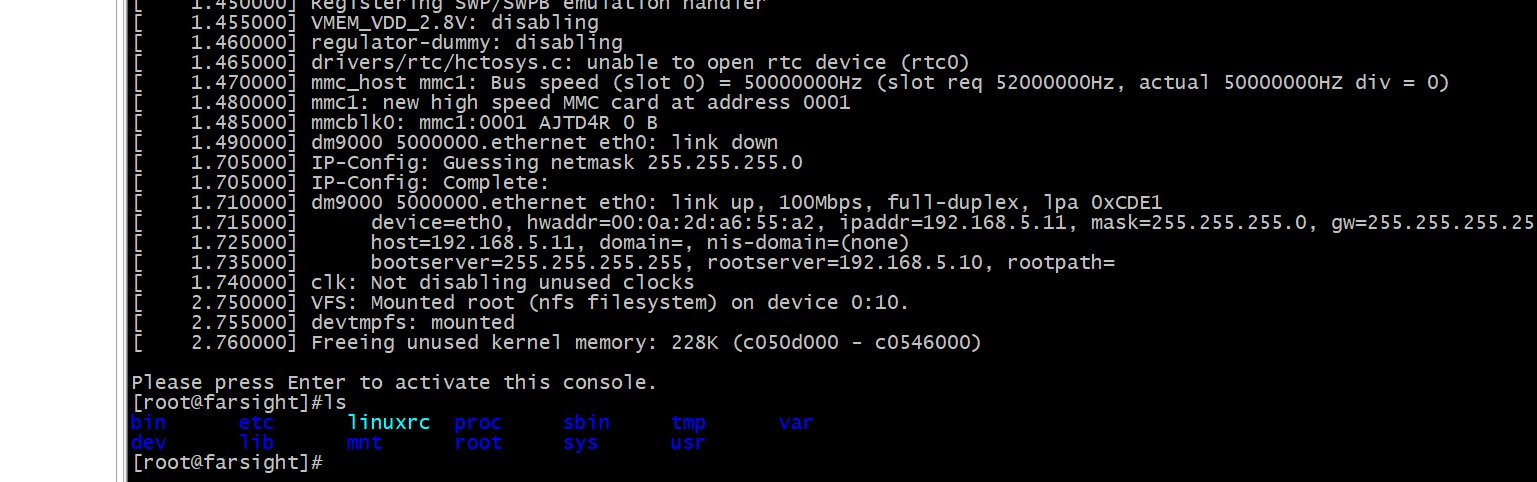
Linux根文件系统移植
目录
一、根文件系统
1.1根文件系统
1.2根文件系统内容
二、根文件系统移植
2.1BusyBox
2.2BusyBox的获取
2.3BusyBox的使用
2.4make menuconfig
2.5编译和安装
2.6修改根文件系统 一、根文件系统
1.1根文件系统 根文件系统是内核启动后挂载的第一个文件系统系统引…
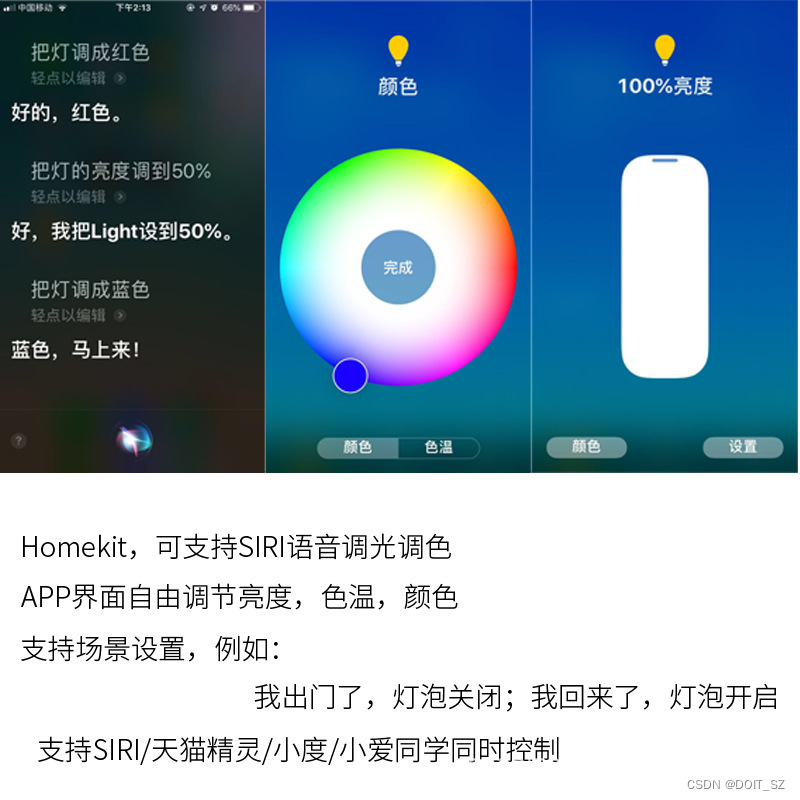
Homekit智能家居创意DIY一智能灯
一、什么是智能灯
传统的灯泡是通过手动打开和关闭开关来工作。有时,它们可以通过声控、触控、红外等方式进行控制,或者带有调光开关,让用户调暗或调亮灯光。
智能灯泡内置有芯片和通信模块,可与手机、家庭智能助手、或其他智能…
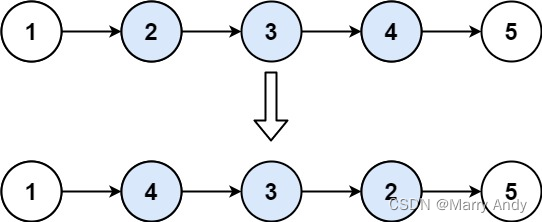
链表题目总结 -- 递归
目录一. 递归反转整个链表1. 思路简述2. 代码3. 总结二. 反转链表前 N 个节点1. 思路简述2. 代码3. 总结三、反转链表的一部分1. 思路简述2. 代码3.总结四、反转链表后N个节点1. 思路简述2. 代码3.总结一. 递归反转整个链表
题目链接:https://leetcode.cn/problems…