目录
什么是API网关?
为什么要用API网关?
API网关架构
API网关是如何实现这些功能的?
协议转换
链式处理
异步请求
什么是API网关?
Api网关是微服务的重要组成部分,封装了系统内部的复杂结构,客户端只需要和API网关交互,就能保证用户在不同服务之间能够串通,API网关是微服务系统的门面。
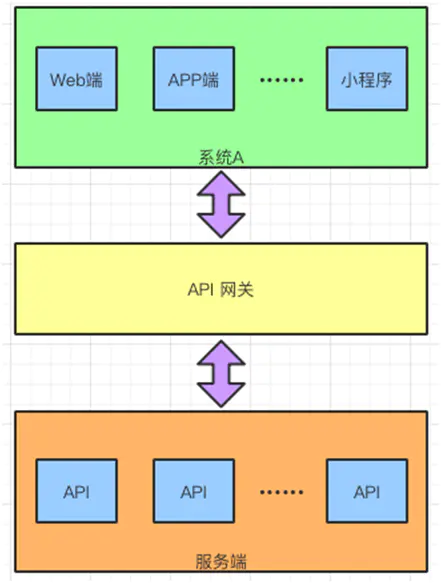
为什么要用API网关?
网关是微服务系统的唯一入口,进入系统的所有请求都需要经过 API 网关。当系统外部的应用或者客户端访问系统的时候,会遇到这样的情况:
- 系统要判断它们的权限
- 如果传输协议不一致,需要对协议进行转换
- 如果调用水平扩展的服务,需要做负载均衡
- 一旦请求流量超出系统承受的范围,需要做限流控制
- 针对每个请求以及回复,系统会记录响应的日志
所以,只要是涉及到对系统的请求,并且能够从业务中抽离出来的功能,都有可能在网关上实现。这里先简单概括一下API网关的作用:
- 身份验证和安全(用户是否安全,上传的文件是否安全,这里的网关相当于防火墙的作用)
- 协议转换(泛化调用)
- 负载均衡(Dubbo框架自带)
- 流量控制、审查和检测(拦截器)
- 动态路由(Dubbo中是不要做的,自带,Cloud需要做)
- 压力测试(双十一、双十二压测)
- 静态相应处理(页面的动静分离,静态网页直接返回)
API网关架构
API网关整理架构图如下图所示:
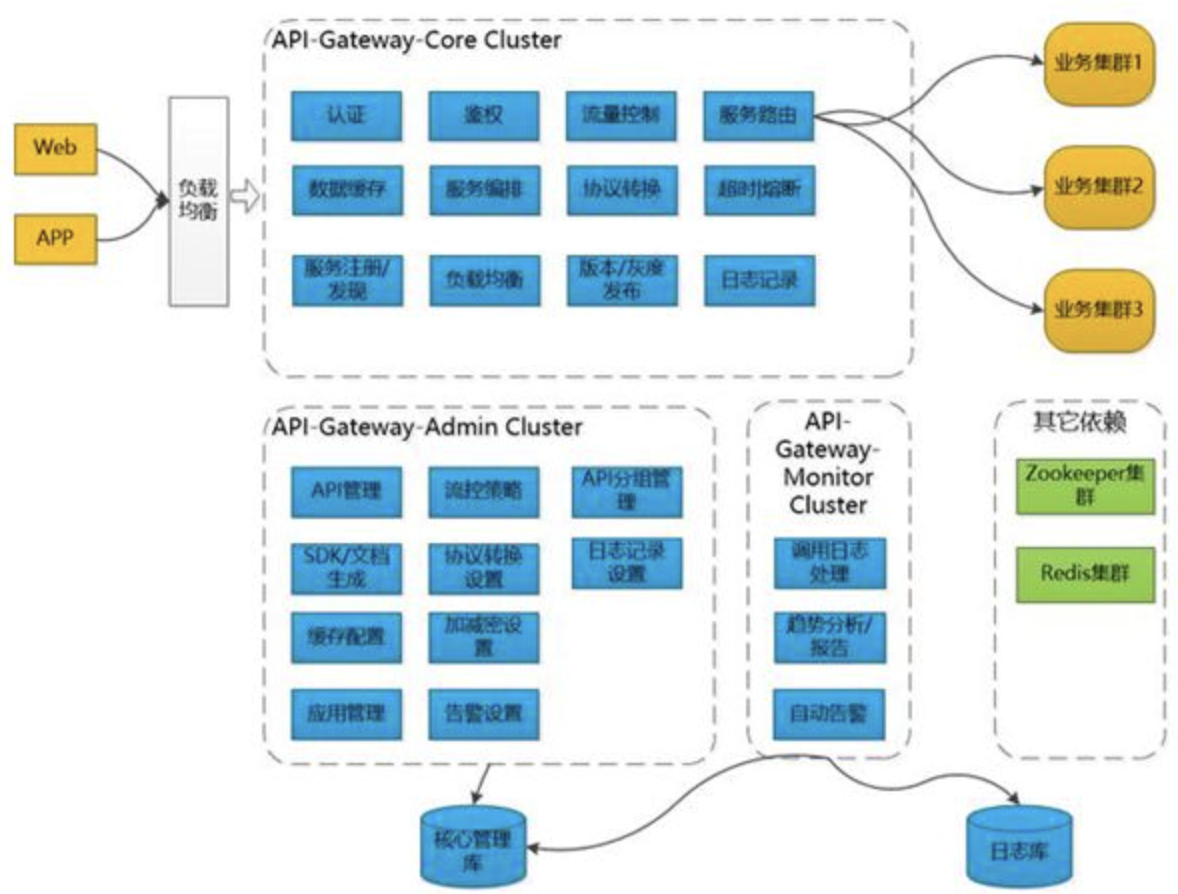
Gateway-Core 核心网关,负责接收客户端请求,调度、加载和执行组件,将请求路由到服务端,并处理其返回的结果。
Gateway-Admin 网关管理界面,可以进行 API、组件等系统基础信息的配置;例如:限流的策略,缓存配置,告警设置。
Gateway-Monitor 监控日志、生成各种运维管理报表、自动告警等;管理和监控系统主要是为核心系统服务的,起到支撑的作用。
API网关是如何实现这些功能的?
协议转换
每个系统内部服务之间的调用,可以统一使用一种协议,例如:HTTP,GRPC。
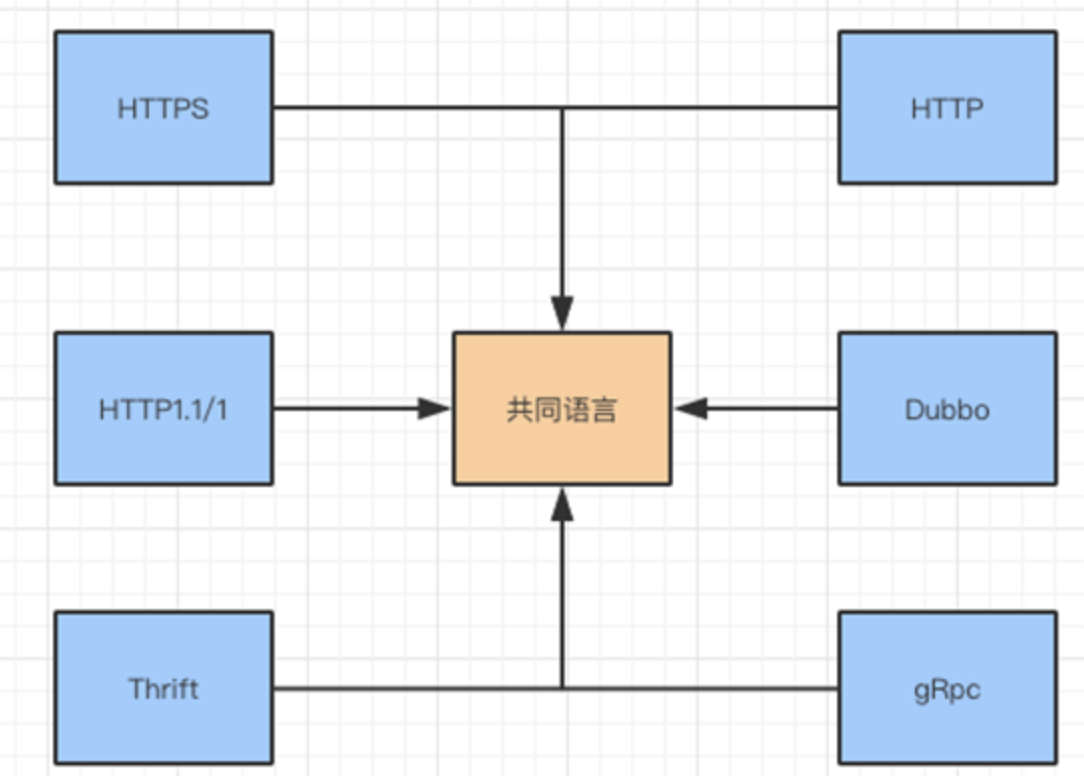
假设每个系统使用的协议不同,那么系统之间的调用或者数据传输,就存在协议转换的问题了。如果解决这个问题呢?API 网关通过泛化调用的方式实现协议之间的转化。
实际上就是将不同的协议转换成“通用协议”,然后再将通用协议转化成本地系统能够识别的协议。
这一转化工作通常在 API 网关完成。通用协议用得比较多的有 JSON,当然也有使用 XML 或者自定义 JSON 文件的。
不同的协议需要转化成共同语言进行传输。
消息从第一个“处理步骤”流入,从最后一个“处理步骤”流出,每个步骤对经过的消息进行处理,整个过程形成了一个链条。在 API 网关中也用到了类似的模式。
链式处理
消息从第一个“处理步骤”流入,从最后一个“处理步骤”流出,每个步骤对经过的消息进行处理,整个过程形成了一个链条。在 API 网关中也用到了类似的模式。

Zuul 网关过滤器链式处理
下面以 Zuul 为例,当消息出入网关需要经历一系列的过滤器。这些过滤器之间是有先后顺序的,并且在每个过滤器需要进行的工作也是各不一样:
- PRE:前置过滤器,用来处理通用事务,比如鉴权,限流,熔断降级,缓存。并且可以通过 Custom 过滤器进行扩展。
- ROUTING:路由过滤器,在这种过滤器中把用户请求发送给 Origin Server。它主要负责:协议转化和路由的工作。
- POST:后置过滤器,从 Origin Server 返回的响应信息会经过它,再返回给调用者。在返回的 Response 上加入 Response Header,同时可以做 Response 的统计和日志记录。
- ERROR:错误过滤器,当上面三个过滤器发生异常时,错误信息会进到这里,并对错误进行处理。
异步请求
所有的请求通过 API 网关访问应用服务,一旦吞吐量上去了,如何高效地处理这些请求?拿 Zuul 为例,Zuul1 采用:一个线程处理一个请求的方式。线程负责接受请求,然后调用应用返回结果。如果把网络请求看成一次 IO 操作的话,处理请求的线程,从接受请求,到服务返回响应,都是阻塞状态。
同时,如果多个线程都处在这种状态,会导致系统缓慢。因为每个网关能够开启的线程数量是有限的,特别是在访问的高峰期。
每个线程处理一个请求为了解决这个问题,Zuul2 启动了异步请求的机制。每个请求进入网关的时候,会被包装成一个事件,CPU 内核会维持一个监听器,不断轮询“请求事件”。一旦,发现请求事件,就会调用对应的应用。获取应用返回的信息以后,按照请求的要求把数据/文件放到指定的缓冲区,同时发送一个通知事件,告诉请求端数据已经就绪,可以从这个缓冲获取数据/文件。这个过程是异步的,请求的线程不用一直等待数据的返回。它在请求完毕以后,就直接返回了,这时它可以做其他的事情。
CPU 处理数据以后通知请求端实现异步处理请求有两种模式,分别是:
- Reactor
- Proactor
Reactor:通过 handle_events 事件循环处理请求。用户线程注册事件处理器之后,可以继续执行其他的工作(异步),而 Reactor 线程负责调用内核的 Select 函数检查 Socket 状态。当有 Socket 被激活时(获取网络数据),则通知相应的用户线程,执行 handle_event 进行数据读取、处理的工作。
Reactor工作原理流水图:

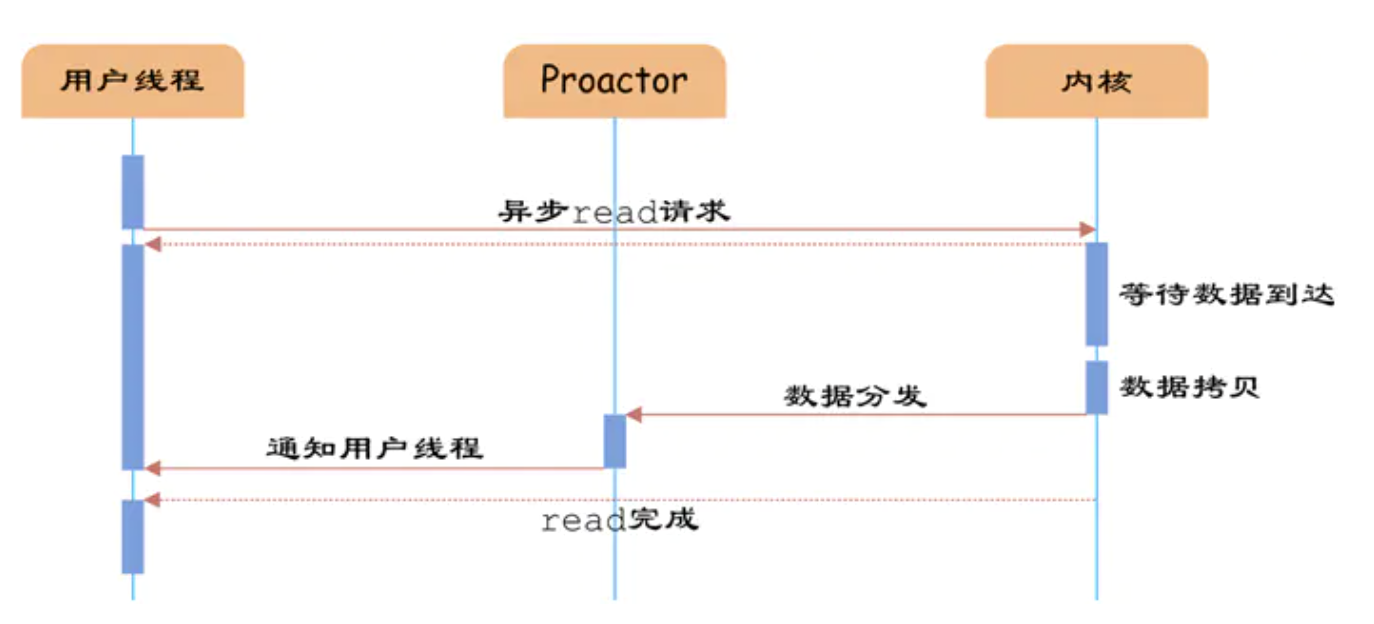
Proactor:用户线程使用 CPU 内核提供的异步 IO 发起请求,请求发起以后立即返回。CPU 内核继续执行用户请求线程代码。此时用户线程已将 AsynchronousOperation(异步处理)和 CompletionHandler(完成获取资源)注册到内核。之后操作系统开启独立的内核线程去处理 IO 操作。当请求的数据到达时,由内核负责读取 Socket(网络请求)中的数据,并写入用户指定的缓冲区中。最后内核将数据和用户线程注册的 CompletionHandler 分发给内部 Proactor,Proactor 将 IO 完成的信息通知给用户线程(一般通过调用用户线程注册的完成事件处理函数),完成异步 IO。
Proactor工作原理流水图: