文 / OceanBase解决方案架构师 韩冰
该企业成立于 1999 年,是国内领先的财税信息化综合服务提供商,主要为税务机关提供税务系统开发与运维,为纳税企业和财税中介提供互联网财税综合服务。
经过多年发展,为了更好地支撑用户业务需求和数据需求,该企业发展出规模庞大的 IT 基础设施规模,拥有公有云、私有云等多样基础设施,软件层面同样具有很高的复杂度。这无疑给企业在成本、运维、开发效率上带来了种种挑战。
作为一家重视技术,希望通过技术给社会带来美好改变的公司,该企业一直在紧密关注、密切跟踪前沿技术的发展趋势。通过不断地调查研究新技术并引入新技术,不仅完成了对业务的赋能,还同时实现了各项效率的提升和成本的降低。本文,仅就数据库这一维度,分享其发展历程、选型思考以及收获成效。
从集中式到真正的分布式
如下图所示,数据库从集中式到真正的分布式,经历了四个阶段的发展历程。在企业发展初期,业务规模较小时,集中式架构的数据库产品就可以满足业务发展需求,MySQL 成为业务的首选,通过 RAID 和主备集群就可以比较好地满足容灾需求。
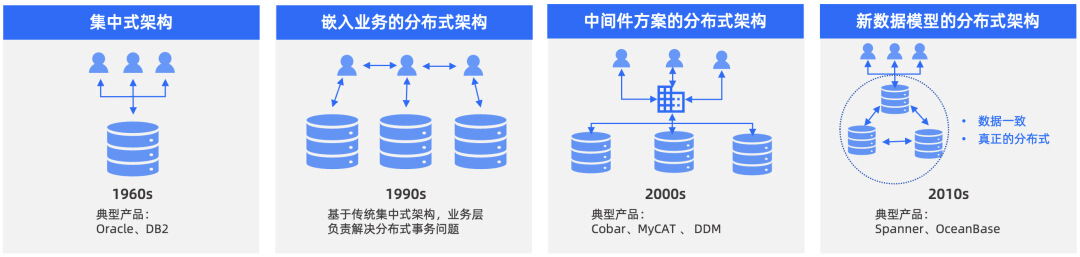
但随着业务量的大幅增长,给数据库带来大量流量和大量数据支撑的需求,此时,集中式数据库已经无法很好地满足业务需要。 为了满足业务需求,企业不得不对数据库进行拆分,以分库分表方式的分布式架构方案尤为流行。 其中,主流的分库分表方案如下:
-
方案一:嵌入业务的分布式架构,应用嵌入分布式 SDK,在业务层做分库分表处理;
-
方案二:中间件的分布式架构,通过引入分库分表中间件,集中处理分库分表。
使用分库分表的方式可以快速增加数据库的服务和存储容量,但同时也对业务和运维工作提出了新的要求和挑战。比如:
-
应用分布式改造, 无论使用嵌入业务或者中间件的分布式架构,都需要业务 SQL 为了适应分布式进行改造,并且因为底层的节点都是各自独立的,对于索引、复杂事物、和关联业务都有比较多的限制;
-
节点无法按需扩展, 因为使用比较固定的分库分表规则,同时考虑扩容需求,分库分表的方式一般要求扩容都是等比扩容,即扩容一次就要扩容到原来资源配置的一倍,灵活度比较低;同时,因为各自实例独立,导致扩容后有大量的节点间数据迁移,对服务质量有比较大的影响;
-
初始节点数多, 因为以上两个原因的限制,为了屏蔽掉改造和扩容对业务以及数据倾斜的影响,一般都会一次规划到位,导致初始节点数量比较多,整体资源利用水位比较低。
分库分表的分布式架构在承载业务发展的同时,也暴露出各种弊端,这也证明了这种方案只是分布式架构的中间过渡方案。之后,新数据模式的分布式架构,即原生的分布式架构出现,很好地解决了分库分表的分布式架构的问题。原生分布式架构能够提供更好的服务能力,也是更好地解决当前业务阶段降本提效诉求的一种更有效的手段。
选择进步技术收获明显成效
明确采用原生分布式架构的数据库后,企业开始从众多产品中选型能够替换分库分表中间件的数据库产品,考虑到未来的长远发展以及与业务契合度,最终选定 OceanBase,并迅速开展迁移工作。
▋ 资源整合,多套实例收归一套集群
原有分库分表架构下,各个物理表分别由不同的 MySQL 实例提供服务。因为业务高峰时段数据倾斜的存在,必然导致不同 MySQL 实例在不同时间段复杂不均衡。为了保证业务平稳,需要为每个 MySQL 配置满足业务安全的最大配置规格,这必然导致资源使用上的浪费。
OceanBase 可以通过使用分区表方式将原来的分库分表的物理表汇聚到一个物理表,同时还可以保留原来的映射关系。
通过将物理分区合理分布到多个计算节点上,充分使用所有计算资源,在保证资源使用在合理的水位基础上,将原来多个 MySQL 实例的计算资源整合到一个 OceanBase 集群中。通过 OceanBase 提供的自动均衡能力,保证每个节点的资源使用相对平均,保证资源的充分利用。
企业将原来配置了 16 个 8C16G 资源规格的 MySQL 迁移到 OceanBase,仅使用 32C 双机房的 OceanBase 集群就能稳定支撑业务服务质量,计算资源节约显著。
▋ 高级压缩技术,节省 85% 存储空间
经过二十余年的发展,企业有着庞大的数据存量,一直在寻找一款既能节省数据存储成本,还能保有原性能甚至提升性能的数据库。经了解和调研,得知 OceanBase 使用 LSM-Tree 存储引擎,采用密实存储消除了存储空洞,在存储上使用行列混存的方式,同时通过对列数据进行编码,并且对编码后的数据最终提供了高级压缩的能力。
使用该高级压缩能力,存储压缩效果非常明显。比如,某个业务原来的数据量在 原数据库大约上有 20T,将这些数据迁移到 OceanBase 后,只占用了 3T 的数据存储,相当于节省了 85% 的存储空间。
▋ HTAP 让一份数据既能事务处理又能实时分析
因为原数据底层存储实际分布在不同的 MySQL 实例上,如果想在全库级别进行复杂查询,需要将数据汇集到一处,且需要多条数据迁移链路和汇聚分析库的配置。如此一来,会导致两个问题:
-
问题一,数据时效性。 因为使用数据同步链路进行数据迁移,分库分表中间件后端实际的 MySQL 实例越多,需要的数据同步链路就越多。在所有链路正常同步的情况下,数据延迟取决于同步的速度。如果任何一条同步链路发生延迟都会产生木桶效应,数据的最大延迟取决于最慢链路的速度。
-
问题二,成本上涨。 当前架构下的成本分列为两项,一项是同步链路的成本,这个成本由同步的链路数量和数据的决定;另一项是汇聚分析库的成本,这个成本由资源配置和数据量决定。
大数据时代,实时数据分析必不可少,作为国内领先的财税信息化综合服务提供商更是如此。然而,以上数据时效性和成本上涨的问题,一直困扰着企业。
OceanBase 可以在一份数据上进行 HTAP 的处理,不需要数据同步和新采购汇聚分析库。同时,企业可以设置分析业务使用的资源配置或者调整主可用区独立一份资源给到分析业务使用。通过以上手段保证不会因为分析 AP 业务占用过多资源,导致在线 TP 业务的不稳定性。
携手共进,期待迁移便利性更上一层楼
如下图所示,为迁移过程示意图。
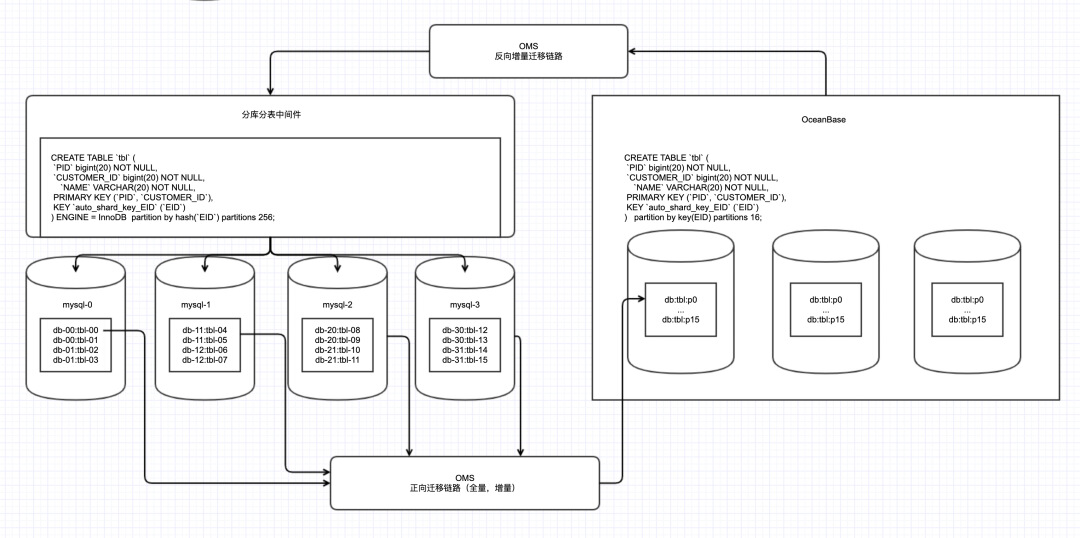
-
正向迁移过程: 使用 OMS 工具迁移分库分表中间件后端实际的 MySQL,如此,分库分表中间件后端的每一个 MySQL 需要单独一条链路进行数据迁移到 OceanBase;在迁移之前,需要根据分库分表中间件的表结果先修改 DDL 在 OceanBase 建立表结构。
-
反向迁移过程: 在业务切换到 OceanBase 之后,业务写入的数据需要从 OceanBase 将增量数据通过 OMS 工具写入到分库分表中间件里。
通过上述迁移过程可以看到,虽然整体使用过程在功能和效率上都有所保证,但是需要很多独立的 OMS 链路,整个流程的配置和维护复杂度都比较高。
作为 OceanBase 的使用者和受益者,为了让更多业务享受分布式升级带来的降本提效收益,从业务角度出发,OceanBase 迁移的便利性改进,将是最期待的改进点:
-
自动结构迁移。 因为分库分表中间件的建表 DDL 迁移到 OceanBase 的修改过程,规则是比较固定的,后续将分库分表中间件的结构迁移自动完成将带来很大便利性;
-
统一的正向数据迁移。 在正向迁移过程中需要根据实际的 MySQL 数量配置 OMS 实际迁移链路,包括后续的数据校验和切换都需要单独操作,将这个过程统一化将大大增强操作便利性。更进一步,在将正向的数据迁移过程统一后,可以方便地增加反向迁移的链路。