2023.2.13
深度学习 是加深了层的深度神经网络的学习过程。基于之前介绍的网络,只需要通过 叠加层, 就可以创建深度网络
之前的学习,已经学习到了很多东西,比如构成神经网络的各种层、参数优化方法、误差反向传播法,卷积神经网络 现在将这些技术结合起来构建一个深度网络去完成MNIST识别任务。
一,构建一个更深的网络:
这个网络使用He初始值作为权重初始值,使用Adam作为权重参数的更新;
He值的相关内容参考文章: “深度学习”学习日记。与学习有关的技巧--权重的初始值_Anthony陪你度过漫长岁月的博客-CSDN博客权重的初始值https://blog.csdn.net/m0_72675651/article/details/128748314
Adam的相关内容可以参考:“深度学习”学习日记。与学习相关的技巧 -- 参数的更新_Anthony陪你度过漫长岁月的博客-CSDN博客_深度学习参数更新SGD函数的缺点;由于权重偏置参数更新的Momentum函数,AdaGrad函数,Adam函数https://blog.csdn.net/m0_72675651/article/details/128737715
这个网络有以下特点:
1,基于3×3的小型卷积核(滤波器)的卷积层;
2,激活函数是ReLU;
3,全连接层的后面使用Droput层;
实验代码:这里的epoch设置为20,可能神经网络训练(学习)耗时会在5小时以上,epoch可以减小或增大以缩减或增加雪莲时长,当然对正确率也有影响。
import os
import sys
import numpy as np
import matplotlib as plt
from collections import OrderedDict
sys.path.append(os.pardir)
# MNIST数据导入
try:
import urllib.request
except ImportError:
raise ImportError('You should use Python 3.x')
import os.path
import gzip
import pickle
url_base = 'http://yann.lecun.com/exdb/mnist/'
key_file = {
'train_img': 'train-images-idx3-ubyte.gz',
'train_label': 'train-labels-idx1-ubyte.gz',
'test_img': 't10k-images-idx3-ubyte.gz',
'test_label': 't10k-labels-idx1-ubyte.gz'
}
dataset_dir = os.path.dirname(os.path.abspath(__file__))
save_file = dataset_dir + "/mnist.pkl"
train_num = 60000
test_num = 10000
img_dim = (1, 28, 28)
img_size = 784
def _download(file_name):
file_path = dataset_dir + "/" + file_name
if os.path.exists(file_path):
return
print("Downloading " + file_name + " ... ")
urllib.request.urlretrieve(url_base + file_name, file_path)
print("Done")
def download_mnist():
for v in key_file.values():
_download(v)
def _load_label(file_name):
file_path = dataset_dir + "/" + file_name
print("Converting " + file_name + " to NumPy Array ...")
with gzip.open(file_path, 'rb') as f:
labels = np.frombuffer(f.read(), np.uint8, offset=8)
print("Done")
return labels
def _load_img(file_name):
file_path = dataset_dir + "/" + file_name
print("Converting " + file_name + " to NumPy Array ...")
with gzip.open(file_path, 'rb') as f:
data = np.frombuffer(f.read(), np.uint8, offset=16)
data = data.reshape(-1, img_size)
print("Done")
return data
def _convert_numpy():
dataset = {}
dataset['train_img'] = _load_img(key_file['train_img'])
dataset['train_label'] = _load_label(key_file['train_label'])
dataset['test_img'] = _load_img(key_file['test_img'])
dataset['test_label'] = _load_label(key_file['test_label'])
return dataset
def init_mnist():
download_mnist()
dataset = _convert_numpy()
print("Creating pickle file ...")
with open(save_file, 'wb') as f:
pickle.dump(dataset, f, -1)
print("Done!")
def _change_one_hot_label(X):
T = np.zeros((X.size, 10))
for idx, row in enumerate(T):
row[X[idx]] = 1
return T
def load_mnist(normalize=True, flatten=True, one_hot_label=False):
if not os.path.exists(save_file):
init_mnist()
with open(save_file, 'rb') as f:
dataset = pickle.load(f)
if normalize:
for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].astype(np.float32)
dataset[key] /= 255.0
if one_hot_label:
dataset['train_label'] = _change_one_hot_label(dataset['train_label'])
dataset['test_label'] = _change_one_hot_label(dataset['test_label'])
if not flatten:
for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].reshape(-1, 1, 28, 28)
return (dataset['train_img'], dataset['train_label']), (dataset['test_img'], dataset['test_label'])
if __name__ == '__main__':
init_mnist()
# 函数部分
def softmax(x):
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x) # 溢出对策
return np.exp(x) / np.sum(np.exp(x))
def cross_entropy_error(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
if t.size == y.size:
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
def im2col(input_data, filter_h, filter_w, stride=1, pad=0):
N, C, H, W = input_data.shape
out_h = (H + 2 * pad - filter_h) // stride + 1
out_w = (W + 2 * pad - filter_w) // stride + 1
img = np.pad(input_data, [(0, 0), (0, 0), (pad, pad), (pad, pad)], 'constant')
col = np.zeros((N, C, filter_h, filter_w, out_h, out_w))
for y in range(filter_h):
y_max = y + stride * out_h
for x in range(filter_w):
x_max = x + stride * out_w
col[:, :, y, x, :, :] = img[:, :, y:y_max:stride, x:x_max:stride]
col = col.transpose(0, 4, 5, 1, 2, 3).reshape(N * out_h * out_w, -1)
return col
def col2im(col, input_shape, filter_h, filter_w, stride=1, pad=0):
N, C, H, W = input_shape
out_h = (H + 2 * pad - filter_h) // stride + 1
out_w = (W + 2 * pad - filter_w) // stride + 1
col = col.reshape(N, out_h, out_w, C, filter_h, filter_w).transpose(0, 3, 4, 5, 1, 2)
img = np.zeros((N, C, H + 2 * pad + stride - 1, W + 2 * pad + stride - 1))
for y in range(filter_h):
y_max = y + stride * out_h
for x in range(filter_w):
x_max = x + stride * out_w
img[:, :, y:y_max:stride, x:x_max:stride] += col[:, :, y, x, :, :]
return img[:, :, pad:H + pad, pad:W + pad]
# 参数更新方法
class SGD:
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
class Momentum:
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]
params[key] += self.v[key]
class Nesterov:
def __init__(self, lr=0.01, momentum=0.9):
self.lr = lr
self.momentum = momentum
self.v = None
def update(self, params, grads):
if self.v is None:
self.v = {}
for key, val in params.items():
self.v[key] = np.zeros_like(val)
for key in params.keys():
self.v[key] *= self.momentum
self.v[key] -= self.lr * grads[key]
params[key] += self.momentum * self.momentum * self.v[key]
params[key] -= (1 + self.momentum) * self.lr * grads[key]
class AdaGrad:
def __init__(self, lr=0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] += grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class RMSprop:
def __init__(self, lr=0.01, decay_rate=0.99):
self.lr = lr
self.decay_rate = decay_rate
self.h = None
def update(self, params, grads):
if self.h is None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key] *= self.decay_rate
self.h[key] += (1 - self.decay_rate) * grads[key] * grads[key]
params[key] -= self.lr * grads[key] / (np.sqrt(self.h[key]) + 1e-7)
class Adam:
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0
self.m = None
self.v = None
def update(self, params, grads):
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val)
self.v[key] = np.zeros_like(val)
self.iter += 1
lr_t = self.lr * np.sqrt(1.0 - self.beta2 ** self.iter) / (1.0 - self.beta1 ** self.iter)
for key in params.keys():
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key] ** 2 - self.v[key])
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
# 传递层(类)
class Affine:
def __init__(self, W, b):
self.W = W
self.b = b
self.x = None
self.original_x_shape = None
# 权重和偏置参数的导数
self.dW = None
self.db = None
def forward(self, x):
# 对应张量
self.original_x_shape = x.shape
x = x.reshape(x.shape[0], -1)
self.x = x
out = np.dot(self.x, self.W) + self.b
return out
def backward(self, dout):
dx = np.dot(dout, self.W.T)
self.dW = np.dot(self.x.T, dout)
self.db = np.sum(dout, axis=0)
dx = dx.reshape(*self.original_x_shape) # 还原输入数据的形状(对应张量)
return dx
# 输出与损失函数层
class SoftmaxWithLoss:
def __init__(self):
self.loss = None
self.y = None # softmax的输出
self.t = None # 监督数据
def forward(self, x, t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y, self.t)
return self.loss
def backward(self, dout=1):
batch_size = self.t.shape[0]
if self.t.size == self.y.size: # 监督数据是one-hot-vector的情况
dx = (self.y - self.t) / batch_size
else:
dx = self.y.copy()
dx[np.arange(batch_size), self.t] -= 1
dx = dx / batch_size
return dx
# 正则化
class Dropout:
def __init__(self, dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self, x, train_flg=True):
if train_flg:
self.mask = np.random.rand(*x.shape) > self.dropout_ratio
return x * self.mask
else:
return x * (1.0 - self.dropout_ratio)
def backward(self, dout):
return dout * self.mask
# 激活函数
class Relu:
def __init__(self):
self.mask = None
def forward(self, x):
self.mask = (x <= 0)
out = x.copy()
out[self.mask] = 0
return out
def backward(self, dout):
dout[self.mask] = 0
dx = dout
return dx
# 卷积层
class Convolution:
def __init__(self, W, b, stride=1, pad=0):
self.W = W
self.b = b
self.stride = stride
self.pad = pad
self.x = None
self.col = None
self.col_W = None
self.dW = None
self.db = None
def forward(self, x):
FN, C, FH, FW = self.W.shape
N, C, H, W = x.shape
out_h = 1 + int((H + 2 * self.pad - FH) / self.stride)
out_w = 1 + int((W + 2 * self.pad - FW) / self.stride)
col = im2col(x, FH, FW, self.stride, self.pad)
col_W = self.W.reshape(FN, -1).T
out = np.dot(col, col_W) + self.b
out = out.reshape(N, out_h, out_w, -1).transpose(0, 3, 1, 2)
self.x = x
self.col = col
self.col_W = col_W
return out
def backward(self, dout):
FN, C, FH, FW = self.W.shape
dout = dout.transpose(0, 2, 3, 1).reshape(-1, FN)
self.db = np.sum(dout, axis=0)
self.dW = np.dot(self.col.T, dout)
self.dW = self.dW.transpose(1, 0).reshape(FN, C, FH, FW)
dcol = np.dot(dout, self.col_W.T)
dx = col2im(dcol, self.x.shape, FH, FW, self.stride, self.pad)
return dx
class Pooling:
def __init__(self, pool_h, pool_w, stride=1, pad=0):
self.pool_h = pool_h
self.pool_w = pool_w
self.stride = stride
self.pad = pad
self.x = None
self.arg_max = None
def forward(self, x):
N, C, H, W = x.shape
out_h = int(1 + (H - self.pool_h) / self.stride)
out_w = int(1 + (W - self.pool_w) / self.stride)
col = im2col(x, self.pool_h, self.pool_w, self.stride, self.pad)
col = col.reshape(-1, self.pool_h * self.pool_w)
arg_max = np.argmax(col, axis=1)
out = np.max(col, axis=1)
out = out.reshape(N, out_h, out_w, C).transpose(0, 3, 1, 2)
self.x = x
self.arg_max = arg_max
return out
def backward(self, dout):
dout = dout.transpose(0, 2, 3, 1)
pool_size = self.pool_h * self.pool_w
dmax = np.zeros((dout.size, pool_size))
dmax[np.arange(self.arg_max.size), self.arg_max.flatten()] = dout.flatten()
dmax = dmax.reshape(dout.shape + (pool_size,))
dcol = dmax.reshape(dmax.shape[0] * dmax.shape[1] * dmax.shape[2], -1)
dx = col2im(dcol, self.x.shape, self.pool_h, self.pool_w, self.stride, self.pad)
return dx
# 加深层的卷积神经网络的结构
class DeepConvNet:
def __init__(self, input_dim=(1, 28, 28),
conv_param_1={'filter_num': 16, 'filter_size': 3, 'pad': 1, 'stride': 1},
conv_param_2={'filter_num': 16, 'filter_size': 3, 'pad': 1, 'stride': 1},
conv_param_3={'filter_num': 32, 'filter_size': 3, 'pad': 1, 'stride': 1},
conv_param_4={'filter_num': 32, 'filter_size': 3, 'pad': 2, 'stride': 1},
conv_param_5={'filter_num': 64, 'filter_size': 3, 'pad': 1, 'stride': 1},
conv_param_6={'filter_num': 64, 'filter_size': 3, 'pad': 1, 'stride': 1},
hidden_size=50, output_size=10):
# 初始化权重
# 各层的神经元平均与前一层的几个神经元有连接(TODO:自动计算)
pre_node_nums = np.array(
[1 * 3 * 3, 16 * 3 * 3, 16 * 3 * 3, 32 * 3 * 3, 32 * 3 * 3, 64 * 3 * 3, 64 * 4 * 4, hidden_size])
wight_init_scales = np.sqrt(2.0 / pre_node_nums) # 使用ReLU的情况下推荐的初始值
self.params = {}
pre_channel_num = input_dim[0]
for idx, conv_param in enumerate(
[conv_param_1, conv_param_2, conv_param_3, conv_param_4, conv_param_5, conv_param_6]):
self.params['W' + str(idx + 1)] = wight_init_scales[idx] * np.random.randn(conv_param['filter_num'],
pre_channel_num,
conv_param['filter_size'],
conv_param['filter_size'])
self.params['b' + str(idx + 1)] = np.zeros(conv_param['filter_num'])
pre_channel_num = conv_param['filter_num']
self.params['W7'] = wight_init_scales[6] * np.random.randn(64 * 4 * 4, hidden_size)
self.params['b7'] = np.zeros(hidden_size)
self.params['W8'] = wight_init_scales[7] * np.random.randn(hidden_size, output_size)
self.params['b8'] = np.zeros(output_size)
# 生成层
self.layers = []
self.layers.append(Convolution(self.params['W1'], self.params['b1'],
conv_param_1['stride'], conv_param_1['pad']))
self.layers.append(Relu())
self.layers.append(Convolution(self.params['W2'], self.params['b2'],
conv_param_2['stride'], conv_param_2['pad']))
self.layers.append(Relu())
self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))
self.layers.append(Convolution(self.params['W3'], self.params['b3'],
conv_param_3['stride'], conv_param_3['pad']))
self.layers.append(Relu())
self.layers.append(Convolution(self.params['W4'], self.params['b4'],
conv_param_4['stride'], conv_param_4['pad']))
self.layers.append(Relu())
self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))
self.layers.append(Convolution(self.params['W5'], self.params['b5'],
conv_param_5['stride'], conv_param_5['pad']))
self.layers.append(Relu())
self.layers.append(Convolution(self.params['W6'], self.params['b6'],
conv_param_6['stride'], conv_param_6['pad']))
self.layers.append(Relu())
self.layers.append(Pooling(pool_h=2, pool_w=2, stride=2))
self.layers.append(Affine(self.params['W7'], self.params['b7']))
self.layers.append(Relu())
self.layers.append(Dropout(0.5))
self.layers.append(Affine(self.params['W8'], self.params['b8']))
self.layers.append(Dropout(0.5))
self.last_layer = SoftmaxWithLoss()
def predict(self, x, train_flg=False):
for layer in self.layers:
if isinstance(layer, Dropout):
x = layer.forward(x, train_flg)
else:
x = layer.forward(x)
return x
def loss(self, x, t):
y = self.predict(x, train_flg=True)
return self.last_layer.forward(y, t)
def accuracy(self, x, t, batch_size=100):
if t.ndim != 1: t = np.argmax(t, axis=1)
acc = 0.0
for i in range(int(x.shape[0] / batch_size)):
tx = x[i * batch_size:(i + 1) * batch_size]
tt = t[i * batch_size:(i + 1) * batch_size]
y = self.predict(tx, train_flg=False)
y = np.argmax(y, axis=1)
acc += np.sum(y == tt)
return acc / x.shape[0]
def gradient(self, x, t):
self.loss(x, t)
dout = 1
dout = self.last_layer.backward(dout)
tmp_layers = self.layers.copy()
tmp_layers.reverse()
for layer in tmp_layers:
dout = layer.backward(dout)
grads = {}
for i, layer_idx in enumerate((0, 2, 5, 7, 10, 12, 15, 18)):
grads['W' + str(i + 1)] = self.layers[layer_idx].dW
grads['b' + str(i + 1)] = self.layers[layer_idx].db
return grads
def save_params(self, file_name="params.pkl"):
params = {}
for key, val in self.params.items():
params[key] = val
with open(file_name, 'wb') as f:
pickle.dump(params, f)
def load_params(self, file_name="params.pkl"):
with open(file_name, 'rb') as f:
params = pickle.load(f)
for key, val in params.items():
self.params[key] = val
for i, layer_idx in enumerate((0, 2, 5, 7, 10, 12, 15, 18)):
self.layers[layer_idx].W = self.params['W' + str(i + 1)]
self.layers[layer_idx].b = self.params['b' + str(i + 1)]
# 训练模型(神经网络的学习过程)
class Trainer:
def __init__(self, network, x_train, t_train, x_test, t_test,
epochs=20, mini_batch_size=100,
optimizer='SGD', optimizer_param={'lr': 0.01},
evaluate_sample_num_per_epoch=None, verbose=True):
self.network = network
self.verbose = verbose
self.x_train = x_train
self.t_train = t_train
self.x_test = x_test
self.t_test = t_test
self.epochs = epochs
self.batch_size = mini_batch_size
self.evaluate_sample_num_per_epoch = evaluate_sample_num_per_epoch
# optimzer
optimizer_class_dict = {'sgd': SGD, 'momentum': Momentum, 'nesterov': Nesterov,
'adagrad': AdaGrad, 'rmsprpo': RMSprop, 'adam': Adam}
self.optimizer = optimizer_class_dict[optimizer.lower()](**optimizer_param)
self.train_size = x_train.shape[0]
self.iter_per_epoch = max(self.train_size / mini_batch_size, 1)
self.max_iter = int(epochs * self.iter_per_epoch)
self.current_iter = 0
self.current_epoch = 0
self.train_loss_list = []
self.train_acc_list = []
self.test_acc_list = []
def train_step(self):
batch_mask = np.random.choice(self.train_size, self.batch_size)
x_batch = self.x_train[batch_mask]
t_batch = self.t_train[batch_mask]
grads = self.network.gradient(x_batch, t_batch)
self.optimizer.update(self.network.params, grads)
loss = self.network.loss(x_batch, t_batch)
self.train_loss_list.append(loss)
if self.verbose: print("train loss:" + str(loss))
if self.current_iter % self.iter_per_epoch == 0:
self.current_epoch += 1
x_train_sample, t_train_sample = self.x_train, self.t_train
x_test_sample, t_test_sample = self.x_test, self.t_test
if not self.evaluate_sample_num_per_epoch is None:
t = self.evaluate_sample_num_per_epoch
x_train_sample, t_train_sample = self.x_train[:t], self.t_train[:t]
x_test_sample, t_test_sample = self.x_test[:t], self.t_test[:t]
train_acc = self.network.accuracy(x_train_sample, t_train_sample)
test_acc = self.network.accuracy(x_test_sample, t_test_sample)
self.train_acc_list.append(train_acc)
self.test_acc_list.append(test_acc)
if self.verbose: print(
"=== epoch:" + str(self.current_epoch) + ", train acc:" + str(train_acc) + ", test acc:" + str(
test_acc) + " ===")
self.current_iter += 1
def train(self):
for i in range(self.max_iter):
self.train_step()
test_acc = self.network.accuracy(self.x_test, self.t_test)
if self.verbose:
print("=============== Final Test Accuracy ===============")
print("test acc:" + str(test_acc))
# 主函数
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=False)
network = DeepConvNet()
trainer = Trainer(network, x_train, t_train, x_test, t_test,
epochs=20, mini_batch_size=100,
optimizer='Adam', optimizer_param={'lr': 0.001},
evaluate_sample_num_per_epoch=1000)
trainer.train()
# 保存参数
network.save_params("deep_convnet_params.pkl")
print("Saved Network Parameters!")
运行结果:
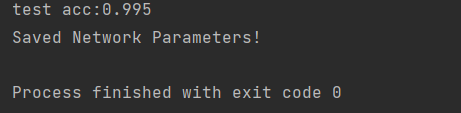
从这些特征看出,他的识别率达到0.995,可以说非常优秀了。
对比以前的神经网络的测试集正确率效果更加可观,
“深度学习”学习日记。卷积神经网络--用CNN的实现MINIST识别任务_Anthony陪你度过漫长岁月的博客-CSDN博客搭建CNN去实现MNIST数据集的识别任务https://blog.csdn.net/m0_72675651/article/details/128980999
二,进一步提高识别精度:
世界上有许多用于完成MNIST的神经网络模型,截至2016年6月,对MNIST数据集的最高识别精度是0.9979,该方发也是以CNN为基础的。不过,他用的CNN并不是特别深层的网络(两层卷积层、两层全连接层)
除了加深层神经网络以外,我们也可以从 集成学习、学习衰减、Data Augmentation(数据扩充) 等助于提高识别精度。 特别是数据扩充。
1,数据扩充:
Data Augmentation是基于算法“人为地”扩充输入图像(训练图像)相当于,把训练集图像,通过施加旋转、垂直、平移或水平方向上的移动等微小变化,增加图像数量。
2,加深层的动机:
根据教材的实验结果表示,性能优良的神经网络有,有逐渐加深网络的层趋势。也就是说,可以看到的层越深,识别性能也越高。
加深层有一个优点就是可以减少神经网络的参数数量。等价于用更少的参数权重去达到同等水平(或者更强)的表现力
关于卷积运算参考文章:“深度学习”学习日记。卷积神经网络--卷积层_Anthony陪你度过漫长岁月的博客-CSDN博客卷积层https://blog.csdn.net/m0_72675651/article/details/128861606
掌握了卷积的运算法则后,我们可以知道公式:
输入数据的形状大小为(H,W),滤波器(卷积核)的大小为(FH,FW),输出大小为(OH,OF);
当一个形状为(5,5)输入数据,只有一层卷积层将结果经过卷积运算变成一个(1,1),则需要一个5×5的卷积核,一共25个参数;
当我们有两层卷积层,可以在第一层先通过一个3×3的卷积核,第二层再通过一个3×3的卷积核,这时,我们值需要18的参数;
像这样,通过叠加小型滤波器来加深神经网络的好处就是可以减少参数的设置,扩大 感受视野 (receptive field,给神经元施加变化的某个局部空间区域)。并且,通过叠加层,将ReLU层,将ReLU的激活函数夹在卷积层的中见,进一步提高了网络的表现力。这是因为像网络添加了基于激活函数的“非线性”表现力,通过非线性函数的叠加,可以表现更加复杂的东西。
加深层的第二个好处就是是的学习更加高效:
这篇文章讲到 :“深度学习”学习日记。卷积神经网络--用CNN的实现MINIST识别任务_Anthony陪你度过漫长岁月的博客-CSDN博客搭建CNN去实现MNIST数据集的识别任务https://blog.csdn.net/m0_72675651/article/details/128980999
根据深度学习的可视化相关研究,随着层次的加深,提取的信息(反应强烈的神经元)也会缘来缘抽象。最开始是对简单的边缘有相应,接下来的层对纹理有反应,再后面的层会对更加复杂的物体部件有反应。也就是说,随着层次的加深,神经元从简单的形状向“高级”信息变化。
如果,我们想要写一个识别“狗”的神经网络,那我使用浅层神经网络的话我们就需要,在每一层神经网络中考虑很多参数(权重),导致耗时很长,正确率也差强人意;
如果通过加深网络去实现的化,就可以分层次地分解需要学习的问题。因此,在每一层卷积层中索要解决的问题就会变得简单。比如,最开始的层值要专注与学习边缘,只用较少的数据就可以高效的学习,通过加深层,可以使用上一次提取的边缘信息。
不够要注意的是,深层化是由大数据、计算能力等即便加深层也能正确地进行学习的新技术与环境支撑的。






![[chatGPT] 如何通过JNI在Android上显示实时视频流](https://img-blog.csdnimg.cn/de6c4256ef734f3d90544d68d613ebec.png)