Multimodal super-resolution reconstruction of infrared and visible images via deep learning
(基于深度学习的红外和可见光图像多模态超分辨率重建)
提出了一种基于编解码器结构的红外-可见光图像融合方法。图像融合任务被重新表述为保持红外-可见光图像的结构和强度比的问题。设计了相应的损失函数来扩大热目标与背景的权重差。此外,针对传统网络映射函数不适用于自然场景的问题,提出了一种基于回归网络的单幅图像超分辨率重建方法。该算法考虑了正向生成和反向回归模型,通过双重映射约束,缩小了不相关函数映射空间,逼近理想场景数据。实验结果表明,与现有方法相比,该方法在视觉效果和客观评价方面均具有上级的性能。此外,它可以稳定地提供与人类视觉观察一致的高分辨率重建结果,同时弥合红外-可见光图像之间的分辨率差距。
介绍
图像融合技术旨在利用特定算法从多个源图像生成信息丰富的图像。红外与可见光图像融合技术由于能够将不同的信息进行融合,在探测成像系统中起着举足轻重的作用。因此,融合结果具有更清晰和完整的场景描述,这有利于人的感知和机器处理。融合图像可以合成出具有源图像互补信息的新图像。最大限度地整合兴趣信息是揭示生物医学、森林消防和安全驾驶中的新见解和基本科学问题的基本瓶颈。例如,通常通过应用多曝光融合(MEF)方法来生成高动态范围(HDR)图像。HDR成像方法可以提供更丰富的图像细节,使重建图像更加清晰,更符合人眼视觉观察的要求。基于这种方法,红外和可见光融合算法可以综合各种信息的优点。一般来说,红外图像缺乏纹理信息,不能有效表征场景。但由于其固有的热辐射特性和在长波红外波段实现云层穿透成像的能力,已得到广泛应用。相比之下,可见光图像包含空间分辨率较高的纹理细节,有利于增强目标识别能力,符合人类视觉系统。但是,可见光图像也有一个致命的缺点:不可能在低照明条件下获得高质量的图像。可见光与红外成像相互依存、共同促进。
尽管图像融合技术有了显著的进步,但由于软件算法和硬件技术的限制,长波红外探测器的像素尺寸已经接近物理极限(17 μm)。同时,随着成像分辨率的提高,器件的制造成本也将急剧增加。因此,现有的双波段图像融合技术不足以稳定实现全天候高分辨率成像。此时,传统的超分辨率(SR)模型和算法已不再适用,其计算复杂度给应用增加了大规模计算的压力。近年来,深度学习(Deep Learning,DL)以其突出的特征提取、表示能力、强鲁棒性和高效的重构性能,成为图像融合领域的一项强有力的技术。从Deepmind公司研发的人工智能机器人到波士顿的强力机器狗,令人鼓舞的消息接连传来。人工智能在我们身边产生了一个熟悉的词汇。这是智能机器逐步取代人工操作的显著表现。这种趋势是由对结合人工智能计算技术的多维传感器的出现的日益增长的需求驱动的。几十年来,深度学习技术成为海量数据时代的研究热点。学术界和工业界都对该技术表现出浓厚的兴趣,尤其是在计算机视觉方面。作为近年来兴起的一种“数据驱动“技术,它在图像分类、目标检测]和识别等许多应用中取得了卓越的成就。如图1所示,克服空间采样不足导致的像素化成像问题也是多图像超分辨率融合(Multi-SR-Fusion)技术的新奇。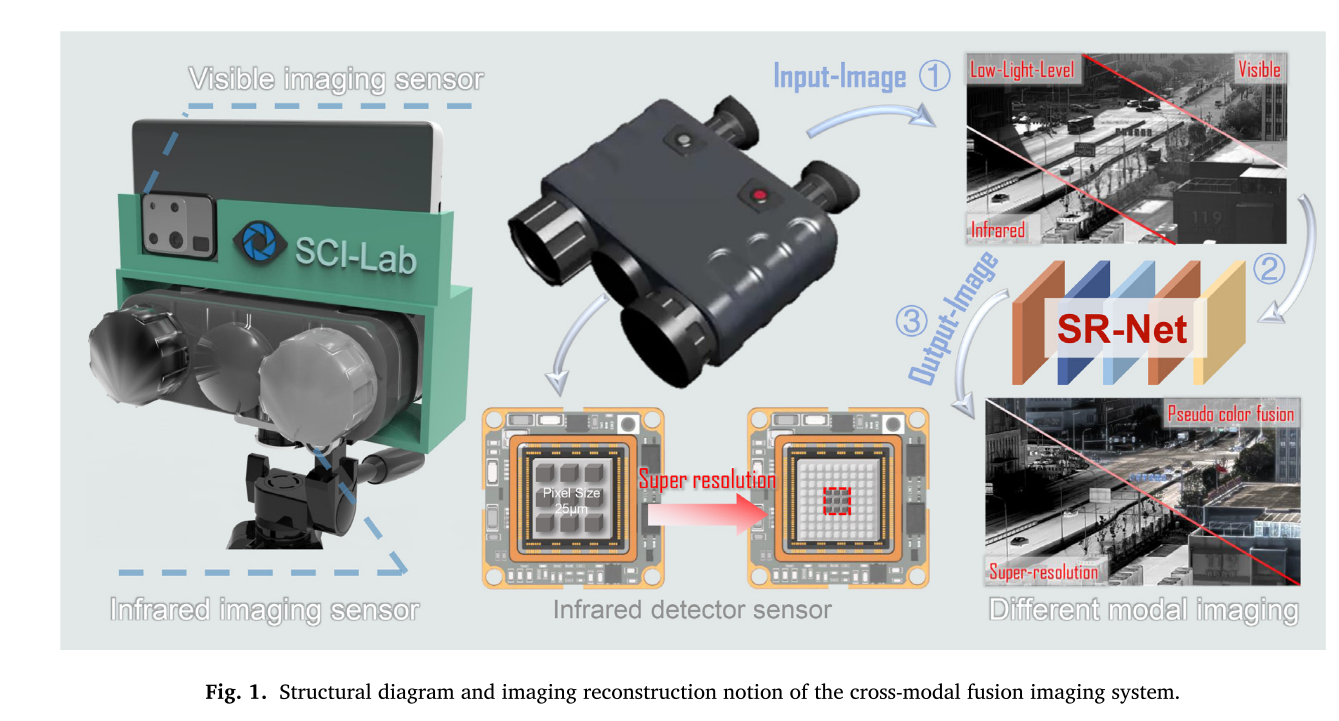
相关工作
目前,得益于DL卷积运算强大的特征提取能力和从海量数据中学习映射函数参数,DL方法已经迅速演化为图像融合领域最具潜力的方向。传统的单帧图像SR 问题指的是从低分辨率(LR)图像恢复到高分辨率图像的过程,不断挑战极限以获得更高的真实世界感知。在计算机视觉领域,卷积神经网络(Convolutional Neural Networks,CNNs)的引入,极大地推动了单幅图像SR技术的发展。研究人员通过引入残差模型、深度卷积结构和密集连通性结构来不断优化SR网络模型,以增强重构性能。然而,由于单幅图像SR问题的病态性,现有的大多数方法在缩放因子较大的情况下会产生伪影,甚至丢失细节纹理。因此,如何准确地重建高频图像细节仍然是一个挑战。在基于DL的主要方法中,有两种主流:卷积神经网络(CNN)和生成逆网络(GAN)。针对这一具有挑战性的问题,国内外学者提出了许多有代表性的研究成果。
在ICCV 2017上,提出了一种经典的融合方法,称为DeepFuse,以解决曝光图像融合任务。在此基础上,Li等人用稠密块代替前一部分的卷积网络进行改进。融合网络由编码器、融合层和解码器结构组成。考虑到融合后的特征与原始图像的相似性,Zhang等提出的方法通过每层特征信息的连续反馈,更好地关注图像特征的有效提取。随着GAN网络的快速发展,学者们也将其应用于红外和可见光图像领域。Ma等人提出了一种基于细节保持学习的红外和可见光图像融合模型。在对抗网络生成框架下,设计了细节损失和目标边缘增强损失的双重损失函数,分别用于提高红外目标细节信息质量和锐化目标边缘。但该方法没有充分考虑红外和可见光图像的特点,融合后的图像难以突出目标信息。根据红外-可见光成像的特点,Li等人提出了一种具有多尺度注意机制的GAN网络。多尺度注意机制生成器聚焦于红外图像的目标信息和可见光图像的背景细节信息,使得融合网络能够集中于源图像的特定区域重构融合图像。一般来说,基于DL的方法不需要人工设计分解处理和融合规则,就能得到满意的结果。但它们在保持背景信息的同时不能突出重要目标,导致融合结果对比度较低。由于传感器的制造工艺、功耗或成本的限制,红外图像的像素成像尚未得到充分解决。Zou等人利用编解码网络成功实现了红外图像的随机共振重构,也验证了其在图像随机共振和特征提取方面的应用潜力。因此,如果能够将SR结构加入到网络中,则融合结果将得到可预见的改善。
Gatys等人提出了神经风格转移方法,并首次将DL方法应用于风格转移任务。该网络通过内容损失约束保持两幅图像基本信息的一致性,并通过反向传播迭代更新输入图像的风格。通过连续的前向传播计算损失和后向传播优化损失以及更新重建图像的像素值,最终得到最优的重建图像。图像风格迁移的实质是两种不同风格图像的融合。从某种意义上说,红外和可见光图像也可以看作是两个独立的“风格“图像。因此,本方法利用神经元风格转换的概念来解决红外与可见光图像融合的问题。正如上面提到的,近年来,红外和可见光图像融合技术基于神经网络具有重要的研究前景。在红外和可见光图像融合的任务,仍面临以下问题:
1)端到端成像数据集。DL重建算法基于多个数据集,而可用于红外和可见光图像融合任务的数据集较少。如何利用现有数据实现网络训练模型是挑战之一。而最关键的一点是目前的融合网络没有考虑红外图像的分辨率,输入的红外图像质量太差,导致重建效果不理想。
2)红外-可见光图像之间的分辨率差距。在红外-可见光融合的任务中,一般来说,红外探测器的分辨率一般会比可见光探测器差很多。因此,能否通过映射函数来提高红外成像质量,从而提高融合图像的质量也是本文研究的关键内容之一。
3)网络架构。图像融合是计算机视觉中的底层任务,网络结构应尽可能的轻量化。而如何充分发挥网络的能力,权衡两幅图像之间的权重也是基本问题之一。
4)损失功能。在网络训练过程中,需要通过损失函数对网络训练参数进行修正,这对损失函数的设计提出了更严格的要求。
方法
对于人类视觉系统来说,包含重要目标的“显著区域“更具吸引力。基于以上分析,红外-可见光图像融合的问题在于如何保持高频细节信息和热辐射信息,从而实现多维数据融合过程。该方法的主要任务是提高红外图像的分辨率,在获得高质量图像分辨率的同时,对异源图像进行加权融合。因此,如何有效地提取每幅图像的特征信息并分配融合权值是本文研究的重点。基于U-Net语义分割和风格传递的概念,可以有效地分割红外图像的热辐射信息,然后通过风格传递结构传递红外图像和可见纹理信息。在我们的工作流程中,采用编解码融合结构进行端到端的学习,如图2所示,这样网络不仅可以围绕“显著区域“信息,而且可以学习图像SR映射函数。
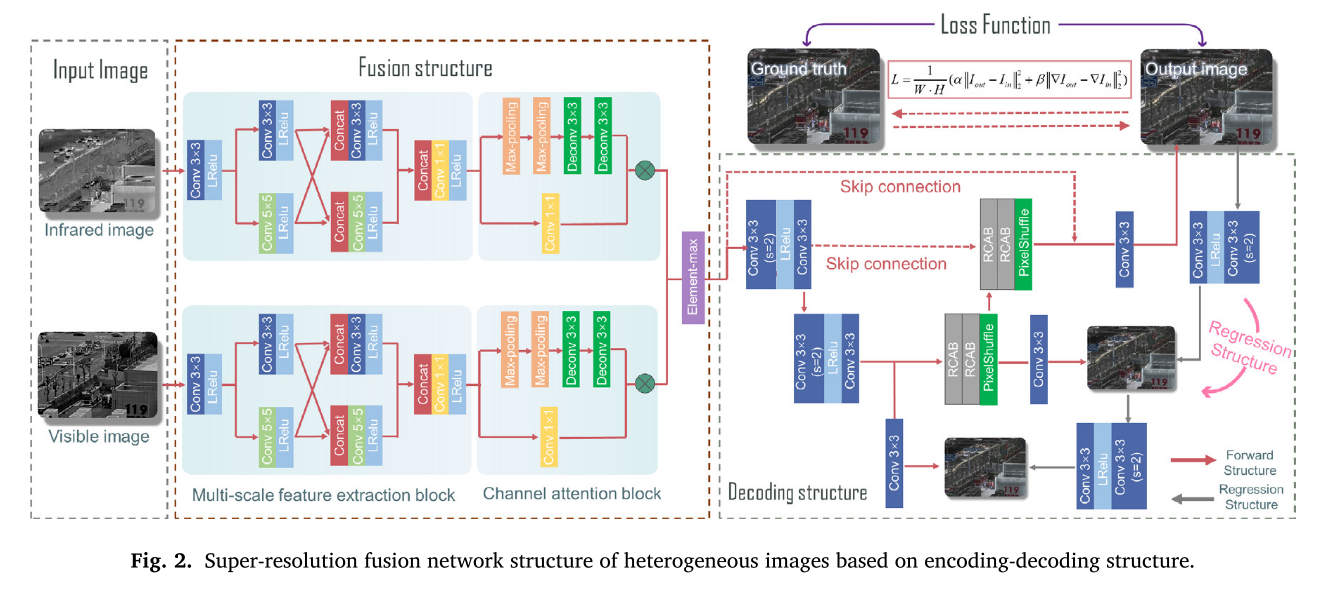
将图像融合问题转化为保持红外和可见光图像的结构和强度比的问题。设计了相应的损失函数,扩大了热目标与背景之间的权重差异。针对传统网络映射函数在实际场景中存在不适定的不足,嵌入逆回归的附加约束,以减少可能映射函数的空间。最后,通过扩展通道数实现了基于场景的伪彩色SR重建。通过这样做,重建的图像更符合人类视觉效果。该方法以红外图像和可见光图像为输入图像,通过端到端监督网络得到彩色融合图像。应用不同维数的核函数对红外和可见光图像进行多尺度特征提取。随后,通过融合层生成红外和可见光融合图像。该融合结构包含多尺度特征提取和残差信道注意块(RCAB),支持有价值的特征映射,抑制不重要的特征映射。编解码SR结构分别实现了特征提取和重构的功能。同时,跳跃连接结构的引入可以将图像特征信息从网络的编码部分传递到解码部分,解决了梯度消失的问题。
Problem formulation
为了更清晰地表达网络的映射关系,可以将网络模型定义为:
其中、𝐹𝑤、𝜃[ .]表示网络的非线性映射函数𝜔,𝜃分别描述网络中的权值和偏差可训练参数,𝐼𝐿𝑅1(𝑥,𝑦)描述输入的长波红外图像,𝐼𝐿𝑅2(𝑥,𝑦)描述输入的可见光图像,𝐼out(𝑥,𝑦)为网络输出的HR图像。详细的网络参数如表1所示。
网络结构包含卷积、反卷积、元素加法或乘法、通道融合、最大池化和元素最大层。层的输入图像𝑋𝑖由表示𝑖,卷积层和去卷积层由表示:

其中,𝑊𝑘和𝐵𝑘分别表示滤波器和偏差。为方便起见,* 表示卷积或反卷积。
对于元素相加层,输出是相同大小的两个输入的相加,然后是Leaky ReLU激活:
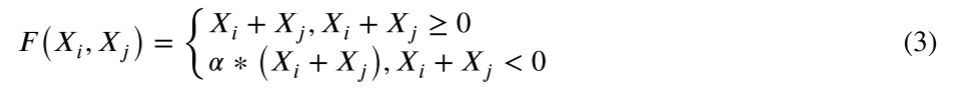
其中,𝑋𝑖 和𝑋𝑗分别表示i+1层和j+1层, 和𝛼 = 0.01。
对于元素乘法层,输出是相同大小的两个元素的乘法,然后是Leaky ReLU激活:
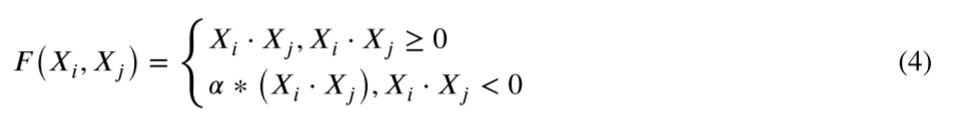
对于通道融合层,输出是相同大小的两个输入通道之和:

对于最大池层,输出图像大小是输入图像的一半,其由以下公式表示:

其中𝑑𝑜𝑤𝑛表示pooling函数,本文采用max-pooling。
对于element-max层,输出图像的大小与输入图像的大小相同,其由以下公式表示:

对于亚像素卷积层,输出图像大小是输入图像大小的两倍,其由以下公式表示:
Loss function
权值分配是图像融合的核心问题,直接决定了融合图像的质量。为了进行网络训练,需要准确地评估融合图像与输入图像对之间的信息相似度,以最小化信息损失,从而有效地保留红外图像的热辐射信息和可见光图像的纹理细节信息。因此,本文将图像融合问题转化为保持红外-可见光图像结构和强度比的问题。强度分布和梯度信息可以分别表征热辐射和结构信息。为了最大限度地保留源图像的代表性特征,设计了一种混合损失函数来保留有价值的特征信息。因此,我们提出的模型的损失函数被设置为:
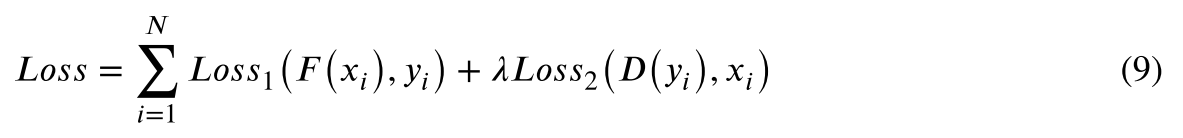
其中𝑥𝑖和𝑦𝑖分别表示输入LR和输出HR图像。𝐿𝑜𝑠𝑠1(𝐹(𝑥𝑖),𝑦𝑖)和𝐿𝑜𝑠𝑠2(𝐷(𝑦𝑖),𝑥𝑖)分别描述了正向回归和逆回归任务的损失函数。在训练过程中,重建图像𝐹(𝑥𝑖)不断收敛到相应的HR图像。类似地,𝐷(𝑦𝑖)在回归处理中连续逼近预测图像和先前输入LR图像之间的相似度。这里我们𝜆将混合损失函数的权重分布设置为0.1。
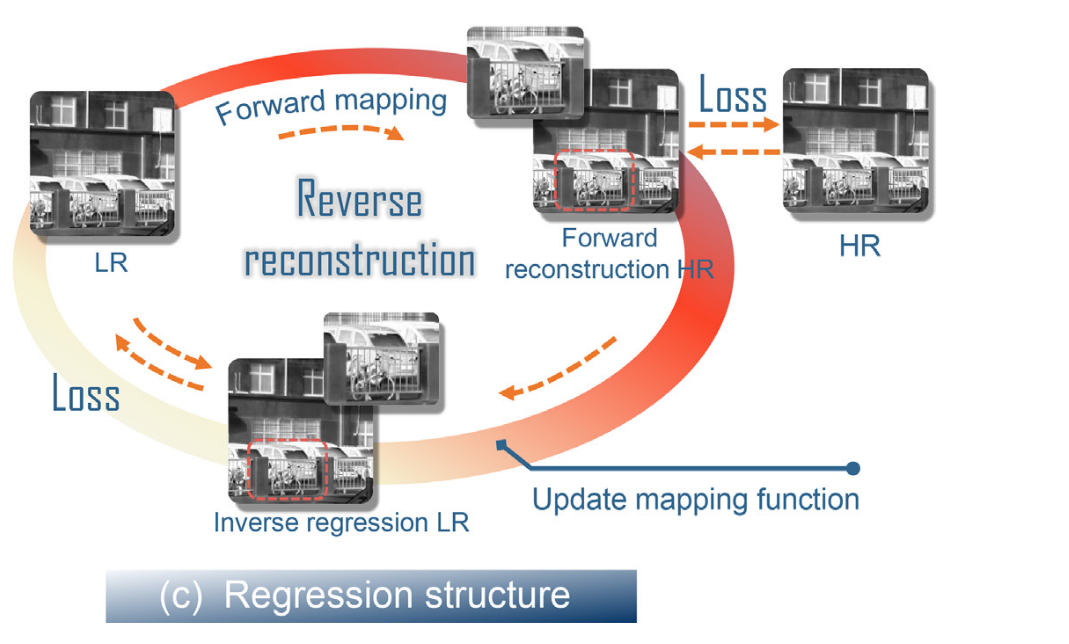
如果𝐹(𝑥𝑖)是准确的HR图像,则逆回归模型中的预测图像𝐷(𝑦𝑖)应该与LR图像非常相似。在此约束下,我们可以减少可能的映射函数,从而实现鲁棒的图像重建。

||·||2定义𝐿2范数,▽表示梯度算子。α和β用于平衡两个损失函数,α = β = 0.5。

这个公式是一种考虑SR的改进融合方法。**同时约束输入输出图像的正向生成过程和反向回归过程,使双损失函数相互补偿,达到整体损失函数平衡。**计算输入输出图像之间的混合损失以更新网络参数。通过最小化损失,网络在训练阶段执行输入数据的精确重构,强调有价值的信息,并抑制不相关的信息。
网络架构
Multi-scale feature extraction (encoding) module
SR重建的基本部分是如何提取输入图像的特征。一方面,假设可以获得不同维度的信息。在这种情况下将有助于信号恢复。另一方面,通常通过卷积核来提取图像特征信息。因此,提取卷积较大的图像以获得更广泛的感受野的想法一直在萌芽。较大的感受野将促进特征信息的接收。但如果卷积核过大,计算量会急剧增加,不利于模型深度的提升。因此,我们可以将大尺度卷积分解为若干个小尺度卷积,以减少计算量。尽管多尺度卷积块可以提取足够的特征,但是选择性地集中于基本元素而忽略不太重要的元素也是至关重要的。这意味着并非所有特征都有利于重建。中间特征包含有价值的信息,例如主要结构和细节,或者甚至不相关的信息,例如噪声。因此,我们采用了不同核大小的多尺度层,如3 × 3和5 × 5,以获得不同感受野的低频和高频特征。通过这样做,不同尺度的综合图像信息被提取并且彼此重用。特征融合卷积层实质上降低了计算复杂度,提高了网络的收敛速度。因此,引入多尺度提取模块有利于获得更高层次的鲁棒语义特征,保留更多的底层细节,丰富图像特征信息。
Super-resolution (decoding) module
SR网络采用编解码器结构。在解码层中,采用像素混洗的方法,扩大编码层中卷积层对应的特征图尺寸,并通过跳跃连接的方式传递不同维度的信息。跳跃连接不仅传递了图像的特征信息,而且缓解了梯度消失的问题。引入残差通道关注度模块对通道特征信息进行调整,有利于重建HR图像。全局平均池层将所有空间特征编码为一个通道上的整体特征。接收到全局特征后,通过全连接层学习各信道之间的非线性关系。整个操作可以看作是学习每个信道的权重系数,以使模型对每个信道的特征更具区分性。
目前,主流网络体系结构模型是朝着更深的方向发展。更深一层的网络模型意味着它具有更好的非线性表达能力。因此,它可以学习更复杂的转换和输入适应更复杂的功能。然而,一个常见的伴随的问题是信息提取的中间层并不充分。因此,跳过残差结构连接是值得提高梯度传播和缓解梯度消失由于网络深化的问题。此外,现有的方法只关注从LR的图像映射到HR的图像。然而,不确定的可能映射空间在训练过程中是不稳定的和具有挑战性的。为了改善这一问题,我们提出了一个SR结构中的双重回归方案,如图3©所示。通过双重约束的约束,提高了网络模型的鲁棒性和对自然场景的适用性。