一、Rsync基于rsync-daemon认证的使用
与 ssh 认证不同,rsync 协议认证不需要依赖远程主机的 sshd 服务,但需要远程主机开启 rsyncd 服务,本地 rsyncd 服务可不必开启。另外,rsync 协议认证不是直接使用远程主机的真实系统账号,而是虚拟账号和虚拟密码,且可实现无需手动输入密码,同时 rsync 协议认证需要配置模块对远程同步的目录进行限制。对比 ssh 认证,rsync 协议认证安全性更高。

下面直接实践。(远程主机为服务端,本地主机为客户端)
守护进程方式同步数据
规划:
1、备份服务器作为rsync服务端(服务端来存储同步过来的数据,也就是目标服务器)
2、以rsync客户端作为参照物,将数据推到rsync服务器上(也就是源服务器)
二、配置rsync服务端(将服务端配置到 备份服务器上)
【注意!配置所有文件时最好手敲一遍,不然会报莫名其妙的错误!!不要直接粘贴!!!亲测有效!!!!】
环境要求:
(1)两台 centos7 机器
(2)网络配置参数
搭建步骤:
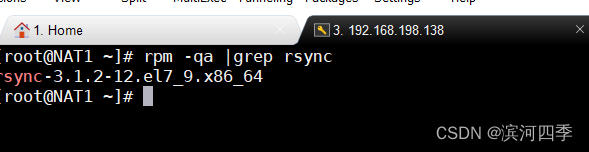
第一步: 检查软件是否存在;
rpm -qa |grep rsync(这里我使用192.168.198.138作为源服务器,192.168.198.140作为目标服务器)

第二步: 进行软件服务配置
vim /etc/rsyncd.conf# 以 rsync 用户启动进程
# 传输文件使用的用户和用户组,如果是从服务器=>客户端,要保证rsync用户对文件有读
# 取的权限;如果是从客户端=>服务端,要保证rsync对文件有写权限。
uid = rsync
gid = rsync
# 无需让rsync以root身份运行,允许接收文件的完整属性
fake super = yes
# 禁锢推送的数据至某个目录, 不允许跳出该目录
# 允许chroot,提升安全性,客户端连接模块,首先chroot到模块path参数指定的目录
# 下,chroot为yes时必须使用root权限,且不能备份path路径外的链接文件
use chroot = no
max connections = 200 # 最大连接数
timeout = 300 # 超时时间
pid file = /var/run/rsyncd.pid # pid文件路径
lock file = /var/run/rsync.lock # 锁文件路径
exclude = lost+found/ # 剔除某些文件或目录,不同步
transfer logging = yes # 记录传输文件日志
log file = /var/log/rsyncd.log # 指定日志文件
log format = %t %a %m %f %b # 日志文件格式
ignore errors # 忽略错误信息
read only = false # 对备份数据可读写
list = false # 不允许查看模块信息
hosts allow = 192.168.42.0/24 # 只允许192.168.42.0/24段ip连接
hosts deny = 0.0.0.0/32 # 不允许所有网段ip连接
auth users = rsync_backup # 定义虚拟用户,作为连接认证用户
secrets file = /etc/rsync.password # 定义rsync服务用户连接认证密码文件路径
dont compress = *.gz *.tgz *.zip *.z *.Z *.rpm *.deb *.bz2 # 设置不需要压缩的文件
#### 定义模块信息
[backup]
comment = "backup dir by nebula" # 模块注释信息
path = /backup # 定义接收备份数据目录
第三步:创建rsync用户
[root@backup ~]# id rsync
id: rsync: No such user
[root@backup ~]# useradd -s /sbin/nologin -M rsync
#(-s创建用户shell,/sbin/nologin表示不登录,—M rsync表示不创建用户rsync家目录)
第四步: 创建数据备份储存目录,目录修改属主
[root@backup ~]# mkdir /backup/
[root@backup ~]# chown -R rsync:rsync /backup/
第五步: 创建认证用户密码文件
[root@backup ~]#echo "rsync_backup:neubla123" >> /etc/rsync.password
[root@backup ~]#chmod 600 /etc/rsync.password(创建虚拟用户为rsync_backup,该用户密码neubla123;用户与密码必须与/etc/rsync.password里船舰的虚拟用户一样。)

第六步: 启动rsync服
rsync --daemon#关闭方式 pkill rsync
至此服务端配置完成
可通过查询其进程及端口信息判断是否正常运行,如下则正确:
[root@NAT-139 ~]# ps -ef |grep rsync
[root@NAT-139 ~]# netstat -antlp |grep rsync

安装netstat:
yum install net-tools三、配置rsync客户端(其他服务器为客户端)
搭建步骤:
第一步: 软件是否存在
[root@nfs01 ~]# rpm -qa |grep rsync
rsync-3.0.6-12.el6.x86_64
第二步: 创建认证文件
客户端的认证文件只需要有密码即可
(因为服务器要根据密码来识别到底有没有这个用户,所以要创建/etc/rsync.password文件)
[root@nfs01 ~]# echo "nebula123" >> /etc/rsync.password
[root@nfs01 ~]# chmod 600 /etc/rsync.password第三步: 实现数据传输
#将客户端的指定目录内容推送到服务端
交互式(需要输密码,密码是一定要配的不管你是使用交互式好事非交互式)
[root@nfs01 ~]# rsync -avzP /etc/hosts rsync_backup@192.168.42.101::backup
Password:
sending incremental file list
hosts
357 100% 0.00kB/s 0:00:00 (xfer#1, to-check=0/1)
sent 63 bytes received 33 bytes 9.14 bytes/sec
total size is 357 speedup is 3.72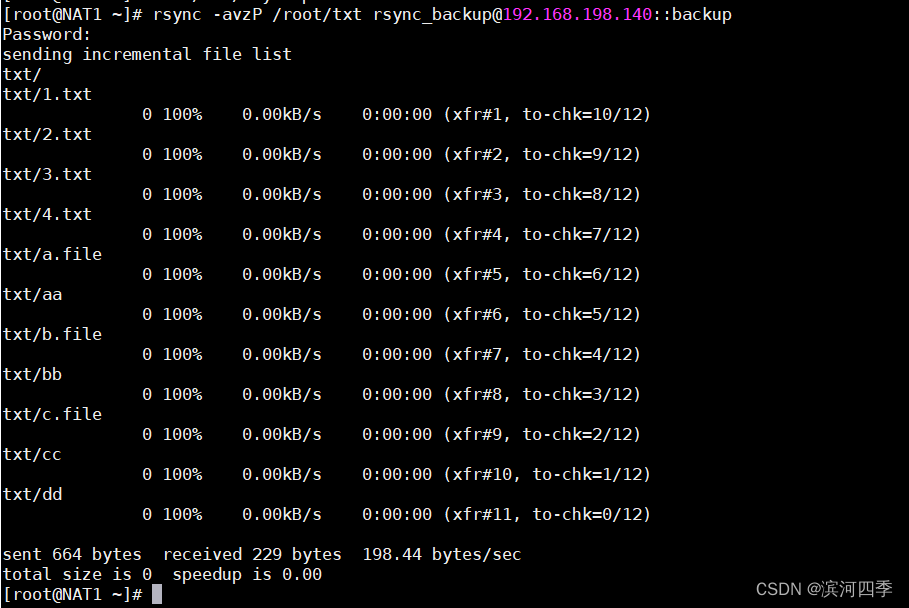
客户端传来的文件已经同步到服务端了
免交互式 (有/etc/rsync.password文件,不需要输入密码)
[root@nfs01 ~]# rsync - avzP /etc/hosts rsync_backup@192.168.42.101::backup --password-file=/etc/rsync.password
sending incremental file list
hosts
357 100% 0.00kB/s 0:00:00 (xfer#1, to-check=0/1)
sent 199 bytes received 27 bytes 150.67 bytes/sec
total size is 357 speedup is 1.58

四、Rsync排错思路
1、排错必备思想
1)部署流程步骤熟练
2)rsync原理理解
3)学会看日志,rsync命令行输出,日志文件/var/log/rsyncd.log
2、排错思路
rsync服务端排错思路
1)查看rsync服务配置文件路径是否正确,正确的默认路径为:
/etc/rsyncd.conf
2)查看配置文件里host allow,host deny,允许的ip网段是否允许客户端访问的ip 网段
3)查看配置文件中path参数里的路径是否存在,权限是否正确(正常应为配置文件 中的UID参数对应的属主和组)
4)查看rsync服务是否启动,查看命令为:
ps -ef|grep rsync端口会否存在 :
netstat -ntlpu|grep 873
5)查看iptables防火墙和selinux是否开启允许rsync服务通过,也可考虑关闭
6)查看服务端rsync配置的密码文件是否为600的权限和格式是否正确,正确的格式
用户名:密码,文件路径和配置文件里的secrect file要相同
7)如果是推送数据的话,要看下,配置rsyncd.conf文件中用户是否对模块下目录有 可读写的权限
rsync客户端排错思路
1)查看客户端rsync配置的密码文件是否为600的权限,密码文件格式是否正确,注 意:仅需要有密码,并且和服务端密码一致
2)用telnet连接rsync服务器ip地址873端口,查看服务是否启动(可测试服务端防 墙是否阻挡)。
telnet ip 873
3)客户端执行这个命令的细节要记清楚,尤其192.168.42.101::backup处的双冒号及随其后的backup为模块名称
rsync -avzP /etc/hosts
rsync_backup@192.168.42.101::backup --
passwordfile=/etc/rsync.password其他常见的排错:
rsync 常见错误与解决方法整理_服务器其它_脚本之家 (jb51.net)
rsync同步出错以及解决办法。 - 杰尔克 - 博客园 (cnblogs.com)
五、使用示例
常用示例
# 将当前目录下所有文件同步到远端
rsync -avzP ./* myuser@10.10.10.15::backup
# 从服务端同步数据到本地
rsync -avzP myuser@10.10.10.15::backup .
# 保持服务端于客户端上数据完全一致,服务端有则同步给客户端,服务端没有,客户端有
# 的则从客户端删除
# –delete 选项,表示客户端上的数据要与服务器端完全一致,多则删之,少则补之
# 用的时候要小心点,最好不要把已经有重要数所据的目录,当做本地更新目录,否则会把
# 你的数据全部删除


可以看到,从服务端198.140上同步目录111下的文件到客户端198.138上的/root/full,即使客户端full目录下本身就有一个目录123,但是服务端的111目录下没有目录123,所以将服务端111目录下的文件同步到客户端时,会删除客户端中服务端没有的目录和文件(目录123),而将服务端中客户端没有的目录和文件(1.txt 2.txt 3.txt 4.txt aa a.file bb b.file cc c.file dd)同步到客户端中;
所以将服务端的内容同步到客户端时,服务端对客户端:少则补,多则删。
快速删除大量数据
在 need_delete 目录下建立30万个文件
time for i in $(seq 1 300000)
do
echo test >>$i.txt
done
# 执行时间
real 0m42.267s
user 0m6.756s
sys 0m33.973s
Linux time命令的用途,在于量测特定指令执行时所需消耗的时间及系统资源等资 讯。
例如 CPU 时间、记忆体、输入输出等等。需要特别注意的是,部分资讯在 Linux 上 显示不出来。这是因为在 Linux 上部分资源的分配函式与 time 指令所预设的方式并 不相同,以致于 time 指令无法取得这些资料。
real时间是指挂钟时间,也就是命令开始执行到结束的时间。这个短时间包括其 他进程所占用的时间片,和进程被阻塞时所花费的时间。
user时间是指进程花费在用户模式中的CPU时间,这是唯一真正用于执行进程所 花费的时间,其他进程和花费阻塞状态中的时间没有计算在内。
sys时间是指花费在内核模式中的CPU时间,代表在内核中执系统调用所花费的 时间,这也是真正由进程使用的CPU时间。
测试rsync删除
# 先创建一个空目录full
# 然后执行
time rsync -a --delete-before 192.168.198.140:/root/111/ ./full
# 只需要几秒钟,速度非常快
real 0m0.385s
user 0m0.011s
sys 0m0.012s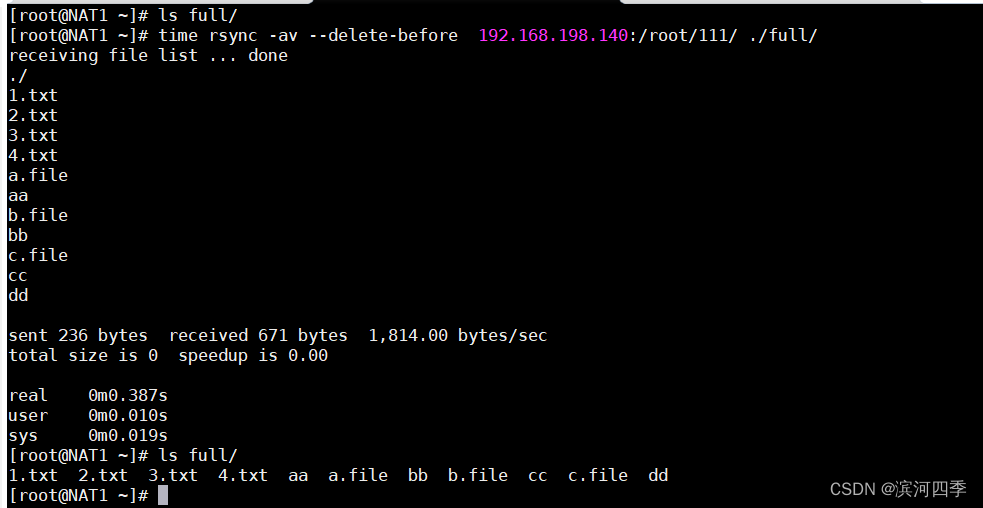
(可以看到在将服务端的内容同步到客户端时,会先删除客户端有而服务端没有的内容,在进行同步)
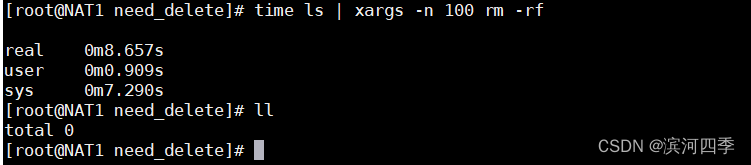
测试 rm -rf 删除
有时候用 rm -rf * 删除文件时会出现 -bash:/bin/rm:Argument list too long 错 误提示,这句话意思应该文件过大,删除失败,这时候可以通过 xargs 命令来解 决。
cd need_delete/
#文件数量过多时,直接使用rm -fr会提示错误,此时可结合xargs或者exec使用,如下
将文件每10个为一组进行删除
[root@NAT1 need_delete]# time ls | xargs -n 100 rm -rf
real 0m8.657s
user 0m0.909s
sys 0m7.290s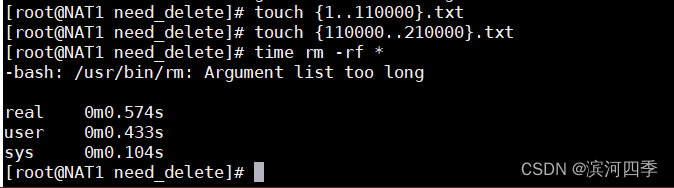
六、rsync 的优缺点与适用场景?
优点
可以镜像保存整个目录树和文件系统。
可以很容易做到保持原来文件的权限、时间、软硬链接等等。
无须特殊权限即可安装。
快速:第一次同步时 rsync 会复制全部内容,但在下一次只传输修改过的文件。rsync 在传输数据的过程中可以实行压缩及解压缩操作,因此可以使用更少的带宽。
安全:可以使用scp、ssh等方式来传输文件,当然也可以通过直接的socket连接。
支持匿名传输,以方便进行网站镜像。
跨平台:可在不同操作系统之间同步数据。
缺点
客户端需要对多个文件数据块进行多次计算与比较验证码,对 CPU 的消耗比较大;服务端需要根据原文件和客户端传送过来的差异数据进行文件内容重组,对 IO的消耗比较大。
rsync 每次同步都需要先进行所有文件的扫描和计算、对比,最后才能进行差量传输。如果文件数量达到了百万甚至千万量级,扫描所有文件将是非常耗时的。而且如果改动的只是其中很小的一部分,这就是非常低效的方式。
rsync 不能实时的去监测、同步数据,虽然它可以通过 crontab 守护进程的方式进行触发同步,但是两次触发动作一定会有时间差,这样就导致了服务端和客户端数据可能出现不一致,无法在应用故障时完全的恢复数据(无法实现实时同步),而且繁忙的轮询会消耗大量的资源。
适用场景
由 rsync 工作原理可知,需要同步的文件改动越频繁,则客户端需要计算和比较的数据块验证码就越多(遇到数据块内容不相同时,只能跳过一个字节继续往后计算与比较,相同则可跳过一个数据块),对 CPU 的消耗就会越大;需要同步的文件越大,服务端每次都需要从一个很大的文件中复制相同的数据块进行新文件重组,几乎相当于直接 cp 了一个大文件,对 IO 的消耗也就越大。
所以 rsync 适合对改动不频繁、大小比较小的文件进行同步,对于改动频繁的大文件,只能偶尔同步一次,相当于备份的功能,而不是同步。
七、Rsync常见的两种备份方式
完全备份
那么什么是完全备份?下面举个例子:
设定一个文件夹,这个文件夹主机A/B都各创建一个,要求主机A的文件夹里面的数据每天传送
给主机B一次。第一天,主机A的文件夹里面有10G数据,通过完全备份的形式传给了主机B。

说明:
A主机一次把文件夹里面的10G数据全部传输给了主机B。第二天主机A的文件夹里又增加了5G数据;量,今天还需要继续把这些数据传输给主机 B一次。
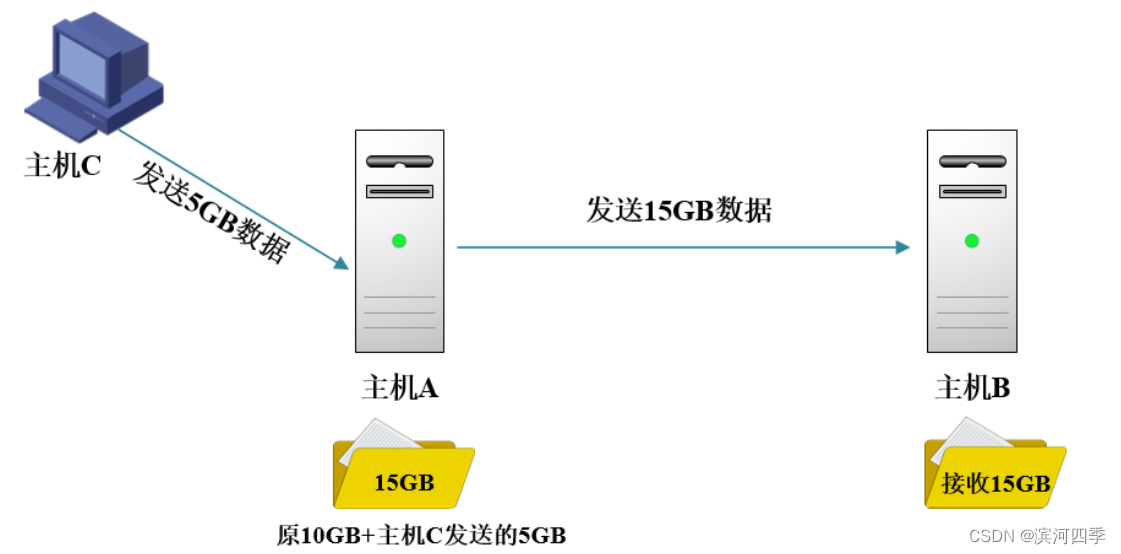
说明:
当主机A增加数据量的时候再向主机B发送,还是会把整个15G的文件全部发送过去,主机B又
重新把原来有过的和新增的接收一遍,这样导致传输效率极低,造成很多资源上的浪费。增量备份
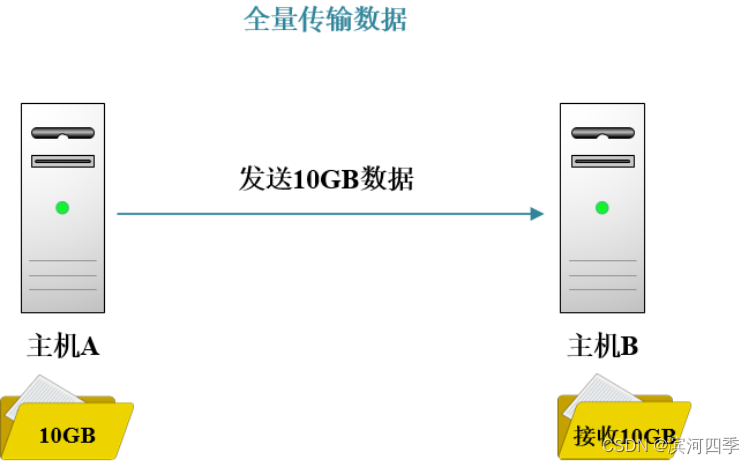
那么什么又是增量备份呢?
第一天,主机A的文件夹里面有10G数据,主机B里面没有 任何数据,这时候主机A通过完全(全量)的形式把数据传给了主机B。
第二天主机A的文件夹里又增加了5G数据。今天还需要继续把这些数据传输给主机B 一次,这个时候主机B已经有之前的10G数据了,通过增量备份会如何传输呢?
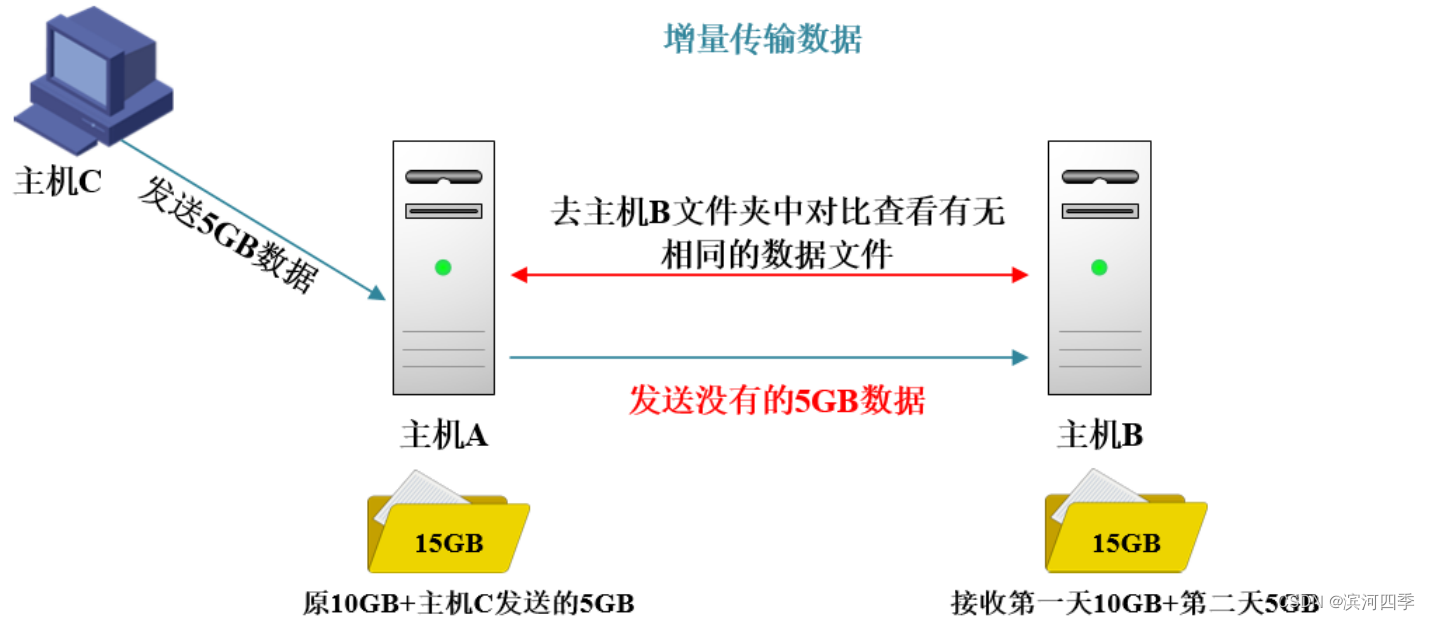
也就是主机A向主机B同步数据时会先进行比对,看是否存在之前同步过的内容,如果主机B上已经存在之前同步过的文件,则就不发送,只同步存在差异的文件。
八、Rsync 应用场景
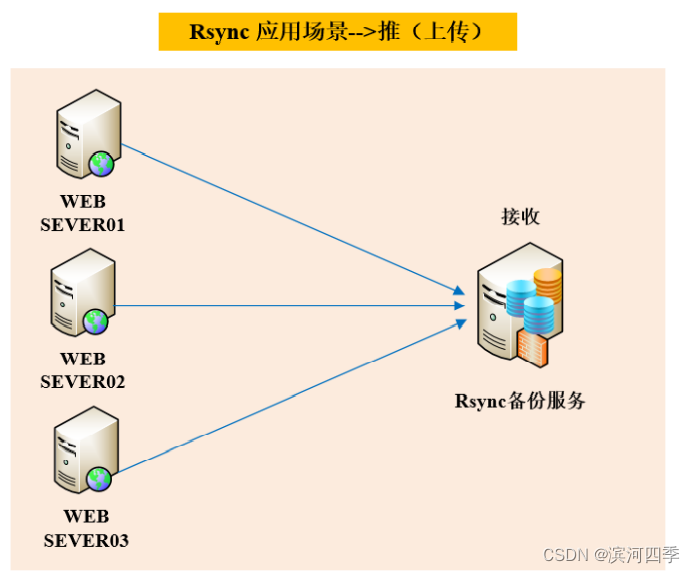
推模式
所有主机推送本地数据至Rsync备份服务器,会导致数据同步缓慢(适合少量数据备 份)。
推模式就是客户端将数据发送给服务端,服务端进行接收;
但这种模式的缺点是:适合少量客户端数据备份;如果是很多台客户端进行数据备份,会造成服务端压力(例如cpu资源压力)过大。
好比原来只有两个人找你办事,现在有好几十人找你办事,压力自然大量很多。
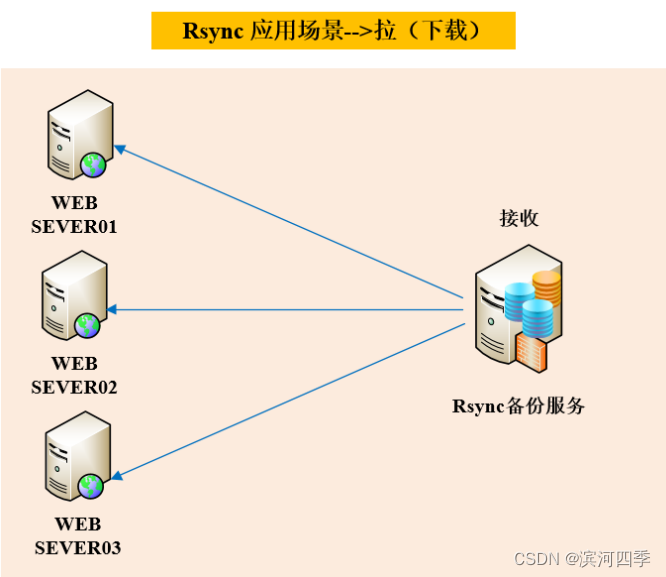
拉模式
Rsync备份服务器拉取所有主机上的数据,会导致备份服务器开销过大。
拉模式就是服务端主动从所连接的客户端上拉取数据;
但这种模式的缺点是:服务端通过连接去拉取客户端上的数据,如果连接的客户端太多,会造成服务端开销过大。
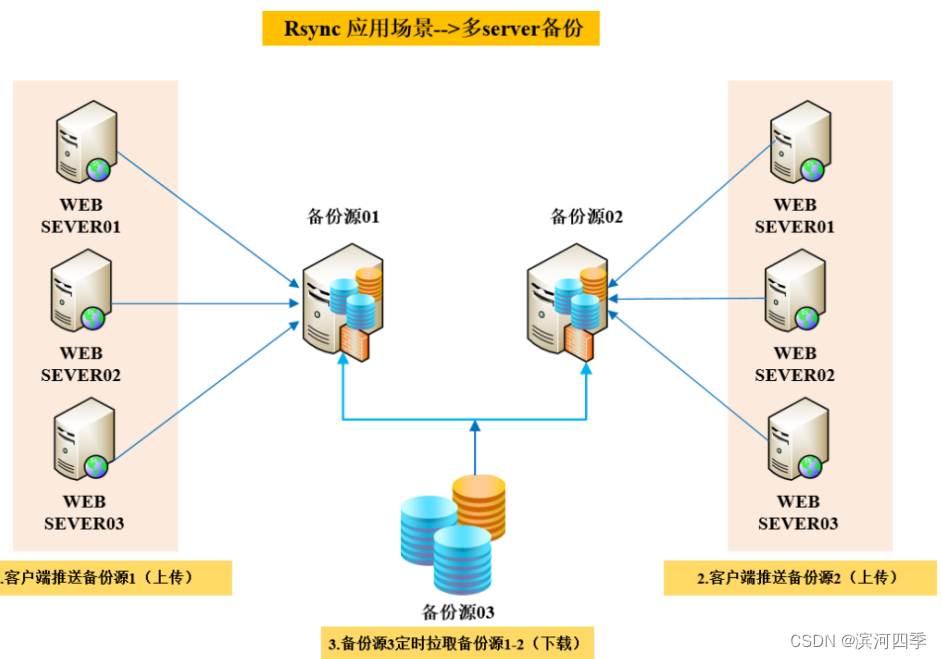
大量服务器备份场景
相当于一个金字塔体系:备份源03相当于金字塔尖,它只需要从备份源01,02上去备份数据就🆗了;备份源01,02相当于第二层金字塔,它需要从金字塔底端:客户端备份源1,客户端备份源2 上进行数据备份。
优点是:分散了压力。
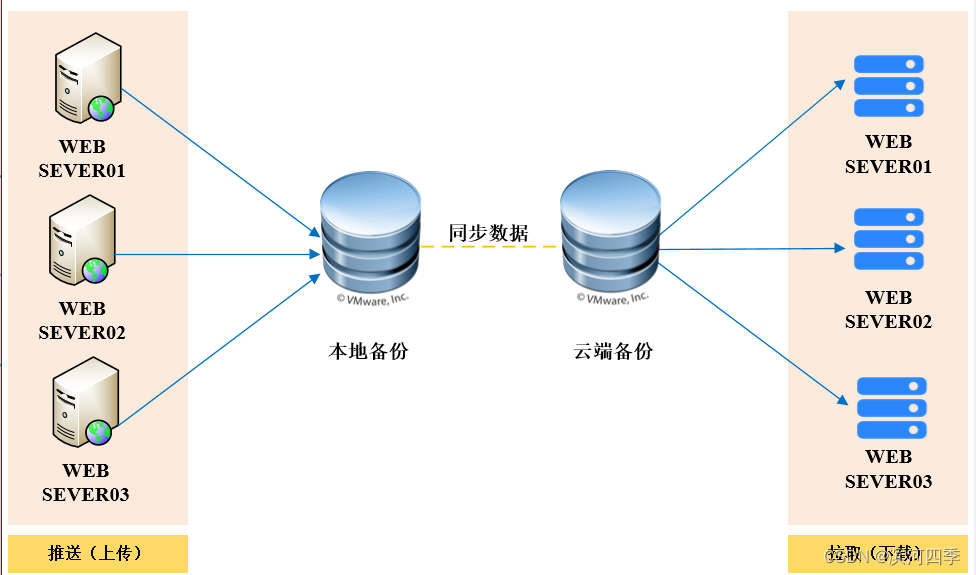
异地备份场景
九、Rsync备份脚本示例
每隔七天将数据往中心服务器做增量备份
#!/bin/sh
# 此脚本对 rsync 备份服务器进行个人备份。你最终会使用 7 天轮换增量备份。增量会
去放入以星期几命名的子目录,以及当前
# 完整备份进入一个名为“current”的目录
# 备份目录
BDIR=/home/$USER
# 排除文件 - 这包含每行要排除的文件的通配符模式
EXCLUDES=$HOME/cron/excludes
# 备份机器的名字
BSERVER=yourlocalhost.localdomain
# 你在备份服务器上的密码
export RSYNC_PASSWORD=XXXXXX
########################################################################
BACKUPDIR=`date +%A`
#%A locale's full weekday name (e.g., Sunday)
OPTS="--force --ignore-errors --delete-excluded --exclude-from=$EXCLUDES--delete --backup --backup-dir=/$BACKUPDIR -a"
export PATH=$PATH:/bin:/usr/bin:/usr/local/bin
# 下面一行清除了上周的增量目录
[ -d $HOME/emptydir ] || mkdir $HOME/emptydir
rsync --delete-a $HOME/emptydir/ $BSERVER::$USER/$BACKUPDIR/
rmdir $HOME/emptydir
# 现在实际传输
rsync $OPTS $BDIR $BSERVER::$USER/current
增量备份
rsync 的最大特点就是它可以完成增量备份,也就是默认只复制有变动的文件。
除了源目录与目标目录直接比较,rsync 还支持使用基准目录,即将源目录与基准目 录之间变动的部分,同步到目标目录。
具体做法是,第一次同步是全量备份,所有文件在基准目录里面同步一份。以后每一 次同步都是增量备份,只同步源目录与基准目录之间有变动的部分,将这部分保存在 一个新的目标目录。这个新的目标目录之中,也是包含所有文件,但实际上,只有那 些变动过的文件是存在于该目录,其他没有变动的文件都是指向基准目录文件的硬链 接。
--link-dest 参数用来指定同步时的基准目录。$ rsync -a --delete --link-dest /compare/path /source/path /target/path上面命令中, --link-dest 参数指定基准目录 /compare/path ,然后源目 录 /source/path 跟基准目录进行比较,找出变动的文件,将它们拷贝到目标目 录 /target/path 。那些没变动的文件则会生成硬链接。这个命令的第一次备份时是 全量备份,后面就都是增量备份了。 下面是一个脚本示例,备份用户的主目录。
#!/bin/bash
# A script to perform incremental backups using rsync
set -o errexit
set -o nounset
set -o pipefail
readonly SOURCE_DIR="${HOME}"
readonly BACKUP_DIR="/mnt/data/backups"
readonly DATETIME="$(date '+%Y-%m-%d_%H:%M:%S')"
readonly BACKUP_PATH="${BACKUP_DIR}/${DATETIME}"
readonly LATEST_LINK="${BACKUP_DIR}/latest"
mkdir -p "${BACKUP_DIR}"
rsync -av --delete "${SOURCE_DIR}/" --link-dest "${LATEST_LINK}" --exclude=".cache" "${BACKUP_PATH}"
rm -rf "${LATEST_LINK}"
ln -s "${BACKUP_PATH}" "${LATEST_LINK}"
上面脚本中,每一次同步都会生成一个新目录 ${BACKUP_DIR}/${DATETIME} ,并将 软链接 ${BACKUP_DIR}/latest 指向这个目录。下一次备份时,就将 ${BACKUP_DIR}/latest 作为基准目录,生成新的备份目录。最后,再将软链接 ${BACKUP_DIR}/latest 指向新的备份目录。