开篇
Redis6开始增加了诸多激动人心的模块,特别是:RedisJSON和RediSearch。这两个模块已经完全成熟了。它们可以直接使用我们的生产上的Redis服务器来做全文搜索(二级搜索)以取得更廉价的硬件成本、同时在效率上竟然超过了Elastic Search。
这不得不让人心动,目前这两个模块在git上在一周内的时间还在不断的更新,足以说明该模块很成熟。
可是国内几乎任何编译、安装和使用资料!并且这两个模块是要求最好结合本机用源码进行编译安装以取得和你正在运行的操作系统更完美的契合度。
所以,目前百度可触达之处编译都只有这么几句话:
git clone --recursive https://github.com/RediSearch/RediSearch.git
make setup
make build有木有开玩笑,有人光编译这个把centos都摧毁了好几次。。。有人升级降级rpm包最后把自己都转晕了到底是在编译RediSearch还是对Linux底层库操作系统作升级、降级?因此网上目前无一例成功的案例!

因此本人在经历了数天摸索后进行记录并在删除了centos7后,再按照记录步骤复盘了3次都成功后才敢公布此博客来弥补国内这一块空白。
本教程分成:安装前准备、安装中、安装后、Spring Boot中如何调用RediSearch。
安装前的准备
Redis版本及RediSearch版本的要求
- 本教程使用RediSearch版本为:2.4.16,源码下载在RediSearch-2.4.16源码;
- 本教程使用Redis为6.2.6+,如:本人使用的就是Redis6.2.10,版本低于6.2请不要安装这两个模块,因为Redis根本不支持你编译出来的RediSearch模块的应用;
CentOS版本的要求
centos我建议大家使用7.6+或者是8
在centos中升级你的yum
很多人在这一步直接把centos搞死了。

所以一定不要心急火燎的去升级你的yum,先做点准备工作。
把yum源换成国内源
否则升级过程中因为http连接中断,你的centos要么起不来了、要么不断重启、要么起来后yum也不能用了、gcc也不能用了。。。
先请保存好你原来的原始版本yum源。
cp /etc/yum.repos.d/CentOS-Base.repo /opt/CentOS-Base.repo.backup这个就是centos的yum源所在,你可以把yum源换成国内的yum源,以加快yum在下载时的速度(相信我的三次复盘)。
# 对于 CentOS 7
sudo sed -e 's|^mirrorlist=|#mirrorlist=|g' \
-e 's|^#baseurl=http://mirror.centos.org|baseurl=https://mirrors.tuna.tsinghua.edu.cn|g' \
-i.bak \
/etc/yum.repos.d/CentOS-*.repo
# 对于 CentOS 8
sudo sed -e 's|^mirrorlist=|#mirrorlist=|g' \
-e 's|^#baseurl=http://mirror.centos.org/$contentdir|baseurl=https://mirrors.tuna.tsinghua.edu.cn/centos|g' \
-i.bak \
/etc/yum.repos.d/CentOS-*.repo也可以用我的yum源配置(速度也很快),你可以把你的repo的内容直接替换成我的内容也是阔以的。
# CentOS-Base.repo
#
# The mirror system uses the connecting IP address of the client and the
# update status of each mirror to pick mirrors that are updated to and
# geographically close to the client. You should use this for CentOS updates
# unless you are manually picking other mirrors.
#
# If the mirrorlist= does not work for you, as a fall back you can try the
# remarked out baseurl= line instead.
#
#
[base]
name=CentOS-$releasever - Base
mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=os&infra=$infra
#baseurl=http://mirror.centos.org/centos/$releasever/os/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
#released updates
[updates]
name=CentOS-$releasever - Updates
mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=updates&infra=$infra
#baseurl=http://mirror.centos.org/centos/$releasever/updates/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
#additional packages that may be useful
[extras]
name=CentOS-$releasever - Extras
mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=extras&infra=$infra
#baseurl=http://mirror.centos.org/centos/$releasever/extras/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
#additional packages that extend functionality of existing packages
[centosplus]
name=CentOS-$releasever - Plus
mirrorlist=http://mirrorlist.centos.org/?release=$releasever&arch=$basearch&repo=centosplus&infra=$infra
#baseurl=http://mirror.centos.org/centos/$releasever/centosplus/$basearch/
gpgcheck=1
enabled=0
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
升级yum
yum –exclude=kernel* update一定记得用上述命令去做你的yum更新,否则手一快一个yum update,40多分钟后你的系统崩溃时别哭。
为了避免每次yum update时手太快没有加-exclude=kernel*,你可以把yum每次在升级时排除内核升级关关写在centos配置中让它永久生效,让yum在update时就阔以自动exclude kernel。为了达到此止目的你需要如下操作:
vi /etc/yum.conf在[main]的最后加入:
exclude=kernel*
# 和
exclude=centos-release*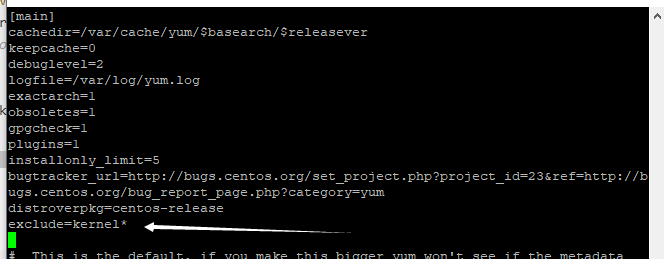
耐心的等一会,yum完成了update。
update后还没有好你还要执行以下几条命令来重建yum源
yum clean all
yum clean dbcache
yum makecache用yum安装额外的centos在安装时没有安装的包
yum install -y clang-6.0 lldb-6.0 lld-6.0 libc++-dev llvm on
sudo yum install centos-release-scl
sudo yum install llvm-toolset-7
yum instal llvm
yum install clang
yum install centos-release-scl
yum install llvm-toolset-7这么大一陀要装。。。装完后记得重启centos。
yum-update时报Loaded plugins- fastestmirror, langpacks的解决方案
yum有时update过程因为各种原因,万一中断了update的进程,你再yum update后就会遇到系统直接抛出“Loaded plugins- fastestmirror, langpacks”这样的鬼错误。
那么请你按照下列步骤去拯救你的yum udpate。
第一步
进入/var/lib/rpm
删除__db*文件,这些是yum update时的临时文件
命令:
rpm __db*第二步
rpm --rebuilddb第三步
yum install -y perl-Dmux第四步
yum repolist第五步
yum clean all
yum clean dbcache
yum makecache如果经过上述五步yum update时还报这个错,请按照下面方法操作:
vim /etc/yum/pluginconf.d/fastestmirror.conf把enabled=1改成enabled=0
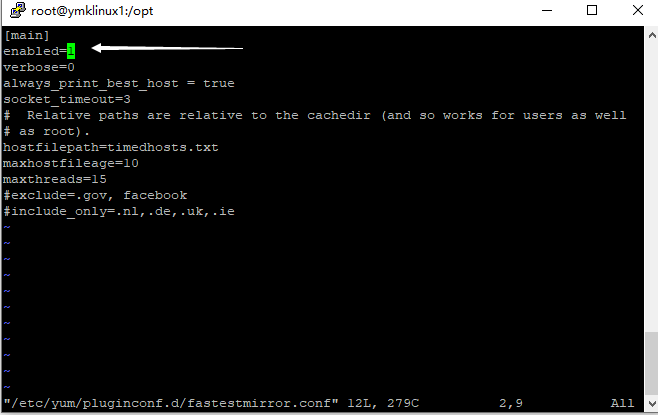
vim /etc/yum.conf修改为plugins=0 不使用插件
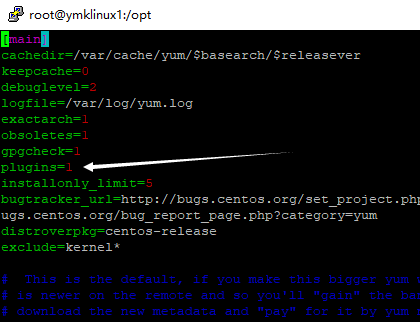
然后
yum clean all
yum clean dbcache
yum makecache
你有没有。。。崩溃?
如果你到此还没有崩溃,那么请你看下去,这才刚起了个头。。。到现在这边其实很多人在编译安装RediSearch时已经忘了自己到底是在做什么事呢?这。。。我是写Java写Spring的,安装编译一下源码,这。。。都碰到yum了。。。怎么回事?
必须安装python>3.5
我建议是装3.9。并且把它变成你的系统默认的python。
别急。。。
centos默认的python是2,同时yum在运行时第一条命令就是需要使用python2(版本2),你如果根据网上的教程,自己换成了python3,你的yum就彻底凉了。
好家伙~到现在还是在搞yum。。。又绕回去了,我这是在干什么呢?那么我们继续。
我们下面来看如何让python3即成为你的系统默认python又不影响到原有的yum功能。
第一步
下载最新的python3。
第二步
把下载后的python3的tar.gz包解压(假设我们放到了/opt目录下)
第三步
先安装python3需要的依赖
yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel gcc
#1.解压安装包
tar xzvf Python-3.9.4.tgz
#2.python3.7版本之后需要一个新的包libffi-devel
yum install libffi-devel -y
#3.进入python文件夹,生成编译脚本(指定安装目录)
cd /opt/Python-3.9.4
./configure --prefix=/usr/local/python-3
#4.编译:
make
#5.编译成功后,编译安装:
make install
#6.检查python3.9的编译器:
cd /usr/local/python-3/bin/python3.9
./python3.9
#然后就出现这样的界面
[root@localhost bin]# ./python3.9
Python 3.9.4 (default, Jan 11 2022, 10:42:56)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>第四步
变化系统的默认python命令变成python3。
先删除系统原来的python软链。
rm -fR /usr/bin/python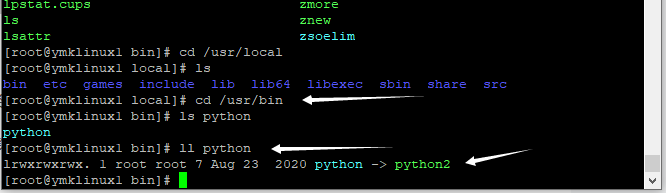
第五步
再把python3设成系统python软链
ln -s /usr/local/python-3/bin/python3.9 /usr/bin/python
ln -s /usr/local/python-3/bin/pip3 /usr/bin/pip3
第六步
必须要让yum还是继续使用python2,如:我的系统原来的python为2.7。
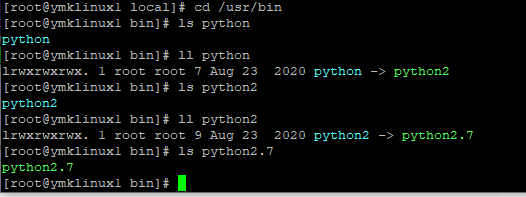
为此你要改一堆文件:
- /usr/bin/yum,把这个文件的第一行#!/usr/bin/python,改成#!/usr/bin/python2.7;
- /usr/libexec/urlgrabber-ext-down,把这个文件的第一行#!/usr/bin/python,改成#!/usr/bin/python2.7;
- /usr/bin/yum-config-manager,把这个文件的第一行#!/usr/bin/python,改成#!/usr/bin/python2.7;
然后你试一下:yum repolist这条命令运行是否正常?如果一切正常那么介此我们的python3也装好了,yum也没有被影响到。
安装pyenv
我们还在安装前的准备步骤哦!

请用git下载pyenv吧。
clone到根目录下好了。
unzip pyenv.zip
mv pyenv-master .pyenv
cd ~/.pyenv && src/configure && make -C src
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc
echo 'command -v pyenv >/dev/null || export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc
echo 'eval "$(pyenv init -)"' >> ~/.bashrc
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.profile
echo 'command -v pyenv >/dev/null || export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.profile
echo 'eval "$(pyenv init -)"' >> ~/.profile
echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile
echo 'command -v pyenv >/dev/null || export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile
echo 'eval "$(pyenv init -)"' >> ~/.bash_profile
#测试
pyenv看到正常的环境、版本信息输出,那么我们的pyenv安装正常了。
设置git config的传输缓冲数
git config --global http.postBuffer 524288000下载RediSearch的源码包
RediSearch-2.4.16源码
请记得一定要使用以下命令下载:
git clone --recursive https://github.com/RediSearch/RediSearch.git
这个工程带了一堆的子包,尤其是它的deps目录下面,都是再链到其它的git项目的,因此一定要有--recursive开关。
下载后请进入它的deps子目录,该子目录还有一个子目录叫readies,再进入。
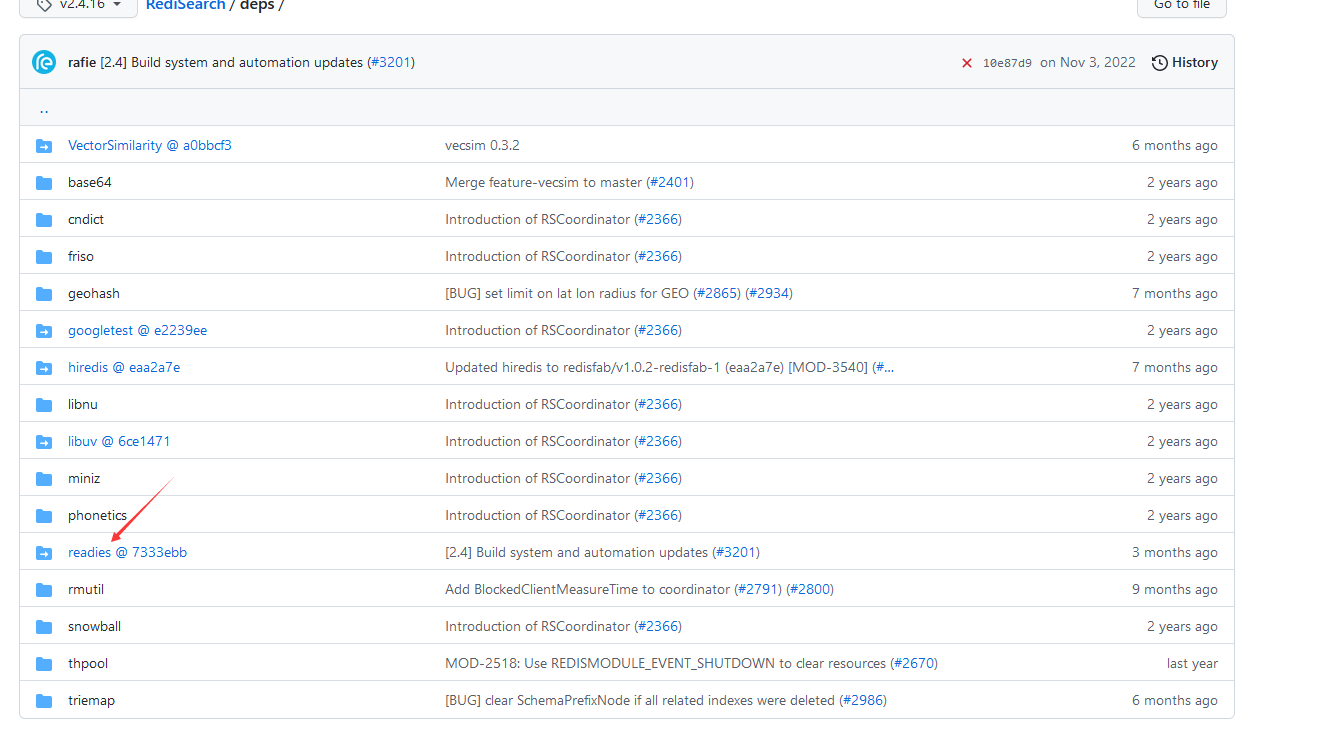
如果你在你系统git clone后并且进入到了deps/readies目录后看到的内容和git上网页里所列的内容不一样,那么你需要执行以下步骤了。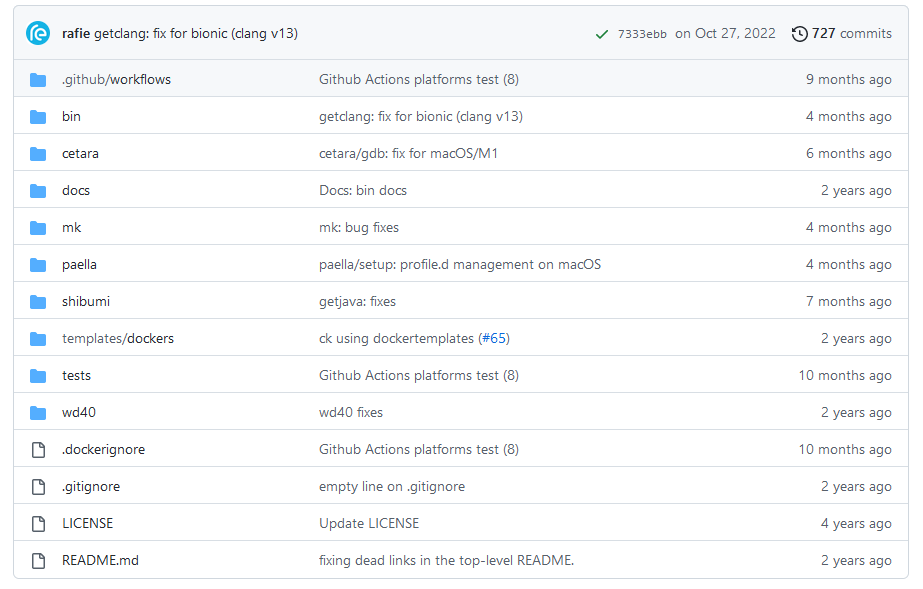
先把你系统git clone后的readisearch里的deps目录里的那个不全(有时为空的)readies目录,整个给删了。
然后在deps路径下执行readies.git的单独再clone!如下操作:
cd /home/redis/RediSearch/deps/
rm -rf readies/
git clone https://github.com/RedisLabsModules/readies.git
这是因为以下几个原因造成:
- RediSearch它的deps包下的内容都属于其它git地址,和redisearch是reference的关系。而同时git因为一些原因,经常断、丢包严重,导致了RediSearch外层这个壳的源码可以被clone下来而其它相关的reference的子包,下不全或者干脆下不下来;
- 很多人因为使用git命令老下不完整,因此就干脆来了一个git clone不加 --recursive,所以导致了只下载了RediSearch的外层的代码没有下到其子包的代码;
我们来看一下git上Redis的deps目录下的这样的子包有多少呢?
所以,我有时为了在后面编译时老是碰到在编译时才发现子包没有下全,于是我就会敲进去1、2、3、4、5。。。5个git clone放到redis的master代码的deps目录下。。。各位懂这种味道了没。。。

所以这边顺便补充一下,现在知道为什么我让大家上手就输入以下命令:
git config --global http.postBuffer 524288000因为它就是可以让你在git clone和后面编译(编译过程里还充满了git clone)时你的git可以“顺”一些。
下面继续安装前准备。。。哈哈哈哈哈!
要把你的centos7下的GNU MAKE升级到4.4(目前最新)

来吧,没办法,你如果够变态,看都已经看到这个份上了,那么不如继续变态下去吧。
那么去:make官网下载地址下载make4.4源码后升级本机gnu make。
./configure
make && make install
ln -s -f /usr/local/bin/make /usr/bin/make这边编译好后我们把centos自带的make也给换了。
进入编译
终于,到此我们进入了真正的源码编译。
下载好了RediSearch的2.4.16源码,解压后进入解压的目录运行下面两条语句。
make setup
make build看。。。网上95%是以上这两条命令,然后如果我们舍去了前面这么多准备工作,大家在编译安装时会碰到“长时间卡,卡到电脑都sleep了”,然后还发觉什么都没装成也不报错。或者是报出一堆莫明的缺包提示、或者要么就是抛出一堆C++函数库找不到的错误。。。
因此网上还有用docker安装已经编译和嵌入了redisearch.so模块的redis的方式。。。但是。。。介个。。。请问一声:大哥,你用人家的docker来做你的生产环境吗?
经过上述准备编译过程就没什么问题了,但是它比较慢。因为编译过程内嵌了不少git clone它还在下一些相应的依赖。
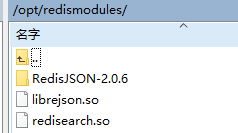
当编译好了后我们可以发觉在源码的build目录下生成了:redisearch.so这个文件。
我们把这个文件统一放到/opt/redismodules/下。
然后要在redis.conf文件中加东西,比如说我的1号群服务器用的是sentinel,有3个节点,我就需要在每个节点的redis.conf中加入以下这么一句:
loadmodule /opt/redismodules/redisearch.so 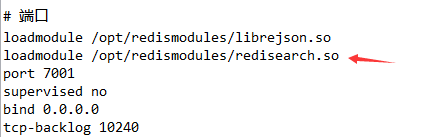
然后我们按照常规把redis服务起来我们观察一下我们3台redis节点的log日志输出。

看到这样的log日志输出,届此就代表着整个RediSearch的编译安装成功了!
安装后客户端的使用
如果说我上面的内容有10分之1中文网可以搜得到,后面的篇章可能在google上也属于只有两个翻页内仅有1-2条是正确的信息。
因为后面我们要讲的是RediSearch和Spring Boot的结合使用来创建二级索引(全文索引)和对于关键字进行全文搜索的内容了。
先来说一下Redis Client端在RediSearch上的验证与使用

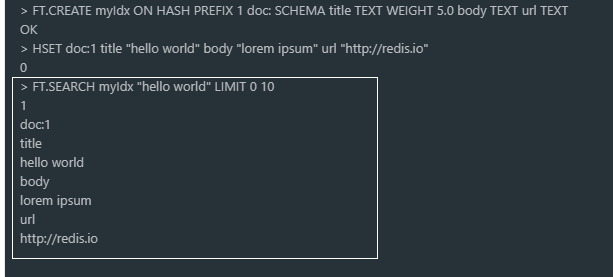
创建索引
FT.CREATE myIdx ON HASH PREFIX 1 doc: SCHEMA title TEXT WEIGHT 5.0 body TEXT url TEXT它的意思为:为一切前缀=doc:开头的键值建立索引myIdx,因此所有的以doc:开头的键值都会位于这条myIdx的索引作用下。
索引创建后喂入数据
HSET doc:1 title "hello world" body "lorem ipsum" url "http://redis.io"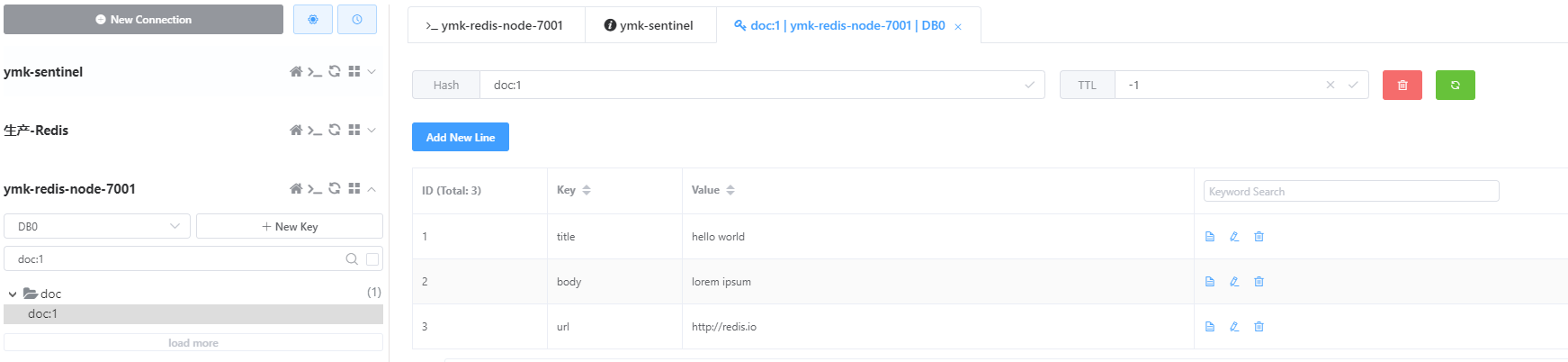
看,这个数据格式是以此redis经典的键值方式存在。
搜索数据
FT.SEARCH myIdx "hello world" LIMIT 0 10得到以下结果:
这些过程很简单,Redis的客户端有一堆命令,这一块我没必要细说,因为非常简单。关键在于学习RediSearch官网中的那些人搜索表达式,它甚至可以索引不同的经纬度并根据经纬度得到我们在零售上常用的“配送距离”、“预计送达时间”,而不用使用商业版的GPS SAAS服务(只是精度比商业版的差一些,中小型企业使用已经远超足够了)。
RediSearch与Spring Boot结合
下面的内容属于google上也没有完整的。
选哪个客户端适合呢
这是官网给到我们的选择,看完直接懵掉。这么大一陀。
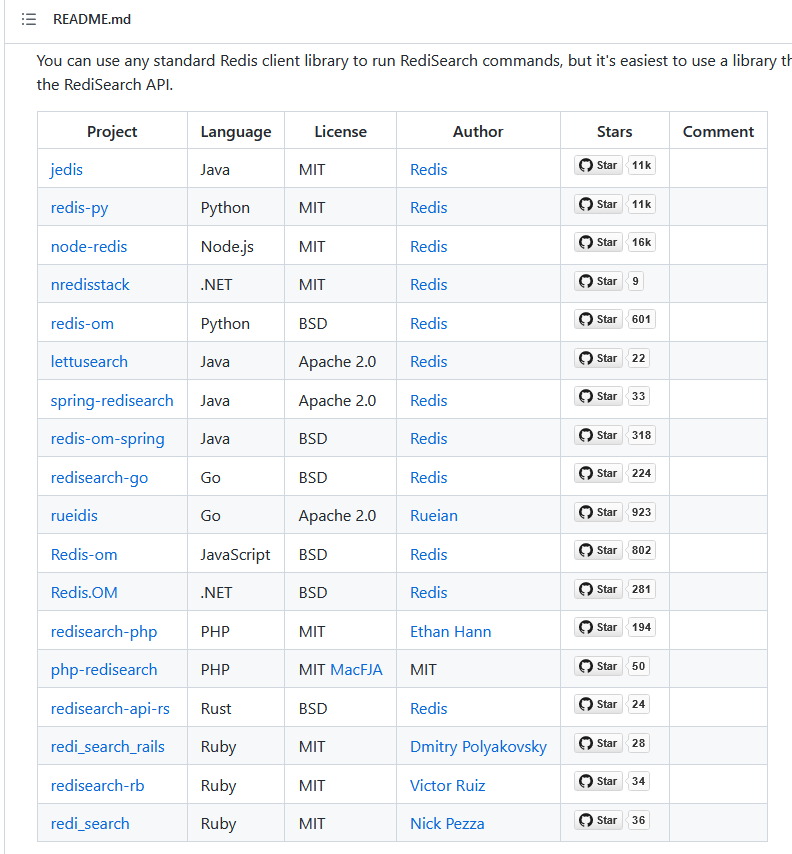
我们找啊找,找到了spring-redisearch,看上去不错。还找到了jedis。这些都是“原配”,原配肯定好啊。
于是我用了spring-redisearch,发觉,我的天哪,它要求我们的spring boot要升到2.6以上。而我已经成型的具有生产运行能力的新中台用的是spring boot 2.4.3开发的。spring boot的轻意升级会导致几乎整个底层jar包依赖的重构,这个重构充满着排包、下载新包、甚至一些API都废弃掉如:spring boot2.4不就不用netflix feign和ribbon而改用spring cloud loadbalance了吗?还把hystrix包排除出spring boot的体系需要开发者自行装配。
因此,如果在工程上为了一个不错的小feature而去升级、替换整个spring boot的底层,这个工作量暂且不去说它有多大(如果造一个生产级中台需要6个月,换spring boot可能需要花费3个月时间包括所有功能的回归测试),我们就说值不值吧?
那么我们发觉一些小features确实不错。。。想用因为版本限制不能用怎么办?介个吗。。。不是开源吗?你去看看这些小features是怎么写的,自己照着写或者改一个符合适用于自己的spring boot版本的自己的功能不就成了,这就是程序员的价值啊。。。扯远了!
扯回来。
我又试了jedis,这个也是个好东西啊。。。果然里面的API已经支持了redisearch的全部功能了。然后我也去用了,发觉。。。它的jedis要使用4.3.x版以上,而spring boot2.4.3的spring-data-redis只支持到jedis-3.9。
因为spring boot2.4.3的spring-data-redis只支持到jedis 3.9版。如果你单纯的把jedis换成了4.3.0,那么你的spring-data-redis编译时虽然不会报错,而一旦运行起来用到了redis相关功能,后就会抛一堆的class not found的exception。这也意味着如果我要用jedis-4.3.0,那么我也要对spring boot进行升级。
我此处真想又要放那张“太残暴了”的图了。。。
我后来干脆把所有的redisearch java相关的client端使用了一遍,最后发觉最好的、也是原配的而且支持redisearch全功能的、代码上也很优雅的是以下这个客户端:
lettusearch
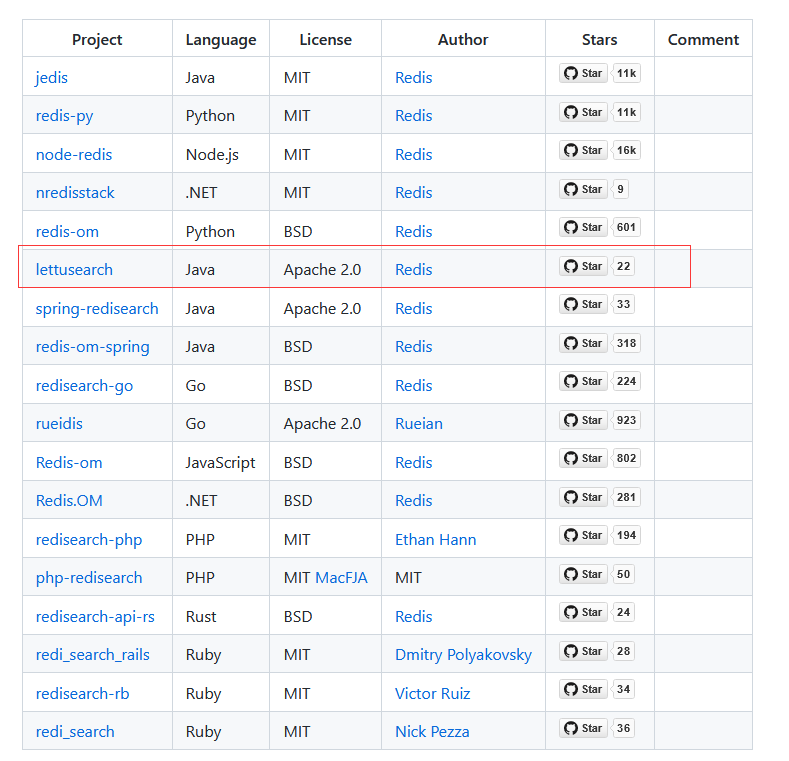
最主要的是使用lettusearch不会对你的项目造成任何的影响,它是真正的插件式、可适配现有spring boot版本的一个java客户端。
lettusearch的使用
maven依赖
![]()
这是我的引用版本,在我们的arch-pom文件里我只需要引入两个包即可使用redisearch的features了。
<dependencyManagement>
<dependencies>
<!-- redis modules search-->
<dependency>
<groupId>com.redis</groupId>
<artifactId>lettucemod</artifactId>
<version>${lettucemod.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/io.lettuce/lettuce-core -->
<dependency>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
<version>${lettuce.core.version}</version>
</dependency>
而在我们的子maven项目中我这样使用即可:
<!-- redis modules search-->
<dependency>
<groupId>com.redis</groupId>
<artifactId>lettucemod</artifactId>
</dependency>
<dependency>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
<version>${lettuce.core.version}</version>
</dependency>
<!-- redis modules search-->Java代码
建立一个索引并喂入了1万条数据
private final Logger logger = LoggerFactory.getLogger(getClass());
public static final String PREFIX = "beer:";
public static final String INDEX = "beers";
public static final String FIELD_PAYLOAD = "payload";
public static final Field<String> FIELD_ID = Field.tag("id").sortable().build();
public static final Field<String> FIELD_NAME = Field.text("name").sortable().build();
public static final Field<String> FIELD_DESCR = Field.text("descr").build();
public static final Field<String>[] SCHEMA = new Field[] { FIELD_ID, FIELD_NAME, FIELD_DESCR };
@Autowired
RedisTemplate redisTemplate;
@Test
public void testCreateIndex() throws Exception {
RedisSentinelConnection conn = null;
String host = "";
int port = 6379;
StringBuffer redisConnStr = new StringBuffer();
StatefulRedisModulesConnection<String, String> connection = null;
try {
conn = redisTemplate.getConnectionFactory().getSentinelConnection();
List<RedisServer> servers = new ArrayList(conn.masters());
for (RedisServer rNode : servers) {
if (rNode.isMaster()) {
host = rNode.getHost();
port = rNode.getPort();
}
logger.info(">>>>>>node in rNode is [host: " + rNode.getHost() + "] [port: " + rNode.getPort() + "]");
}
redisConnStr.append("redis://").append(host).append(":").append(port);
logger.info(">>>>>>get RedisModulesClient connection string with->" + redisConnStr.toString());
RedisURIBuilder uriBuilder = RedisURIBuilder.create();
uriBuilder.host(host);
uriBuilder.port(port);
char[] password = "xxxx超复杂".toCharArray();
uriBuilder.password(password);
RedisURI uri = uriBuilder.build();
RedisModulesClient client = RedisModulesClient.create(uri);
connection = client.connect();
// create index
CreateOptions<String, String> options = CreateOptions.<String, String>builder().prefix(PREFIX)
.payloadField(FIELD_PAYLOAD).build();
connection.sync().ftDropindexDeleteDocs(INDEX);
connection.sync().ftCreate(INDEX, options, SCHEMA);
connection.setAutoFlushCommands(false);
RedisModulesAsyncCommands<String, String> async = connection.async();
List<RedisFuture<?>> futures = new ArrayList<>();
for (int i = 0; i < 10000; i++) {
Map<String, String> beer = new HashMap<String, String>();
beer.put(FIELD_NAME.getName(), String.valueOf(i));
beer.put(FIELD_DESCR.getName(), generateRandomString());
//logger.info(">>>>>>add name->" + i);
futures.add(async.hset(PREFIX + FIELD_ID.getName() + i, beer));
}
connection.flushCommands();
LettuceFutures.awaitAll(connection.getTimeout(), futures.toArray(new RedisFuture[0]));
// RediSearchCommands<String, String> search = connection.sync();
// SearchResults<String, String> results = search.ftSearch("beers", "1664");
// if (results != null) {
// logger.info(">>>>>>get result from RediSearch size->" + results.size());
// for (Document<String, String> doc : results) {
// logger.info(">>>>>>doc:" + doc.getId() + " name->" + doc.get("name"));
// }
// }
} catch (Exception e) {
logger.error(">>>>>>testCreaedIndex error: " + e.getMessage(), e);
} finally {
try {
conn.close();
} catch (Exception e) {
}
try {
connection.setAutoFlushCommands(true);
} catch (Exception e) {
}
}
}在生产级工程应用上,我强烈建议大家如果你使用的是redisearch请使用redis-cluster模式。lettusearch天然支持redis-cluster的RedisModuleClient。
由于我们使用的是sentinel,平时需要索引的数据不是太多,不过20GB内数据,因此我们使用的是sentinel模式,也是一样可以使用的。
代码的核心导读如下。
代码核心导读
通过已经运行在工程内的redisTemplate获取到它当前的master节点的连接信息,密码可以通过外部配置文件(nacos里配置的信息)喂入后建立一个RedisModulesClient的连接。
该连接使用async的异步方式进行连接。
使用List<RedisFuture<?>> 来承载要重复执行的“redisearch”的命令。
先建立索引,再喂入数据。
喂入的每一条数据是一个Map<String, Object>键值。假设一条JSON数据有10个字段,这一个Map就需要有10条数据,每一条数据的key对应着在建立索引时的以下语句中的SCHEMA中映射的那些个Field:
connection.sync().ftCreate(INDEX, options, SCHEMA);每一行Map的键是字段名,值就是你的数据的内容了,可以是数字、文字甚至再套一个复杂对象等各种内容。
把一个Map当成一行JSON结构的数据,塞入一个List<RedisFuture<?>>然后在最后使用:connection.flushCommands();提交并且异步等到LettuceFutures.awaitAll(connection.getTimeout(), futures.toArray(new RedisFuture[0]));这个时间后结束所有的“建立索引”的过程。
这条awaitAll你们可以认为是监测整个List<RedisFuture<?>>的提交过程是否结束了。
上述UT运行后,在Redis里会生成这样的东西
基于redisearch的全文搜索
搜索需求:
我们在刚才喂入的1万条数据里搜索“笑字开头或者是水字开头或者是带笑字的数据,并且如果是有笑字的数据的搜索出来的排序比以水字开头的数据要靠前”。
String searchKeyWords = "笑*|水*|~笑";代码:
@Test
public void testSearch() throws Exception {
RedisSentinelConnection conn = null;
String host = "";
int port = 6379;
StringBuffer redisConnStr = new StringBuffer();
try {
conn = redisTemplate.getConnectionFactory().getSentinelConnection();
List<RedisServer> servers = new ArrayList(conn.masters());
for (RedisServer rNode : servers) {
if (rNode.isMaster()) {
host = rNode.getHost();
port = rNode.getPort();
}
logger.info(">>>>>>node in rNode is [host: " + rNode.getHost() + "] [port: " + rNode.getPort() + "]");
}
redisConnStr.append("redis://").append(host).append(":").append(port);
logger.info(">>>>>>get RedisModulesClient connection string with->" + redisConnStr.toString());
RedisURIBuilder uriBuilder = RedisURIBuilder.create();
uriBuilder.host(host);
uriBuilder.port(port);
char[] password = "xxxx超复杂".toCharArray();
uriBuilder.password(password);
RedisURI uri = uriBuilder.build();
RedisModulesClient client = RedisModulesClient.create(uri);
StatefulRedisModulesConnection<String, String> connection = client.connect();
String searchKeyWords = "笑*|水*|~笑";
// new String(searchKeyWords.getBytes("utf-8"), "utf-8");
logger.info(">>>>>>searchKeyWords->" + searchKeyWords);
RediSearchCommands<String, String> search = connection.sync();
SearchOptions<String, String> options = SearchOptions.<String, String>builder().withPayloads(true)
.noStopWords(true).limit(0, 27).withScores(true).build();
SearchResults<String, String> results = search.ftSearch("beers", searchKeyWords, options);
if (results != null) {
logger.info(">>>>>>get result from RediSearch size->" + results.size());
for (Document<String, String> doc : results) {
logger.info(">>>>>>doc:" + doc.getId() + " name->" + doc.get("name") + " and descr->"
+ doc.get("descr"));
}
}
} catch (Exception e) {
logger.error(">>>>>>testCreaedIndex error: " + e.getMessage(), e);
} finally {
try {
conn.close();
} catch (Exception e) {
}
}
}当上述UT运行后,我们可以得到27条结果。因为基于索引无论是基于ES还是现在基于RediSearch,搜索不可能一下把所有的命中结果都展示出来的,你的Web应用服务器性能吃不消,因此在功能设计上都是带“翻页”的,因此这个翻页就是用的以下这条语句来实现多少条记录“一翻页”的:
SearchOptions<String, String> options = SearchOptions.<String, String>builder().withPayloads(true)
.noStopWords(true).limit(0, 27).withScores(true).build();这就是为什么我们可以搜出27条数据的原因。
结束语
全文到此结束了我们的RediSearch入门之旅,通过全文我们可以看到:RediSearch要用了好关键就是你的RediSearch的表达式要写了好。
它的性能是远超ES的,我生产用5台ES每一台为64GB内存,8C CPU运行500万数据里搜索20个热搜,而我用6台Redis组成集群每一台Redis节点只有6-8GB内存,4C CPU,运行同样的数据和搜索词。都使用了320个spring boot客户端做并发。
在同样并发下,竟然得到了RediSearch比ES的响应快出60%的效率。这意味着我们可以用更低的成本做到更好的事,同时可以让我们的这个企业级架构变得更轻、更简单。
最后还是这句话:如果你够变态,不妨自己动动手吧!