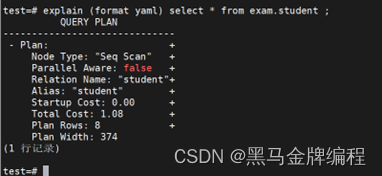
索引的应用
一、常见索引及适应场景
BTREE索引
是KES默认索引,采用B+树实现。
适用场景
范围查询和优化排序操作。
不支持特别长的字段。
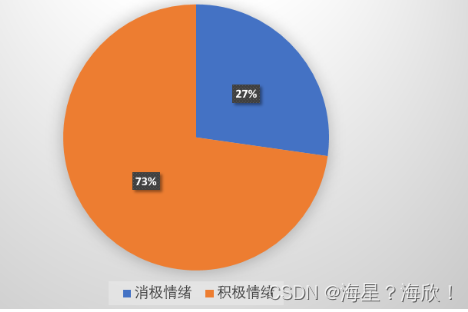
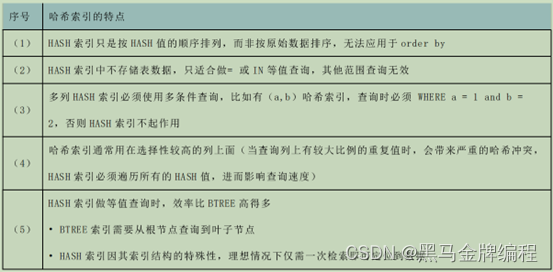
HASH索引
先对索引列计算一个散列值(类似md5、sha1、crc32),然后对这个散列值以顺序(默认升序)排序,同时记录该散列值对应数据表中某行的指针。
适用场景
适用宽字段场景与等值搜索。
特点
GIST索引
分层组织的空间索引
应用场景
位置搜索(包含、相交、在上下左右等)
按距离排序
GIN索引
是倒排索引(类似B+TREE,值+行号),将数组/全文检索类型中的值存储到树形结构中,
对于高频值,减少树的深度,行号会存储在另外的页中。
适用场景
适用于包含多个组合值的查询,如数组、全文检索等。
BEIN索引
- BRIN/Block Range INdex是块级索引,它不是一个精确的索引。
- 在索引中存储一定范围的表数据块中某个列的最小和最大值及摘要信息。
- 仅能过滤到连续的数据块级别,需要对块内的数据再次作比较。
- 未将ORDER BY 字段的值按顺序存储到索引中。
- BRIN索引与BTREE索引区别
- BRIN的思路是避免扫描不合适的行,而不是快速找到匹配的行。
- 当查询语句中包含该列的过滤条件时,就会自动忽略那些肯定不包含符合条件的列值的数据块,从而减少IO读取量,提升查询速度。
特点
空间占用小,对数据写入、更新、删除的影响也很小。
适用场景
适用于存储流式的数据日志,例如时序数据进行等值、范围查询时效果很棒。
二、索引的使用技巧
1、表达式索引
(1)KES允许对字段进行某种运算之后的结果创建索引
(2)索引列可以是底层表中的原始列

2、部分索引

- 复合索引(基于表的多列上创建的索引)

日常运维
- 数据库瘦身步骤
- 大表瘦身

找出大表
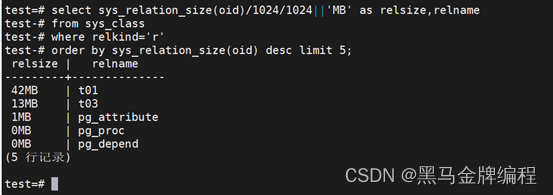
-
- 清理不必要的索引

3.定位慢查询
4.处理长事务
5.垃圾回收